IA & Jeux
INTELLIGENCE ARTIFICIELLE
Utiliser l'ordinateur pour simuler des taches de RÉFLEXION qu'on attribue aux humains et animaux
INTELLIGENCE ARTIFICIELLE
Va de la calculatrice au chatbot, en passant par :
- résolution de jeu de plateaux
- optimisation mathématique
- reconnaissance d'images
- planification de taches
- ...
S'inspire de/utilise :
- mathématiques
- logique
- biologie
- neuroscience
- psychologie
- philosophie
Histoire IA & Jeux
-
pacman, 1979 : 4 fantomes avec des scripts distincts
-
Scripts simples jusque dans le milieu 90s
-
Fin 90 : goldeneye, metal gear solid : ajout de la perception des autres NPC pour des scripts plus complexes
-
RTS (warcraft) : pathfinding
-
Creatures, 1997 : algorithmes génétiques et réseaux de neurones : une des IA les plus complexes même maintenant!
Briques Principales
-
input (environnement / état interne)
-
stratégie : suite d'actions simples / synchronisation d'un groupe d'agents
-
prise de décision : quelle action faire maintenant en fonction de : état, environnement, état ennemi, etc
-
mouvements/actions (output)
Catégorie d'IA
-
agent-based AI : chaque NPC a son intelligence indépendante des autres
-
"God" AI : un même système calcule et envoie les commandes à tous les NPC
Les bases de la base en IA
Besoin de :
-
Algorithmes : suite d'instructions relativement simples
-
Structure de données : choisir et arranger les données utilisées pour faire des décisions
-
Heuristiques : un algorithme qui donne une solution rapidement mais peu précise
-
Hack : n'importe quelle astuce qui rend l'IA intéressante
IA efficace (agent-based)
- IA complexe != IA réaliste ou intéressante
- Le mieux : technique simple qui donne l'illusion de la complexité
- actions du NPC doivent être compréhensible du point de vue du joueur! (par rapport à ce que le joueur sait de l'environnement et du NPC)
- changements de comportement du NPC doivent être minimes ou alors compréhensibles par le joueur
...mais : pas important pour ce défi !!
IA 1 : mouvement
-
IA bas niveau : trouver le plus court chemin entre start et end, en évitant les obstacles
-
UE fait presque tout
-
voir A*
-
autres problèmes à gérer : orientation, inertie, prédiction de mouvements, formation en groupe, synchroniser animation et déplacement
IA 2 : décision
-
Decision tree : un arbre pour trouver l'action à faire
-
State machine (et Hierarchical SM) : graphe avec les états possibles de l'agent et les transitions possibles entre états (animation blueprint - State Machine)
-
Behavior Tree (UE4) : l'arbre affiche les taches à faire
-
Markov Process : représente les états du jeu par des vecteurs et des événements par des matrices de transition
IA par apprentissage
-
2 Problèmes à régler
-
prédiction : que va faire l'ennemi ?
-
décision : qu'est ce que je vais faire ?
-
-
Mode d'apprentissage
-
online : pendant le jeu
-
offline : avant le jeu, pendant le développement
-
- Nécessite
- représentation simple des actions possibles
- représentation simple de l'état du jeu (environnement, personnages, temps, ...)
IA apprentissage (1)
Prédiction
-
garder l'historique des actions du joueur (par ex: IFHIB ) et trouver la séquence actuelle de l'ennemi pour déduire l'action suivante
-
N-grams : garde la fréquence de toutes les séquences d'actions en mémoire
IA apprentissage (2)
Méthode générique : parameter-based
- une fonction mathématique composée de variables et de paramètres
- Il faut calculer les paramètres pour obtenir un "bon" résultat
IA apprentissage (3)
Naive Bayes Classifier
- Trouver la probabilité de faire une action à partir d'un état
- utilise la formule de Bayes
- nécessite une liste d'expériences pour calculer des probabilités intermédiaires
IA apprentissage (4)
Decision tree learning
- création d'un decision tree à partir d'expériences de jeu
- crée des branches à partir des états du jeu ou des actions faites et indique le résultat à la fin
IA apprentissage (5)
Reinforcement learning
- apprendre l'efficacité d'une action en fonction de l'état du jeu
-
Si dans un état donné, on a fait une action particulière et que le résultat est bon, on augmente la probabilité de faire cette action la prochaine fois, et inversement.
- voir Q-learning
IA apprentissage (6)
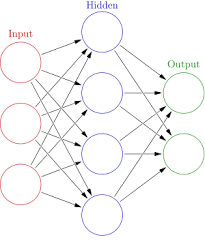
Neural network
voir Multi-Layer Perceptron
Liens
P:\AGORA Poly1\Defi Ai Fighting Game\Documents
GDC_Designing Awesome AI for Games.mp4
GameAIPro_Chapter01_What_is_Game_AI.pdf
livre : Artificial Intelligence for games
https://wiki.unrealengine.com/Blueprint_Behavior_Tree_Tutorial
https://docs.unrealengine.com/latest/INT/Engine/AI/BehaviorTrees/QuickStart/index.html
GameAI
By tetorea



