Music Genre
Classification
Text Mining Project
Orange Team 6 - Matthew Gilmore, Mary Hall,
Steve Neola, Mikhail Pikalov, Samantha Strapason
Agenda
- Project Intro
- Unsupervised Exploration
- Supervised Model
- Results
Problem
Pandora, Last.fm, Spotify etc... all try to correctly classify songs by genre
Solution
Theirs: Manually tag songs and analyze algorithmically
Ours: Build a classification model - with 75% accuracy - to analyze their lyrics
Gathering Lyric Data
Scraped lyrics.com for the top ~100 songs for 3 genres:
-
Pop
-
Country
-
Hip - Hop
For each song, we gathered:
-
Author(s)
-
Title
-
Lyrics
-
Genre
Web Scraping Code
import urllib
import re
import pandas as pd
genre=[20,2,22,6,17,18,11,12,14,15,24,21]
increments=[0,30,60,90,120]
links=[]
tag=[]
for i in genre:
for j in increments:
l='http://www.lyrics.com/tophits/genres/'+str(j)+'/'+str(i)
p=i
tag.append(p)
links.append(l)
dictionary=dict(zip(links,tag))
lyrics_links=[]
gerne_tag=[]
for key,value in dictionary.items():
htmltext=urllib.urlopen(key).read()
htmlstr=str(htmltext)
p=re.findall('<a href="(.*?)" style="padding:2px', htmlstr)
for i in p:
g='http://www.lyrics.com'+i
lyrics_links.append(g)
gerne_tag.append(value)
dict2=dict(zip(lyrics_links,gerne_tag))
lyrics=[]
title=[]
artist=[]
genre2=[]
for key,value in dict2.items():
htmltext=urllib.urlopen(key).read()
htmlstr = str(htmltext)
d=htmlstr.replace('<br />\r\n',' ').replace('<br />\n',' ').replace('<div id="lyrics" class="SCREENONLY" itemprop="description">','')
title2=re.findall('<h1 id="profile_name">([^"]+)<br /><span', d)
print title2
m=re.findall('<div id="lyric_space">\s+((.*?)[^"]+)<br />---<br />', d)
c=re.findall('<h1 id="profile_name">([^"]+)<br /><span class="small">', d)
f=re.findall('">([^"]+)</a></span></h1>\s+<div class="fblike_btn">', d)
if len(m)==1:
if len(c)==1:
if len(f)==1:
lyrics.extend(re.findall('<div id="lyric_space">\s+((.*?)[^"]+)<br />---<br />', d))
title.extend(re.findall('<h1 id="profile_name">([^"]+)<br /><span class="small">', d))
artist.extend(re.findall('">([^"]+)</a></span></h1>\s+<div class="fblike_btn">', d))
genre2.append(value)
data={'lyrics':lyrics,'title':title, 'artist':artist, 'genre2':genre2}
lyric_data= pd.DataFrame(data)
number_to_genre={20:'alternative',2:'blues',22:'christain/gospel',6:'country',17:'dance',18:'hiphop/rap',11:'jazz',
12:'latino',14:'pop',15:'r&b/soul',24:'reggae', 21:'rock'}
lyric_data['genre']=lyric_data['genre2'].map(number_to_genre)
lyric_data.to_csv('C:\Users\MatthewGilmore\Desktop\lyric_data.csv')
Unsupervised Exploration
Progressive Clarity
- Word Clouds
- Topic Clustering
- Text Association
Word Clouds

Topic Clusters: Guess the Genre
town +sittin country +truck road +song +sweet +sun +hair radio +blue pretty +seat +summer +night +little +long alright +home +good +hear +down +baby +turn +old
+fall +love +heart always eyes wont youre lost ill +cause +feel +know +find id +dont +hand +mind im well +stay youll +want +face cant ive
+bitch +shit club +party +verse +man +damn +hit em people +beat +hope real +play +hell aint +day +stop +head +world chorus alright +time +face +turn
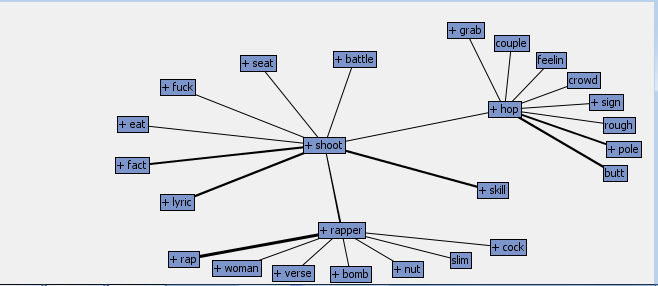
Text Association: Pop
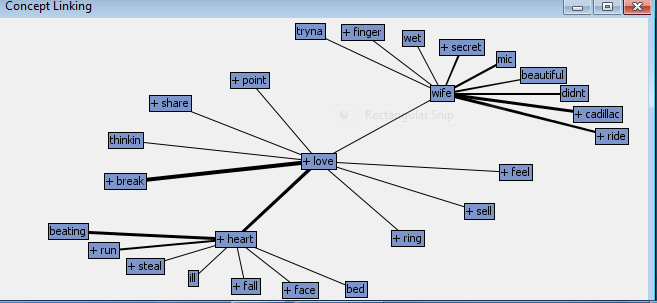
Text Association: Country
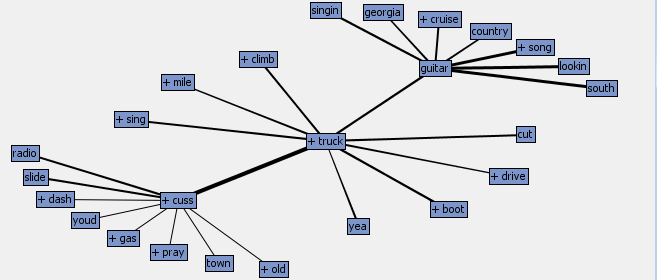
Text Association: Hip-Hop
Word Cloud #2

Word Cloud #3

SUPERVISED Classification
GOAL
Build a classifier using song lyrics to predict genre
Text ClassifiCation Process
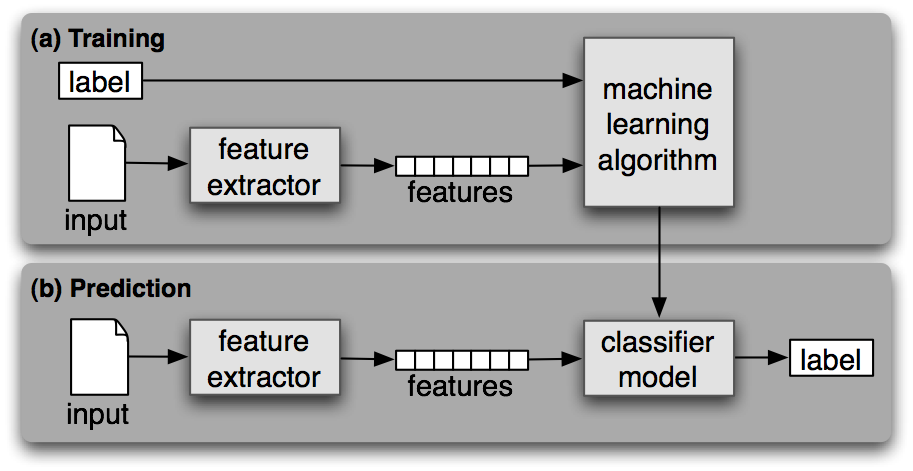
Training
OVERVIEW
Methodology:
1. Build Feature Extractor2. Build Classification Model
building a feature extractor
Methodology:
- Create a TF-IDF matrix representation of the training lyrics.
- Use SVD to reduce the dimensionally
CReating the tF-Idf matrix
corpus=numpy.asarray(train['lyrics'])cv=TfidfVectorizer(stop_words=stops,sublinear_tf=True, use_idf=True)counts=cv.fit_transform(corpus)
REDUCING DIMENSIONS
svd=TruncatedSVD(n_components=100)
lsa=svd.fit_transform(counts)so what exactly did we just do?
1. Original Dataset:
- Genre || Lyrics
2. TF-IDF Data:
- Genre || W1, W2, ..., ~W5000
3. SVD:
- Genre || SVD1, SVD2..., SVD100
Creating a classification model
Methodology:
- With the text now represented numerically we can use standard classification techniques.
- The random forests model had the most accurate classification results.
RANDOM FOREST MODEL
clf = RandomForestClassifier(n_estimators=2000)targets = numpy.asarray(train['genre2'])clf.fit(lsa, targets)scores=cross_validation.cross_val_score(clf,lsa, targets, cv=10)print("Accuracy: %0.2f (+/- %0.2f)"%(scores.mean(),scores.std() * 2))
Accuracy: 0.75 (+/- 0.18)
clf = RandomForestClassifier(n_estimators=2000)targets = numpy.asarray(train['genre2'])clf.fit(lsa, targets)scores=cross_validation.cross_val_score(clf,lsa, targets, cv=10)print("Accuracy: %0.2f (+/- %0.2f)"%(scores.mean(),scores.std() * 2))
PREDICTION
OVERVIEW
Methodology:
1. Apply Feature Extractor
2. Apply Classification Model
Methodology:
1. Apply Feature Extractor2. Apply Classification Model
Apply Feature Extractor
test_lyrics= numpy.asarray(test['lyrics2'])test_data= cv.transform(test_lyrics).toarray()
test_reduced_data=svd.transform(test_data)APPLY CLASSIFICATION MODEL
test['predictions'] = clf.predict(test_reduced_data)CLASSIFICATION RATE
confusion_matrix=pd.crosstab(test.genre2,test.predictions)Testing Confusion Matrix
(Accuracy ~ .78)
predictions country pop rap/hip-hop All genre country 9 5 0 14 pop 0 13 0 13 rap/hip-hop 0 3 6 9 All 9 21 6 36
Inspecting CLASSIFICATION errors
Examples from testing sample:
HIP HOP:
- Macklemore-Cant Hold Us
- Flo Rida-Whistle
COUNTRY:
- Flordia Gorigia Line-Take It Out On Me
- Lady Antebellum-Downtown
Suggested model improvements
- Use bi-grams
- Integrate POS
- Utilize song features
Summary
- Project Intro
- Unsupervised Exploration
- Supervised Model
- Results
Title
Music Genre Classification: Text Mining Project
By textproject

