Nuxeo Platform
Architecture Overview

Thierry Delprat
td@nuxeo.com
https://github.com/tiry/
Some Context
About Nuxeo Platform

Nuxeo
we provide a Platform that developers can use to
build highly customized Content Applications
we provide components, and the tools to assemble them
everything we do is open source
various customers - various use cases


Track game builds
Electronic Flight Bags
Central repository for Models
Food industry PLM
https://github.com/nuxeo

Nuxeo Document
Storing objects (think {JSON} object)
- Schemas
- Streams
- Security
- Search
- Audit
Custom Domain Model
Conversions & Previews
Security Policies
on any field
At SCALE
Application Log
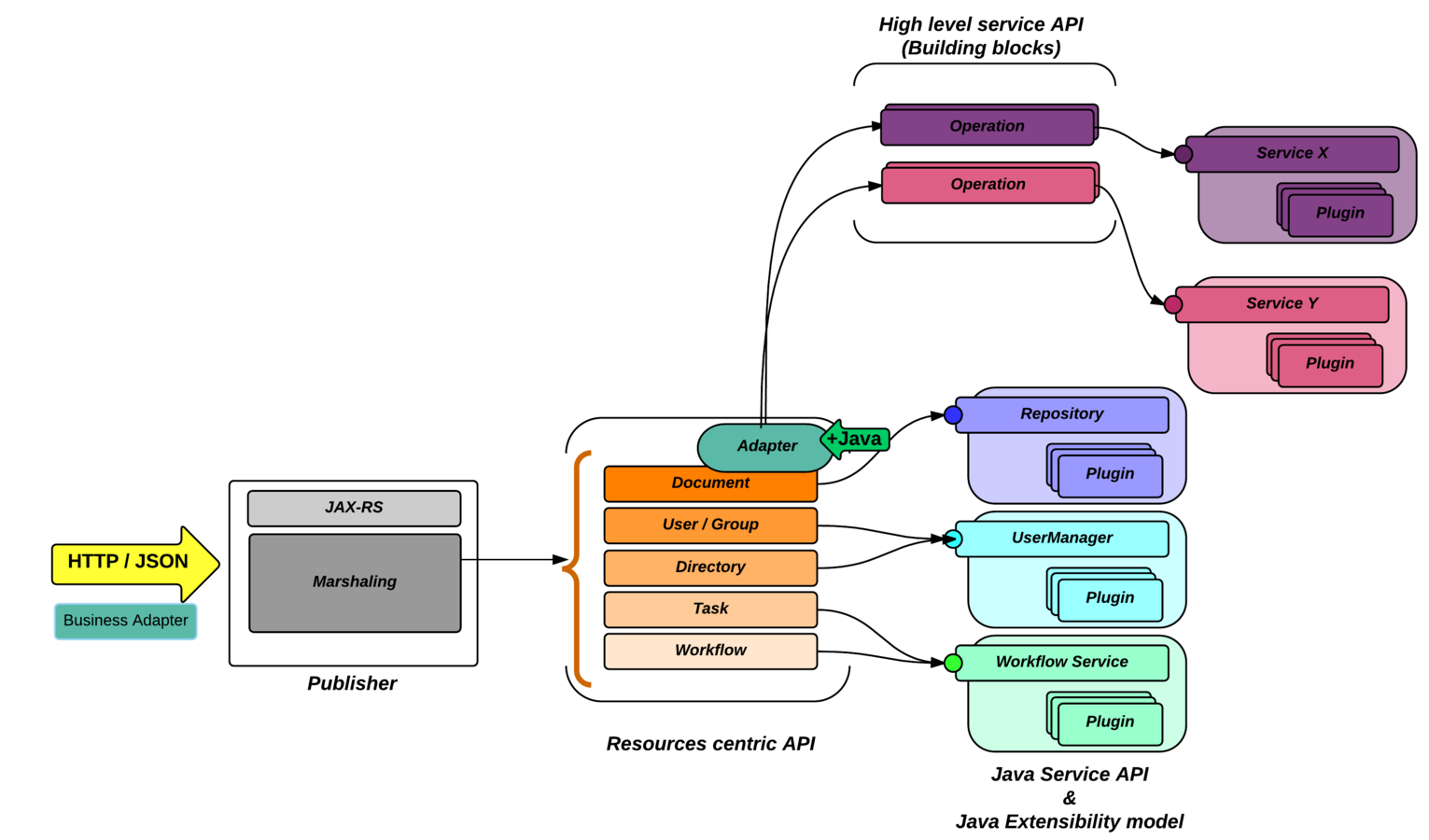
Nuxeo Platform
Repository
Services
- Workflows, Conversions, Diff, Notifications, Activity ...

Architecture goal
Custom tailored Business application
Application must evolve with Business
Architecture goal
-
Goals
- Let you focus on business logic
- Allow advanced configuration
- Ensure maintenance
- Provide clean upgrade path
-
Principles
- Provide an Extensible Component Model
- Ensure clear separation between
- custom code
- Nuxeo provided code
- Provide the test infrastructure
ArchitEcture
Principles and technologies used
Component Model
- In Nuxeo architecture everything is a plugin
-
Everything is configurable
- Logic and Data Structrures depends on configuration

Plugins everywhere
One plugin model for
- all layers
- for the platform
- for your custom components

Plugins At Storage level

Plugins At Storage level

Plugins At Storage level

Plugins At Storage level

About technologies
-
Core infrastructure
- Java "a la OSGi"
-
Contributions
- Java, JavaScript, XML
-
Third party technologies
- SQL Storage: PostgreSQL, Oracle, MySQL, MS SQL
- NoSQL Storage: MongoDB / Marklogic
- Binary Storage: S3, GridFS, GoogleDrive
- Indexing: Elasticsearch
- Queuing: ChronicalQueue, Kafka
- Cache and Shared structures: Redis
About technologies
- REST API
-
Web UI
- WebComponents / Polymer UI (nuxeo-elements)
- Legacy JSF2 back office
- JAX-RS / Freemarker for custom portal
-
Mobile Application
- ReactNative based customizable Mobile application
- Client libs




FrontEnd - Clients
About technologies
Build - Test - Ship - Deploy

About technologies
-
Testing
-
Junit for unit tests
- Feature runner to deploy Nuxeo bundles
- No need for mocks
- WebDriver & Selemium for functional testing
-
Gatling & Funkload for performance testing
-
Junit for unit tests
-
Build & Automation
- Maven for build, dependencies and running tests
- Jenkins for CI
- Ansible
FrontEnd - Clients
About technologies
-
Packaging and deployment
- Debian packages
- Nuxeo packages
- VM images
- Docker images
-
Cloud
- AWS deployment models (Terraform and CloudFormation)
- K8S / OpenShift templates
-
Ansible Playbook Bundles
Customization
Building a business App with Nuxeo
About Extension points
- 260 Bundles
-
200+ Components
- 180+ Services exposed
- 280+ Extension points
- 1000+ Contributions
-
200+ Components
Pretty much everything inside the Platform can be customized
Anatomy of a Nuxeo based Application

-
Easy maintenance and upgrade
-
Clear separation between infrastructure provided by Nuxeo
and the custom components -
Nuxeo Studio configuration is transparently upgraded
-
Building with Nuxeo


Continuous deploymemt

Reusing Customization

Create a new Addon
-
This addon is a first class citizen
-
It can receive additional configuration
-
it can be mixed with other addons
-
Reusing Customization

-
You can use Studio to configure your addons
-
override or extend domain model
-
extend default configuration
-
Reusing Customization

-
Share common code and configuration
- Allow 2nd level customization

Studio Branches

-
Share common code
-
Different branches
of configuration
Repository
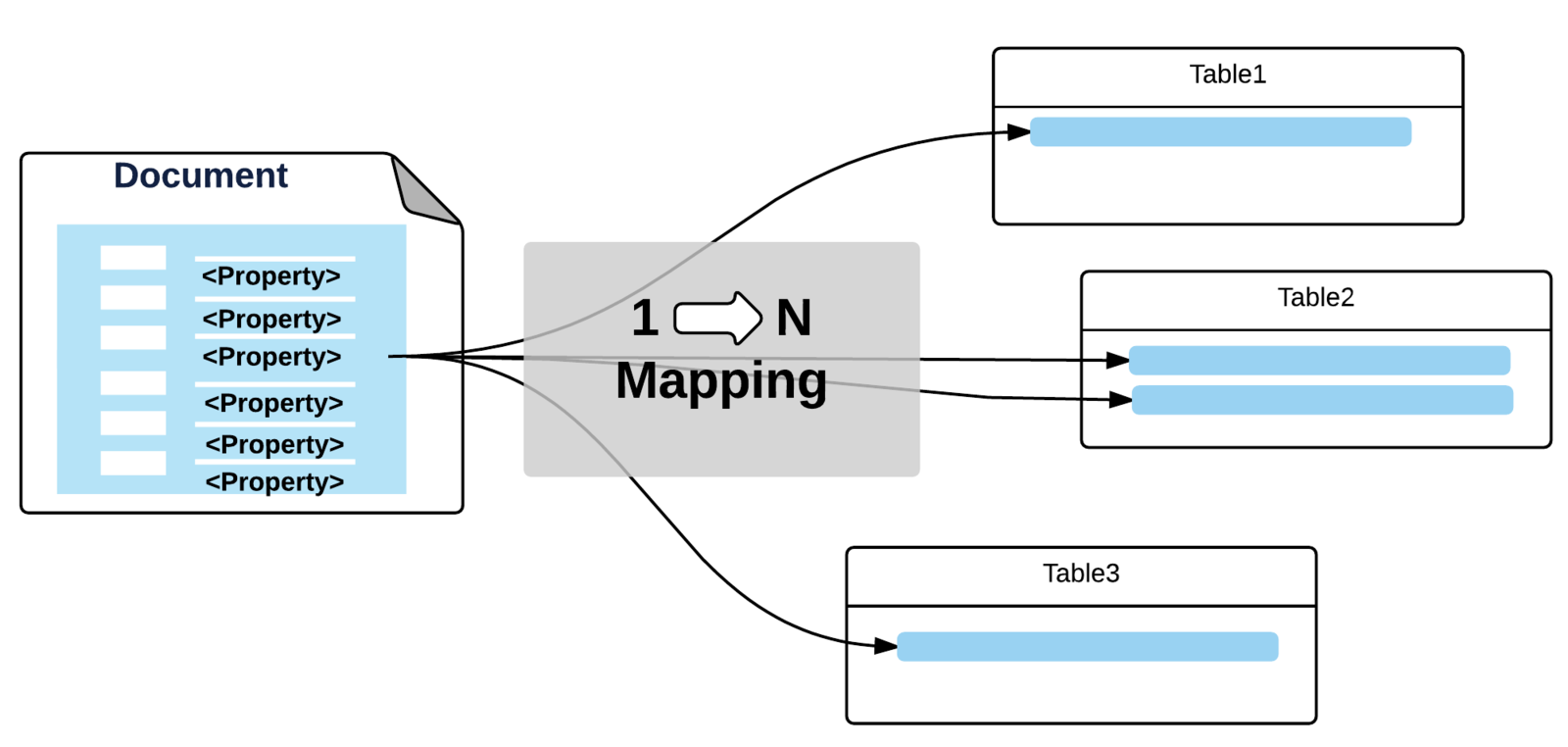
Nuxeo Storage Model
Nuxeo Document
-
a “Document” is not a simple file
-
one document = a persistent object with properties (String, Date, File, Complex types ...)
-
properties are defined by Schemas
-
-
Document types
-
a document type is defined by a set of schemas, inheritance is supported
-
-
Lifecycle
-
document type is associated with states and transitions
-
-
Facets
-
can be used to associate behavior (Folderish, Hidden, Commentable …)
-
can be associated with a schema (Mixins) and with a Business Object adapter
-
Nuxeo Document
-
Document Schemas are based on XSD
-
a field can be a Binary Stream
-
a field can have constraints
-
required, validation pattern
-
reference to a document or a user
-
custom constraint
-
Scalar properties and arrays:
dc:title = "My Document"
dc:contributors = ["bob", "pete", "mary"]
dc:created = 2014-07-03T12:15:07+0200
ecm:uuid = 52a7352b-041e-49ed-8676-328ce90cc103
Complex properties and lists of them:
primaryAddress = { street = "1 rue René Clair", zip = "75018",
city = "Paris", country = "France" }
files = [
{ name = "doc.txt", length = 1234, mime-type = "plain/text",
data = 0111fefdc8b14738067e54f30e568115 },
{ name = "doc.pdf", length = 29344, mime-type = "application/pdf",
data = 20f42df3221d61cb3e6ab8916b248216 }
]
Storage Adapters

Hybrid Storage Architecture
-
MongoDB
-
store structure & streams in a BASE way
-
-
elasticsearch
-
provide powerful and scalable queries
-
-
SQL DB
-
store structures in an ACID way
-
Storage does not impact application : this can be a deployment choice!

A
tomic
C
onsistent
I
solated
D
urable
B
asic
A
vailability
S
oft state
E
ventually consistent
depends on Availability & Performances requirements


Send Queries
to the repository
(here SQL)

or send Queries
to elasticsearch
Store Structures
in SQL Database

or store Structures
in MongoDB

store streams
in MongoDB too

store streams
in S3

HSM

Leverage
Google Drive & Google Doc integration

Can mix all
storages types

Audit Log too
can be configured
to use
elasticsearch
Blob Store
-
BlobStorage is pluggable
-
several implementations available
- FS, SQL, GridFS
- S3, Azure, JCloud
- GoogleDrive, DropBox
-
several implementations available

-
easy to build new implementation as needed
- new Cloud Storage, HDFS, GlusterFS, Ceph...
BlobManager
-
Blob Storage is externalized
- leverage external storage
- leverage existing repository - no migration
-
Leverage Nuxeo features
- Indexing including full text extracted from the Blob
- Security
- common meta-data
-
BlobManager / LiveConnect is a framework
- SPI
- Security model
- Importer
BlobManager and External Repositories

Model &
Data Structures

Model &
Data Structures

loaded from Extension Points
(Startup time)
Model &
Data Structures

ORM like mapper
SQL
Model &
Data Structures

Tables are created at startup time
according to configuration
SQL
Model &
Data Structures

Fields removed from configuration
are simply ignored (no data loss)
SQL
Model &
Data Structures

Added fields are added to the tables.
Old entries get default values.
SQL
Model &
Data Structures

In case of incompatible change,
an error is raised at startup time.
SQL
Model &
Data Structures

No Schema Check at startup.
NoSQL
Search
Searching the repository
Principles
-
All Document properties are indexed (default)
-
can query on any field
-
can query on any field
-
Search always include Security filtering
-
at low level to allow scalability
-
at low level to allow scalability
-
Sort, Order by and batching are supported
-
One or several FullText index
- One Query Language: NXQL
SEARCH
SELECT * FROM Document WHERE dc:title = 'Sections' OR dc:title = 'Workspaces'
LEVERAGE ELASTICSEARCH
-
Fast indexing
-
No ACID constraints / No impedance issue
-
3,500 documents/s when using SQL backend
-
10, 000 documents/s when using MongoDB
-
-
Super query performance
-
query on term using inverted index
-
very efficient caching
-
native full text support & distributed architecture
-
3,000 queries/s with 1 elasticsearch node
-
6,000 queries/s with 2 elasticsearch nodes
-
Advanced indexing
- Fine tuning of elasticsearch indexing
- multi language support using multiple analyzers and copy_to
- compound fields created using groovy scripts
- Introduce elasticsearch hints into NXQL
-
select a specific elasticsearch index / analyzer
- leverage elasticseach operators
- do geolocation search
-
select a specific elasticsearch index / analyzer
-- Use an explicit Elasticsearch field
SELECT * FROM Document WHERE /*+ES: INDEX(dc:title.ngram) */ dc:title = 'foo'-- Use ES operators not present in NXQL
SELECT * FROM Document WHERE /*+ES: OPERATOR(regex) */ dc:title = 's.*y'
SELECT * FROM Document WHERE /*+ES: OPERATOR(fuzzy) */ dc:title = 'zorkspaces'-- Use ES for GeoQuery based on geo_hash_cell location near a point using geohash;
SELECT * FROM Document WHERE /*+ES: OPERATOR(geo_hash_cell)*/ osm:location IN ('40','-74','5')leverage what comes for free with elasticsearch
Leverage Aggregates
- Leverage elasticsearch
aggregates
- integrate with the Query system (PageProvider)
- integrate with the Listing / UI model (ContentView)
- Allow to easily build and configure faceted search

Elasticsearch PASS-Through
- Expose an
HTTP pass-through API on top of Nuxeo integration
-
Integrate Authentication & Authorization
- not all users can access workflow index
-
Integrate Security Filtering
- activate data level security filtering
-
Expose "virtual index" via http
-
index + filter
-
index + filter
-
Integrate Authentication & Authorization
-
Use
elasticsearch API related components on Nuxeo data
- Documents + Audit log
- With embedded security
Easy real time data analytics on business data
Elasticsearch mapping
- Pluggable document mapping
- can denormalize relations
-
can levarage relation engine at indexing time
- Use Elasticsearch hints to query on denormalized index
ASYNC INDEXING FLOW

PSEUDO-SYNC INDEXING FLOW

Ingestion
Importing data in the repository
Possible strategies
-
REST API or CMIS
- write importer in JavaScript, Python ...
- plug with ETL or ESB
-
Core-IO (Java)
- Complete Import/Export pipe with transformers
- Ideal for swapping storage backend
-
CSV importer
- User facing import
-
Bulk Import Framework
- High speed import
- Bulk mode / optimized Transaction management
- Samples with different models
Blobs
-
Blobs can be "pre-imported"
-
pre-fill BlobStore / S3 bucket
-
pre-fill BlobStore / S3 bucket
-
Use async computation
- previews and pictures conversions

Performance
IO Bound / depend on backend
Single Server
6 core HT 3.5Ghz
126 GB RAM
std hdd



Nuxeo REST API
Flexible, Extensible, Composable
Why API is Key for us
-
Nuxeo Repository is a
backend
-
Portals, Mobile Apps, ERP, CRM ...
-
Portals, Mobile Apps, ERP, CRM ...
- API is
UI
- for the developers
- HTML5/JS


API Challenge
"
One API
"
but
Multiple
combinations
of
services, plugins
and Domain Models

Expose a Platform: not an application
developers using the platform
want to expose the API of
their Application
API Challenge
-
Flexible
- Adapt to client requirements
- Adapt to client requirements
-
Extensible
- Enable adding new API
- Enable adding new API
-
Composable
- Expose application specific API
DESIGN Principles
- Do not lose our soul
-
fight to keep the dynamicity of the platform!
-
fight to keep the dynamicity of the platform!
- Be practical
-
Useful is more important than Rest integrism
-
Useful is more important than Rest integrism
-
Dogfooding is key
-
if this is not good enough internally, this is not good
-
if this is not good enough internally, this is not good
-
Building API is part of the development cycle
-
adding http API should never be a task for later
-
adding http API should never be a task for later

Expose simple resources

EXPOSE SIMPLE RESOURCES

Get a Document
GET /nuxeo/api/v1/path/movies/star-wars HTTP/1.1{
"entity-type": "document",
"repository": "default",
"uid": "5b352650-e49e-48cf-a4e3-bf97b518e7bf",
"path": "/movies/star-wars",
"type": "MovieCollection",
"isCheckedOut": true,
"title": "Star Wars",
"facets": [
"Folderish"
]
}Server returns a minimal payload
Adaptative marshaling
Client need to control what data schemas are sent


Adaptative marshaling
- Control what data schemas are sent to the client
GET /nuxeo/api/v1/path/movies/star-wars HTTP/1.1
X-NXProperties dublincore, common
{
"entity-type": "document",
"repository": "default",
"uid": "5b352650-e49e-48cf-a4e3-bf97b518e7bf",
"path": "/movies/star-wars",
"type": "MovieCollection",
"isCheckedOut": true,
"title": "Star Wars",
"properties": {
...
"common:icon": "/icons/movieCollection.png",
"dc:description": "Star Wars collection",
"dc:creator": "tiry",
"dc:modified": "2015-10-22T02:12:59.07Z",
"dc:lastContributor": "tiry",
"dc:created": "2015-10-22T02:12:59.07Z",
"dc:title": "Star Wars",
...
"dc:contributors": [tiry, "system" ]
},
"facets": [
"Folderish"
]
}Fetching CONTEXTUAL data
- Client may require more data
- get Document children at the same time
- get the breadcrumb data
- get thumbnail or preview url
-
...
-
Client ask for the data
- using Headers
- using Query String parameters

Fetching CONTEXTUAL data

Marshaling registry is pluggable
custom Enrichers can be contributed
"How the data is fetched"
is a server side matter
Fetching CONTEXTUAL data
GET /nuxeo/api/v1/path/movies/star-wars HTTP/1.1
X-NXenrichers.document: thumbnail
{
"entity-type": "document",
"repository": "default",
"uid": "5b352650-e49e-48cf-a4e3-bf97b518e7bf",
"path": "/movies/star-wars",
"type": "MovieCollection",
"isCheckedOut": true,
"title": "Star Wars",
"contextParameters":
{
"thumbnail":
{
"url": "/nuxeo/nxthumb/default/5b352650-e49e-48cf-a4e3-bf97b518e7bf/thumb:thumbnail/Small_photo.jpg"
}
},
"facets": [
"Folderish"
]
}GET /nuxeo/api/v1/path/movies/star-wars?enrichers.document=thumbnail HTTP/1.1
Retrieve Linked Data
-
Resolve entity fields
- pointing to a label
- pointing to an other Document
- pointing to a User
- ...
Implicit JOIN

Retrieve Linked Data
-
Use client side parameter to know what to resolve
- header
-
QueryString parameter
-
Can be recursive
- client need to control that too!
fetch.objectType=fieldToFetch
translate.objectType=fieldToTranslate
depth=childrenRetrieve Linked Data

Adapters
- Change the return type
- get only ACLs or History info about the Document
-
get the tasks associated to document
- Use your own business object
-
use business Adapters
- wrap document or documents
- provide custom marshaling
-
use business Adapters
GET /nuxeo/api/v1/path/movies/star-wars@acl HTTP/1.1GET /nuxeo/api/v1/path/movies/star-wars@audit HTTP/1.1GET /nuxeo/api/v1/path/movies/star-wars@bo/MyBusinessObject HTTP/1.1Adapters

Adapters
{
entity-type: "MovieCollection"
id: "5b352650-e49e-48cf-a4e3-bf97b518e7bf",
"title": "Star Wars"
"episodes": 7
}GET /nuxeo/api/v1/path/movies/star-wars@bo/MovieCollection HTTP/1.1Blobs
-
Sent as links
- Digest
-
CDN
-
Uploaded out-of-band
- chunking
- reference in JSON


Blob Upload
-
Upload EndPoint
- Reference Blobs from JSON Payload
{"entity-type": "document",
"properties": {
{
"file:content" : {
"upload-batch' : "0b0061d48f69b072",
"upload-fileId" : 0,
"type" : "blob"
}
}} POST /api/v1/upload/{batchId}/{fileIdx} HTTP 1.1
X-Upload-Chunk-Index 0
X-Upload-Chunk-Count 5PUT /nuxeo/api/v1/path/movies/star-wars HTTP/1.1Need a way to map 100+ Services
Without creating 100 endpoints!
Need an other paradigm !
Command synopsis
Command
INPUT
(Doc, Blob, User ...)
OUTPUT
(Doc, Blob, User ...)
Parameters
Context
(User, Doc ...)
Commands
WebUI.AddErrorMessage WebUI.AddInfoMessage WebUI.AddMessage Document.AddPermission Document.AddToCollection DocumentMultivaluedProperty.addItem Task.ApplyDocumentMapping Blob.AttachOnDocument BlobHolder.AttachOnCurrentDocument AttachFiles Audit.QueryWithPageProvider Blob.ImportClipboard Blob.ImportWorklist Blob.RunConverter Document.BlockPermissionInheritance WorkflowModel.BulkRestartInstances Business.BusinessCreateOperation Business.BusinessFetchOperation Business.BusinessUpdateOperation Navigation.GoBack WorkflowInstance.Cancel Navigation.ChangeCurrentTab Document.CheckIn Document.CheckOut Update.NextStep.ConditionalFolder WebUI.ClearClipboard WebUI.ClearSelectedDocuments WebUI.ClearWorklist WorkflowTask.Complete Blob.ConcatenatePDFs Context.FetchDocument Context.FetchFile Blob.ToPDF Blob.Convert Document.Copy Document.Create FileManager.Import UserWorkspace.CreateDocumentFromBlob Seam.CreateDocumentInUI Picture.Create Document.CreateLiveProxy Document.AddRelation Collection.Create Workflow.CreateRoutingTask Task.Create Directory.CreateEntries Document.Delete Document.DeleteRelation Directory.DeleteEntries WebUI.DestroySeamContext Repository.GetDocument Document.Export WebUI.DownloadFile Blob.ExportToFS Document.FetchByProperty Blob.CreateFromURL FileManager.ImportInSeam FileManager.ImportWithMetaData FileManager.ImportWithMetaDataInSeam Document.Filter Document.FollowLifecycleTransition Comment.Moderate Document.GetBlobs Document.GetChild Document.GetChildren Document.GetBlob Document.GetBlobsByProperty User.GetUserWorkspace Document.GetLinkedDocuments Proxy.GetSourceDocument User.Get Document.GetParent Context.GetEmailsWithPermissionOnDoc Context.GetTaskNames Context.GetUsersGroupIdsWithPermissionOnDoc Document.GetVersions Directory.Projection Collection.Suggestion User.GetCollections Directory.Entries Directory.SuggestEntries Collection.GetDocumentsFromCollection Favorite.GetDocuments Document.Routing.GetGraph Picture.GetView Workflow.GetOpenTasks Tag.Suggestion Task.GetAssigned UserGroup.Suggestion Document.GetRendition Blob.PostToURL Image.Blob.Resize WebUI.InitSeamContext JsonStack.ToggleDisplay Actions.GET GetRepositories Document.Lock Log Audit.LogEvent Auth.LoginAs Auth.Logout Document.Move Document.PublishToSections NRD-AC-PR-ChooseParticipants-Output NRD-AC-PR-LockDocument NRD-AC-PR-UnlockDocument NRD-AC-PR-ValidateNode-Output NRD-AC-PR-force-validate NRD-AC-PR-storeTaskInfo WebUI.NavigateTo NuxeoDrive.SetActiveFactories NuxeoDrive.AddToLocallyEditedCollection NuxeoDrive.AttachBlob NuxeoDrive.CanMove NuxeoDrive.CreateFile NuxeoDrive.CreateFolder NuxeoDrive.CreateTestDocuments NuxeoDrive.Delete NuxeoDrive.FileSystemItemExists NuxeoDrive.GenerateConflictedItemName NuxeoDrive.GetRoots NuxeoDrive.GetChangeSummary NuxeoDrive.GetChildren NuxeoDrive.GetClientUpdateInfo NuxeoDrive.GetFileSystemItem NuxeoDrive.GetTopLevelFolder NuxeoDrive.GetTopLevelChildren NuxeoDrive.Move NuxeoDrive.SetSynchronization NuxeoDrive.Rename NuxeoDrive.SetVersioningOptions NuxeoDrive.SetupIntegrationTests NuxeoDrive.TearDownIntegrationTests NuxeoDrive.UpdateFile NuxeoDrive.WaitForElasticsearchCompletion NuxeoDrive.WaitForAsyncCompletion Repository.PageProvider Context.PopDocument Context.PopDocumentList Context.PopBlob Context.PopBlobList Document.PublishToSection Context.PullDocument Context.PullDocumentList Context.PullBlob Context.PullBlobList Context.PushDocument Context.PushDocumentList Context.PushBlob Context.PushBlobList WebUI.AddToClipboard WebUI.PushDocumentToSeamContext WebUI.AddToWorklist LocalConfiguration.PutSimpleConfigurationParameters LocalConfiguration.PutSimpleConfigurationParameter Repository.Query Audit.Query Repository.ResultSetPageProvider WebUI.RaiseSeamEvents Blob.ReadMetadata Context.SetMetadataFromBlob Directory.ReadEntries WebUI.Refresh WebUI.Refresh Document.RemoveACL Services.RemoveDocumentTags Document.RemoveEntryOfMultivaluedProperty Blob.RemoveFromDocument Document.RemovePermission Document.RemoveProperty Collection.RemoveFromCollection Render.Document Render.DocumentFeed TemplateProcessor.Render Document.ReplacePermission Document.Reload Picture.Resize Context.RestoreDocumentInput Context.RestoreDocumentsInput Context.RestoreBlobInput Context.RestoreBlobsInput Document.RestoreVersion Context.RestoreBlobInputFromScript Context.RestoreBlobsInputFromScript Context.RestoreDocumentInputFromScript Context.RestoreDocumentsInputFromScript Repository.ResultSetQuery Document.Routing.Resume.Step Workflow.ResumeNode Counters.GET RunOperation RunDocumentOperation Context.RunDocumentOperationInNewTx RunFileOperation RunOperationOnList RunOperationOnProvider RunOperationOnListInNewTx RunInputScript RunScript WebUI.RunOperationInSeam Document.Save Seam.SaveDocumentInUI Repository.SaveSession SeamActions.GET Document.Mail Event.Fire Document.AddACE Context.SetVar Context.SetInputAsVar LocalConfiguration.SetSimpleConfigurationParameterAsVar Document.Routing.SetRunningStepFromTask Document.SetBlob Document.SetBlobName WebUI.SetJSFOutcome Workflow.SetNodeVariable Document.Routing.Step.Done Document.Routing.BackToReady Document.Routing.EvaluateCondition Context.SetWorkflowVar WebUI.ShowCreateForm Document.CreateVersion Context.StartWorkflow Search.SuggestersLauncher Services.TagDocument Traces.Get Traces.ToggleRecording Document.SetMetadataFromBlob Seam.GetChangeableDocument Seam.FetchFromClipboard Seam.GetCurrentDocument Seam.GetCurrentDomain Seam.GetCurrentWorkspace Seam.FetchDocument Seam.GetSelectedDocuments Seam.GetDocumentsFromSelectionList Seam.FetchFromWorklist Document.Unlock Document.UnblockPermissionInheritance Services.UntagDocument Document.Update Document.SetProperty Document.Routing.UpdateCommentsInfoOnDocument Directory.UpdateEntries Workflow.UserTaskPageProvider VersionAndAttachFile VersionAndAttachFiles Blob.SetMetadataFromDocument Blob.SetMetadataFromContext Blob.CreateZip acceptComment addCurrentDocumentToWorklist blobToPDF cancelWorkflow conditionalTask decideNextStepAndSimpleValidate downloadFilesZip evaluateCondition followLifeCycleTransition followLifeCycleTransitionTask initInitiatorComment logInAudit nextAssignee notifyInitiatorEndOfWorkflow publishDocument publishTask reinitAssigneeComment rejectComment Workflow.RemoveRoutingTask sendTaskCreatedNotificationMail setDone setNextStep setTaskDone simpleChooseNextOption1AndDone simpleChooseNextOption2AndDone simpleRefuse simpleTask simpleUndo simpleValidate terminateWorkflow undoRunningTask updateCommentsOnDoc validateDocument voidChain xmlExportRendition zipTreeExportRendition
Favorite.GetDocumentsBlob.ToPDFImage.Blob.ResizeDocument.AddRelationWorkflow.CreateRoutingTasklot of contributed operations
Principles
Commands as REST resources
-
GET to retrieve definition
-
POST to execute

Get an Operation
GET /nuxeo/api/v1/automation/Document.PageProvider HTTP/1.1HTTP/1.1 200 OK
Content-Type: application/json
{
"id":"Document.PageProvider",
"label":"PageProvider",
"description":"Perform a query ...",
"signature":[ "void", "documents" ],
"params":[
{ "name":"page",
"type":"integer",
"required":false
},{
"name":"query",
"type":"string",
"required":false, },
... ]
}Get an Operation

Run an Operation
POST /nuxeo/api/v1/automation/Document.PageProvider HTTP/1.1
Content-Type: application/json+nxrequest
{ "params" :
{ "query" : "select * from Note",
"page" : 0
}
}HTTP/1.1 200 OK
Content-Type: application/json
{
"entity-type": "documents",
"pageIndex": 0,
"pageSize": 2,
"pageCount": 2,
"entries": [
{
"entity-type": "document",
"repository": "default",
"uid": "3f76a415-ad73-4522-9450-d12af25b7fb4",
...
}, { ...}, ...
]
}Resources & Automation
- Share the
marshaling layer and
extension
-
Enrichers, Resolvers are available too
-
Enrichers, Resolvers are available too
-
Compose Resources and Automation API
- Pipe Resources as input for Automation Operation
> cat /doc/path/somedoc | command(p3,p4)Resources & Automation
RESOURCES > AUTOMATION
POST /nuxeo/api/v1/path/somePath/@op/Blob.ToPDF HTTP/1.1HTTP/1.1 200 OK
Content-Type: application/pdf
...More Composition
assemble API blocks without having to code
build business API
Composable API : GOALS
-
Tailor the API to match application requirements
-
one API behind every action / button
-
one API behind every action / button
- Allow
business analysts or
UI developers to tailor the API
- define what API is exposed
- UI & Workflow needs
- define what API is exposed

Automation Chain

- Assemble operations in a chain
- Pipe Output / Input
- Give it a name
- Call and execute within a
single transaction
Server side assembly
One Context
Assembling Chains

It does work !
-
Business users & Front end developers leverage this
- to expose custom API for their UI
- to build custom logic inside their Workflows
- to add automatic processing (listeners)
-
Actually it
works almost
too well
- users do awfully complicated things
- chains calling chains calling chains ...




Scalability
Scale out Architecture

Scale Interactive Processing

Scale Batch Processing

Scale
Queries

Scale out Storage

Scale Storage
with NoSQL

HA / Multi-AZ
Geographical redundancy & disaster recovery
Mono-AZ deployment

(Manual) Multi-AZ deployment

AWS Multi-AZ deployment

NoSQL Multi-AZ deployment

Extreme Storage
Supercharging Nuxeo Repository
About Large Binary files
-
No impact on Repository performances
- Link (digest) to the Stream stored in Blob Manager
- Blob upload is done out of transaction
-
Download
- http streaming
- CDN integration
-
Upload
- chunking & resume on upload
-
Processing on large files
can be off-loaded
About LARGE Binary Storage
- Backend storage is pluggable
- several implementations (FS, S3, GridFS, GDoc, DropBox ...)
- easy to implement
- Can do partitions
- Can do HSM
Large Documents
- Nuxeo Repository does handle arbitrary complex Schemas
- but humans don't
-
CRUD operations
-
SQL: impact due to the number of columns / tables
- can be tweaked with lazy-loading & prefetch
- NoSQL: no real impact on Read/Write, minor on update
-
SQL: impact due to the number of columns / tables
-
Search operations
- Elasticsearch can handle complex queries on complex documents
- Can Scale-Out Elasticsearch as needed
Massive number of Documents
-
CRUD operations
- SQL: Lot of rows => Need Sharding
- NoSQL: MongoDB is happy with Billions of Documents
-
Search operations
- Can Scale-Out Elasticsearch as needed

KEY Limitations of SQL - search
-
Complex SQL Queries
- Configurable Data Structure
-
User defined
multi-criteria searches
-
Scaling queries is complex
- depend on indexes, I/O speed and available memory
-
poor performances on unselective multi-criteria queries
-
Fulltext support is usually poor
- limitations on features & impact on performances
SELECT "hierarchy"."id" AS "_C1" FROM "hierarchy"
JOIN "fulltext" ON "fulltext"."id" = "hierarchy"."id"
LEFT JOIN "misc" "_F1" ON "hierarchy"."id" = "_F1"."id"
LEFT JOIN "dublincore" "_F2" ON "hierarchy"."id" = "_F2"."id"
WHERE
("hierarchy"."primarytype" IN ('Video', 'Picture', 'File'))
AND ((TO_TSQUERY('english', 'sydney')
@@NX_TO_TSVECTOR("fulltext"."fulltext")))
AND ("hierarchy"."isversion" IS NULL)
AND ("_F1"."lifecyclestate" <> 'deleted')
AND ("_F2"."created" IS NOT NULL )
ORDER BY "_F2"."created" DESC
LIMIT 201 OFFSET 0;
some types of queries
can
simply
not be fast in SQL
KEY Limitations of SQL - CRUD
-
Impedance issue
- storing Documents in tables is not easy
-
requires
Caching and
Lazy
loading
-
Scalability
- Document repository and Audit Log can become very large (versions, workflows ...)
-
scaling out SQL DB is complex (and never transparent)
-
Concurrency model
- Heavy write is an issue (Quotas, Inheritance)
- Hard to maintain good Read & Write performances

USING NOSQL
-
No Impedance issue
- One Nuxeo Doc = One MongoDB Document
-
No application level cache / no invalidations
-
No Scalability issue for CRUD
-
native distributed architecture with scale out
-
native distributed architecture with scale out
-
No Concurrency performance issue
- Document Level "Transactions"
Repository & Audit Trail
-
Fast indexing
-
No ACID constraints / No impedance issue
-
Append only index
-
-
Super query performance
-
query on term using inverted index
-
very efficient caching
-
native full text support
-
distributed architecture
-
Search & Audit Trail
Hybrid Storage Architecture
-
MongoDB
-
store structure & streams in a BASE way
-
-
elasticsearch
-
provide powerful and scalable queries
-
-
SQL DB
-
store structures in an ACID way
-
Storage does not impact application : this can be a deployment choice!
A
tomic
C
onsistent
I
solated
D
urable
B
asic
A
vailability
S
oft state
E
ventually consistent
depends on Availability & Performances requirements
HUGE Repository WITH NOSQL
-
Massive amount of Documents
-
x00,000,000
-
Automatic versioning
-
create a version for each single change
-
create a version for each single change
-
x00,000,000
-
Write intensive access
- daily imports or updates
-
recursive updates
(quotas, inheritance)
SQL DB collapses
(on commodity hardware)
MongoDB handles the volume

About MongoDB & Consistency
- Atomic Document Operations are safe
-
Large batch updates is not so much of an issue
- Multi-documents transactions are an issue
- ex: Workflows
Transactions can not span across multiple documents
-
Transient State Manager
- Run all operations in Memory
- Populate an Undo Log
- Recover Commit / Rollback model
Elasticsearch & Consistency
-
Async Indexing :
- ensure convergeance
- ensure convergeance
-
Sync indexing :
- see changes in listings in "real time"

Should I Worry about Jepsen resultS ?
- Maintaining availability during network partition is hard
-
Distributed system try to stay available
- and sometimes give access to staled data or loose updates
-
Standard ACID DB (SQLDB , MarkLogic) do not even try
- so application become unavailable
- so application become unavailable
-
Distributed system try to stay available
-
Aphyr built a great testing system (Jepsen)
- testing opensource distributed system during network partitions
- helps improving solutions & documentation
-
Currently all distributed systems break at some points
- Cassendra, Riak, Redis, Aerospike, NuoDB, Elasticsearch, etcd, ...
- MongoDB is probably just the most visible one (and has evolved since)
- Even PGSQL or MySQL have issues in some cases
Hybrid storage

Sample use case:
Press Agency
production system
mixed
requirements
Security
Understanding Nuxeo Security
Security in the Repository
- Security is always on
- Java API / Http API / Search
- Java API / Http API / Search
-
ACL based default security policy
- multiple & ordered ACLs
- ACL inheritance or block
-
validity dates on ACE
- additional pluggable security policy
- implement custom security
(ex: meta-data based)
- implement custom security

Security CONTEXT
- Security is evaluated in a Context
- a Document
- Security is placeful
- a User
- attributes (or profiles)
- groups
- a Document
- ACLs give or deny permission in a Context
- Atomic permissions
- Groups of permissions
- Custom permissions
Permissions
-
Nuxeo defines a set of Atomic permissions
-
Nuxeo defines groups of permissions
-
Repository always checks the Atomic permissions
-
You can define custom permissions and groups of permissions
-
You can use Core API to check permissions explicitly
READ_PROPERTIES, ADD_CHILDREN, READ_LIFECYCLE ...READ, WRITE, MANAGE ...session.hasPermission(Document, Perm)Security in UI & Services

(also available in Directories)
Security Granularity
-
Security is checked at Document Level
-
field/schemas do not hold ACLs
-
-
No field level security
-
Download action is checked by a custom Download Policy
-
depending on Document, File, XPath, User
-
-
Can view document meta-data without being able
to download or preview

Security Granularity
-
Compound Documents
-
use nested documents with different ACLs
-
Handle finer grained security
-
-
Custom API for custom visibility
-
Leverage Custom indexing in Elasticsearch
-
Custom marshaling layer in the Rest API
-
Expose data that would otherwise not be accessible
-

Handling Complex Security
-
ACL based
-
Computed Groups
-
i.e. compute groups based on user attributes
-
-
Automatically apply ACLs
-
i.e. Listeners and Automation
-
-
Complex to manage, test and update
-
-
Security Policies
-
Integrate custom logic at the core of the security system
-
Initially introduced for "military" use cases
-
Low administration + Good testability
-
Security Policy
-
Atomic permission check: Checkperm
-
Override or complement ACL based security
-
Java Based logic to Grant/Access based on
-
Document (including attributes)
-
User (including attributes)
-
-
-
Search security filtering: QueryTransformer
-
Avoid post-filtering in search
-
generate additional where clause
-
-
Allows custom security to scale with large queries
-
Directory Abstraction

Security Content vs Origin

Security Content vs Origin

Authentication
-
Nuxeo provides a pluggable Authentication system
- Basic Auth, Form, Token, Kerberos,OAuth,
- OpenId, CAS2, Shibboleth, SAML2, ...
- Keycloak, Okta, DuoWeb
Nuxeo Event Bus
Listeners & Queues
Nuxeo Event Bus
-
Nuxeo fires events for all actions
- Document Create / Update / Delete
- Workflow starts
- User logged in
-
Events can be listened by
-
By synchronous inline listeners
- intercepts ongoing action
- can block / rollback processing
-
By asynchronous listener
- transaction events bundle
-
By synchronous inline listeners
- Scheduled asynchronous worker are persisted
Nuxeo Event Bus

Example: ES Indexing
Audit Service

Custom Audit
- Audit log is customizable
- choice of events to track
- what information to log with event
- where to log
the only limit is storage !
- When using a NoSQL backend, it is easy to
- Store all changes for all Documents
- Store per-transaction changes
Current Event Bus

Target Event Bus (8.10+)

Target Gains
- Redis / Kafka switch
- High throughput resilient queuing
-
Better bulk import
-
Custom Audit Queuing
-
More efficient Audit log
-
More efficient Audit log
-
Plug Nuxeo Event Bus
- Batch Notifications
- Activities
- Reactive UI
Monitoring
Scale out Architecture
Monitoring Nuxeo
- Integrate Coda Hale Yammer Metrics
-
Nuxeo exposes core metrics
- repository activity
- transactions
- async jobs
- elasticsearch
- ...
-
Can deploy
application specific metrics
-
Metrics are exposed via JMX
- can be exposed via Http too

Graphite Dashboard
Provide sample dashboard for Graphite


Nuxeo
Metrics
System
Metrics
DataDog Dashboard
Integrate with DataDog


Nuxeo & AWS
Deploying Nuxeo on AWS
Nuxeo LogicaL architecture

Leverage AWS Services

Leverage AWS Services
API driven provisioning and deployment
transparent fail-over
easy scalability
Deploy on AWS
-
AMI
- Use Linux AMI + Debian Packages + Nuxeo Packages
-
Build custom AMI with Packer
-
CloudFormation
-
Template to provision and deploy Nuxeo
-
Template to provision and deploy Nuxeo
-
Ansible
- Highly customized Nuxeo deployment
- Highly customized Nuxeo deployment
-
Terraform
- Infrastructure as Code + independence from IaaS



Leverage AWS Services

Multi-tenAncy
Isolated configuration in Nuxeo
Requirement

APPLICATION LEVEL MULTI-TENANTS

Document Store
Security
Life Cycle
Indexing
Versioning
all clients share the same application
application manages data and configuration partitionning
Application Level Multi-Tenants
Shallow isolation
- quota management is not efficient
-
customization options are limited
Monolithic
- same version, same component set
-
same
upgrade and maintenance policy
Not even simple
- scale out is not that easy (i.e. move a tenant)
- per-tenant Backup/Restore is not easy
-
Heterogeneous
deployment units
VM level / JVM level / App level



Can not leverage
OSGi / Extension Point model
Not
"Cloud Native approach"

Container Level Multi-tenants
rely on infrastructure to provide tenants isolation
application does not need to be impacted

Flexible
Unlimited
Customization
Full
Isolation &
Quotas
Application Factory

Create "on demand" application for each customer
- use Container level isolation
- provision infrastructure from the Cloud
- custom assembly for each customer

Build Your Own Application
Deploy & Run !
nuxeo.io
-
nuxeo.io v1
- Build on a very young Docker ecosystem
- Docker / CoreOS / Fleet
-
Lot of custom glue
-
nuxeo.io v2
- Align on all the converging work on Docker
- Focus on Nuxeo specific requirements
- Docker / Swarm / Rancher
Nuxeo.io v1

Nuxeo.io v2 - Rancher

Nuxeo.io with Rancher

Roadmap
What we are working on
http://roadmap.nuxeo.com/

From RoadMAP to Jira
-
Roadmap items are associated to Jira Epics Repository
- Jira is public : https://jira.nuxeo.com/browse/NXP
- You can track and comment issues
- Issues are assigned to a dev and associated to a target release
-
GitHub is an other way to track our progress
- All Commits are associated with Jira Issues
- All main features are available in separated branches
Comments,
Any Questions ?
Thank You !
Architecture Overview
By Thierry Delprat




