Supercharging
Your Content Management Stack with MongoDB & Elasticsearch

Thierry Delprat
Agenda
-
Quick introduction
-
provide some context
-
provide some context
-
Why moving to Not Only SQL
-
explain the problems and the solutions we choose
-
explain the problems and the solutions we choose
-
Technical integration of MongoDB & Elasticsearch
-
describe how we make it work
-
describe how we make it work
-
Resulting hybrid storage architecture
- use cases and performances
Some Context
What we Do and What Problems We Try to Solve

Nuxeo
-
Nuxeo
- we provide a Platform that developers can use to build highly customized Content Applications
- we provide components, and the tools to assemble them
-
everything we do is open source (for real)
- various customers - various use cases
- me: developer & CTO - joined the Nuxeo project 10+ years ago


Track game builds
Electronic Flight Bags
Central repository for Models
Food industry PLM
https://github.com/nuxeo

CONTENT REPOSITORY

Scalability Challenges
-
Queries are the first scalability issue
-
Massive Writes
- History tracking generating huge volumes

History : Nuxeo repository
-
2006: Nuxeo Repository is based on ZODB (Python / Zope based)
-
2007: Nuxeo Platform 5.1 - Apache JackRabbit (JCR based)
-
2009: Nuxeo 5.2 - Nuxeo VCS - pure SQL
-
2013/2014: Nuxeo 5.9 - Nuxeo DBS + Elasticsearch
Object DB
Document DB
SQL DB
Not only SQL
But why is SQL not enough ?
From Sql to Not only SQL
Understanding the motivations
SQL based Repository - VCS

ACID
XA
KEY Limitations of SQL - search
-
Complex SQL Queries
- Configurable Data Structure
-
User defined multi-criteria searches
-
Scaling queries is complex
- depend on indexes, I/O speed and available memory
-
poor performances on unselective multi-criteria queries
-
Fulltext support is usually poor
- limitations on features & impact on performances
SELECT "hierarchy"."id" AS "_C1" FROM "hierarchy"
JOIN "fulltext" ON "fulltext"."id" = "hierarchy"."id"
LEFT JOIN "misc" "_F1" ON "hierarchy"."id" = "_F1"."id"
LEFT JOIN "dublincore" "_F2" ON "hierarchy"."id" = "_F2"."id"
WHERE
("hierarchy"."primarytype" IN ('Video', 'Picture', 'File'))
AND ((TO_TSQUERY('english', 'sydney')
@@NX_TO_TSVECTOR("fulltext"."fulltext")))
AND ("hierarchy"."isversion" IS NULL)
AND ("_F1"."lifecyclestate" <> 'deleted')
AND ("_F2"."created" IS NOT NULL )
ORDER BY "_F2"."created" DESC
LIMIT 201 OFFSET 0; some types of queries can simply
not be fast in SQL
KEY Limitations of SQL - CRUD
-
Impedance issue
- storing Documents in tables is not easy
-
requires Caching and Lazy loading
-
Scalability
- Document repository and Audit Log can become very large (versions, workflows ...)
-
scaling out SQL DB is complex (and never transparent)
-
Concurrency model
- Heavy write is an issue (Quotas, Inheritance)
- Hard to maintain good Read & Write performances

When SQL starts needing help
- Challenging use cases
- 500+ complex queries /seconds
- 20+ Millions of Documents
- daily batches impacting 100 000+ Documents
- complex data models generating 200+ tables
-
keep complete history for several years
-
Challenging organization
- poor SQL infrastructure
- DBA low skills
Need to leverage different storage models
Not Only SQL
USING Mongodb
-
No Impedance issue
- One Nuxeo Document = One MongoDB Document
-
No application level cache / no invalidations
-
No Scalability issue for CRUD
-
native distributed architecture allows scale out
-
native distributed architecture allows scale out
-
No Concurrency performance issue
- Document Level "Transactions"
Good candidate for the Repository & Audit Trail
USING Elasticsearch
-
Fast indexing
-
No ACID constraints / No impedance issue
-
Append only index
-
-
Super query performance
-
query on term using inverted index
-
very efficient caching
-
native full text support & distributed architecture
-
- Good for write once / read many use cases
Good candidate for the Search & Audit Trail
Just Plug MongoDB and Elasticsearch?
... argh !
Target Architecture

And yes, it does work
let's see the technical details

Integrating NOSQL
MongoDB and Elasticsearch at work
Mongodb Repository

Storing Nuxeo Documents in MongoDB
{
"ecm:id":"52a7352b-041e-49ed-8676-328ce90cc103",
"ecm:primaryType":"MyFile",
"ecm:majorVersion":NumberLong(2),
"ecm:minorVersion":NumberLong(0),
"dc:title":"My Document",
"dc:contributors":[ "bob", "pete", "mary" ],
"dc:created": ISODate("2014-07-03T12:15:07+0200"),
...
"cust:primaryAddress":{
"street":"1 rue René Clair", "zip":"75018", "city":"Paris", "country":"France"},
"files:files":[
{ "name":"doc.txt", "length":1234, "mime-type":"plain/text",
"data":"0111fefdc8b14738067e54f30e568115"
},
{
"name":"doc.pdf", "length":29344, "mime-type":"application/pdf",
"data":"20f42df3221d61cb3e6ab8916b248216"
}
],
"ecm:acp":[
{
name:"local",
acl:[ { "grant":false, "perm":"Write", "user":"bob"},
{ "grant":true, "perm":"Read", "user":"members" } ]
}]
...
}-
40+ fields by default
- depends on config
- 18 indexes
hIERARCHY & Security
- Parent-child relationship
-
Recursion optimized through array
ecm:parentId
ecm:ancestorIds
{ ... "ecm:parentId" : "3d7efffe-e36b-44bd-8d2e-d8a70c233e9d",
"ecm:ancestorIds" : [ "00000000-0000-0000-0000-000000000000",
"4f5c0e28-86cf-47b3-8269-2db2d8055848",
"3d7efffe-e36b-44bd-8d2e-d8a70c233e9d" ] ...}- Generic ACP stored in ecm:acp field
- Precomputed Read ACLs to avoid post-filtering on search
ecm:racl: ["Management", "Supervisors", "bob"]{... "ecm:acp":[ {
name:"local",
acl:[ { "grant":false, "perm":"Write", "user":"bob"},
{ "grant":true, "perm":"Read", "user":"members" } ]}] ...}SEARCH
db.default.find({
$and: [
{"dc:title": { $in: ["Workspaces", "Sections"] } },
{"ecm:racl": {"$in": ["bob", "members", "Everyone"]}}
]
}
)SELECT * FROM Document WHERE dc:title = 'Sections' OR dc:title = 'Workspaces'
Consistency Challenges
- Atomic Document Operations are safe
- No impedance issue
-
Large batch updates is not so much of an issue
-
SQL DB do not like long running transactions anyway
-
SQL DB do not like long running transactions anyway
- Multi-documents transactions are an issue
- Workflows is a typical use case
- Isolation issue
- Other transactions can see intermediate states
- Possible interleaving
Find a way to mitigate consistency issues
Transactions can not span across multiple documents
Mitigating consistency issues
-
Transient State Manager
- Run all operations in Memory
- Populate an Undo Log
- Recover partial Transaction Management
-
Commit / Rollback model
-
Commit / Rollback model
-
"Read uncommited" isolation
- Need to flush transient state for queries
- "uncommited" changes are visible to others

Elasticsearch indexing

routing
Challenges
- Handle security filtering
- Without join or post-filtering
-
Manage readACLs
- Keep index in sync with the repository
- Do not try to make it transactionnal
- Do not lose anything
-
Handle recursive indexing
-
Mitigate eventually consistent effect
-
Avoid displaying transient inconsistent state
-
Avoid displaying transient inconsistent state


ASYNC INDEXING FLOW

Mitigate Consistency Issues
-
Async Indexing :
- Collect and de-duplicate Repository Events during Transaction
-
Wait for commit to be done at the repository level
-
then call elasticsearch
-
then call elasticsearch
-
Sync indexing (see changes in listings in "real time"):
-
use pseudo-real time indexing
- indexing actions triggered by UI threads are flagged
- run as afterCompletion listener
- refresh elasticsearch index
-
use pseudo-real time indexing
PSEUDO-SYNC INDEXING FLOW

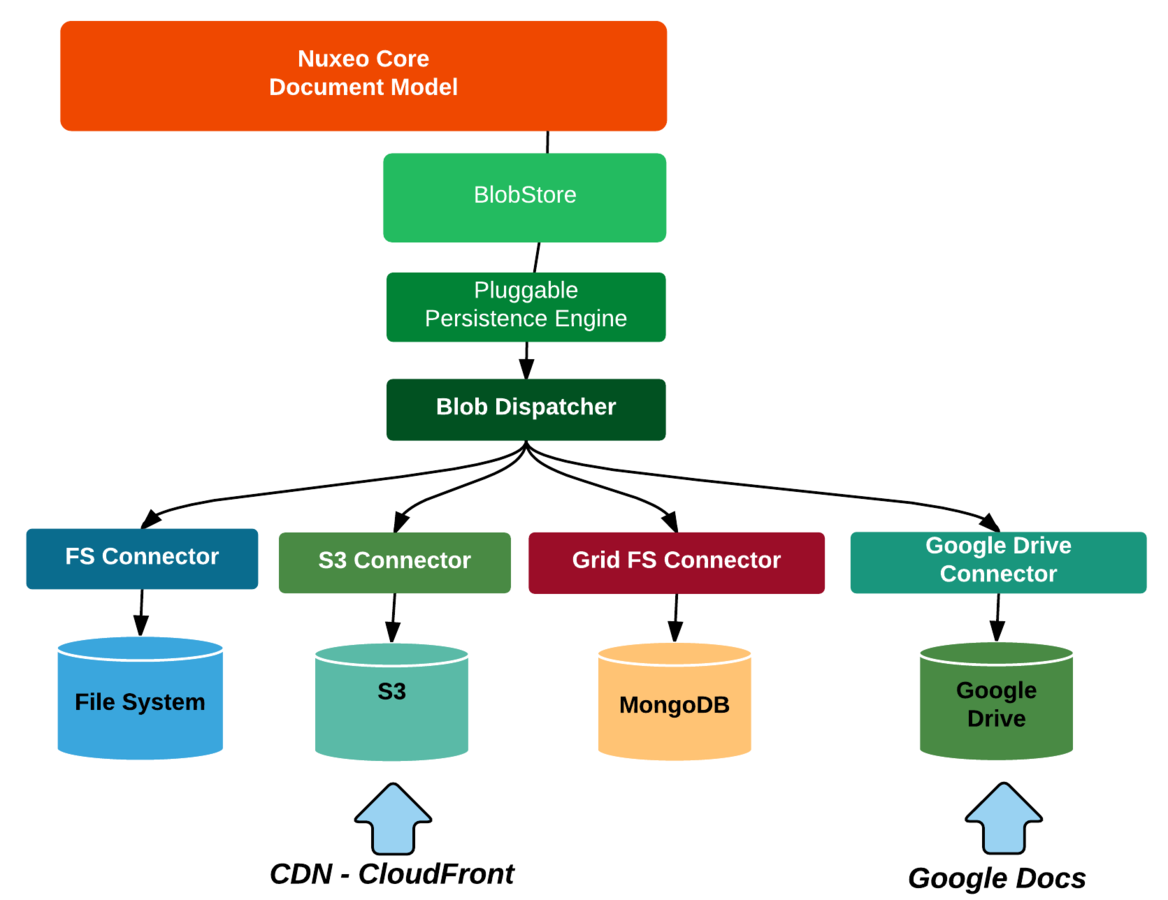
Storing Blobs
Audit

Hybrid Storage
-
Documents properties and hierarchy
-
SQL or MongoDB
-
SQL or MongoDB
-
Documents blobs
-
FileSystem, S3, MongoDB/GridFS, Google Drive
-
FileSystem, S3, MongoDB/GridFS, Google Drive
-
Indexes
-
SQL or MongoDB and elasticsearch
-
SQL or MongoDB and elasticsearch
-
Audit log
- SQL, MongoDB or elasticsearch
It's great to have the choice!
now what ?
Hybrid Storage
Store according to use cases
There is not one unique solution
Does not impact application code: this can be a deployment choice!
-
SQL DB
-
store content in an ACID way
-
strong schema
-
scalability issue for queries & storage
-
-
MongoDB
-
scale CRUD operations
-
store content in a BASE way, schema-less
-
queries are not really more scalable
-
-
elasticsearch
-
powerful and scalable queries
-
flexible schema
-
asynchronous storage
-

Ideal use cases for Elasticsearch
Using Elasticsearch
-
Fast indexing
-
3,500 documents/s when using SQL backend
-
10,000 documents/s when using MongoDB
-
-
Scalability of queries
-
Scale out
-
3,000 queries/s with 1 elasticsearch node
-
6,000 queries/s with 2 elasticsearch nodes
-


USING ELASTICSEARCH
-
Can choose to route queries to ES or Repository
- by code
-
by configuration
-
Can use Elasticsearch to offload & scale out
- queries
- read access

Customer quote on Nuxeo+ES
We are now testing the Nuxeo 6 stack in AWS.
DB is Postgres SQL db.r3.8xlarge which is a a 32 cpus
Between 350 and 400 tps the DB cpu is maxed out.
Please activate nuxeo-elasticsearch !
We are now able to do about 1200 tps with almost 0 DB activity.
Question though, Nuxeo and ES do not seem to be maxed out ?
It looks like you have some network congestion between your client and the servers.
...right... we have pushed past 1900 tps ... I think we are close to declaring success for this configuration ...
Customer
Customer
Customer
Nuxeo support
Nuxeo support
Elasticsearch is by default since 6.0
we keep sync indexing "inside the repository backend"

Ideal use cases for Mongodb
HUGE Repository - Heavy loading
-
Massive amount of Documents
-
x00,000,000
-
Automatic versioning
- create a version for each single change
- create a version for each single change
-
x00,000,000
-
Write intensive access
- daily imports or updates
-
recursive updates (quotas, inheritance)
SQL DB collapses (on commodity hardware)
MongoDB handles the volume

Benchmarking Read + Write


Read & Write Operations
are competing
Write Operations
are not blocked
C4.xlarge (nuxeo)
C4.2Xlarge (DB)
SQL
Benchmarking Mass Import


SQL
with tunning


commodity hardware
SQL
7x faster
Data LOADING Overflow
Processing on large Document sets are an issue on SQL
Side effects of impedance miss match
Ex: Process 100,000 documents
- 750 documents/s with SQL backend (cold cache)
-
9,500 documents/s with MongoDB / mmapv1: x13
-
11,500 documents/s with MongoDB / wiredTiger: x15

lazy loading
cache trashing
Some examples
VOD repository
-
Requirements:
- store videos
- manage meta-data & availability
- manage workflows
- generate thumbs & conversions
- Very Large Objects:
- lots of meta-data (dublincore, ADI, ratings ...)
- Massive daily updates
- updates on rights and availability
- Need to track all changes
- prove what was the availability for a given date
Real life project choosing Nuxeo + MongoDB


good use case for MongoDB
want to use MongoDB
lots of data + lots of updates
Hybrid storage

Sample use case:
Press Agency
production system
mixed
requirements
Next steps
Going further with NoSQL
Next steps
- elasticsearch 2.0 & MongoDB 3.2
- Expose a new Batch API at Nuxeo level
-
leverage MongoDB processing capabilities
-
leverage MongoDB processing capabilities
-
Leverage elasticsearch percolator
- push updates on the nuxeo-drive clients
- notify users about saved search
-
automatic categorization
-
Leverage DBS model: code more storage adapters
- PostgreSQL + JSONB / Cassandra / CouchBase
Any Questions ?
Thank You !
https://github.com/nuxeo
http://www.nuxeo.com/careers/
Supercharging Your Content Management Stack with MongoDB & Elasticsearch
By Thierry Delprat



