NoSQL mix
for a content repository
at scale

Thierry Delprat
tdelprat@nuxeo.com
https://github.com/tiry/
Some Context
Understanding the challenges & use cases

Document Repository
Storing objects (think {JSON} object)
- Schemas
- Streams
- Security
- Search
- Audit
Custom Domain Model
Conversions & Previews
Security Policies
on any field
At SCALE
Application Log
REPOSITORY & Storage Adapters

REPOSITORY & Storage Adapters
Choose storage backends according to challenges

Store Structures
in SQL Database

or store Structures
in MongoDB

store streams
in MongoDB too
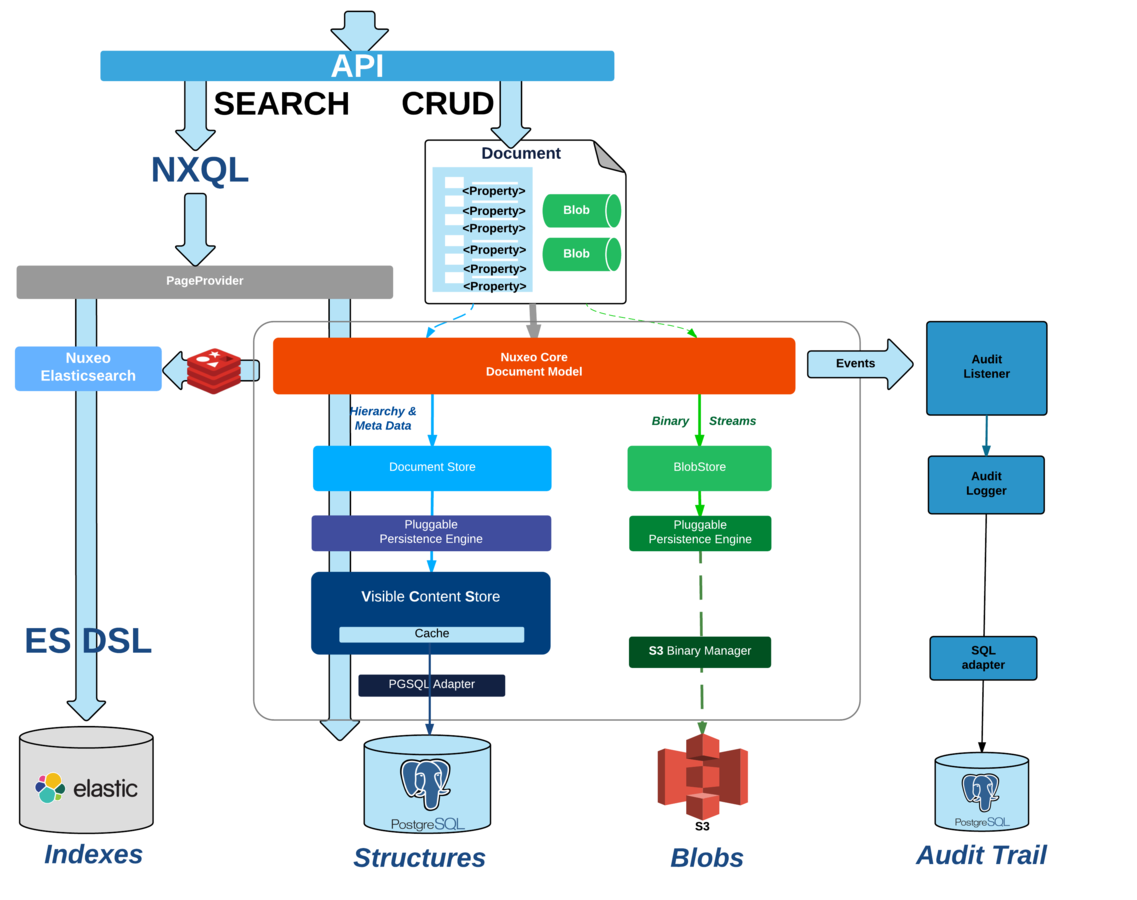
store streams
in S3

Leverage
Google Drive & Google Doc integration
Challenges
Search
Storage / Import
Async processing
SCaling SEARCH
the first challenge
Search everywhere
- Simple search
-
Faceted search
-
Listings and views
- Suggestion widgets




Challenges
-
Dynamic Queries
- depends on Application Model
- depends on User
-
Un-selective queries
-
Performance Challenges
- Large number of documents
- Can not always rely on DBA optimization work
- Poor SQL DB infrastructure
Challenges
-
Dynamic Queries
- depends on Application Model
- depends on User
-
Un-selective queries
-
Performance Challenges
- Large number of documents
- Can not do DBA optimization work
- poor SQL DB
Offload search queries to
Elasticsearch & Repository

One query
Several possible backends
Elasticsearch challenges
-
Asynchronous API
-
Non-transactional API
- Need to recursively index security
Asynchronous batched updates
Ensure we can not lose any update
Async Indexing Flow

Mitigate Consistency Issues
-
Async Indexing
:
- Collect and de-duplicate Repository Events during Transaction
-
Wait for commit to be done at the repository level
-
then call elasticsearch
-
then call elasticsearch
-
Sync indexing
(
see changes in listings in "real time")
:
-
use pseudo-real time indexing
- indexing actions triggered by UI threads are flagged
- run as afterCompletion listener
- refresh elasticsearch index
-
use pseudo-real time indexing
Pseudo-Sync Indexing Flow

ElasticSearch & Nuxeo
-
Offload queries from DB
-
Decouple sizing of search & storage
-
Decouple sizing of search & storage
-
Good performances & Scalability
-
Always faster on complex queries
-
Always faster on complex queries
-
Great search features
- Fulltext
- Aggregates
- Fuzzy search
Scaling Storage
Big document databases and big imports

Giant DataSet
Challenges
Massive Imports
?
Mongo Document Database
No Impedance issue
less backend calls
no invalidation cost
Document level locking
no table level concurrency
Native distributed architecture
Easy scale out of read
MongoDB Challenges
Document level transactions
No MVCC isolation
Provide shared mitigation policies
for critical use cases
Different transaction paradigm
Ensuring consistency
Transient State Manager
Run all operations in Memory
Populate an Undo Log
- Recover
Application level Transaction Management
-
Commit / Rollback model
-
Commit / Rollback model
-
"Read uncommited" isolation
- Need to flush transient state for queries
- "uncommited" changes are visible to others

Is Nuxeo Fast
with mongodb ?
SPEED
Significant RAW Speed improvements for most use cases
More importantly: some use cases are simply better handled

https://benchmarks.nuxeo.com/
More than RAW Performances
Side effects of no-cache
No Cache
Less memory per Connection
More connections
More Concurrent Users
More than RAW Performances
Processing on large Document sets are an issue on SQL
Side effects of impedance miss match
Sample Nuxeo batch on 100,000 documents
750 documents/s with SQL backend
(cold cache)
11,500 documents/s with MongoDB / wiredTiger: x15

lazy loading
cache trashing
MORE THAN RAW PERFORMANCES


Read & Write Operations
are competing
Write Operations
are not blocked
C4.xlarge (nuxeo)
C4.2Xlarge (DB)
SQL
READ + WRITE
Supersize-ME
Side effects of hyper-scaling the repository

Giant Repository
Millions of documents
-
Millions of events
- Millions of Jobs
Indexing Jobs
Conversion Jobs
Audit update
Challenges
-
Distribute jobs across nodes
- Have dedicated nodes
- Make it scale for millions of Jobs
Use shared Queues to manage Jobs
Already used for
Cache & Invalidations
Good match for Complex structures + Atomic API + Speed
Redis WorkManager

Giant ReDIS
-
Billions of documents
-
Billions of events
-
Billions of Jobs
-
Billions of Redis entries
- Memory issues !
-
Billions of Redis entries
-
Billions of Jobs
-
Billions of events
Redis WorkManager

Kafka + Redis

KAFKA + REDIS
- Queue Messages/Actions instead of Jobs
- Minimize redis persistence
-
Optimize processing
- pre-process messages (Audit)
- regroup/batch some updates
Benchmarking this
Results and lessons learned
1B benchmark


Key Figures
Initial import
- Injection: 32,680 docs/s with peak at 40,400 docs/s.
- Indexing: 18,660 docs/s with peak at 27,400 docs/s

https://benchmarks.nuxeo.com/
lessons Learned - MongoDB & ShArding
-
Sharding to leverage multiple nodes
- more nodes = more disks = more IO (at least on AWS)
-
mongod + WiredTiger limits write concurrency to 128 (write tickets)
-
Indexing IO cost increases with volume
-
mitigate by increasing the number of nodes
- 4 nodes => slowdown at 600M / 6 nodes => slowdown at 900M
- 4 nodes => slowdown at 600M / 6 nodes => slowdown at 900M
-
mitigate by increasing the number of nodes
-
Sharding & Queries
- requires query caching - don't mix queries & writes
- requires query caching - don't mix queries & writes
-
Disable chunk balancing when using hash shard key
- avoid erratic re-organization
Lessons Learned
-
UUIDs vs Big Int
- Smaller memory footprint and compact index
-
Faster to generate
-
Handling batch is not optional
- Sequence generation by batch
-
Audit bulk write
- Added stateful scroll api for the repository
-
needed for indexing more than 100M docs !
-
needed for indexing more than 100M docs !
-
Elasticsearch performances
- ES 2.x slower than 1.7 ( index.translog.durability)
- Use a static mapping for speed
1B benchmark
3B benchmark

SOON
https://benchmarks.nuxeo.com/
Deployment
How to deploy that ?
DEPLOYMENT

Nuxeo Cluster
MongoDB Replicaset
ES Cluster
Redis + Sentinel
Kafka Cluster
ZK Cluster
DEPLOYMENT
this is complex !
PaaS & Containers




PaaS & Containers
Makes it easier.
Leverage various storage sub-systems.
Any Questions ?
Thank You !
https://github.com/nuxeo
http://www.nuxeo.com/careers/
NoSQL
By Thierry Delprat
NoSQL
MongoDB + ElasticSearch + Redis + Kafka : NoSQL mix for a content repository at scale




