















Tim Thompson
Manager, Metadata Services Unit, at Yale Library
Manager, Metadata Services Unit
Yale Library
timothy.thompson@yale.edu
www.linkedin.com/in/timathompson
Princeton, New Jersey
March 10, 2025
Catalog card taken from the digital version of the book Documentation made easy.
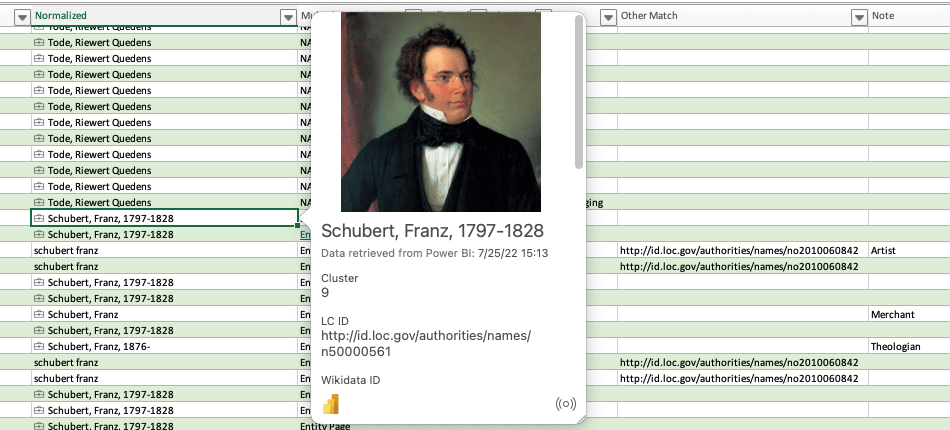
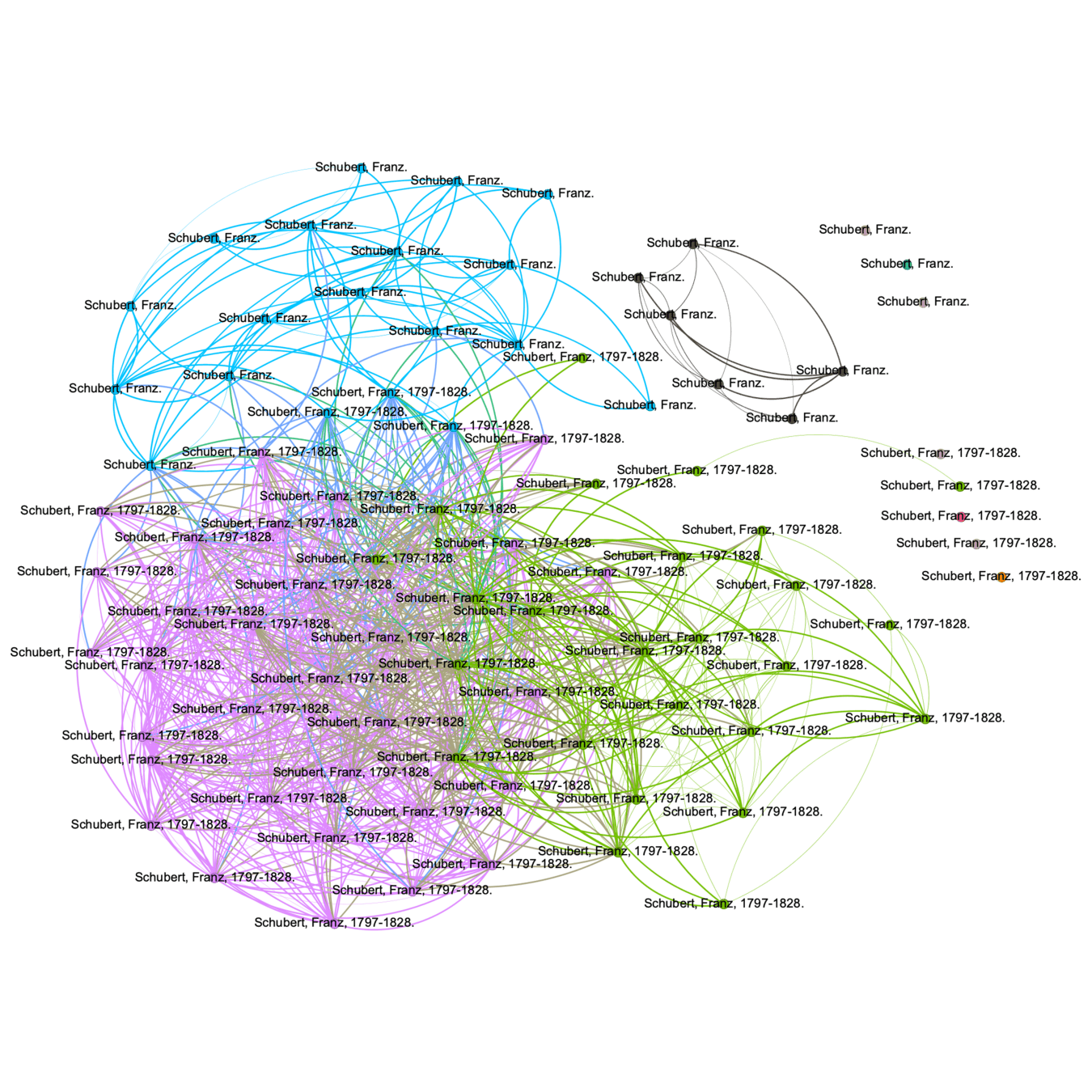
Schubert, Franz
2022–2023
Student employees (CHIT and library funded) used an Excel plugin to perform manual entity resolution and disambiguation for common names in the catalog.
November 2023
Pilot project proposal
September 2024–present
2023
Research and testing with TerminusDB (open source graph database)
February–March 2024
Pilot project with consultants
Embedding models transform text into a numeric representation.
Given a word or string of words, embedding models output a high-dimensional vector that captures the text’s semantic meaning, syntactic structure, and contextual nuance.
Credit: Catherine Kwon
[0.004, -0.005, ..., -0.017, 0.005]
“Today is a great day!”
string of text
high-dimensional vector
EMBEDDING
MODEL
Credit: Catherine Kwon
Contributor: Schubert, Franz
Title: The art of photography: instructions in the art of producing photographic pictures
Attribution: by G.C. Hermann Halleur ; with practical hints on the locale best suited for photographic operations, and on the proper posture, attitude, and dress, for portraiture by F. Schubert and an appendix ; translated from the German by G.L. Strauss
Subjects: Photography
Provision information: London: J. Weale, 1854
[0.007, -0.008, ..., -0.019, 0.001]
“Contributor: Schubert, Franz...”
high-dimensional vector
EMBEDDING
MODEL
Credit: Catherine Kwon
1
2
3
4
See “Leveraging LLMs and Machine Learning for Record Matching,” blog post by Gavin Mendel-Gleason.
Instead of just indexing a single embedding string, we need an entity resolution pipeline:
Split the data into separate fields:
Response from Claude Sonnet 4
| Claude 3.5 Haiku | Claude 3.7 Sonnet | |
|---|---|---|
| Expected Cost (1 input/output) |
$0.00029 |
$0.00403 |
| Unique name strings in Yale catalog | 4,984,022 | 4,984,022 |
| Total | $1,445.37 | $20,085.61 |
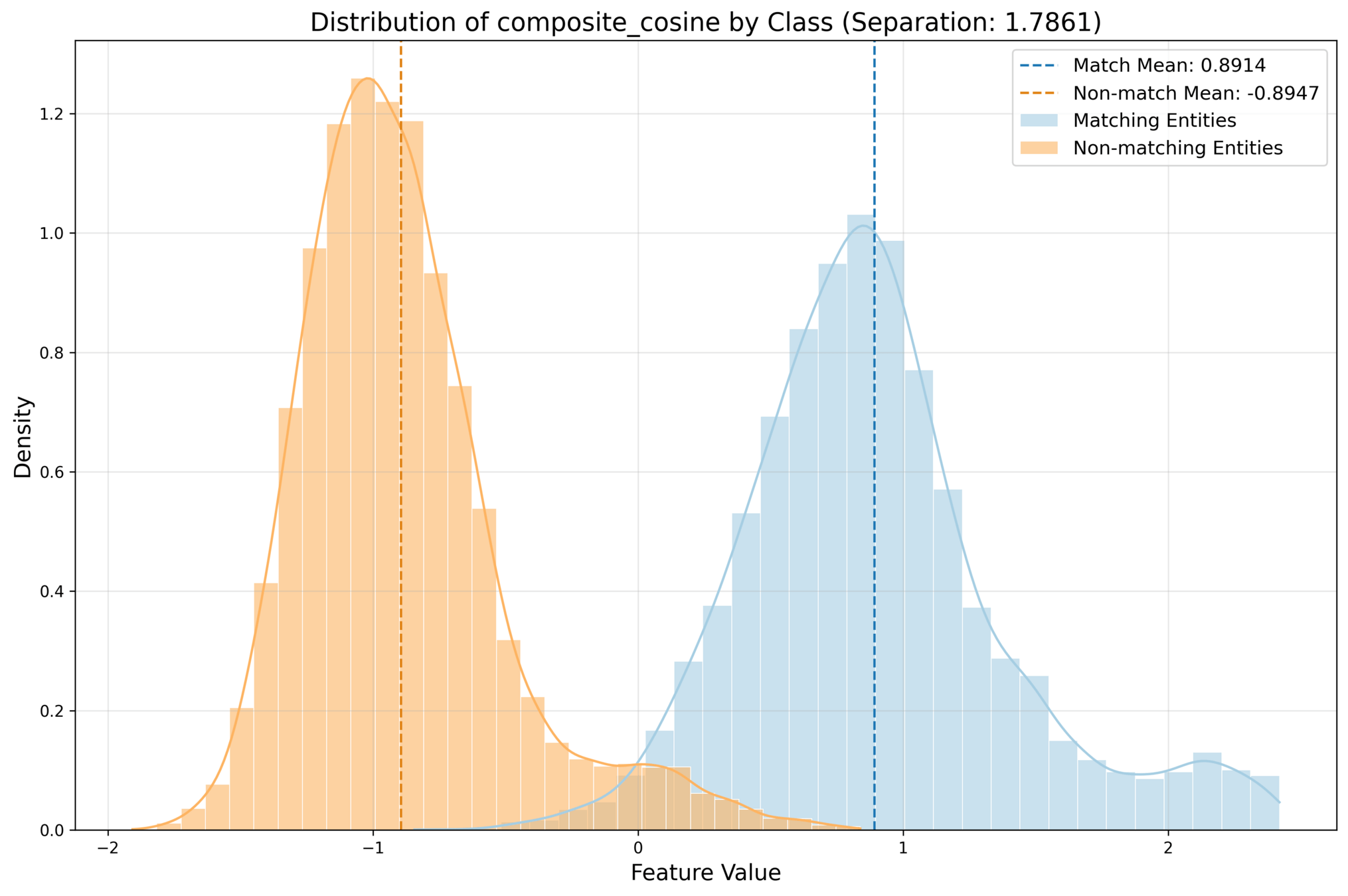
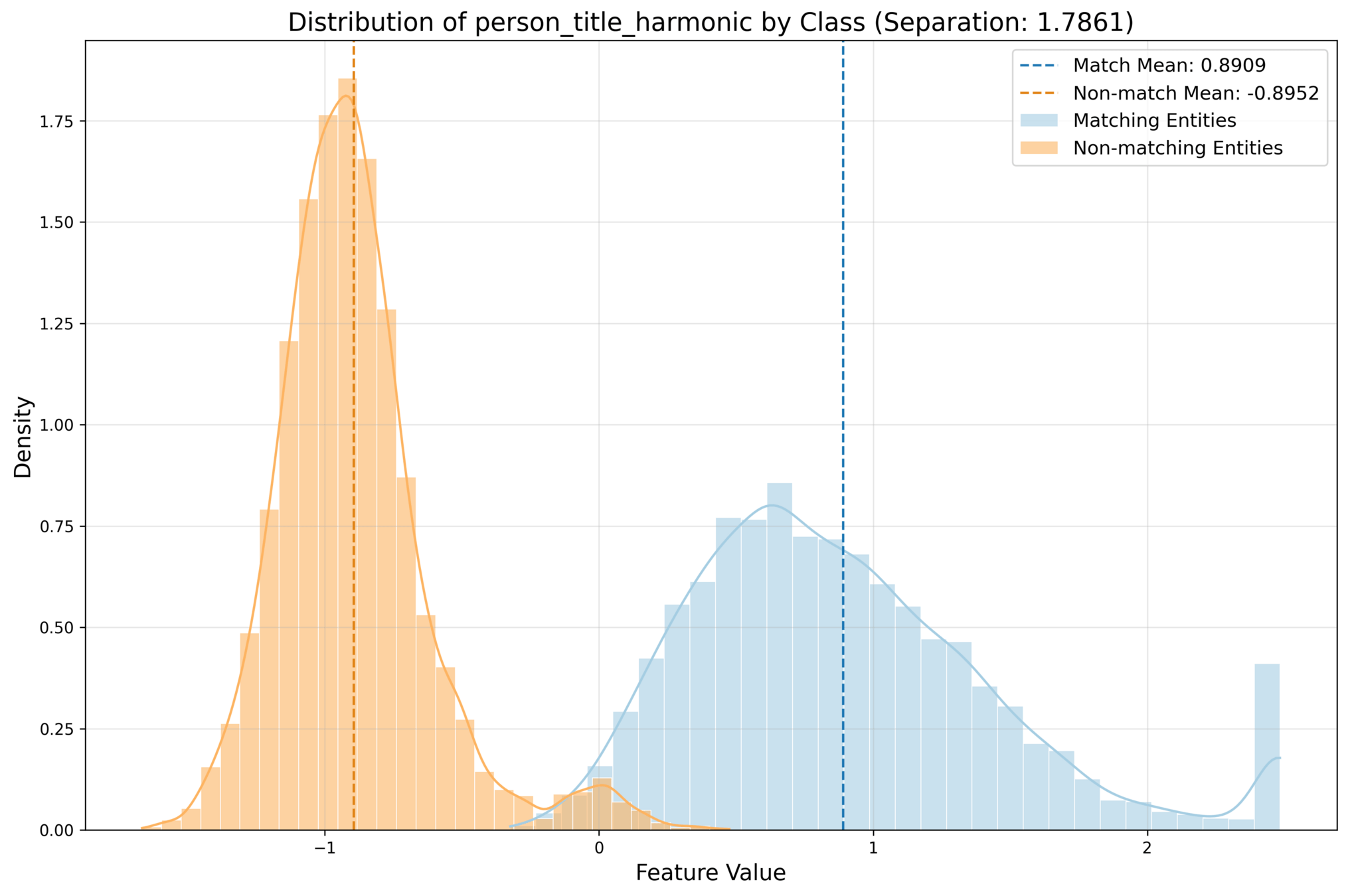
Test Results Summary:
Total test instances: 23268
Correct predictions: 22102 (94.99%)
Incorrect predictions: 1166 (5.01%)| Performance Metrics | ||
|---|---|---|
| Metric | Value | |
| Precision | 1.0000 | |
| Recall | 0.9006 | |
| F1 | 0.9477 | |
| Accuracy | 0.9500 | |
| ROC AUC | 0.9999 | |
| Confusion Matrix | ||
| Predicted Negative | Predicted Positive | |
| Actual Negative | 11559 | 0 |
| Actual Positive | 1164 | 10545 |
[Photograph of Beinecke Construction]. 0AD. https://collections.library.yale.edu/catalog/2037090.
2022–2023
Student employees (CHIT and library funded) used an Excel plugin to perform manual entity resolution and disambiguation for common names in the catalog
November 2023
Proposal to Marty Kurth and ITSC
September–October 2024
2023
TerminusDB (graph database) and VectorLink: research and testing
February–March 2024
Consultant project with DataChemist (TerminusDB and VectorLink developers)
Credit: Catherine Kwon
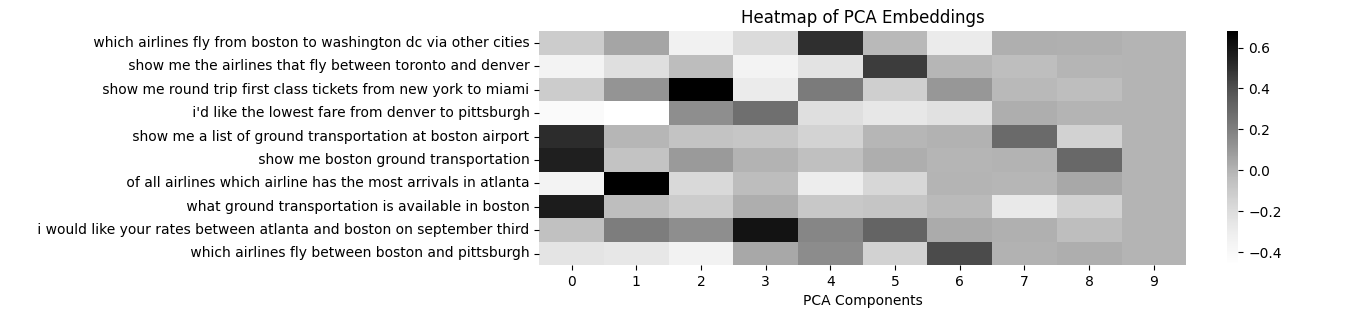
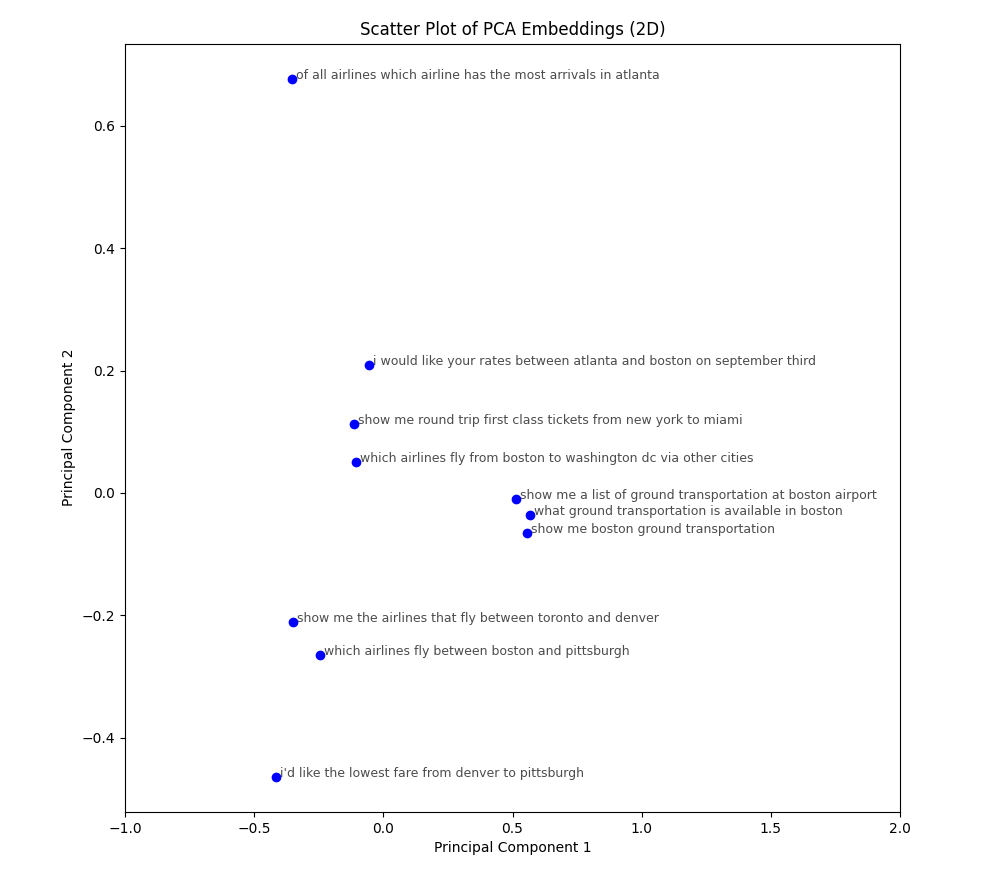
Principal Component Analysis (PCA)
Ground Transportation
Credit: Catherine Kwon
{
"op": "Inserted",
"string": "Contributor: Schubert, Franz\n Title: The art of photography: instructions in the art of producing photographic pictures in any color, and on any material : for the use of beginners : and also of persons who have already attained some proficiency in the art : and of engravers on copper, stone, wood, etc.\n Subjects: Photography\n",
"marcKey": "7001 $aSchubert, Franz.",
"person": "Schubert, Franz",
"roles": "Contributor",
"title": "The art of photography: instructions in the art of producing photographic pictures in any color, and on any material : for the use of beginners : and also of persons who have already attained some proficiency in the art : and of engravers on copper, stone, wood, etc.",
"variant_titles": null,
"hub_title": null,
"subjects": "Photography",
"genres": null,
"record": "14703468",
"id": "14703468#Agent700-23"
}1
2
3
4?
1a
1b
Contributor: Halleur, G. C. Hermann
Title: The art of photography: instructions in the art of producing photographic pictures in any color, and on any material : for the use of beginners : and also of persons who have already attained some proficiency in the art : and of engravers on copper, stone, wood, etc.
Subjects: Photography
Contributor: Schubert, Franz
Title: The art of photography: instructions in the art of producing photographic pictures in any color, and on any material : for the use of beginners : and also of persons who have already attained some proficiency in the art : and of engravers on copper, stone, wood, etc.
Subjects: Photography
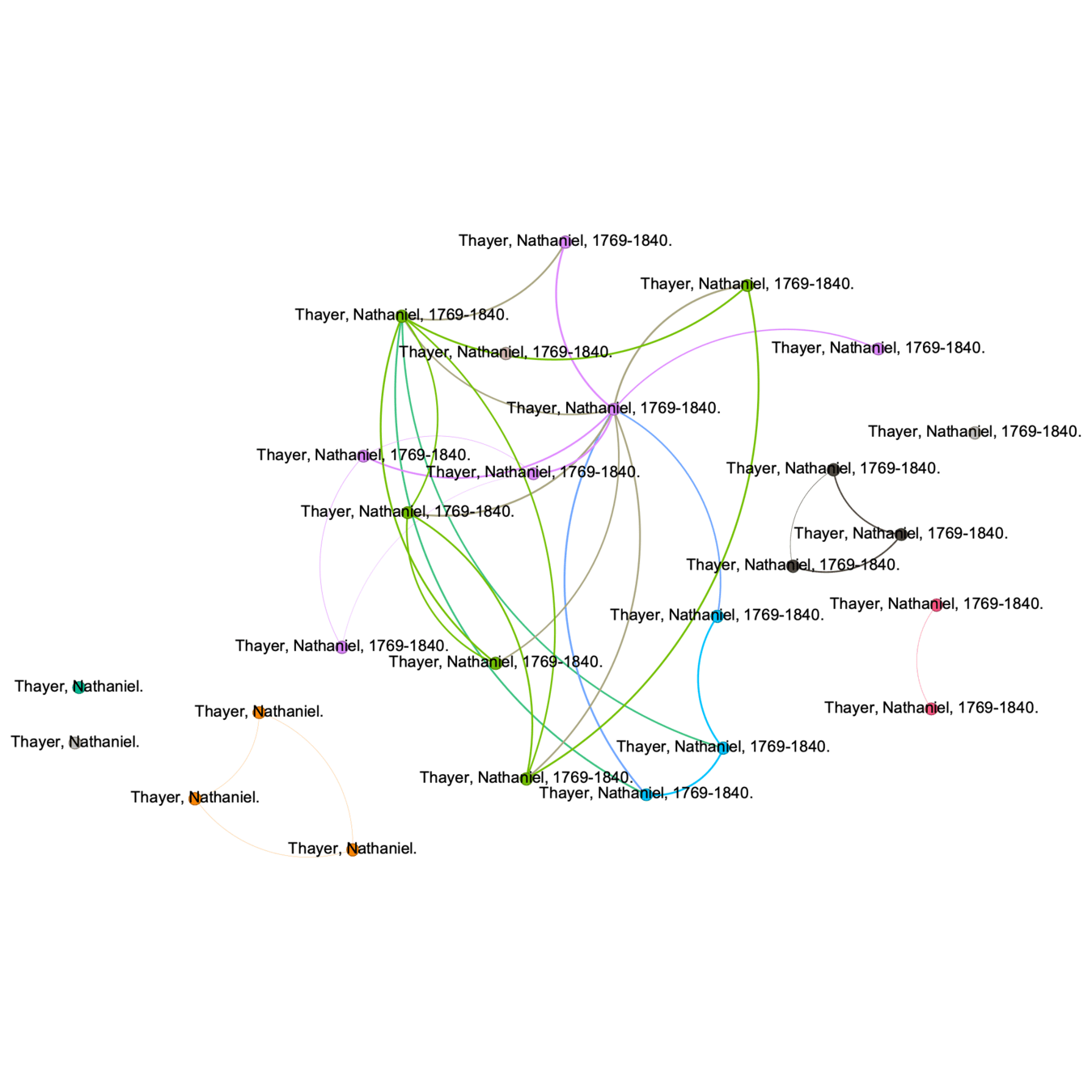
Name: Schubert, Franz, 1876-
Variant names: Schubert, Franz, b. 1876
Sources: Grundzüge der Pastoraltheologie, 1922 (Dr. Franz Schubert, o. ö. Professor an der Universität Breslau); DNB in VIAF, Oct. 7, 2011 (hdg.: Schubert, Franz, 1876-; German theologian, professor of pastoral theology); Deutsche Biographie, viewed 28 September 2022 (Franz Schubert; born in Bistrai-Bielitz (Austrian Silesia) in 1876, died in Breslau in 1937; Catholic theologian specializing in pastoral theology)
Contributor: Schubert, Franz
Title: Liturgische Zeitschrift
Subjects: Catholic Church--Liturgy--Periodicals.
Similarity: 0.23 😿
By Tim Thompson
Explore the innovative use of text embeddings for enhancing entity resolution and name disambiguation in library catalogs, addressing common ambiguities and showcasing authority control challenges.



