Web Crawler 爬蟲
第二堂
lecturer:溫室蔡、乘一
課前隨便講講時間
-
因為上次有好多人沒來(但今天可能也沒人就是了QAQ
-
課程內容:爬蟲、DCBot、人工智慧
-
有問題一定要舉手!!!
-
如果沒有學過Python,不用擔心,我們會幫助你~
明顯簡報是抄上次的
課前隨便複習時間
什麼是爬蟲?
-
自動搜尋全球資訊網(www)的機器人
-
可以對網站進行抓取
-
消耗目標網站資源
-
省時省力
-
提高效率
requests
把網頁的html抓取下來!!!
import requests #匯入requests模組
url='https://ckefgisc.github.io/' #這是你想要爬的網址
html=requests.get(url) #get函式返回一個response物件
print(html.text) #.text返回網頁原始碼btw 這是我們(還沒架好)的社網
解析HTML
怎麼做呢?
import requests #匯入requests模組
from bs4 import BeautifulSoup #注意大小寫!!!
#匯入bs4模組中的BeautifulSoup
url = 'https://ckefgisc.github.io/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
#要使用需要兩個參數,第一個是原始碼,第二個是解析方式
#把解析後的結果傳進soup
print(soup.prettify())#輸出排版後的HTML解析HTML
尋找標籤
import requests
from bs4 import BeautifulSoup #注意大小寫!!!
url = 'https://ckefgisc.github.io/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
print(soup.find('a'))#尋找<a>標籤
print(soup.find_all('a'))#尋找所有的<a>標籤
print(soup.find_all('p', limit=2))#尋找頭兩個<p>標籤
print(soup.find("div", class_="aboutsite_text"))
#尋找<div>標籤中的特定class的內容動態網頁爬蟲
先下載個酷東西
來看個網頁
打開javascript和關起來會有甚麼差別?
網頁原始碼也會改變嗎?
爬爬看這個網頁...?
import requests
url = 'https://hipala.github.io/js-example/'
r = requests.get(url)
print(r.text)<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>消失的文字</title>
</head>
<body>
<div id="word"></div>
<p>其實上面還有段文字<p>
<script type="text/javascript" src="example.js"></script>
</body>
</html>怎麼讓消失的文字出現呢?
動態網頁爬蟲!
-
和靜態爬蟲差別在於有沒有加載網頁
-
客戶端:將javascript一起爬下來,在客戶端執行
-
伺服器端:使用selenium,模仿使用者操作加載後的網頁
Selenium
-
模擬使用者操作網頁
-
可以進行點擊按鍵、輸入內容等等動作
-
包含IDE、API、WebDriver
Selenium安裝
API
pip install seleniumWebDriver
Selenium安裝
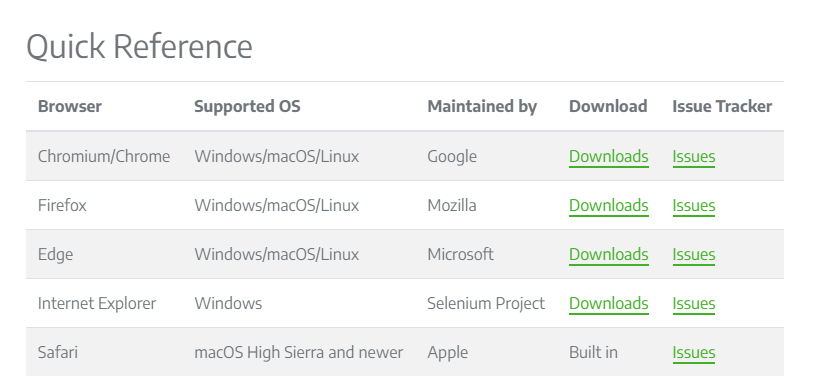
Selenium安裝
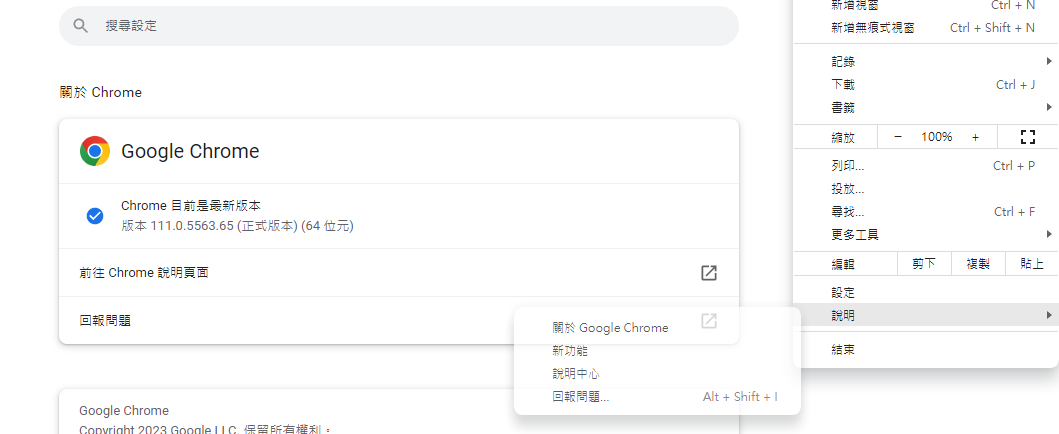
Selenium安裝
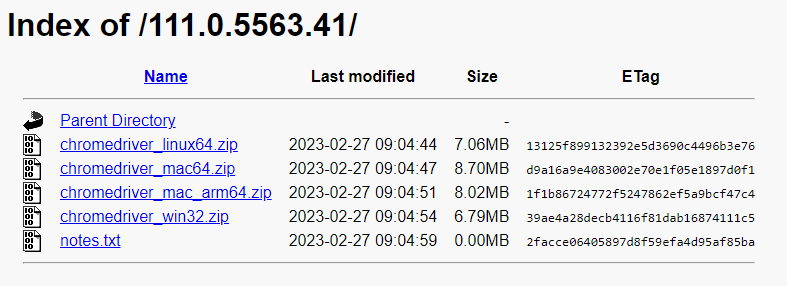
記得要和你的py檔下載在同一個資料夾
Selenium!!!
基本操作
from selenium import webdriver
driver = webdriver.Chrome()
#如果你的檔案不是存在同一個資料夾:
#driver = webdriver.Chrome('檔案的絕對位址')
driver.get("https://hipala.github.io/js-example/") #前往指定網頁
driver.implicitly_wait(10)#給網頁下載的時間
print(driver.page_source)#顯示網頁原始碼
driver.close() #關閉網頁Selenium!!!
搜尋標籤
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
#如果你的檔案不是存在同一個資料夾:
#driver = webdriver.Chrome('檔案的絕對位址')
driver.get("https://hipala.github.io/js-example/") #前往指定網頁
driver.implicitly_wait(10)#給網頁下載的時間
'''各種搜尋方法 這是舊方法
driver.find_element_by_id()
driver.find_element_by_name()
driver.find_element_by_xpath()
driver.find_element_by_link_text()
driver.find_element_by_partial_link_text()
driver.find_element_by_tag_name()
driver.find_element_by_class_name()
driver.find_element_by_css_selector()
'''
'''新的方法
driver.find_element(By.你要搜尋的方法, 搜尋的內容)
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
像是
driver.find_element(By.ID, 'id')
'''
driver.close() #關閉網頁Selenium!!!
輸入文字
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
#如果你的檔案不是存在同一個資料夾:
#driver = webdriver.Chrome('檔案的絕對位址')
driver.get("https://www.google.com.tw/?hl=zh_TW") #前往指定網頁
driver.implicitly_wait(10)#給網頁下載的時間
element = driver.find_element(By.CLASS_NAME, 'gLFyf')
element.send_keys('selenium')#輸入文字Selenium!!!
動作指令
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
#如果你的檔案不是存在同一個資料夾:
#driver = webdriver.Chrome('檔案的絕對位址')
driver.get("https://www.google.com.tw/?hl=zh_TW") #前往指定網頁
driver.implicitly_wait(10)#給網頁下載的時間
element = driver.find_element(By.CLASS_NAME, 'gLFyf')
element.send_keys('selenium')
element.send_keys(Keys.ENTER)#按下按鍵實作時間!!!
恭喜各位上完
第二堂Py小社課!!!

反正我不放還是
會有人亂動我電腦
crawler-2
By times1-chang




