Bloggo

from 0 to Blog with Spring Boot and MongoDB


Who Am I?
Tonino Catapano

Software Dev @
Drone racing hobbyist


Agenda
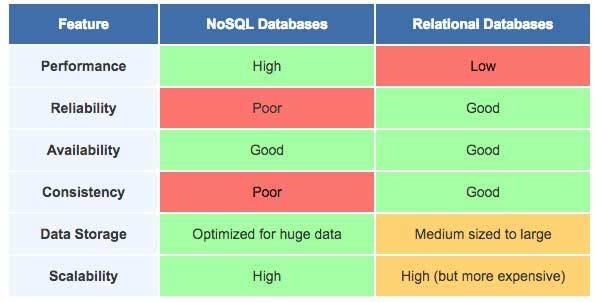
- NOSQL and Mongo: a bit of History
- Comparison with Relational & Why Mongo
- CRUD (REPL vs Java)
- Bloggo: a Spring Boot blog backed by MongoDB
- Schema Design
- Performance
- Extra & Goodies
NoSQL?
A NoSQL database is a non (striclty) SQL database.
It provides a mechanism for storage and retrieval of data that is not modeled in tabular form like traditional RDBMS do. [wiki]
#NoSQL
Existed since 1960s, but they were called differently back then.
Only from 2009 they gained the name NoSQL because they needed a short hashtag to tweet about the first meetup in SF. Nobody expected to be the next big db movement!
Big Data
A term for data sets that are so large that traditional methods of storage & processing are inadequate

Massive increase in data volume within the last decade
Social networks, search engines etc..
Challenges in storage, capture, analysis, transfer etc..
Vertical vs Horizontal Scaling
Stuff was getting slower. Upgrading hardware was not enough anymore (Scale-in)
Big players said: «We need to change; I will develop my own data storage!»
Scale-in is expensive and many companies were going in the direction of having "many small clusters"
Situation today
Different NoSQL db for different purposes, they share common traits:

non relational
open-source
cluster-friendly
schema-less
Advantages of NoSQL DBs
If designed correctly, handles Big Data successfully
Extreme flexible Data Models - Schema less => but you need to handle the consistency of your data in the application layer
Cheap(er) to manage
Easy Scaling
Schema Migrations tools are optional - Flyway, fly away!
Advantages of Relational DBs
Relational Databases are better for relational data! (duh!)

Normalization (eg 3NF) => eliminate redundancy, less space required, faster access in some cases
SQL is well known language (it's been around for 30 years)
Data Integrity => using foreign key constraints help reducing inconsistency
A C I D
Mongo and JSON
Mongo is a document based DB: every model, query and data stored in MongoDB is a BSON that is an extension of JSON (Javascript Object Notation)
Can you tell how many tables in a normalized relational database would be needed to store the same amount information displayed on the right (single document)?
« In a nutshell, MongoDB allows developers to design data models that support common data access patterns.»
{
"title":"Game of Thrones",
"producers":["Television 360","Grok! Television",
"Generator Entertainment"..],
"createdBy":["David Benioff", "D. B. Weiss"],
"firstSeasonReleased": 2009,
"locations":[{"country" : "Northern Ireland",
"city":"...", "dateShooted": [
{..},..]} ],
"website":"https://www.hbo.com/game-of-thrones",
"characters":["...","..."],
"seasons":[{"ordinal": 1, "newCharacters":[],
"plot": ""}....]
}tv series
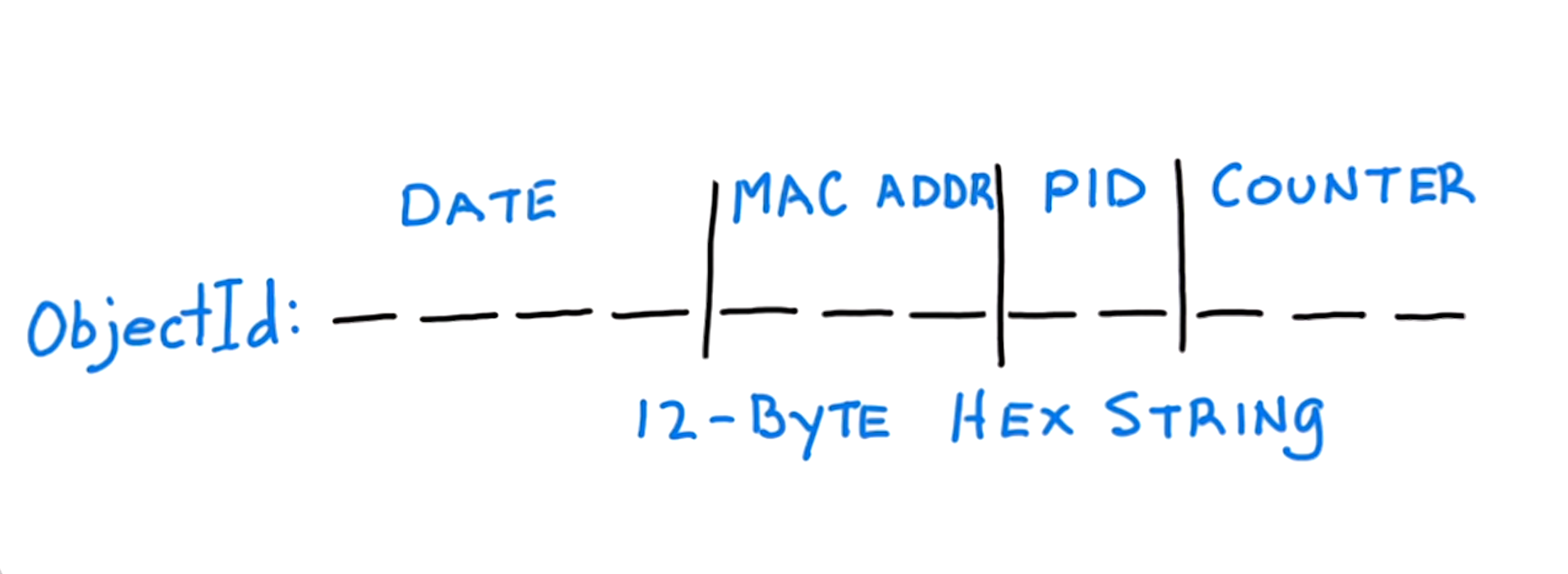
The _id field
All documents in MongoDB must have an _id field that is unique (key).
If you don't specify one when inserting, Mongo will create one for you as ObjectId() that is guaranteed to be unique within that collection.
WHY BSON?

- lightweight
- traversable
- efficient
- ISODate() natively
- but MAX 16 MB
JSON value types are limited e.g.:
- There is a single number type (no floats)
- JSON doesn't support Date format natively
- JSON does not support binary data
see details at bsonspec.org/spec.html
BSON on the other hand is:
C R U D
Create (DDL):
-
SQL: create table users(user_id varchar2(10),name varchar2(10),age number) -
Mongo: db.createCollection("users"); [optional]
Read:
-
SQL: Select * from users Where age!=23 -
Mongo: db.users.find({ age: {$ne:23} })
Update:
-
SQL: UPDATE Customers SET customerId = 1 WHERE customerID = 0 -
Mongo: db.users.update({cutomerId:0}, { $set: { customerId: 1} }, { multi: true })
Delete:
-
SQL: DELETE FROM USERS WHERE ID = 6 -
Mongo: db.users.remove({id:6})
DDL in Mongo is less strict than SQL. Some DML statements in comparison:
Creating & Reading documents:

REPL!
The query language for mongoDB use a query-by-example strategy, let's give it a look!
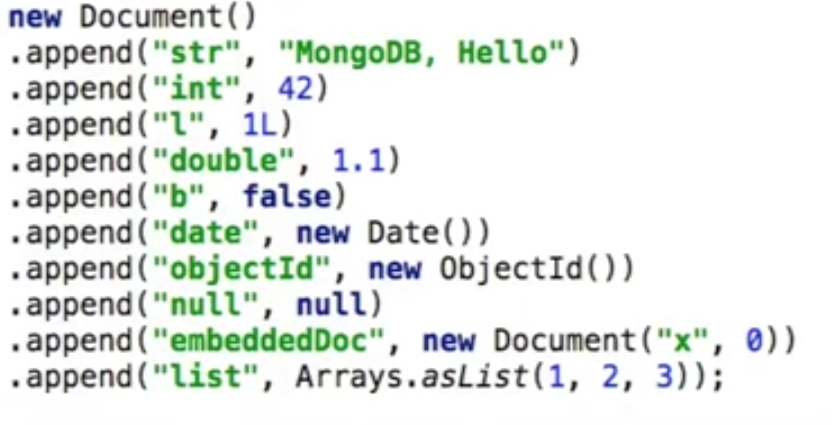
Let's get Java: Document obj
Beside
There is also a type safe object called
It requires the explicit field type when declaring a Document => avoid Runtime Exceptions for type mismatch.
Document()BsonDocument()Exercise0: Java warm up

you@yourmachine:~$ git checkout exercise0you@yourmachine:~$ git clone https://github.com/tonycatapano/Bloggo.git or via ssh you@yourmachine:~$ git clone git@github.com:tonycatapano/Bloggo.git
Bloggo: architecture
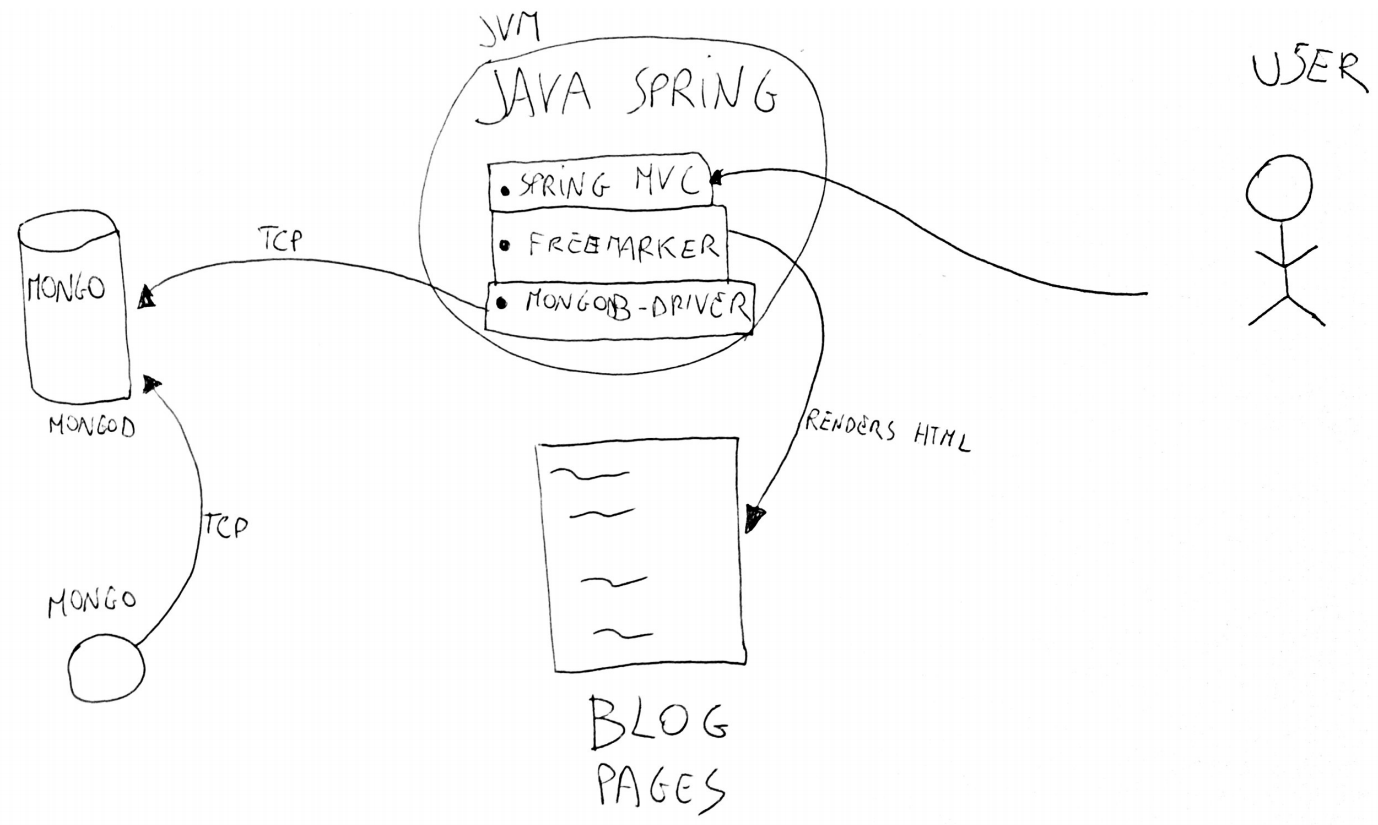

Bloggo: some clarifications
- No fancy UI
- No Single Page App
- No models /pojos => no ODM
(dont try this at home) - Skipping all concerns regarding
Security (but please read: https://docs.mongodb.com/
manual/administration/security-checklist/ )
@MongoCollection(name = "comments")
public class Comment {
@Id
public String id;
public String text;
}
public class BlogPost {
@Id
public String id;
@ObjectId
public List<DBRef<Comment, String>> comments;
}
BlogPost post = coll.findOneById(someId);
for (DBRef<Comment, String> comment : post.comments) {
System.out.println(comment.fetch().text);
}DAO Layer
Demo!
Schema Design

Starting situation:
Goals of normalization:
- Free the DB from modification anomalies
- Minimize re-design when extending
- Avoid bias towards any particular access pattern
Thinking relational
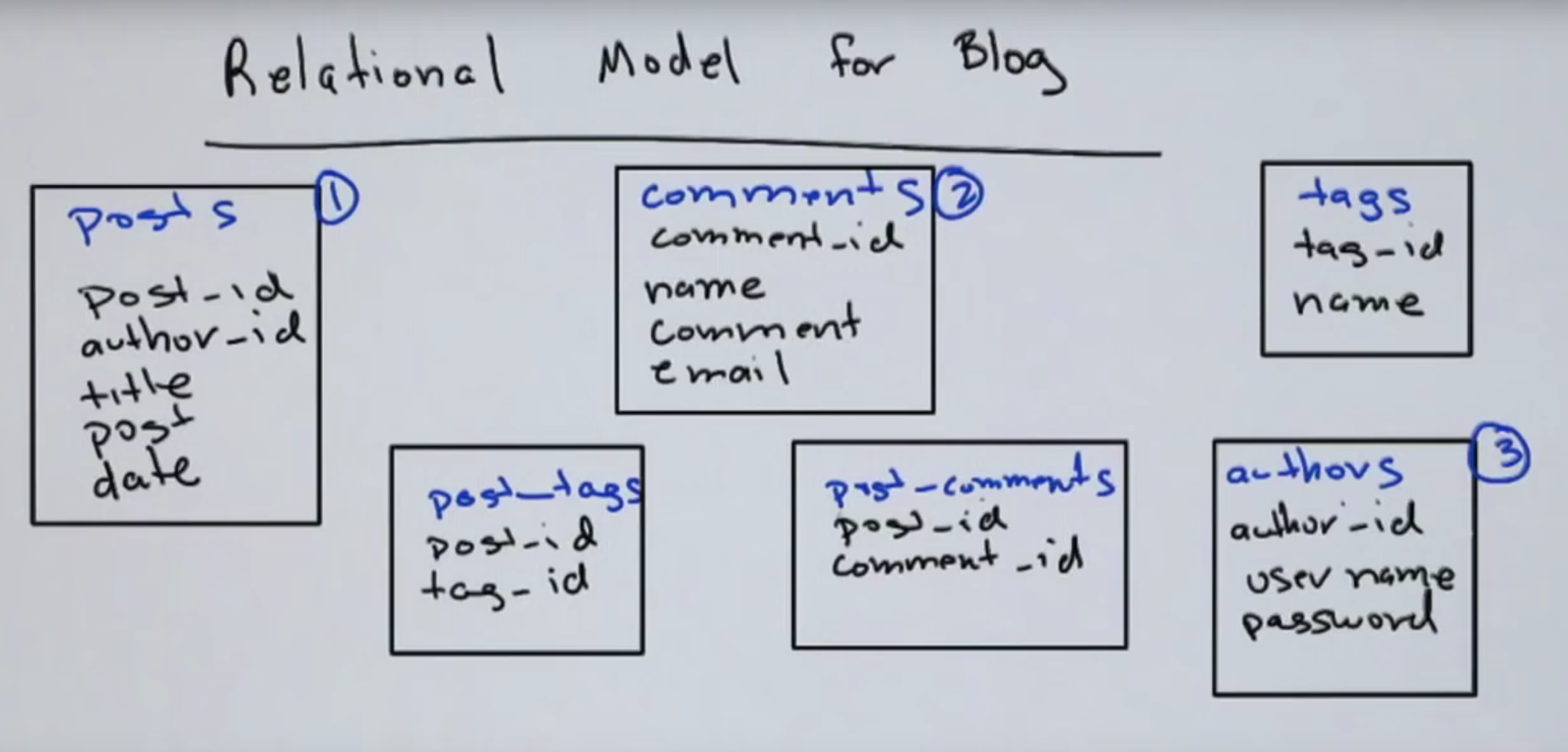

- No joins embedded in the kernel of Mongo
- No constraint system
- Lesson: If you find yourself thinking relational while designin with Mongo, you're most probably wrong
Designing with Mongo
In designing with Mongo you have to think out of the box. This is not relational.

Always tradeoff between linking or embedding.
Decision based on:
- Data access pattern
- cardinality
- read/write frenquency
OneToOne relationship
- Either link or Embed!
{
_id: 20,
name: "Ragnar",
resume: 1
}{
_id:1,
jobs:[],
education:[],
employee:20
}Employee
Resume
Considering:
- Frequency of access
- Writing only a field all the time
- Easy atomicity
{
_id: 20,
name: "Ragnar",
resume: {
jobs:[],
education:[]
}
}{
_id:1,
jobs:[],
education:[],
employee: {
name: "Ragnar"
}
}OneToMany relationship
{
_id: 20,
name: "Ragnar",
...
}{
_id:1,
name: "NYC",
inhabitants:[1,2,3],
...
}Person
City
Solution: true linking
{
_id: 20,
name: "Ragnar",
city: {name: "NYC",
zipCode: 123,
population:8.538.000},
...
}{
_id: "1",
name: "Ragnar",
city: "NYC",
...
}{
_id:"NYC",
zipCode: 123,
population:8.538.000
}OneTo"Few" relationship
when the Many are in the order of "few"
{
_id: 1,
name: "Mark",
surname:"Zuckerberg",
cars:["Ferrari", "Lamborghini"]
}Person
EMBED!
ManyToMany relationship
{
_id: 11,
title: "The Matrix",
director: "The Wachowski
'siblings'",
producer: "Joel Silver",
peopleInvolved: [1,2,3...,n]
}{
_id: 222,
name: "Nicola Nardone",
role: "bullet-time expert"
workedOnMovies: [1,2,3,...,n]
}Movies
People
- this is ok because data does not change otherwise:
- do not embed
- two way linking only if necessary
{
idMovie:11
idPerson:22
}PeopleMovies
"FewToFew" relationship
- two way linking only if necessary
{
_id: 20,
title: "The Sagas of Ragnar Lodbrok",
author:[1,2]
}{
_id:1,
author_name:"Ben Waggoner",
education:[],
books:[11,20,42]
}Book
Authors
- do not embed
Representing trees (e.g. categories)
{
_id: 10,
category: 7,
prod_name: "16 GB USB DRIVE 3.0"
}{
_id:7,
category_name:"usb drives",
parent:6
}Product
Category
Problems:
- many access to create a breadcrumb (list all ancestors) => inefficient
{
_id:7,
category_name:"usb drives",
ancestors:[8,9,10]
}Category
{
_id:7,
category_name:"usb drives",
children:[8,9,10]
}Category

- can't find all children of a certain node easily
Living without constraints and transactions
- No Foreign keys ⇓ you have to enforce constraints manually in your app layer but embedding helps
- No transactions =>
Restructure code: single document FTW
Implement locking, semaphores, critical sections...
Tolerate: e.g. Facebook feed
Bloggo: just 2 collections!
After what we just saw we can design our blog with just 2 (+1) collections:
- 1 for the posts & comments
- 1 for users
- 1 for session management
{
"_id" : ObjectId("59e336472687c8737a5c2735"),
"title" : "A RANDOM BLOG POST",
"author" : "ragnar",
"body" : "first post tahahhahaha",
"tags" : [
"uolo",
"miesta",
"asdoas",
"cocacola"
],
"comments" : [ {
"author" : "Tony",
"email" : "info@toninocatapano.com",
"body" : "this blog in Mongo sucks"
} ],
"date" : ISODate("2017-10-15T10:19:51.691Z"),
"permalink" : "a_random_blog_post"
}{
"_id" : "ragnar",
"password" : "HScSZiHvv73vv71kY++/ve+/vQrvv73vv71R77+9,-1847318508",
"email" : "therealspartan77@vikings.org"
}
posts
users
Exercise1: Sign up and Sign in

you@yourmachine:~$ git checkout exercise1Exercise2: Posts and comments

you@yourmachine:~$ git checkout exercise2Performance
Two ways to impact latency & throughput of database queries:
- adding indexes
- distribute load across multiple servers with sharding
From Mongo 3.0 we have Pluggable Storage engines:
- MMAPv1
- WiredTiger (default since 3.2)

MMAPv1 vs Wired Tiger
- Collection level concurrency (file)
- In place updates: Documents are stored in power of 2 size bytes
- No memory handling
- Multiple readers, single writer
- Document level concurrency
- Compression (data & indexes)
- Memory handling
- No in place updates
MMAPv1
Wired Tiger (default since 3.2)
vs
Indexes in theory
{name:"Doom III", genre:"FPS", price:40, extras:"Doom 1990 maps"}videogames
collection on disk
indexes on name
Amnesia
Zelda
{..}{..}{..}{..}{..}{..}{..}{..}{..}{..}Indexes in practice
Will my app be available during indexes creation?
- fast
- block all writers & readers in db (even with W.T.)
- slower
- don't block readers nor writers
- from 2.4+ multiple creation even on the same db
Foreground (default)
Background
vs
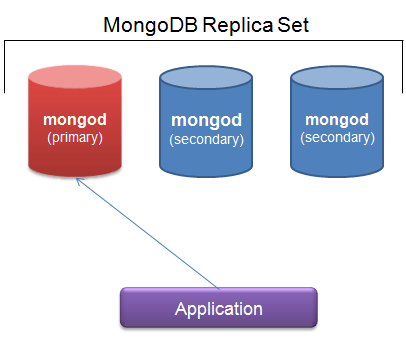
alternative: replica set redirection
- nb from 2.6+ after index creation on primary, will start on secondary automatically.
Index size
To benefits of the speed of having indexes make sure that the size of your indexes fits into your memory, let's see how to assess that.
Memory
Working set
Indexes

slow
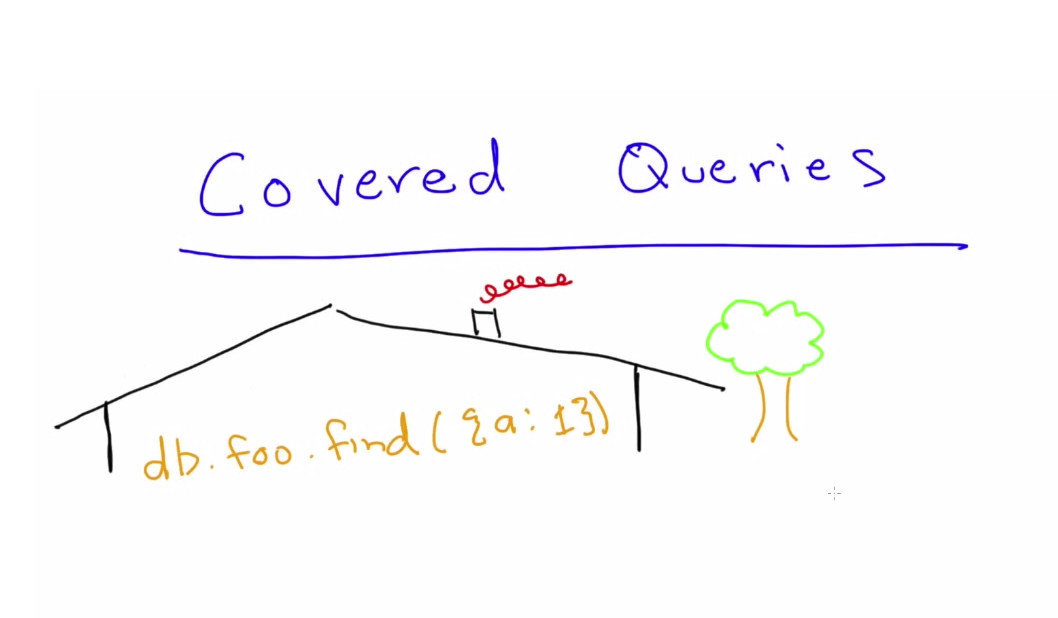
Covered query
A query where all the queried fields AND projected fields are indexed. This kind of query is, as you may expect, the fastest.
REPL!
Exercise3: indexes

you@yourmachine:~$ git checkout exercise3Geospatial query and indexes
Mongo allows to query documents based on coordinates in a 2d space.

There is also a 3d model called GeoSphere that is far more complete and allows you to define a location with an area or on planes that are 3Dimensional.
And query by range!
Let's see how to use it.
Exercise4: let's get Geospatial

you@yourmachine:~$ git checkout exercise4My favourite Mongo tools

Still much more to see
-
Text Indexes : easy search on big texts
-
Multi indexes aka indexes on arrays
-
Query profiling
-
MongoDB Atlas: Database as a Service
-
Embedded JS interpreter: Store JS functions on Mongo and use them for distributed Map-Reduce aggregations, $eval or $where
-
Aggregation Framework aka groupBy
-
Replication and fail-over support
-
(auto) Sharding


A new love?
Questions?


Bloggo
By tonnoz
