"Why should I trust you?"
Explaining the Predictions of Any Classifier
J. Paternina - Lab meeting 31/01/2017
MT Ribeiro, S. Singh, C. Guestrin. 2016
Outline
- Motivation
- LIME: algorithm intuition
- Results
Motivation
Data
ML model
Decision
?
Trust
-
Is the model working?
-
How do I convince others?
Why is trust important?
"My product is good"
"I'm making the right decision"
"My model is better"
How to determine trust?
simple model
interpretable
accurate
>90%
accuracy
A/B
A/B testing
"real world" test
$$$
OK
Data leaking
Data shift
Data leaking
| ID | GENE 1 | GENE 2 | SAMPLE |
|---|---|---|---|
| 001 | 1.0 | 75.3 | healthy |
| 002 | 1.1 | 87.1 | healthy |
| ... | ... | ... | ... |
| 101 | 200.1 | 45.2 | ill |
| 102 | 220.5 | 56.4 | ill |
Training/validation set
95% accuracy
generalization
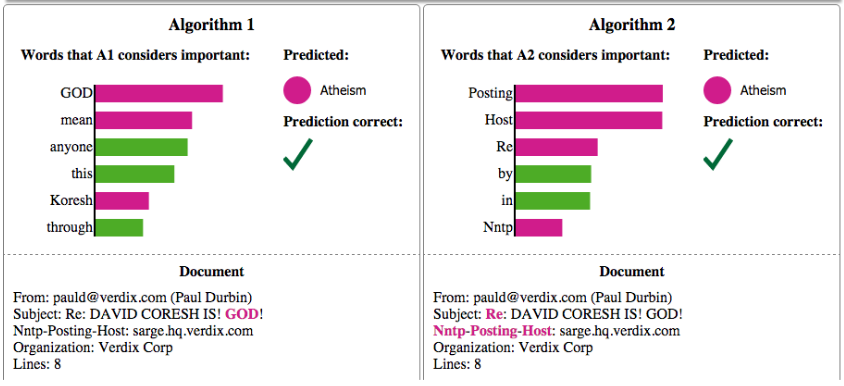
Data shift: 20 newsgroups
post
Atheism
Christianity
94% accuracy
57% accuracy
training set
≠
test set
LIME
Local Interpretable
Model-agnostic Explanations
20 newsgroups
Explainer model
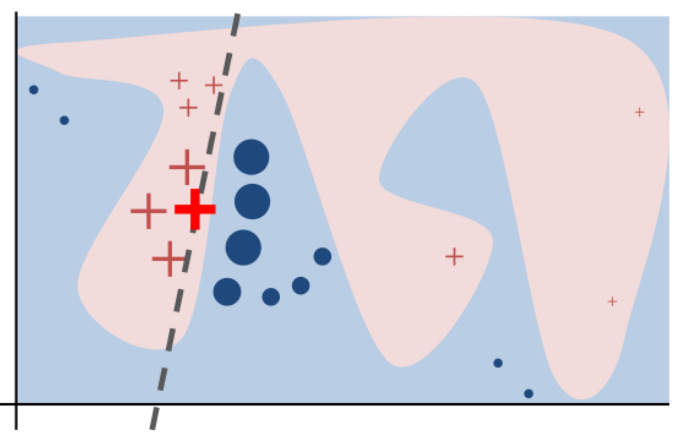
Explanation
f:
g:
\pi_x:
\Omega(g):
\mathcal{L}(f,g,\pi_x):
model to be explained
explainer
proximity measure to x
complexity of the explainer
unfaithfulness measure
\xi(x)=argmin\space\mathcal{L}(f,g,\pi_x)+\Omega(g)
Explanation
\pi_{x}(z)=exp(-D(x,z)^2/\sigma^2)
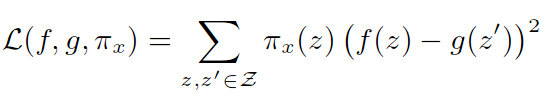
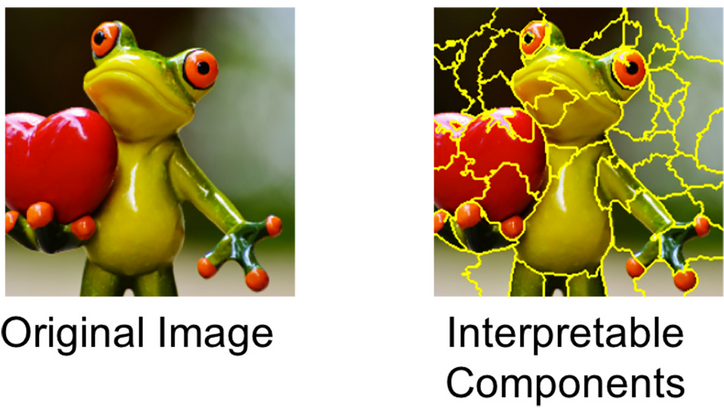
The LIME algorithm

Results
Google's Inception
Google's Inception

Explanation faithfulness

Explainer faithfulness
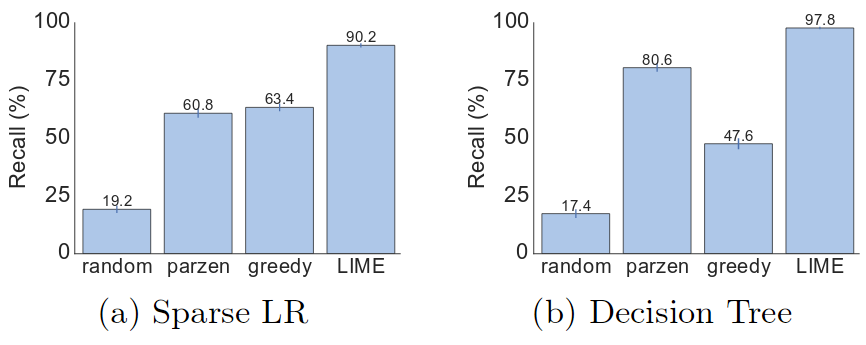
Human evaluation

Feature engineering
Feature engineering
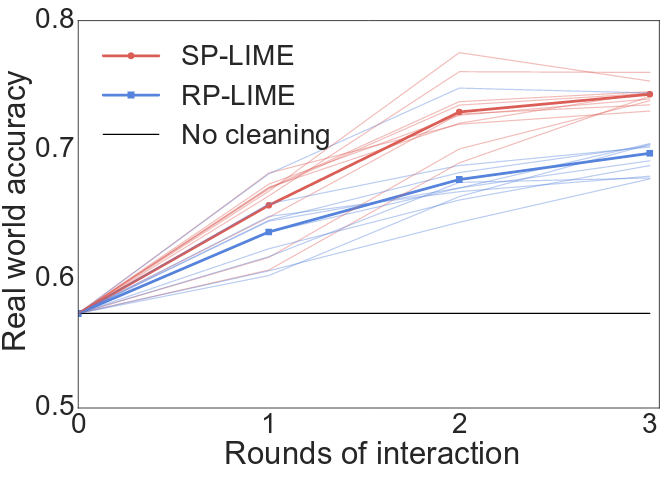
Model assessment


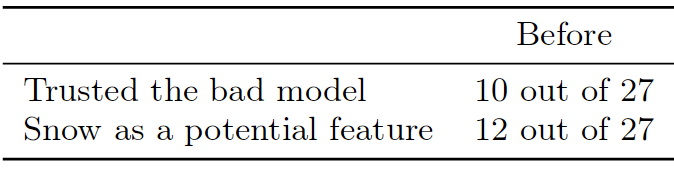
WOLF

Explanation

Conclusions
- Accuracy is not necessarily a trust indicator
- Local approximations are faithful to model (locally)
- Model explanations are useful for model assessment and improvement
Thank you!

lab_meeting_170131
By tpaternina
lab_meeting_170131
Lab meeting presentation at IBENS (31/01/2017)

