





Trang Le
#math graduate. Postdoc fellow with Jason Moore.
University of Pennsylvania
Virtual GECCO 2020
@trang1618
Clean data
Select features
Preprocess features
Construct features
Select classifier
Optimize parameters
Validate model
Pre-processed data
Automate
Automate
TPOT is a an AutoML system that uses GP to
optimize the pipeline with the objective of
Entire data set
Entire data set
PCA
Polynomial features
Combine features
Select 10% best features
Support vector machines
Multiple copies of the data set can enter the pipeline for analysis
Pipeline operators modify the features
Modified data set flows through the pipeline operators
Final classification is performed on the final feature set
GP primitive Feature selector & preprocessor, Supervised classifier/regressor
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target,
train_size = 0.75, test_size = 0.25, random_state = 42)
tpot = TPOTClassifier(generations = 5,population_size = 50,
verbosity = 2, random_state = 42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import Normalizer
from tpot.export_utils import set_param_recursive
# NOTE: Make sure that the outcome column is labeled 'target' in the data file
tpot_data = pd.read_csv(
'PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1)
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'], random_state=42)
# Average CV score on the training set was: 0.9826086956521738
exported_pipeline = make_pipeline(
Normalizer(norm="l2"),
KNeighborsClassifier(n_neighbors=5, p=2, weights="distance")
)
# Fix random state for all the steps in exported pipeline
set_param_recursive(exported_pipeline.steps, 'random_state', 42)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)feature selectors
feature preprocessors
supervised classifiers/regressors
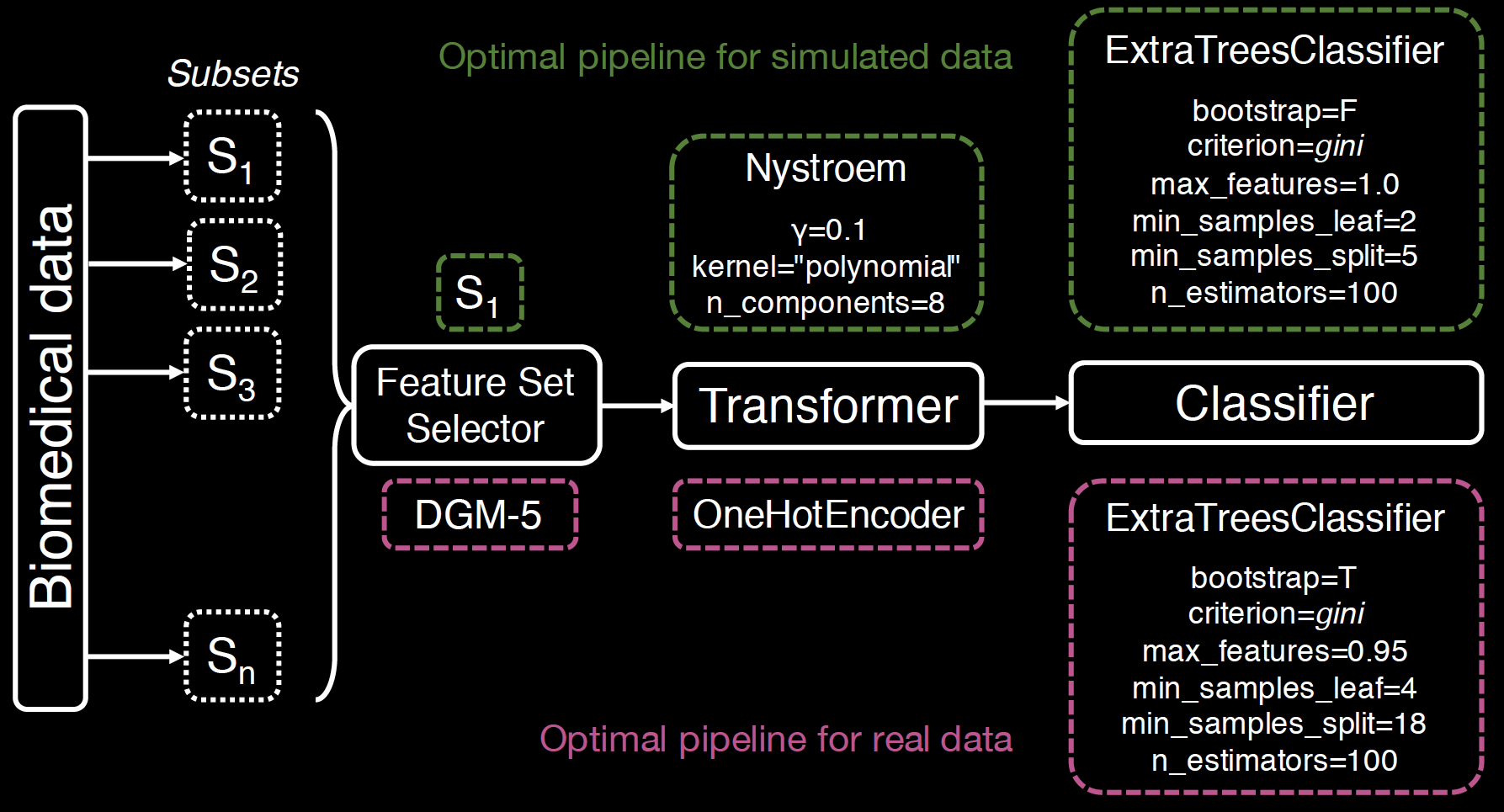
feature set selector (FSS)
generations
population_size
offspring_size
mutation_rate
...
...
template
new in this work
template:
FeatureSetSelector-Transformer-Classifierfrom tpot.config import classifier_config_dict
classifier_config_dict['tpot.builtins.FeatureSetSelector'] = {
'subset_list': ['subsets.csv'],
'sel_subset': range(19)
}
tpot = TPOTClassifier(
generations = 100, population_size = 100,
verbosity = 2, random_state = 42, early_stop = 10,
config_dict = classifier_config_dict,
template = 'FeatureSetSelector-Transformer-Classifier')For each training and testing set
100 replicates of TPOT runs
template:
FeatureSetSelector-Transformer-ClassifierThe optimal pipelines from TPOT-FSS significantly outperform those of XGBoost and standard TPOT.
template:
FeatureSetSelector-Transformer-ClassifierJason Moore
Weixuan Fu
Alena Orlenko
Nadia Penrod
Elisabetta Manduchi
Bill La Cava
Ruowang Li
By Trang Le
Presentation recorded on 2020-06-10 at GECCO, virtual conference




