





Trang Le
#math graduate. Postdoc fellow with Jason Moore.
Trang Lê
@trang1618
Clean data
Select features
Preprocess features
Construct features
Select classifier
Optimize parameters
Validate model
Raw data
Automate
Automate
Randy Olson
Ryan J. Urbanowicz
Peter C. Andrews Nicole A. Lavender
La Creis Kidd
Jason H. Moore
Weixuan Fu
Entire data set
Entire data set
PCA
Polynomial features
Combine features
Select k best features
Logistic regression
Multiple copies of the data set can enter the pipeline for analysis
Pipeline operators modify the features
Modified data set flows through the pipeline operators
Final classification is performed on the final feature set
GP primitive Dataset selector, Feature selector & preprocessor, Supervised classifier/regressor
Individual Sequence of pipeline operators
Population
Generations
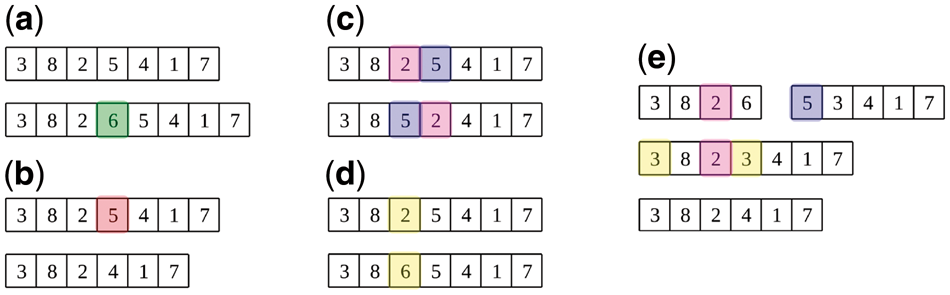
(a) insertion mutation
(b) deletion mutation
(c) swap mutation
(d) substitution mutation
(e) crossover
feature selectors
feature preprocessors
supervised classifiers/regressors
feature set selectors (FSS)
generations
population_size
offspring_size
mutation_rate
...
...
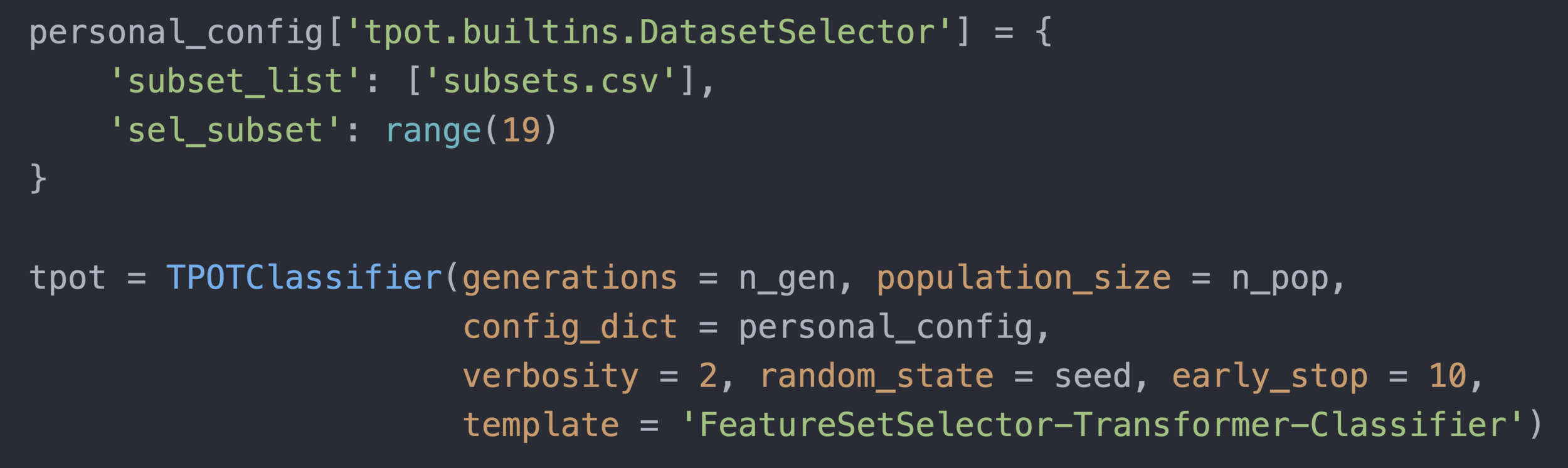
template
Jason Moore
Weixuan Fu
By Trang Le
Presentation on 2019-07-01, Moore lab Lunch&Learn



