CS110 Case Study: MapReduce
Principles of Computer Systems
Winter 2021
Stanford University
Computer Science Department
Instructors: Chris Gregg and
Nick Troccoli


CS110 Extra Topic: How can we parallelize data processing across many machines?
Learning Goals
- Apply our knowledge of networking and concurrency to understand MapReduce
- Learn about the MapReduce library and how it parallelizes operations
- Understand how to write a program that can be run with MapReduce
Plan
- Motivation: parallelizing computation
- What is MapReduce?
- Further Research
- Optional: Implement your own MapReduce!
Plan
- Motivation: parallelizing computation
- What is MapReduce?
- Further Research
- Optional: Implement your own MapReduce!
Parallelizing Programs
Task: we want to count the frequency of words in a document.
Possible Approach: program that reads document and builds a word -> frequency map
How can we parallelize this?
Idea: split document into pieces, count words in each piece concurrently
Problem: what if a word appears in multiple pieces? We need to then merge the counts.
Idea: combine all the output, sort it, split into pieces, combine in each one concurrently
Example: Counting Word Frequencies
Idea: split document into pieces, count words in each piece concurrently. Then, combine all the text output, sort it, split into pieces, sum each one concurrently.
Example: "the very very quick fox greeted the brown fox"
the very very
quick fox greeted
the brown fox
the, 1
very, 2
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
the, 1
very, 2
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
Combined
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 2
Sorted
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 2
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 2
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
the, 1
very, 2
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
Combined
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 2
Sorted
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 2
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
2 "phases" where we parallelize work
- map the input to some intermediate data representation
- reduce the intermediate data representation into final result
Example: Counting Word Frequencies
The first phase focuses on finding, and the second phase focuses on summing. So the first phase should only output 1s, and leave the summing for later.
Example: "the very very quick fox greeted the brown fox"
the very very
quick fox greeted
the brown fox
the, 1
very, 2
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
...
the, 1
very, 1
very, 1
Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
Combined
Sorted
2 "phases" where we parallelize work
- map the input to some intermediate data representation
- reduce the intermediate data representation into final result
the, 1
very, 1
very, 1
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
Combined
Sorted
the, 1
very, 1
very, 1
quick, 1
fox, 1
greeted, 1
the, 1
brown, 1
fox, 1
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
Question: is there a way to parallelize this operation as well?
Idea: have each map task separate its data in advance for each reduce task. Then each reduce task can combine and sort its own data.
Example: Counting Word Frequencies
Idea: have each map task separate its data in advance for each reduce task. Then each reduce task can combine and sort its own data.
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
bucket 2
bucket 3
fox, 1
greeted, 1
quick, 1
bucket 1
bucket 2
brown, 1
fox, 1
the, 1
bucket 1
bucket 2
bucket # = hash(key) % R where R = # reduce tasks (3)
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
Example: Counting Word Frequencies
Input
Files
Map
Phase
Intermediate
Files
Reduce
Phase
Output
Files
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
bucket 2
bucket 3
fox, 1
greeted, 1
quick, 1
bucket 1
bucket 2
brown, 1
fox, 1
the, 1
bucket 1
bucket 2
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
Parallelizing Programs
Task: we have webpages, and want to make a list of what webpages link to a given URL.
Possible Approach: program that reads webpages and builds a URL -> list(webpage) map
How can we parallelize this?
Idea: split webpages into groups, find URLs in each group concurrently
Problem: what if a URL appears in multiple groups? We need to then merge the lists.
Idea: use hashing to split the intermediate output by reduce task, and have each reduce task merge, sort and reduce concurrently.
Example: Inverted Web Index
Idea: split webpages into groups, find URLs in each group concurrently. Then, use hashing to split the intermediate output, and reduce each piece concurrently.
Example: 3 webpages (1 per group): a.com, b.com, c.com
a.com: Visit d.com for more! Also see e.com.
b.com: Visit a.com for more! Also see e.com.
c.com: Visit a.com for more! Also see d.com.
a.com, b.com
a.com, c.com
d.com, a.com
d.com, c.com
e.com, a.com
e.com, b.com
a.com, [b.com, c.com]
d.com, [a.com, c.com]
e.com, [a.com, b.com]
d.com, a.com
e.com, a.com
bucket 2
bucket 3
a.com, b.com
e.com, b.com
bucket 1
bucket 3
d.com, c.com
bucket 1
bucket 2
a.com, c.com
Example: Inverted Web Index
a.com: Visit d.com for more! Also see e.com.
b.com: Visit a.com for more! Also see e.com.
c.com: Visit a.com for more! Also see d.com.
a.com, b.com
a.com, c.com
d.com, a.com
d.com, c.com
e.com, a.com
e.com, b.com
a.com, [b.com, c.com]
d.com, [a.com, c.com]
e.com, [a.com, b.com]
d.com, a.com
e.com, a.com
bucket 2
bucket 3
a.com, b.com
e.com, b.com
bucket 1
bucket 3
d.com, c.com
bucket 1
bucket 2
a.com, c.com
2 "phases" where we parallelize work
- map the input to some intermediate data representation
- reduce the intermediate data representation into final result
Example: Inverted Web Index
a.com: Visit d.com for more! Also see e.com.
b.com: Visit a.com for more! Also see e.com.
c.com: Visit a.com for more! Also see d.com.
a.com, b.com
a.com, c.com
d.com, a.com
d.com, c.com
e.com, a.com
e.com, b.com
a.com, [b.com, c.com]
d.com, [a.com, c.com]
e.com, [a.com, b.com]
d.com, a.com
e.com, a.com
bucket 2
bucket 3
a.com, b.com
e.com, b.com
bucket 1
bucket 3
d.com, c.com
bucket 1
bucket 2
a.com, c.com
Input
Files
Map
Phase
Intermediate
Files
Reduce
Phase
Output
Files
Parallelizing Programs
Case Study: Counting Word Frequencies
Standard Approach: program that reads document and builds a word -> frequency map
Parallel Approach: split document into pieces, count words in each piece concurrently, partitioning output. Then, sort and reduce each chunk concurrently.
Case Study: Inverted Web Index
Standard Approach: program that reads webpages and builds a URL -> list(webpage) map
Parallel Approach: split webpages into groups, find URLs in each group concurrently, partitioning output. Then, sort and reduce each chunk concurrently.
Parallelizing Programs
Word frequencies: split document into pieces, count words in each piece concurrently, partitioning output. Then, sort and reduce each chunk concurrently.
Inverted web index: split webpages into groups, find URLs in each group concurrently, partitioning output. Then, sort and reduce each chunk concurrently.
We expressed these problems in this two step structure:
- map the input to some intermediate data representation
- reduce the intermediate data representation into final result
Not all problems can be expressed in this structure. But if we can express it in this structure, we can parallelize it!
Plan
- Motivation: parallelizing computation
- What is MapReduce?
- Further Research
- Optional: Implement your own MapReduce!
MapReduce is a library that runs an operation in parallel for you if you specify the input, map step and reduce step.

Published by Google in 2004. Read it [here].
MapReduce
- Goal: a library to make running programs across multiple machines easy
- Many challenges in writing programs spanning many machines, including:
- machines failing
- communicating over the network
- coordinating tasks
- etc.
- MapReduce handles these challenges! The programmer just needs to express their problem as a MapReduce program (map + reduce steps) and they can easily run it with the MapReduce library.
- Example of how the right abstraction can revolutionize computing
- An open source implementation immediately appeared: Hadoop (not optimized well...)
MapReduce
Programmer must implement map and reduce steps:
map(k1, v1) -> list(k2, v2)
reduce(k2, list(v2)) -> list(v2)
Here's pseudocode for the word counting example:
map(String key, String value):
// key: document name
// value: document contents
for word w in value:
EmitIntermediate(w,"1")
reduce(String key, List values):
// key: a word
// values: a list of counts
int result = 0
for v in values:
result += ParseInt(v)
Emit(AsString(result))MapReduce Terminology
map(k1, v1) -> list(k2, v2)
reduce(k2, list(v2)) -> list(v2)
- map step - the step that goes from input data to intermediate data
- reduce step - the step that goes from intermediate data to output data
- worker - a machine that performs map or reduce tasks
- leader [master] - a machine that coordinates all the workers
- task - a single piece of work (either mapping or reducing) that a worker does
MapReduce Process
- User specifies information about the job they wish to run, such as:
- input data
- map step code
- reduce step code
- # map tasks M (perhaps set to reach some target size for task data)
- # reduce tasks R (perhaps set to reach some target size for task data)
- MapReduce partitions input data into M pieces, starts program running on cluster machines - one will be leader, rest will be workers
- Leader assigns tasks (map or reduce) to idle workers until job is done
- Map task - worker reads slice of input data, calls map(), output is partitioned into R partitions on disk with hashing % R. The leader is given the location of these partitions.
- Reduce task - reducer is told by leader where its relevant partitions are, it reads them / sorts them by intermediate key. For each intermediate key and set of intermediate values, calls reduce(), output is appended to output file.
- If a worker fails during execution, the leader re-runs and reallocates tasks to other workers.
Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
bucket 2
bucket 3
fox, 1
greeted, 1
quick, 1
bucket 1
bucket 2
brown, 1
fox, 1
the, 1
bucket 1
bucket 2
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
- User specifies information about the job they wish to run:
- input data -> the very very quick fox greeted the brown fox
- map step code -> see at right
- reduce step code -> see at right
- # map tasks M = 3
- # reduce tasks R = 3
map(String key, String value):
// key: document name
// value: document contents
for word w in value:
EmitIntermediate(w,"1")
reduce(String key, List values):
// key: a word
// values: a list of counts
int result = 0
for v in values:
result += ParseInt(v)
Emit(AsString(result))Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
bucket 2
bucket 3
fox, 1
greeted, 1
quick, 1
bucket 1
bucket 2
brown, 1
fox, 1
the, 1
bucket 1
bucket 2
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
2. MapReduce partitions input data into M (=3) pieces, starts program running on cluster machines - one will be leader, rest will be workers
map(String key, String value):
// key: document name
// value: document contents
for word w in value:
EmitIntermediate(w,"1")
reduce(String key, List values):
// key: a word
// values: a list of counts
int result = 0
for v in values:
result += ParseInt(v)
Emit(AsString(result))Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
bucket 2
bucket 3
fox, 1
greeted, 1
quick, 1
bucket 1
bucket 2
brown, 1
fox, 1
the, 1
bucket 1
bucket 2
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
3. Leader assigns tasks (map or reduce) to idle workers until job is done.
map(String key, String value):
// key: document name
// value: document contents
for word w in value:
EmitIntermediate(w,"1")
reduce(String key, List values):
// key: a word
// values: a list of counts
int result = 0
for v in values:
result += ParseInt(v)
Emit(AsString(result))Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
bucket 2
bucket 3
fox, 1
greeted, 1
quick, 1
bucket 1
bucket 2
brown, 1
fox, 1
the, 1
bucket 1
bucket 2
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
Map task - worker reads slice of input data, calls map(), output is partitioned into R (=3) partitions on disk with hashing % R. The leader is given the location of these partitions.
map(String key, String value):
// key: document name
// value: document contents
for word w in value:
EmitIntermediate(w,"1")
reduce(String key, List values):
// key: a word
// values: a list of counts
int result = 0
for v in values:
result += ParseInt(v)
Emit(AsString(result))Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
bucket 2
bucket 3
fox, 1
greeted, 1
quick, 1
bucket 1
bucket 2
brown, 1
fox, 1
the, 1
bucket 1
bucket 2
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
Reduce task - reducer is told by leader where its relevant partitions are, it reads them / sorts them by intermediate key. For each intermediate key and set of intermediate values, calls reduce(), output is appended to output file.
map(String key, String value):
// key: document name
// value: document contents
for word w in value:
EmitIntermediate(w,"1")
reduce(String key, List values):
// key: a word
// values: a list of counts
int result = 0
for v in values:
result += ParseInt(v)
Emit(AsString(result))Example: Counting Word Frequencies
the very very
quick fox greeted
the brown fox
the, 1
very, 1
very, 1
bucket 2
bucket 3
fox, 1
greeted, 1
quick, 1
bucket 1
bucket 2
brown, 1
fox, 1
the, 1
bucket 1
bucket 2
brown, 1
fox, 1
fox, 1
greeted, 1
quick, 1
the, 1
the, 1
very, 1
very, 1
brown, 1
fox, 2
greeted, 1
quick, 1
the, 2
very, 2
Leader assigns tasks (map or reduce) to idle workers until job is done.
map(String key, String value):
// key: document name
// value: document contents
for word w in value:
EmitIntermediate(w,"1")
reduce(String key, List values):
// key: a word
// values: a list of counts
int result = 0
for v in values:
result += ParseInt(v)
Emit(AsString(result))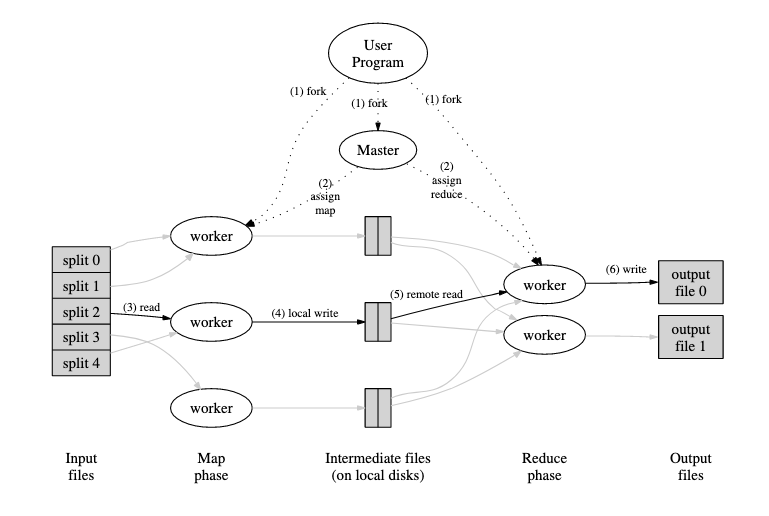
MapReduce Diagram
MapReduce Notes
- We have to execute map code before reduce code, because maps may all feed into a single reduce.
- The number of workers is separate from the number of tasks; e.g. in the word count example, we could have 1, 2, 3, 4, ... etc. workers. A worker can execute multiple tasks, and tasks can run anywhere.
- MapReduce library handles parallel processing, networking, error handling, etc...
- MapReduce relies heavily on keys to distribute load across many machines while avoiding moving data around unnecessarily.
- Hashing lets us collect keys into larger units of work
- for N tasks, a key K is the responsibility of the task whose ID is hash(K) % N
- All data with the same key is processed by the same reduce task
- Hashing lets us collect keys into larger units of work
Plan
- Motivation: parallelizing computation
- What is MapReduce?
- Further Research
- Optional: Implement your own MapReduce!
Further Research
MapReduce was one framework invented to parallelize certain kinds of problems. There are many other ways to process large datasets, and MapReduce must make tradeoffs.
- must consider network traffic that MapReduce causes - too much?
- what if the leader fails?
- Leader can become a bottleneck - what if it cannot issue tasks fast enough?
(In practice, MapReduce doesn't face this, but other frameworks like Spark do) - what about jobs that don't fit the map-reduce pattern as well? (Spark)
- Can we do better than MapReduce?
- Research project from Phil Levis (Stanford CS) and others -> "Nimbus"
Further Research - Bottlenecks
- Leader can become a bottleneck - what if it cannot issue tasks fast enough?
(In practice, MapReduce doesn't face this, but other frameworks like Spark do) - "Control plane" -> sending messages to spawn tasks to compute
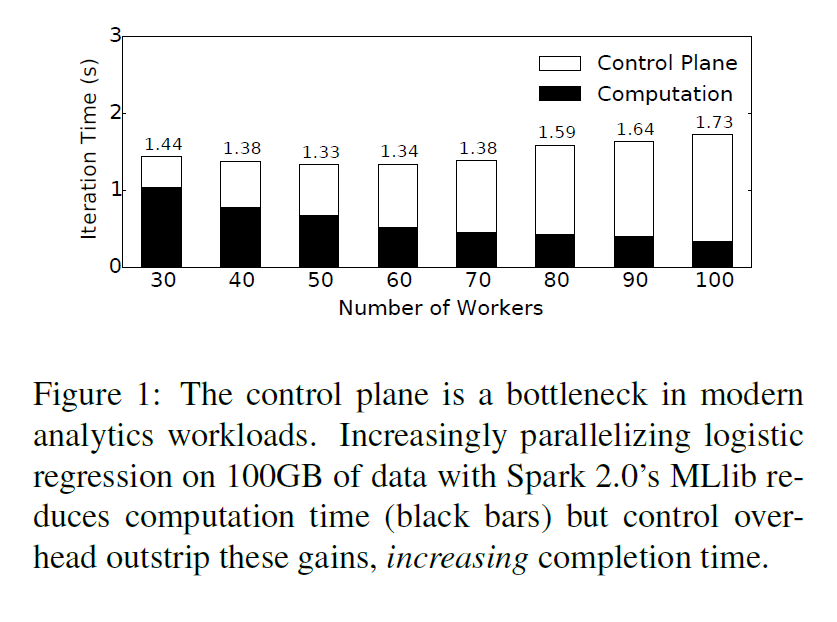
"Execution Templates: Caching Control Plane Decisions for
Strong Scaling of Data Analytics"
Omid Mashayekhi, Hang Qu, Chinmayee Shah, Philip Levis
In Proceedings of 2017 USENIX Annual Technical Conference (USENIX ATC '17)
Further Research - Bottlenecks
- Leader can become a bottleneck - what if it cannot issue tasks fast enough?
(In practice, MapReduce doesn't face this, but other frameworks like Spark do) - "Control plane" -> sending messages to spawn tasks to compute
- Idea - what if there are only workers, and no leader?
- What if a worker fails? How do you coordinate?
- How do you load balance?
Further Research - Bottlenecks
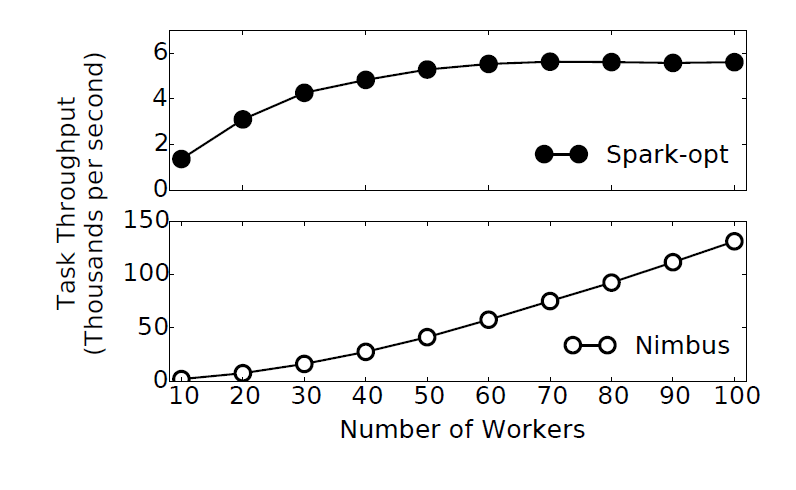
Idea: what about caching?
- Caching control plane messages allows Nimbus to scale to support over 100,000 tasks/second, while Spark bottlenecks around 6,000
- Caching control plane messages (Nimbus) is as fast as systems that do not have a centralized master (Naiad-opt), and much faster than systems which have a centralized master but do not cache messages (Spark-opt)
Plan
- Motivation: parallelizing computation
- What is MapReduce?
- Further Research
- Optional: Implement your own MapReduce!
Your Own MapReduce
There is an optional assignment where you implement your own version of MapReduce!
- combines networking, multiprocessing, multithreading
You implement the standard MapReduce design, with scaffolding and a few differences:
- intermediate files aren't saved locally and fetched - we rely on AFS
- e.g. if myth53 is mapping and myth65 is reducing, if myth53 creates a file then it's automatically also on myth65 because AFS is a networked filesystem! No need to transmit over the network ourselves. But means lots of network traffic.
- you specify # mappers and # reducers, not # workers
- you provide sliced input files, and that determines # map tasks
- # reduce tasks = # mappers x # reducers
- Demo time!
Recap
- Motivation: parallelizing computation
- What is MapReduce?
- Further Research
- Optional: Implement your own MapReduce!
CS110 Case Study: MapReduce (w21)
By Nick Troccoli



