i18n for Web Developers
intro to
Me
Jared Anderson
ICS Stack Team
LDS Church
not an i18n expert
but I did stay in attend a unicode conference
🙄
i18n & l10n
what the h2k?
i18n & l10n
internationalization and localization are means of adapting computer software to different languages, regional differences and technical requirements of a target locale
the design and development of a product, application or document content that enables easy localization for target audiences that vary in culture, region, or language.
INTERNATIONALIZATION (I18N)
LOCALIZATION (L10N)
the adaptation of a product, application or document content to meet the language, cultural and other requirements of a specific target market (a locale).
i18n
- adaptable
- flexible
- enabling
l10n
- a specific adaption
we write software this way
To Allow for Localization
so "they" can configure it to a target locale
i18n
- allowing Unicode
- separating content from source code
- no hardcoded strings
- careful string concatenation
- customizable currency preferences
- customizable date/time preferences
For EXAMPLE
l10n
- displaying/storing Kanji characters
- translating English content to Japanese (sans developer)
- injecting in Japanese strings bundle
- converting USD to yen currency (or just starting from yen)
allows for
i18n efforts enabling a Japanse i10n
L10N Customizations & Considerations
- language / translation
- text / writing systems
- text & UI direction
- number formats
- numeral systems
- date and time formats
- calendar systems
- currency systems
- keyboard usage
- collation and sorting
- symbols, icons and colors
- diverse cultural interpretation of graphics and action-text
- varying legal requirements
- rethinking of logic
- visual design
- and more...
Text, Writing Systems & Unicode
the foundation
Written Communication
h e l l o

h e l l o
h e l l o

h e l l o
0110 1000 0110 0101 0110 1100 0110 1100 0110 1111
we agree on meaning?
computers agree on meaning?
Unicode provides a unique number for every character,
no matter what the platform,
no matter what the program,
no matter what the language.
The Unicode Standard
- A standard for text
- provides a unique number (called a code point) for every character
- replaces ASCII, UC-2, 8-bit, double-byte and 240 other “standards”
- covers all known business languages today (& then some)
The Unicode Standard

Every character in unicode contains data describing its characteristics such as its:
- Code Point (that's the number)
- Name
-
General Category
- Letter, Mark, Number, Symbol, Separator, etc
- Punctuation
- Bidi properties
The Unicode Standard
717,993
- ASCII: room for 128 code points
- Unicode: room for 1,114,112 code points 😱
- 2^16 * 17
Fun Fact
The Unicode Standard
- Unicode 10.0 (June 2017) added 8,518 characters, for a total of 136,690 characters.
- These additions include 4 new scripts, for a total of 139 scripts, as well as 56 new emoji characters.
The Unicode Standard
Fun Fact
The Unicode Standard
Fun Facts
- 1,114,112 (2^16 * 17) code points
- divided into 17 planes
- each plane contains 65,536 (2^16) code points
- the first plane, plane 0, is called the Basic Multilingual Plane (BMP)
- contains all the most common characters
- smaller code points
- the other 16 planes (1-16) are called Astral or Supplementary
- contains emoji, symbols, less commonly used chars
- higher code-points = more "space" required
important to know
ignore & ☠️
Character
a single logical unit of text
- includes things like: A B 1 2 😆 🤡 ⻯ ` ̃
Array
.from("AB12😆🤡⻯` ̃")
.map(c => `${c.codePointAt(0)} is ${c}`)
/*
[ '65 is A',
'66 is B',
'49 is 1',
'50 is 2',
'128518 is 😆',
'129313 is 🤡',
'12015 is ⻯',
'96 is `',
'32 is ',
'771 is ̃' ]
/*Character, Grapheme, Glyph, Ligature
ideograms, logograms, pictographs 🤕
"👨👩👧👦".replace("👦", "")a. 👨👩👧👦
b. 👨👩👧
c. 👨👩👧
d. ""
Pop Quiz
when two+ sequential graphemes are represented by one glyph.
Grapheme
the smallest unit of a writing system of any given language; user perceived characters
-
may be a single Unicode code points or multiple, component glyphs positioned appropriately
-
letters, numbers, punctuation, CJK characters, symbols, etc
a single visual unit of text
- one character may have multiple Glyphs.
- sometimes, 2+ characters side by side are represented by a single glyph.
LIGATURE
GLYPH


PlayGround
Character Encoding
from zeroes & ones to other zeroes & ones
"💩u"[0] === "u"
"💩u"[1] === "u"
"💩u"[2] === "u"a. true false false
b. false true false
c. false false true
d. false false false
Pop Quiz
"🥓=❤".indexOf("=")a. 0
b. 1
c. 2
d. 3
1
2
| char | code point (decimal) | code point (binary) |
|---|---|---|
| a | 65 | 00000000 00000000 01000001 |
| 🥓 | 129,363 | 00000001 11111001 01010011 |
| [not used] | 1,114,111 | 00010000 11111111 11111111 |
inefficient to transport, put in memory or store all these zeros, so we encode them
a🥓
00000000 00000000 01000001
00000001 11111001 01010011
Encoding
Unicode Encoding
- UTF-8: variable width. 1-4 bytes. ASCII is valid UTF-8. Most popular for web documents.
- UTF-16: variable width. 2 or 4 bytes with "surrogate" pairs when 4 bytes.
- UTF-32: same width. 32-bit code units. Inefficient storage / less common.
algorithmic mapping from every Unicode code point to a unique, physical bit sequence, called code unit
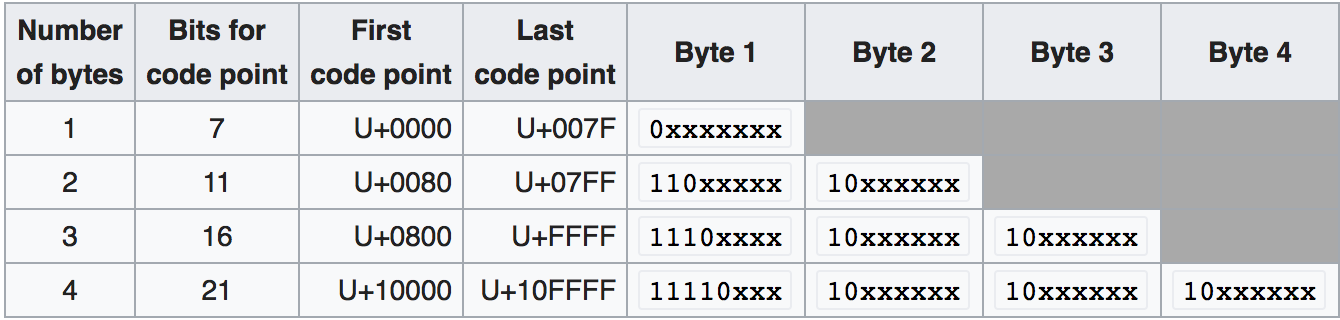
utf-8 encoding algorithm
2^7 = 127
2^11 = 2,048
2^16 = 65,536
2^21 = 2,097,152
"💩u"[2] === "u"so back to this problem....
Javascript uses a 2-byte, fixed-width encoding to store each character. This encoding translates roughly to a UC-2 / UTF-16 Frankenstein monster
UTF-16
- variable width, 2 or 4 bytes
- 2 bytes: all the most common characters (most of the BMP plane)
- 4 bytes: less common characters (the Astral plane)
- encoded using special markings to denote surrogate pairs
- informs if char is a 2-byte or 2x2-byte character
UC-2/UTF-16 JS Encoding
- sort of like UTF-16, but defers actual decoding
- surrogate pairs are only recombined into a single Unicode character when they’re displayed by the browser (during layout).
- happens outside of the JS engine
'𝌆'.length === 2;
'\uD834'.concat('\uDF06');explore more?
JS Frankencoding
Solution
be aware, be careful, use a modern, Unicode-aware JS APIs, and/or a 3rd-party lib
[..."💩u"][0] === "💩"
[..."💩u"][1] === "u"
[..."💩u"][2] === undefinedfor( const symb of "💩u" ) {
console.log(symb);
}
Good Advice
Strings: sequence of Glyphs
Strings: sequence of Code Units
String Normalization
"ñ".length === 1;without running the code, is this true or false?
Pop Quiz
a. true
b. false
c. literally nobody knows
const string1 = "ñ";
const string2 = "ñ";
console.log(
`string1 (${string1}) and string2 (${string2}) double equal?: `,
string1==string2,
);
console.log(
`string1 (${string1}) and string2 (${string2}) triple equal?: `,
string1===string2,
);a. true, true
b. true, false
c. false, true
d. false, false
Pop Quiz
Combining Character
characters that are intended to modify other characters
- In the Latin script, combining diacritical marks (including combining accents) is most common
- Many CJK symbols are constructed using combining characters
t̴̨̲̫̫͙̩̙̖̥̘̙̜̓̇͌̊̓̉͆̏̓͂̅̏̚̕͜͠ͅh̶̳̠̝̭̀̐̂̃̐̋̓̐̽͋͑̇̑̀̚ͅe̸͔̻̱̝̯̜̟̭̝͓͋͋̇̍̊̍̑̄͜͜͝͝ ̵̳̠̞̞̙̜̳͕̞̱̖̺̺̜̐̍m̶͉̝͖͚̳̙̠̀̔͌̇̋̇͛̃̋̽̈̓̆͝͠a̶̹̩̦̐͛̐̀t̴̨̼͓̫̳͔̤́̉̐̿͋̿̓͋r̴̡̘͚̩̜̳͎͍͎͎̼͕͎͇̲̽̍͗i̸̡̩̻̠̼͉̳̘͔̲͔̩͂̂̔͌̍̕͝x̷͔̞̫͇͆̈͛̓̋̌͗͛͒̚͜
Try It
n + ̃ = ñ (copy/paste individually)
"n".concat("\̃")
Fun Fact
String Comparison is NOT Simple
there are many correct ways to construct a string with the same canonical meaning
For example, there are 3 correct ways to make an Angstrom character (Å)
- U+00C5 (Å)
- U+0041 (A) +U+030A (\̊) = Å
- U+212B (Å)
"Å" === "Å" && "Å" === "Å"try it?
String.prototype.normalize
const string1 = "ñ";
const string2 = "ñ";
console.log(
`string1 (${string1}) and string2 (${string2}) compare?: `,
string1 === string2
);
console.log(
`normalized string1 (${string1}) and normalized string2 (${string2}) compare?: `,
string1.normalize() === string2.normalize()
);
"Å".normalize() === "Å".normalize() && "Å".normalize() === "Å".normalize()try it?
4 Ways to Normalize (TMI?)
Composed (NFC)
decomposed and then recomposed by canonical equivalence (same look & meaning). Recommended by W3C & default for String.prototype.normalize
Decomposed (NFD)
decomposed by canonical equivalence and then arrange combining characters in a specific order.
Compatible Composed (NFKC)
decomposed by compatibility (maybe look different, same meaning sometimes), then recomposed by canonical equivalence. Used by IETF for domain names
Compatible Decomposed (NFKD)
decomposed by compatibility, and multiple combining characters are arranged in a specific order
"fluff.com" === "fluff.com"
"fluff.com".normalize() === "fluff.com".normalize()
"fluff.com".normalize("NFKC") === "fluff.com".normalize("NFKC")try it?
pretty fly for a
BIDI
<div dir="rtl">ABC123</div>How will this render in the browser?
Pop Quiz
a. ABC123
b. 321CBA
c. CBA123
d. 123CBA
Answer
Base Direction
the direction that the bidirectional algorithm falls back on when calculating how it should display
- is set with a `dir` attribute
- defaults to LTR when not explicitly set.
<div dir="rtl">12345, 🙈🙉🙊!</div>How will this render in the browser?
Pop Quiz
a. 12345, 🙈🙉🙊!
b. !🙊🙉🙈 ,54321
c. !🙊🙉🙈 ,12345
d. just shut up and tell me
Answer 🤯
Bidirectional Text
languages that are read from right-to-left (RTL) aren't 100% RTL
- quoting "latin characters" is LTR
- numbers are rendered LTR
simply writing (anywhere) a "ש", followed by a "ר", followed by a "ה" renders how?
Pop Quiz
a. שרה
b. שרה
BUILT IN Unicode BIDI Properties
-
strongly typed: characters with strongly typed LTR or RTL direction will display its strongly typed direction regardless of base direction
- Latin Characters (ABCD) are strongly typed LTR
- Arabic & Hebrew (שרה) are strongly typed RTL
-
always display in their direction unless explicitly overridden
-
neutrally typed: directionality indeterminable without context.
- most white-space characters and some punctuation.
- when between 2 strongly typed chars of same directionality, assumes that directionality
- when between 2 strongly typed characters of different directionality, assumes prevailing base direction
- most white-space characters and some punctuation.
-
weakly typed: characters with vague directionality
- european digits (1234) & arabic-indic digits (١٢٣٤)*
- arithmetic and currency symbols
- punctuation common to many scripts (:,)
we input the following characters in the following logical order; it renders how?
- "a"
- "b"
- "c"
- " " (space)
- "ש"
- "ר"
- "ה"
Pop Quiz
1.
abc שרה
2.
abc שרה
3.
neither
answer: either 1 or 2 depending on the base direction
Directional Run
When text with different directionality is mixed inline, the bidi algorithm produces a separate directional run out of each sequence of contiguous characters with the same directionality (no markup required)
the order in which directional runs are displayed across the page depends on the prevailing base direction.
<div dir="rtl">
<bdi>></bdi>>
</div>
How will this render in the browser?
Pop Quiz
a. >>
b. <<
c. ><
d. <>
Mirrored Characters
Certain characters have mirror-imaged shapes, depending on the direction of the text where they are found. For example, parenthesis and brackets have mirrored pairs that are used when direction changes.
Explore Mirrored Characters
bidirectional isolation (<bdi>)
isolates a span of text that might be formatted in a different direction from other text outside it. No effect on directionally-strong characters
bidirectional Overrides (<bdO>)
overrides the current directionality of text, so that the text within is rendered in a different direction.
- affects directionally-strong characters
- render order, does not cause them to mirror
- affects mirrored characters
Explore Isolates and Overrides
Language & Locale Codes
ISO 639
is a set of standards by the International Organization for Standardization that is concerned with representation of names for languages and language groups.
| language | ISO 639-1 | ISO 639-3 |
|---|---|---|
| English | en | eng |
| Spanish | sp | spa |
IETF Language Tag
an abbreviated language code defined by the Internet Engineering Task Force (IETF) in the BCP-47 document series which is currently composed of normative RFC 5646 and RFC 4647, along with the normative content of the IANA Language Subtag Registry 😅
| Description | IETF Language Tag |
|---|---|
| English | en |
| Spanish | sp |
| Brazilian Portuguese | pt-BR |
| Min Nan Chinese as spoken in Taiwan using traditional Han characters | nan-Hant-TW |
IETF Language Tag
Components of language tags are drawn from ISO 639, ISO 15924, ISO 3166-1, and UN M.49.
for language codes, it wants "shortest ISO 639 code"
- uses 2-digit country code (ISO 639-1) when available
- falls back to 3-digit (ISO 639-3) code when not.
Provides an authoritative list of language codes at:
https://www.iana.org/assignments/language-subtag-registry/language-subtag-registry
IETF Language Tag
Used by/in:
- HTTP
- W3C
- HTML
- XML
- PNG
- ANSI
- ECMA
- Unicode
in the Window
window.navigator.language
In JavaScript
Intl.NumberFormat
Intl.DateTimeFormat
Intl.Collator
Intl.PluralRules
HTTP
|
Accept-Language Content-Language |
IETF LANGUAGE TAG: As Experienced by Web Devs
In HTML
<html lang="">
In CSS
:lang()
IN JS Libraries
|
MomentJS GlobalizeJS |
IETF LANGUAGE TAG

The golden rule when creating language tags is to keep the tag as short as possible.
Avoid region, script or other subtags except where they add useful distinguishing information. For instance, use ja for Japanese and not ja-JP, unless there is a particular reason that you need to say that this is Japanese as spoken in Japan, rather than elsewhere.
Converting Formats
import langs from "langs";
langs.where("3", "kor");
/*
{
"name":"Korean",
"local":"한국어",
"1":"ko",
"2":"kor",
"2T":"kor",
"2B":"kor",
"3":"kor"
}
*/Regular Expressions
it's all about u
/a.b/.test("a𝌆b")true of false?
Pop Quiz
a. true
b. false
c. ?
/a.b/u.test("a𝌆b")false
why? no u
/𝌆{2}/.test('𝌆𝌆');true of false?
Pop Quiz
a. true
b. false
c. ?
/𝌆{2}/u.test('𝌆𝌆')false
why? no u
/^[^a]$/.test("💩")true of false (do I really need u here)?
Pop Quiz
a. true
b. false
c. ?
/^[^a]$/u.test("💩")false
yes you need u
the /u flag is an ES6 feature, but Babel will convert it
Fun Fact
Babel and U
More tO Come
UNicode Property Escapes
stage 3 feature
\p{UnicodePropertyName=UnicodePropertyValue}
\p{UnicodePropertyNameAlias=UnicodePropertyValueAlias}
\p{LoneUnicodePropertyNameOrValue}
/^\p{Decimal_Number}+$/u
.test('𝟏𝟐𝟑𝟜𝟝𝟞𝟩𝟪𝟫𝟬𝟭𝟮𝟯𝟺𝟻𝟼');
/^\P{Decimal_Number}+$/u
.test('Իմ օդաթիռը լի է օձաձկերով');
/^\p{Number}+$/u
.test('²³¹¼½¾𝟏𝟐𝟑𝟜𝟝𝟞𝟩𝟪𝟫𝟬𝟭𝟮𝟯𝟺𝟻𝟼㉛㉜㉝ⅠⅡⅢⅣⅤⅥⅦⅧⅨⅩⅪⅫⅬⅭⅮⅯⅰⅱⅲⅳⅴⅵⅶⅷⅸⅹⅺⅻⅼⅽⅾⅿ');
Language Translation
const createName = ({firstName, lastName}) =>
`${firstName} ${lastName}`;
what name comes first?
what's a last name?
what's wrong with this?
const createMessage = ({greeting, name, message}) => `
${greeting} ${name},
${message}
`;are you sure about that comma?
what's wrong with this?
// Hey translation team, can you translate
// my strings bundle?
const strings = {
home: "Home",
date: "Date"
};Date: courtship or calendar?
what's wrong with this?
Translation
- careful with string concatenation
- no hardcoded strings
- translators need context
Date Formatting
const d = new Date();
d.toLocaleDateString();
d.toLocaleTimeString();
Intl.DateTimeFormat('en-US')
.format(d);
Intl.DateTimeFormat('en-US', {
weekday: 'long',
year: 'numeric',
month: 'long',
day: 'numeric'
})
.format(d);
Built In
Built In SUpport
Jan 2018
Playground
Date Libraries
- MomentJS
- date-fns
- GlobalizeJS
Number Formatting
var number = 3500;
new Intl.NumberFormat()
.format(number);Built In
Playground
Built In SUpport
Jan 2018

Number Libraries
- GlobalizeJS
Collation & Sorting
[string1, string2, string3].sort()should I do this?
Pop Quiz
a. no
b. no
Why?
Sorting strings by their code point only works for ASCII
[string1, string2, string3].sort(
(a, b) => a.localeCompare(b)
);Solution
[string1, string2, string3]
.sort(
(a, b) => new Intl.Collator("es")
.compare(a, b)
);
Solution
Common Locale Data REPO
tl;dr: cldr
Unicode CLDR
provides key building blocks for software to support the world's languages, with the largest and most extensive standard repository of locale data available
Building Blocks
- Locale-specific patterns for formatting and parsing: dates, times, timezones, numbers and currency values
- Translations of names: languages, scripts, countries and regions, currencies, eras, months, weekdays, day periods, timezones, cities, and time units
- Language & script information: characters used; plural cases; gender of lists; capitalization; rules for sorting & searching; writing direction; transliteration rules; rules for spelling out numbers; rules for segmenting text into graphemes, words, and sentences
- Country information: language usage, currency information, calendar preference and week conventions, and telephone codes
- Other: ISO & BCP 47 code support (cross mappings, etc.), keyboard layouts
ICU
International Components for Unicode (ICU)
an open source project of mature C/C++ and Java libraries for Unicode support, software internationalization, and software globalization
- parts are built into core NodeJS (may require a special Node build) and browser JS (Intl)
International Components for Unicode (ICU)
- Code Page Conversion
- Collation
- Formatting
- numbers
- dates
- times
- currency
- Time Calculations
- Unicode Support
- Regular Expressions
- BiDi
- Text Boundaries
Internal Help
i18n.ldschurch.org
i18n@ldschurch.org
Sources
https://kev.inburke.com/kevin/node-js-string-encoding/
https://mathiasbynens.be/notes/javascript-encoding
https://www.w3.org/International/questions/qa-what-is-encoding
https://dmitripavlutin.com/what-every-javascript-developer-should-know-about-unicode/
i18n for web developers
By Jared Anderson




