
I'm Uvindu Perera
Hello !
ආයුබෝවන් !
CC @ MozillaNSBM
im@uvix.me
https://www.linkedin.com/in/uvindu-perera

"Mozilla crowdsources the largest dataset of human"
voices available for use, including 18 different languages, adding up to almost 1,400 hours of recorded voice data from more than 42,000 contributors.
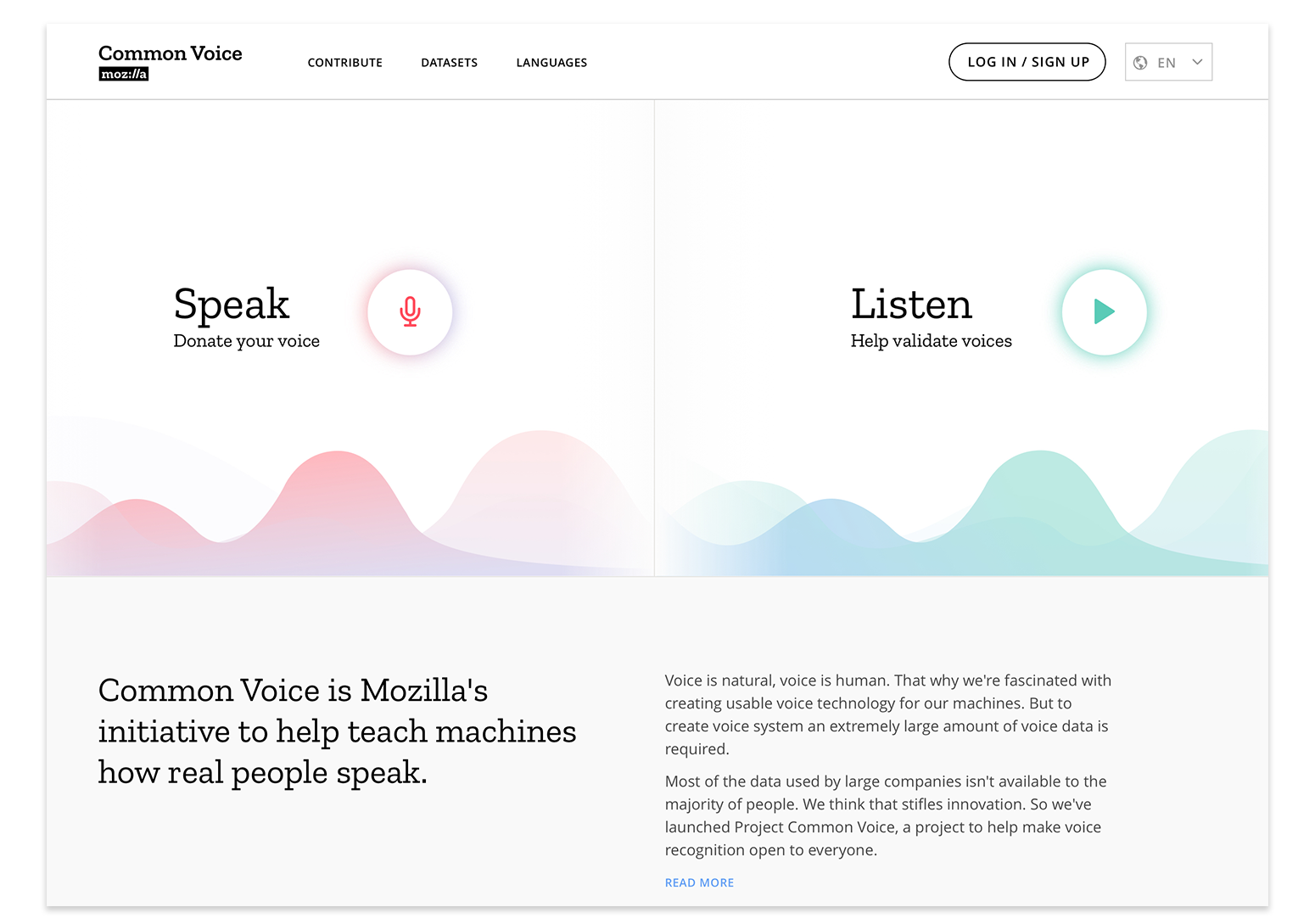
From the onset, our vision for Common Voice has been to build the world’s most diverse voice dataset, optimized for building voice technologies. We also made a promise of openness: we would make the high quality, transcribed voice data that was collected publicly available to startups, researchers, and anyone interested in voice-enabled technologies.

Today, we’re excited to share our first multi-language dataset with 18 languages represented, including English, French, German and Mandarin Chinese (Traditional), but also for example Welsh and Kabyle. Altogether, the new dataset includes approximately 1,400 hours of voice clips from more than 42,000 people.

IS IT
Real?
Free?
YEAH..!
Let's Have A Look


Yeah How Can I Help You?
Can I Have A DataSet?

Follow Me !
VISIT

https://voice.mozilla.org/en/datasets
WoW That's Amazing !
How Can I Help As A Mozillian?

One
Two
Three
voice.mozilla.org

Thank You !
deck
By Uvindu Perera



