Things that make and break Clojure code analysis
Opinions
- We mostly don't write code, we read it
- We mostly don't read code, we browse it and search it
- usually not for holistic understanding, but incremental investigations in causality
- clarity > aesthetics, although both tend to be correlated
- often overrated: prettiness, brevity, stylistic consistency
- often underrated: contrast, redundancy
Things that help with code analysis
- Simplicity
- Clear names
- Tests
- Comments
- In particular Rich Comments: (comment ...)
- Stacktraces and other traceability information
- Who called me?
- Obvious types
- Explicit bounded context
- in particular the explicit from our own code vs from our libs distinction
- ns aliases help signal that
- Reproducible and observable execution
Names
- Must-reads:
- Elements of Clojure by Zach Tellman (free chapter on naming).
- Readable Clojure by Tonsky
- Names:
- narrow, consistent,
- natural / synthetic
- Fear not the weird characters (contrast!), e.g.:
=my-channel=*my-atom, *my-futuremy+tuplemy-key->my-value<my-react-component>

:name.spaced/keywords
- The unsung heroes of Clojure codebases
- Context-free, non-colliding names
- Easy to search and follow, trivial to refer to
-
:this_namespacing_conventionalso works
Don't: transform keywords
- By trimming the namespace
- By changing the syntax
- (I'm looking at you,
camel->kebab!)
- (I'm looking at you,
- By string-building them
- Keywords are NOT composites
- Don't complect identification and data structure!
- Dynamically transforming of keywords makes you lose the track.
- Keywords should be trivial to follow and rename - don't ruin that.
- the difference between trivial and not impossible is a big deal.
Namespaced keywords: don't
- don't use the same keyword for different types;
- clojure.spec will punish you!
- don't use the same keyword for different semantics;
- don't bike-shed all day over the structure of the keyword (e.g.
:my.namespaced/keyword-conventionvs:my.name.spaced.keyword/convention)- the existential crisis is not worth the time
- what matters is that the keyword is clear, non-colliding and searchable.
Keywords: portability for ubiquity
- Recommendation: use
-
:this.idiomatic/namespacing-conventionfor process-local attributes -
:this_portable_namespacing_conventionfor far-ranging attributes- DB columns, network messages, URI components, etc.
-
- The inconsistency is not a problem: contrast fosters clarity
- universality >> local customs
- https://vvvvalvalval.github.io/posts/clojure-key-namespacing-convention-considered-harmful.html
Things that make us lose track of execution
- Asynchronous/Event-Driven flow control
- incl. core.async channels
- Colliding keywords
- Worst offenders: :id, :name, :type, :n, :value, :key, ...
- Dynamically transforming keywords
- Silencing stacktraces
- Network calls
- Positional semantics (e.g.
(nth my-csv-row 8))
It's just data
- a.k.a Lost In Interpretation
- a.k.a the call-by-fn/call-by-data Dilemma
[:defn :fibonacci [:n]
[:cond
[:= :n 0] 0
[:= :n 1] 1
[:+
[:fibonacci [:- :n 1]]
[:fibonacci [:- :n 2]]]]]Data-orientation is great, until...
- the semantics of the data become less trivial...
- i.e. the language of the data becomes more expressive
- ...then the interpreters we write for the data become more sophisticated...
- ... and we find ourselves with a new programming language.
- But several affordances remain to be reinvented:
- Debugging and monitoring utilities
- Source mapping
- Editor support
- Linters and other static analyzers
- Documentation (usually), coding conventions, familiarity to newcomers
- Language maturity
Symptom
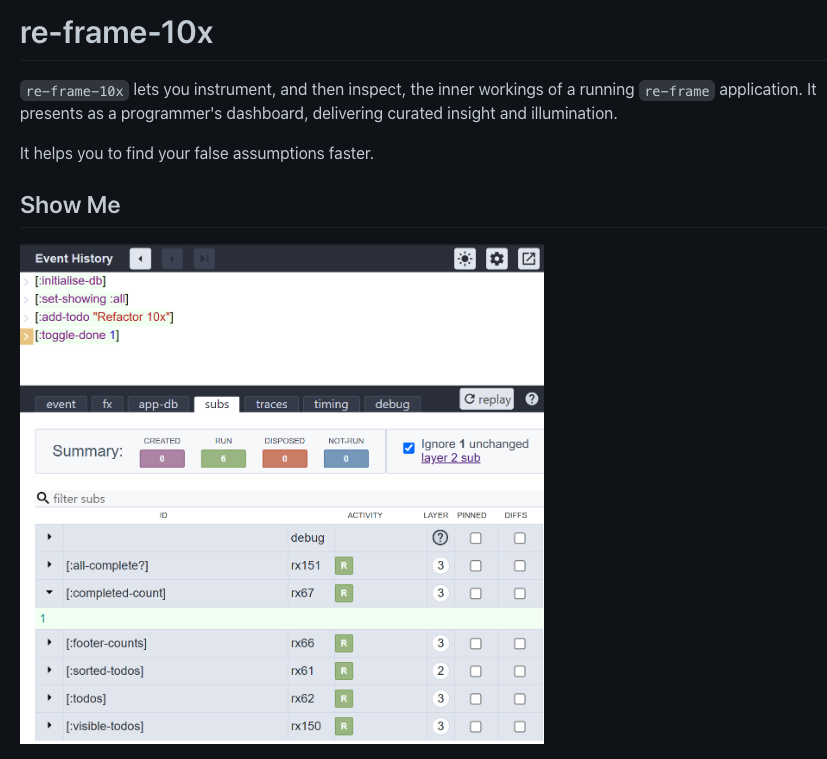
- re-frame-10x is awesome...
- ... by addressing a self-inflicted problem *ducks*
Any sufficiently complicated C or Fortran program contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of Common Lisp.
- Greenspun's 10th Rule
Any sufficiently data-oriented
C or FortranClojure program contains an ad hoc, informally-specified, bug-ridden, slow interpretation of half of Clojure.
The special case of side-effects
- "Side-effects at the edges" compels us to schedule side-effects by building data structures (commands)
- The delayed interpretation of multi-effects commands can make it hard to trace what part of the system requested a given side-effect.
- again, namespaced keywords help
- carrying causality-encoding metadata seems like a promising and under-used approach
- "source-mapping"
- "higher-level stacktraces"
- correlation IDs
The curious case of synchronous read-only data-fetching
- (say, HTTP GET)
- Is fetching (read-only) data across the network really a side-effect?
- I mean, so is moving data from RAM to CPU registers, right?
- Those read-only side-effects might be harmless enough that we can feel free to interleave them in execution.
- (Datomic does that.)
Data-orientation: in summary
- A valuable tool in the toolbox
- With pitfalls and limitations
- "it's data-oriented therefore it must be good" is naive
- It's insightful to recognize that data-orientation consists of:
- inventing data-encoded domain-specific languages
- implementing ad hoc interpreters for them.
- If those DSLs are highly expressive, or if their "code" is non-trivial to analyze, is it still data?
- Preserving the traceability of execution is a challenge.
things-that-make-and-break-clojure-code-analysis
By Val Waeselynck



