Technology Overview
Presentation Outline
General Tech Topics
Interesting articles from various different fields to broaden general knowledge
1.
# INTRO
LLMs
Research papers that focus on language models and their utilization
2.
RAGs
Research papers revolving around different novel approaches to RAG
3.
OSS Technology
GitHub Repositories containing tools that could improve our tech stack
4.
& video appendix at the endGeneral Tech Topics
# CHAPTER 1
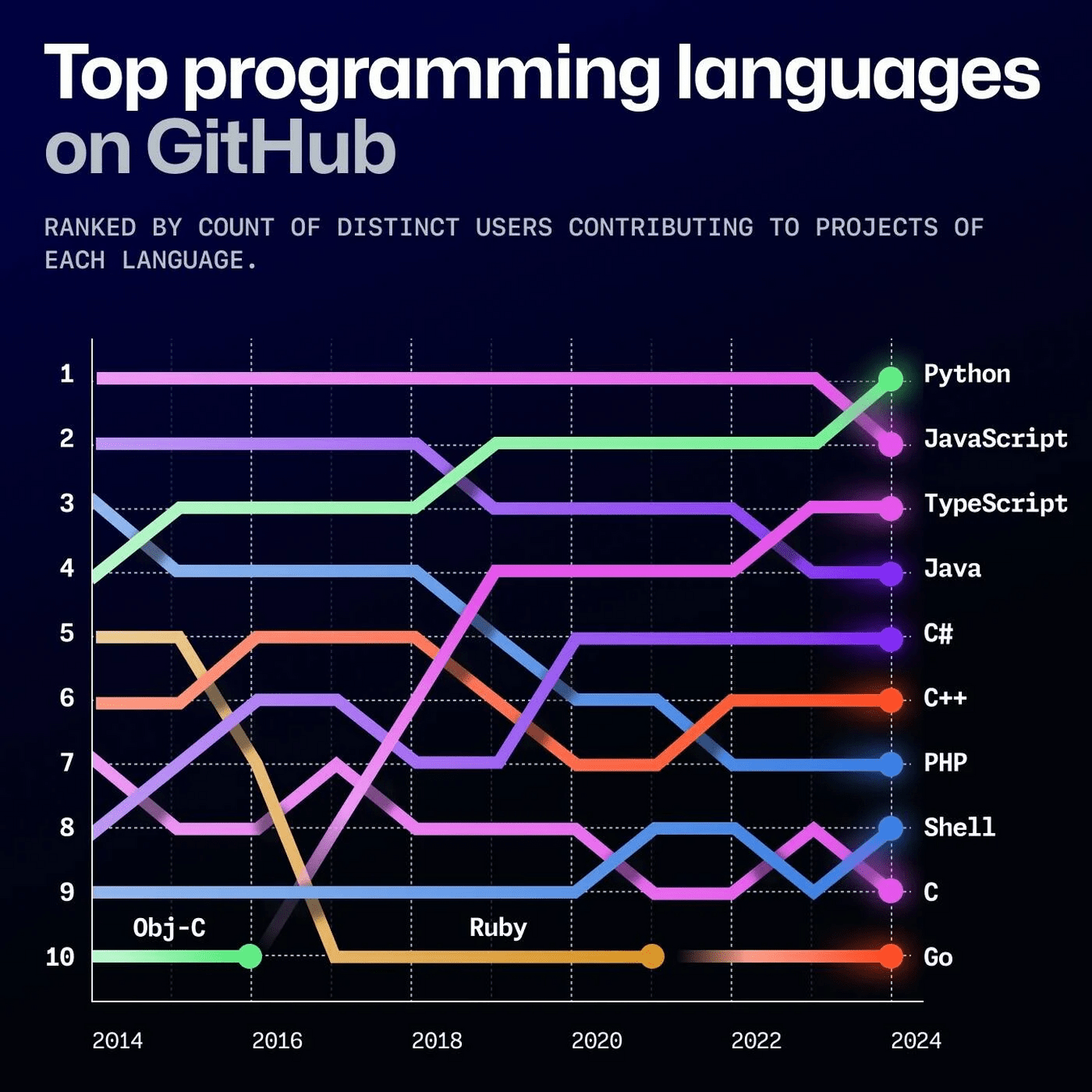
Python dethrones JavaScript as the most-used language on GitHub 🔥
Along with Python jumping to first place, GitHub noted that the use of Jupyter Notebooks rose by 92 percent on the platform in the past year. Those two factors, along with a surge of new users, "could indicate people in data science, AI, machine learning, and academia increasingly use GitHub."
5 Nov 2024
# CHAPTER 1
AI-induced indifference: Unfair AI reduces prosociality ⚖️
Four experiments (combined N = 2425) show that receiving an unfair allocation by an AI (versus a human) actor leads to lower rates of prosocial behavior towards other humans in a subsequent decision—an effect we term AI-induced indifference
23 Sep 2024
# CHAPTER 1
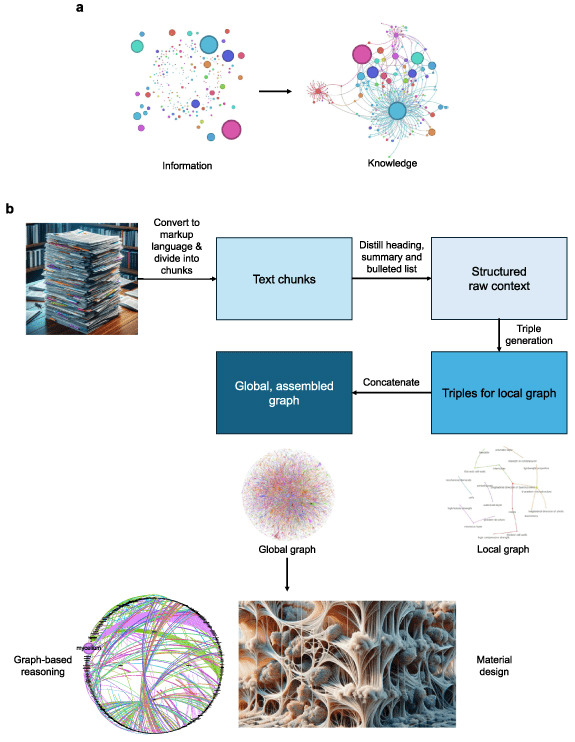
Accelerating scientific discovery with generative knowledge extraction, graph-based representation, and multimodal intelligent graph reasoning 🔧
Using a large language embedding model we compute deep node representations and use combinatorial node similarity ranking to develop a path sampling strategy that allows us to link dissimilar concepts that have previously not been related [...]
27 Sep 2024
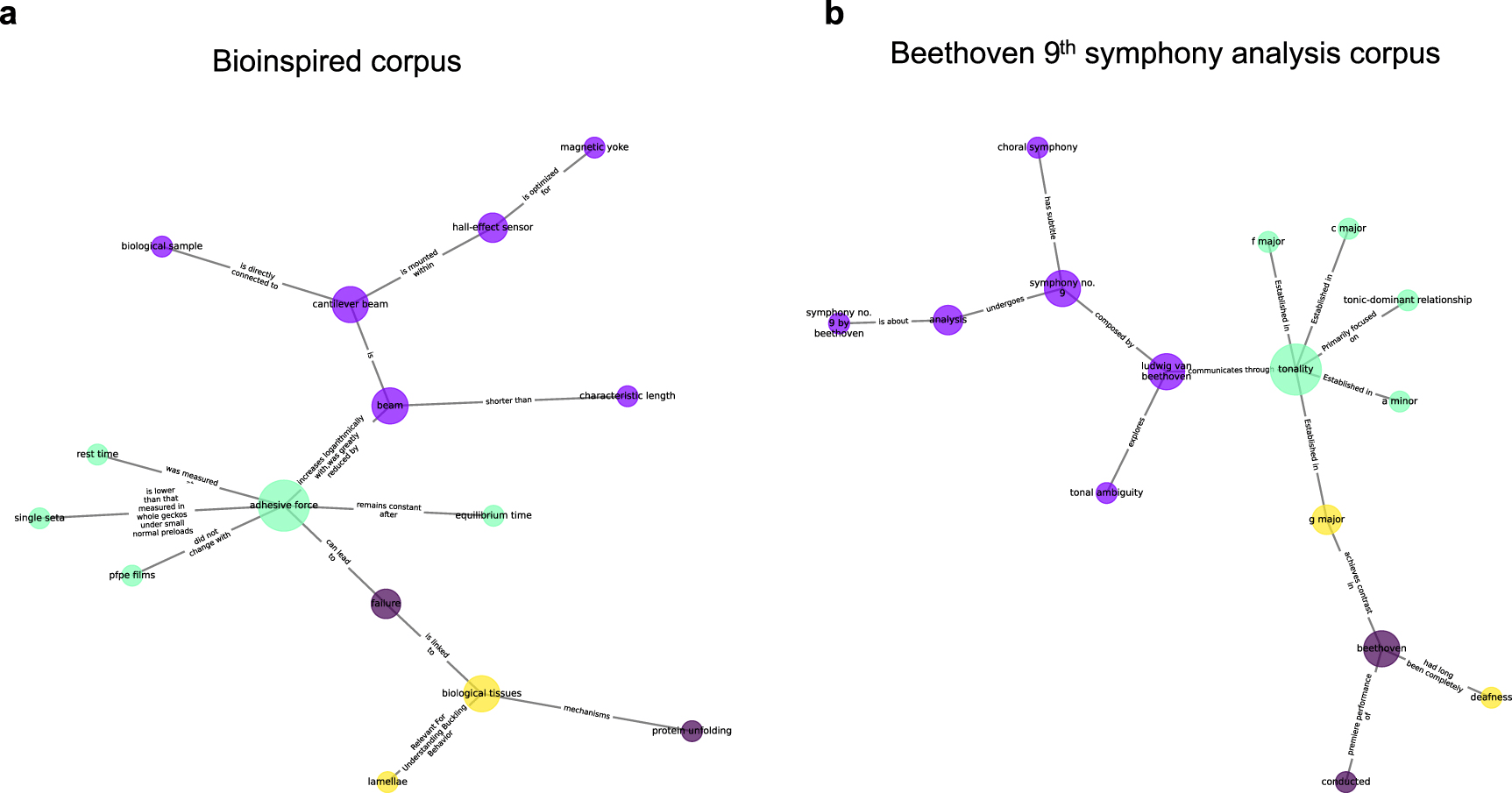
One comparison revealed detailed structural parallels between biological materials and Beethoven's 9th Symphony, highlighting shared patterns of complexity through isomorphic mapping.
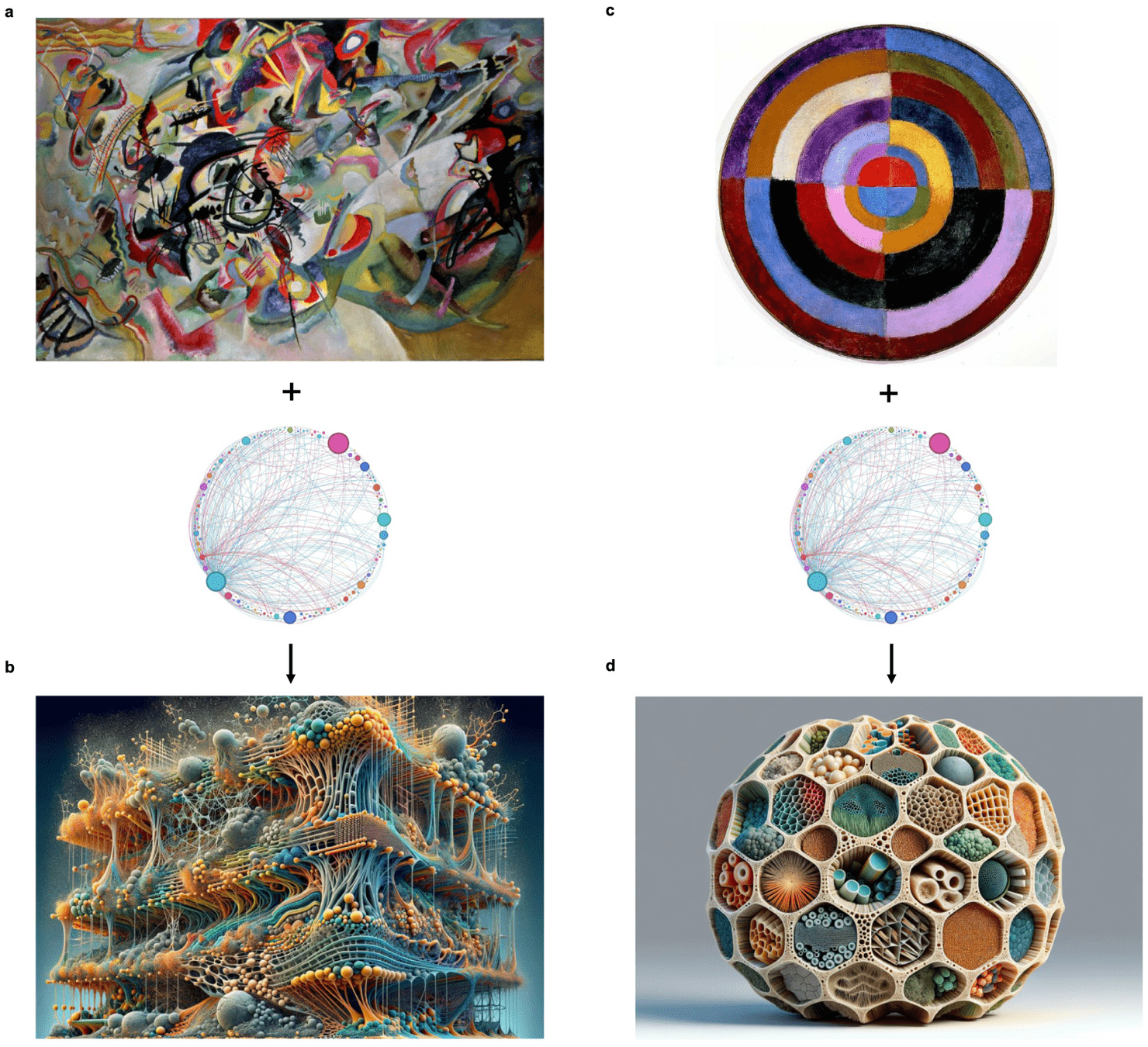
In another example, the algorithm proposed an innovative hierarchical mycelium-based composite based on integrating path sampling with principles extracted from Kandinsky's 'Composition VII' painting.
The resulting material integrates an innovative set of concepts that include a balance of chaos and order, adjustable porosity, mechanical strength, and complex patterned chemical functionalization.
We uncover other isomorphisms across science, technology and art, revealing a nuanced ontology of immanence that reveal a context-dependent heterarchical interplay of constituents
LLMs
# CHAPTER 2
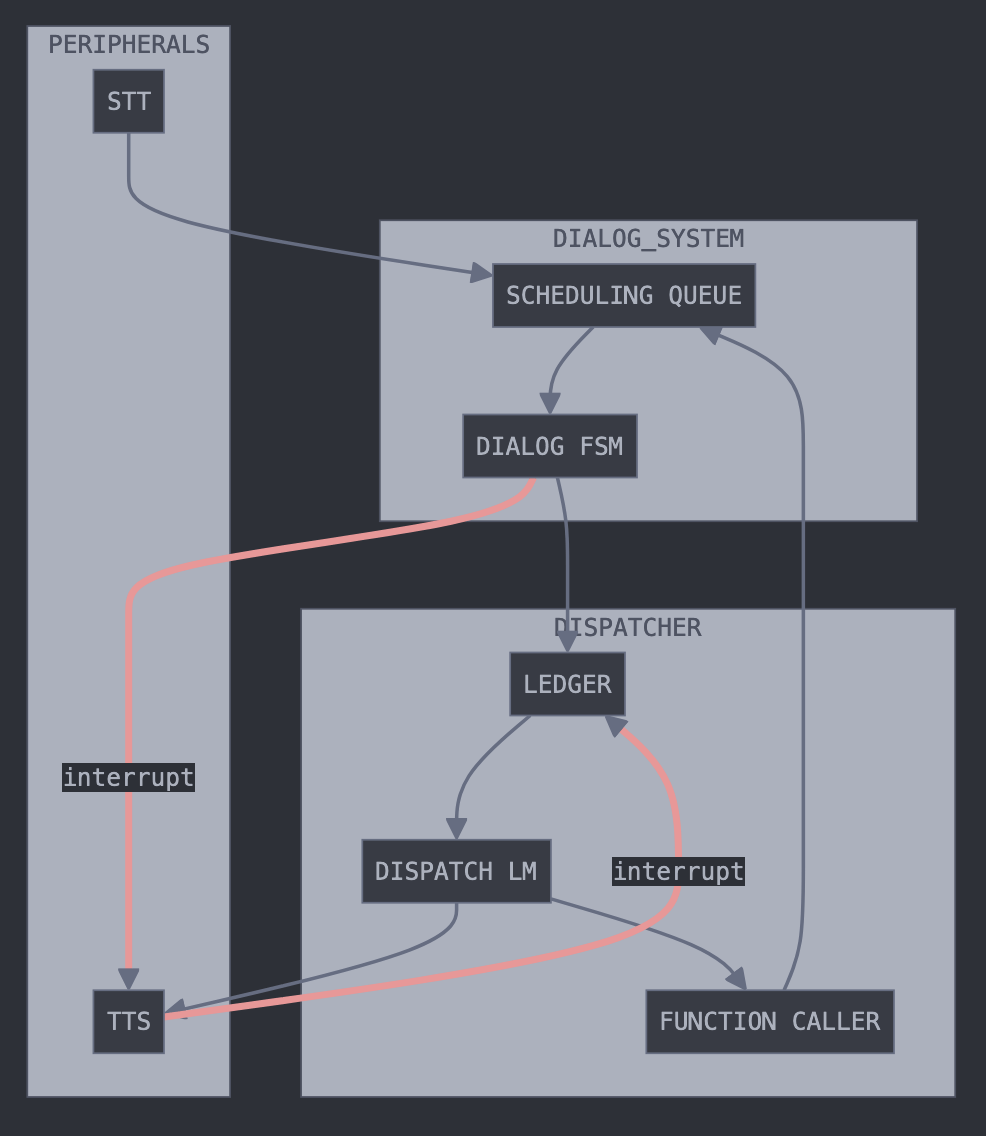
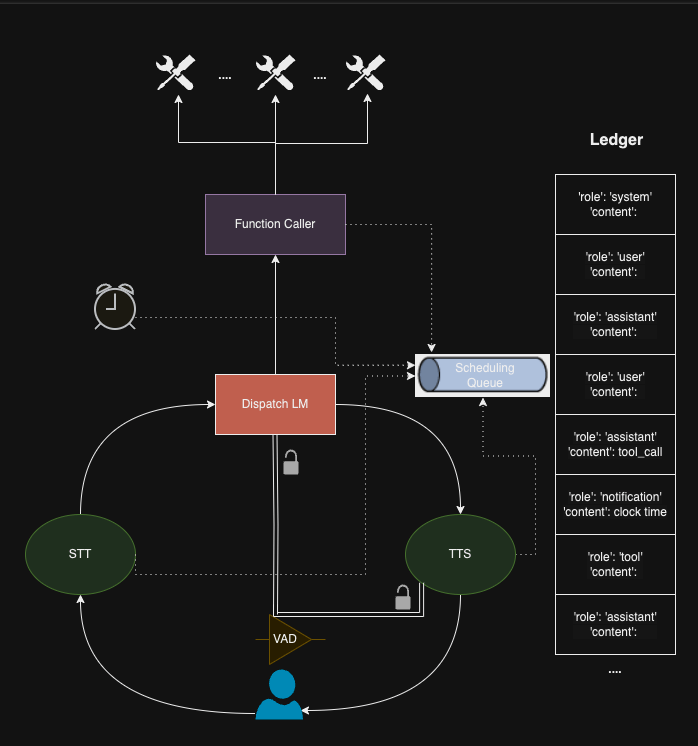
Asynchronous Tool Usage for Real-Time Agents 🏃♂️➡️
While frontier large language models (LLMs) are capable tool-using agents, current AI systems still operate in a strict turn-based fashion, oblivious to the passage of time. This synchronous design forces user queries and tool-use to occur sequentially, preventing the systems from multitasking and reducing interactivity. To address this limitation, we introduce asynchronous AI agents capable of parallel processing and real-time tool-use. [...]
28 Oct 2024
Our key contribution is an event-driven finite-state machine architecture for agent execution and prompting, integrated with automatic speech recognition and text-to-speech.
Drawing inspiration from the concepts originally developed for real-time operating systems, this work presents both a conceptual framework and practical tools for creating AI agents capable of fluid, multitasking interactions.
# CHAPTER 2
IoT-LLM: Enhancing Real-World IoT Task Reasoning with Large Language Models 🌍
Inspired by human cognition, where perception is fundamental to reasoning, we explore augmenting LLMs with enhanced perception abilities using Internet of Things (IoT) sensor data and pertinent knowledge for IoT task reasoning in the physical world. In this work, we systematically study LLMs capability to address real-world IoT tasks by augmenting their perception and knowledge base, and then propose a unified framework, IoT-LLM, to enhance such capability
3 Oct 2024
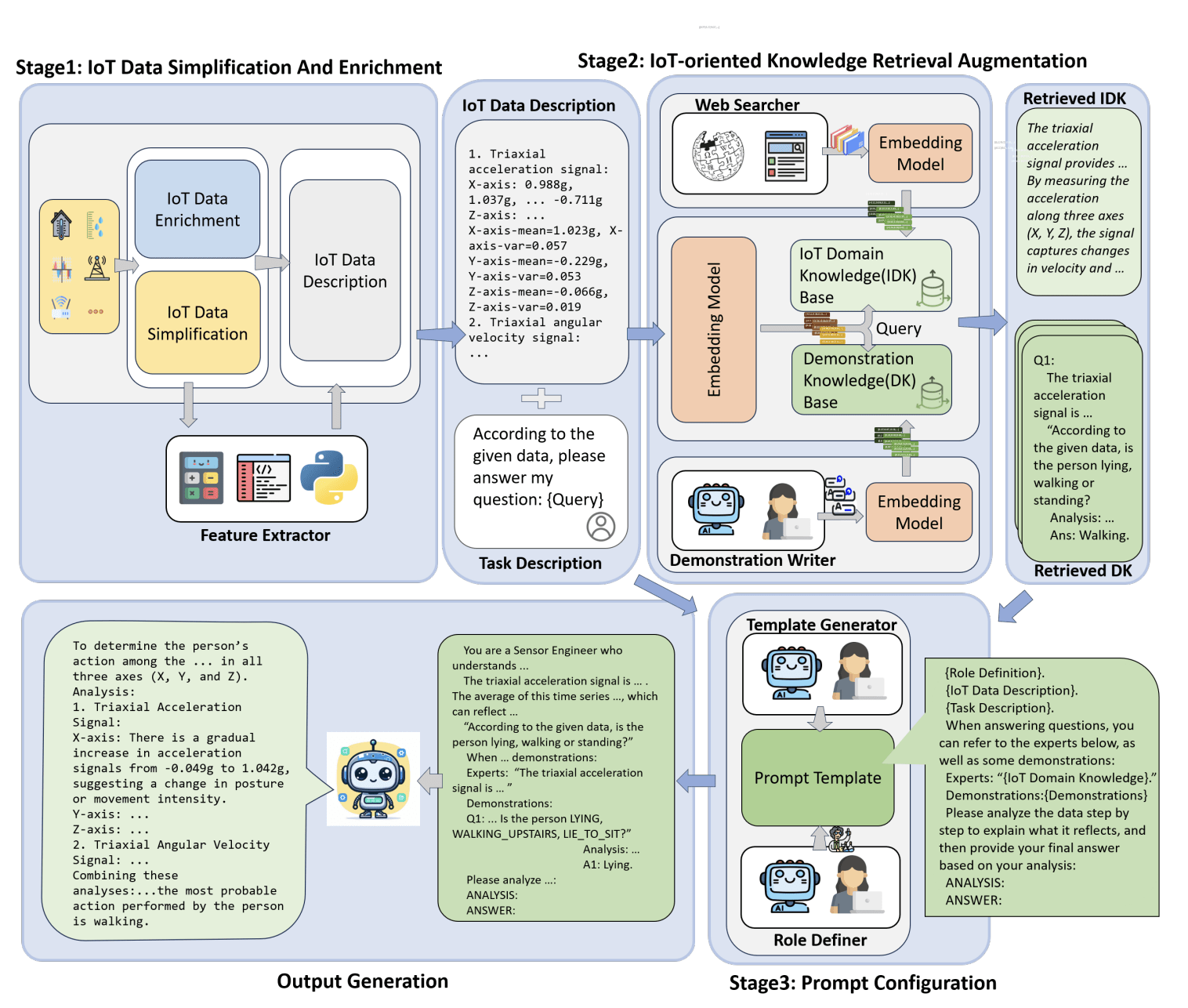
1. Preprocessing:
It is crucial to preprocess raw IoT data into formats easily understood by the LLMs. This process simplifies and enriches the data, providing more context to the LLMs.
2. Commonsense Knowledge Activation:
Chain of thought prompting is utilized in this step for better reasoning and interpretation of the processed data. Complex tasks are broken down into more manageable ones, mirroring human cognitive thinking. Inherent common sense is employed within these LLMs, and specialized role definitions guide the models in understanding the context better.
3. IoT-Oriented Retrieval-Augmented Generation:
In the final step, the LLMs use the retrieval-augmented generation model to retrieve context-specific understanding dynamically. The model can effectively use current context and previously acquired knowledge. This combination helps with quick adaptation to real-time changes in IoT environments.
IoT-LLM significantly enhances the performance of IoT tasks reasoning of LLM, such as GPT-4, achieving an average improvement of 65% across various tasks against previous methods. The results also showcase LLMs ability to comprehend IoT data and the physical law behind data by providing a reasoning process
RAGs
# CHAPTER 3
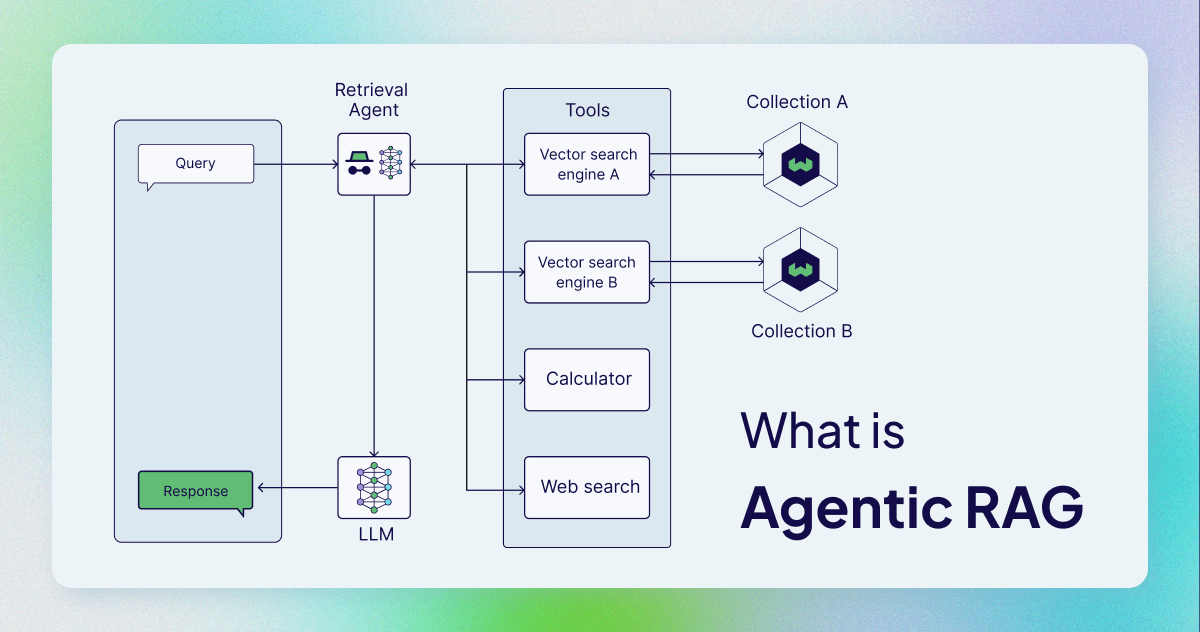
What is Agentic RAG? 🧐
Agentic RAG describes an AI agent-based implementation of RAG. Specifically, it incorporates AI agents into the RAG pipeline to orchestrate its components and perform additional actions beyond simple information retrieval and generation to overcome the limitations of the non-agentic pipeline.
5 Nov 2024
Although agents can be incorporated in different stages of the RAG pipeline, agentic RAG most commonly refers to the use of agents in the retrieval component.
In contrast to the sequential naive RAG architecture, the core of the agentic RAG architecture is the agent.
Agentic RAG architectures can have various levels of complexity. In the simplest form, a single-agent RAG architecture is a simple router. However, you can also add multiple agents into a multi-agent RAG architecture
# CHAPTER 3
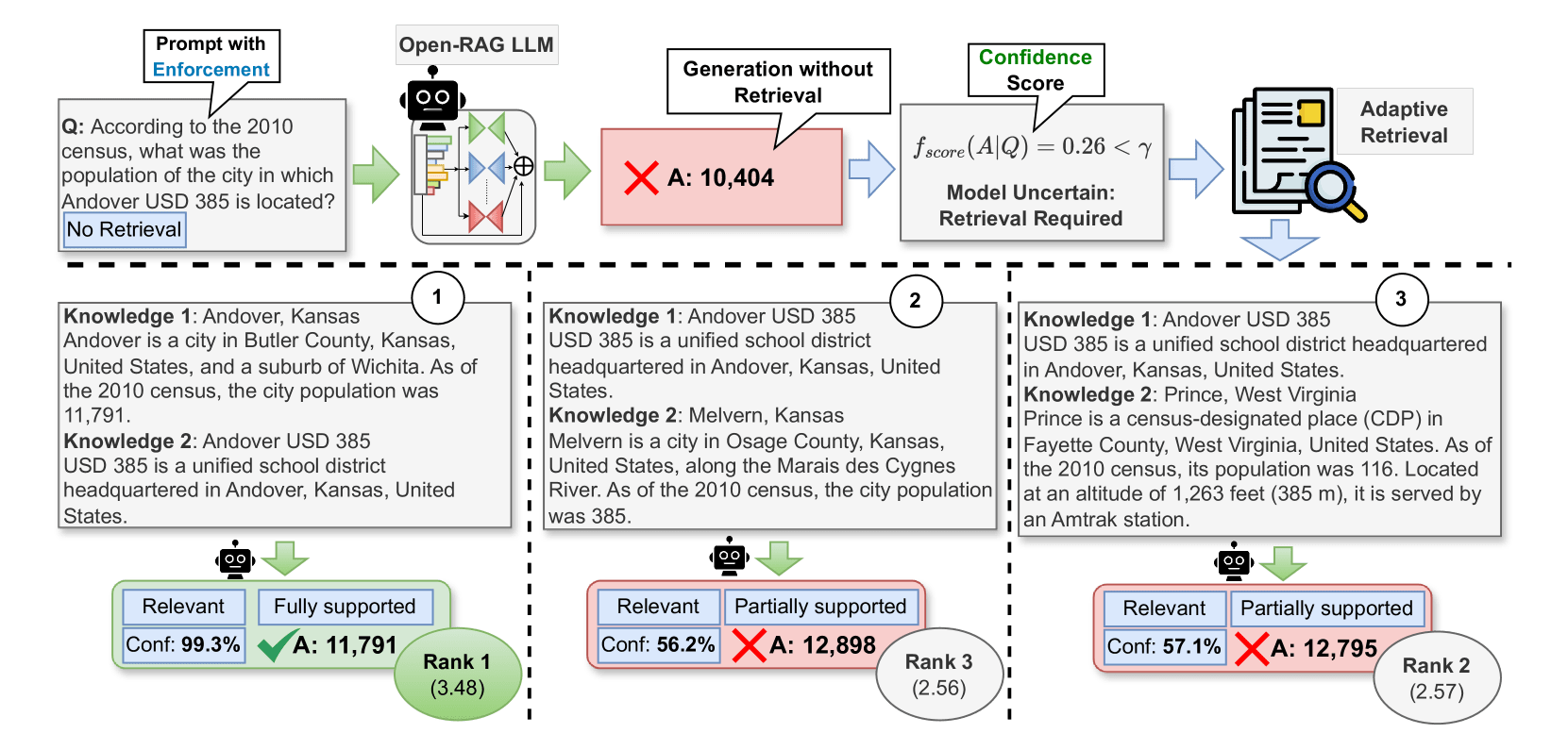
Open-RAG: Enhanced Retrieval-Augmented Reasoning with Open-Source Large Language Models 🧠
Retrieval-Augmented Generation (RAG) has been shown to enhance the factual accuracy of Large Language Models (LLMs), but existing methods often suffer from limited reasoning capabilities in effectively using the retrieved evidence, particularly when using open-source LLMs. To mitigate this gap, we introduce a novel framework, Open-RAG, designed to enhance reasoning capabilities in RAG with open-source LLMs
2 Oct 2024
Our framework transforms an arbitrary dense LLM into a parameter-efficient sparse mixture of experts (MoE) model capable of handling complex reasoning tasks, including both single- and multi-hop queries.
Open-RAG uniquely trains the model to navigate challenging distractors that appear relevant but are misleading. As a result, Open-RAG leverages latent learning, dynamically selecting relevant experts and integrating external knowledge effectively for more accurate and contextually relevant responses.
In addition, we propose a hybrid adaptive retrieval method to determine retrieval necessity and balance the trade-off between performance gain and inference speed. Experimental results show that the Llama2-7B-based Open-RAG outperforms state-of-the-art LLMs and RAG models such as ChatGPT, Self-RAG, and Command R+ in various knowledge-intensive tasks.
We open-source our code and models
# CHAPTER 3
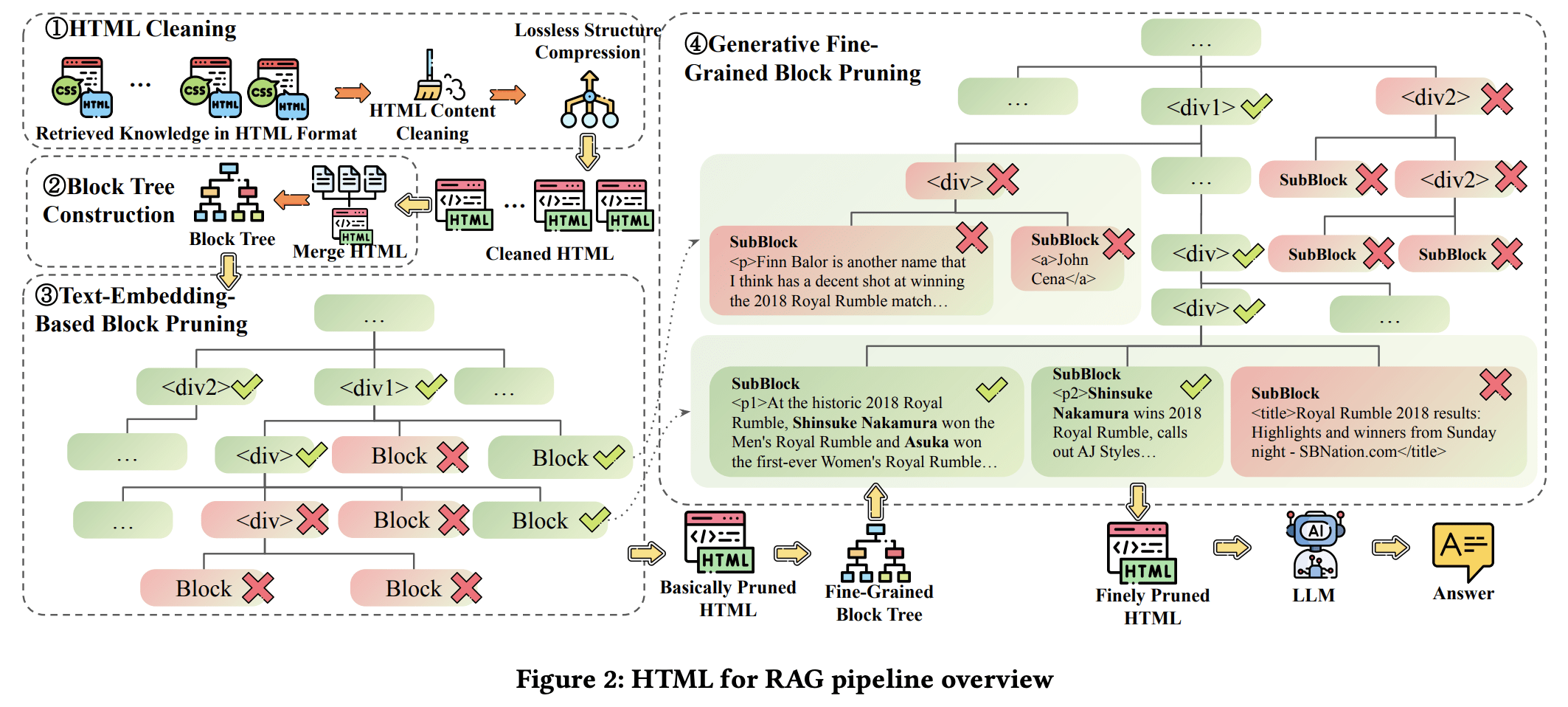
HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems? 🌐
HTML contains a lot of intrinsic information, so we propose taking HTML as the format of retrieved knowledge in RAG systems, and design HTML cleaning and block-tree-based HTML pruning to shorten the length and preserve information.
5 Nov 2024
The Web is a major source of external knowledge used in RAG systems, and many commercial systems such as ChatGPT and Perplexity have used Web search engines as their major retrieval systems.
Typically, such RAG systems retrieve search results, download HTML sources of the results, and then extract plain texts from the HTML sources. Plain text documents or chunks are fed into the LLMs to augment the generation.
However, much of the structural and semantic information inherent in HTML, such as headings and table structures, is lost during this plain-text-based RAG process.
To alleviate this problem, we propose HtmlRAG, which uses HTML instead of plain text as the format of retrieved knowledge in RAG
We propose HTML cleaning, compression, and pruning strategies, to shorten the HTML while minimizing the loss of information.
Specifically, we design a two-step block-tree-based pruning method that prunes useless HTML blocks and keeps only the relevant part of the HTML.
Experiments on six QA datasets confirm the superiority of using HTML in RAG systems.
Open Source Technology
# CHAPTER 3
garak, LLM vulnerability scanner
garak checks if an LLM can be made to fail in a way we don't want. garak probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. If you know nmap, it's nmap for LLMs.
garak focuses on ways of making an LLM or dialog system fail. It combines static, dynamic, and adaptive probes to explore this.
# CHAPTER 3
Memoripy: A Python Library that Brings Real Memory Capabilities to AI Applications
Memoripy is a Python library designed to manage and retrieve context-aware memory interactions using both short-term and long-term storage.
It supports AI-driven applications requiring memory management, with compatibility for OpenAI and Ollama APIs.
Features include contextual memory retrieval, memory decay and reinforcement, hierarchical clustering, and graph-based associations.
# CHAPTER 3
Guardrails: Ship to production confidently with Portkey Guardrails on your requests & responses
One of the challenges of generative AI is keeping the AI from straying off course. The engineers of Portkey Gateway found a way to integrate more controls into the generative AI pipeline.
Asynchronous functions, known as guardrails, can track the evolution of AI-generated answers and “vote” at various stages of the pipeline. With each vote, an answer is refined. The end result should be fewer hallucinations and more correct answers
# CHAPTER 3
Swirl: Get your AI up and running in minutes, not months
SWIRL is an open-source platform that streamlines the integration of advanced AI technologies into business operations.
SWIRL operated without needing to move data into a vector database or undergo ETL processes. This approach not only enhances security but also speeds up the deployment. As a private cloud AI provider,
SWIRL operates entirely within your private cloud infrastructure, running locally inside the firewall to ensure maximum data security and compliance.
Appendix: Visualizing 4D
Two amazing videos from HyperCubist Math

Technology Overview
By vandavv
Technology Overview
Review of new research to share knowledge with others



