
Análise exploratória:
como obter insights dos seus dados
Ana Karolina Fernandes e Vivian Yamassaki
TDC 2021
Sobre nós :)
- Mestra em Sistemas de Informação pela USP
- Data Scientist na Creditas
-
Co-organizadora da MIA (Mulheres em Inteligência Artificial)
- Graduada em Engenharia Geológica pela UFOP
- Data Scientist na Creditas



E vai ter evento da MIA na semana que vem! 😍
As inscrições podem ser feitas gratuitamente aqui!

Como é o fluxo de um projeto de Data Science na Creditas:

Entendimento do problema: etapa inicial do projeto na qual conversamos com diversas pessoas para entender o que queremos resolver ao criar um modelo
Coleta dos dados: após entendermos o problema, fazemos a coleta de dados tanto dos campos que potencialmente serão utilizados no modelo quanto do target do modelo
Como é o fluxo de um projeto de Data Science na Creditas:
Análise exploratória de dados: nessa etapa, investigamos os dados extraídos (verificamos se os dados estão inconsistentes ou faltando, a relação entre as variáveis e entre elas e o target do modelo, etc).
Como é o fluxo de um projeto de Data Science na Creditas:
Engenharia de atributos: nessa etapa, criamos novas variáveis, fazemos algumas transformações e geramos uma base de dados que será dividida entre treino e teste
Como é o fluxo de um projeto de Data Science na Creditas:
Modelagem: nessa etapa, fornecemos a base de treinamento para o modelo esperando que ele consiga aprender e generalizar o comportamento que estamos querendo que ele identifique
Como é o fluxo de um projeto de Data Science na Creditas:
Avaliação: nessa última etapa, fazemos as avaliações com a base de teste para analisar o desempenho do modelo e ver se resolve o problema e se faz sentido colocá-lo em produção.
Como é o fluxo de um projeto de Data Science na Creditas:
Para demonstrarmos como fazemos nossa análise exploratória, pegamos um dataset que se encaixa no contexto da Creditas...
Vamos utilizar como exemplo o desafio do House Prices, disponibilizado pelo Kaggle.
Quem quiser, pode pegar os dados aqui:
O conjunto de treinamento possui apenas 1.460 exemplos...
Mas tem 80 colunas!

A primeira que podemos fazer então é verificar as variáveis com muitos valores faltantes...
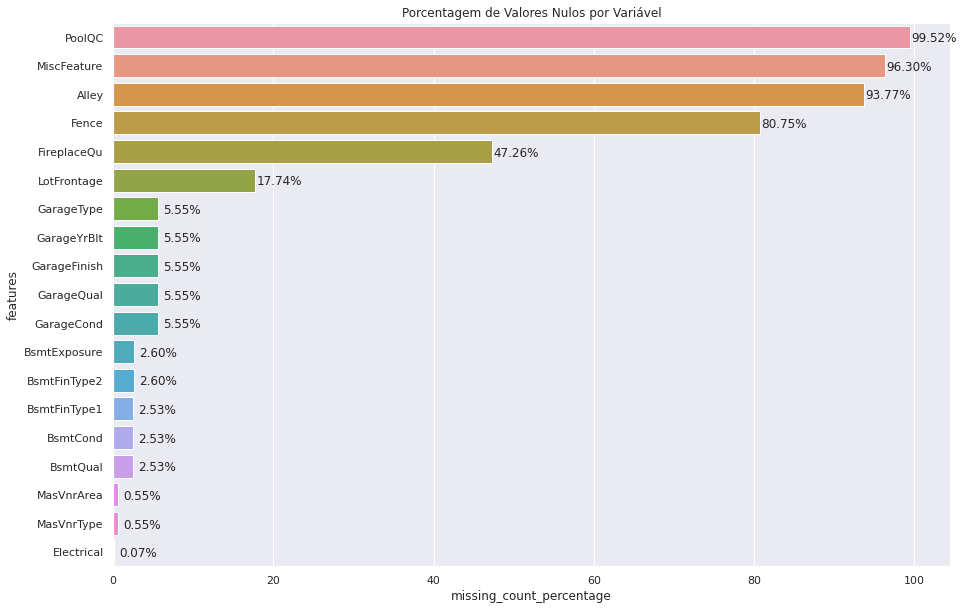
Escolhemos 10 variáveis do nosso dataset para explorar:
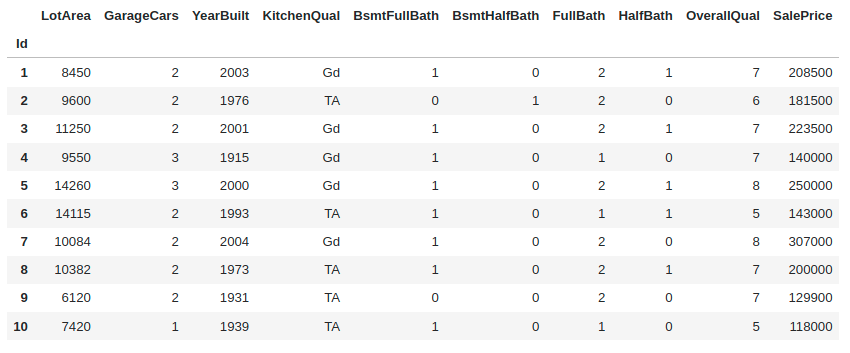

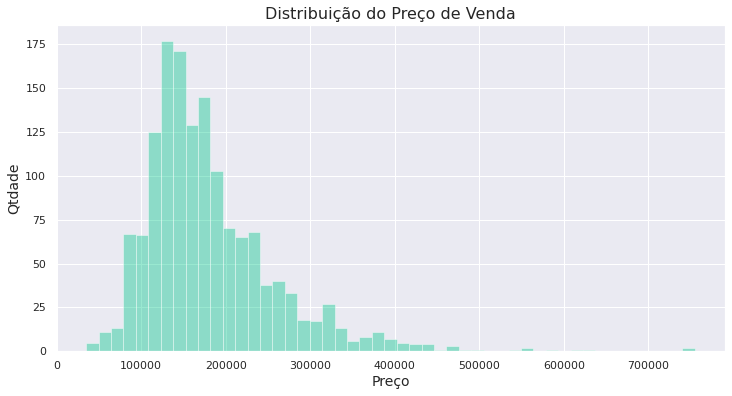
Com esse conjunto de dados, podemos construir um modelo de regressão e o target será o Preço de Venda do imóvel
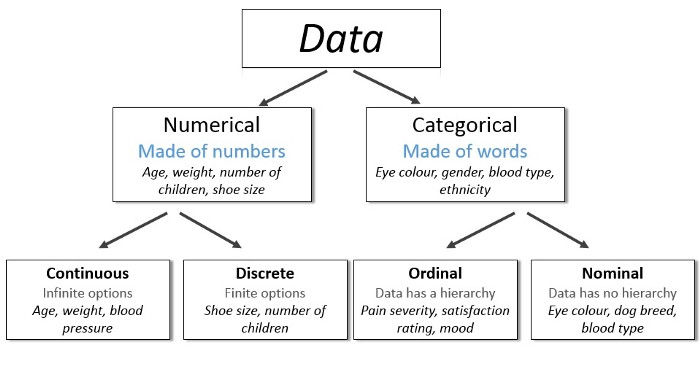
Imagem retirada daqui
Alguns tipos de gráficos só fazem sentido para alguns tipos de variáveis, por isso é importante saber que tipo de dado vamos analisar para que isso seja feito de forma mais adequada.
Variáveis Categóricas
São variáveis que apresentam categorias (ou seja, palavras ou números que descrevem alguma coisa). Exemplos:
- Estado: Amazonas, Minas Gerais, Rio Grande do Norte, São Paulo, etc.
- Escolaridade: ensino fundamental, ensino médio, ensino superior, etc.
Nesse dataset contamos com algumas features categóricas:
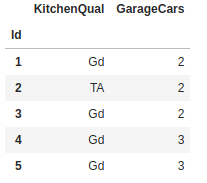

Variáveis Categóricas
Nesse dataset contamos com algumas features categóricas:
- KitchenQual:
df['KitchenQual'].value_counts(normalize=True)*100
Variáveis Categóricas
Nesse dataset contamos com algumas features categóricas:
- GarageCars:
df['GarageCars'].value_counts(normalize=True)*100
Variáveis Categóricas
Uma das coisas que mais utilizamos na etapa de análise exploratória são gráficos!
Existem diversas bibliotecas para visualização de dados, como o Matplotlib e o Seaborn.
Hoje também vamos utilizar os gráficos que desenvolvemos para o Galeritas, nossa biblioteca open source para visualização de dados 💚

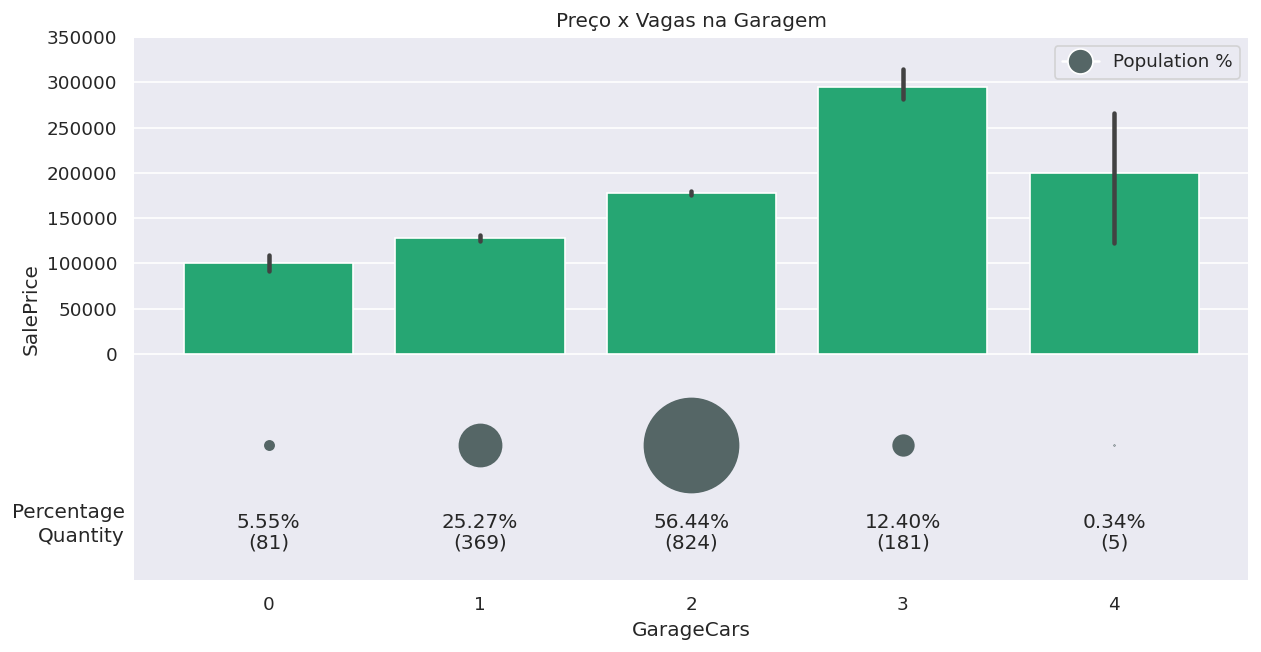
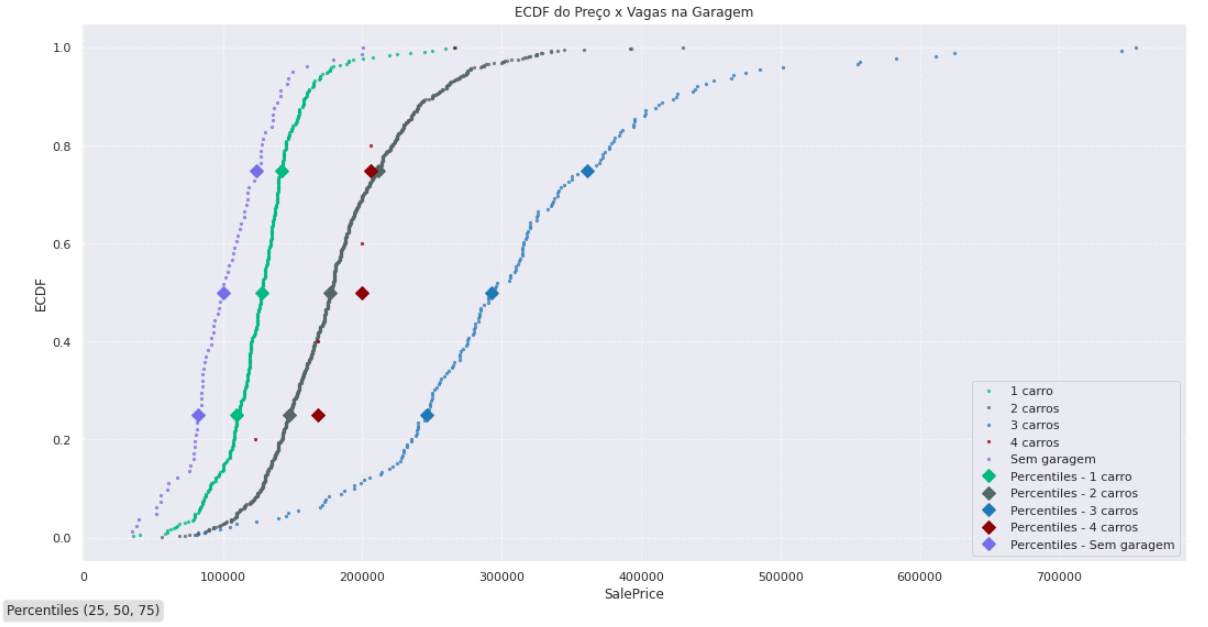
Vamos ver como o preço do imóvel se relaciona com a quantidade de vagas na garagem?
bar_plot_with_population_proportion(df, x='GarageCars',y='SalePrice',plot_title='Preço x Vagas na Garagem',
figsize=(12, 6),circle_diameter=100)plot_ecdf_curve(df,
hue_labels= {0:'Sem garagem',
1:'1 carro',
2:'2 carros',
3:'3 carros',
4:'4 carros'},
column_to_plot='SalePrice',
hue='GarageCars',
figsize=(18, 9),
plot_title='ECDF do Preço x Vagas na Garagem',
colors= ['#11bb77',
'#556666',
'#3377bb',
'#8b0000',
'#7b68ee']
)Também podemos visualizar as distribuições do preço com relação à quantidade de vagas na garagem com a curva ECDF
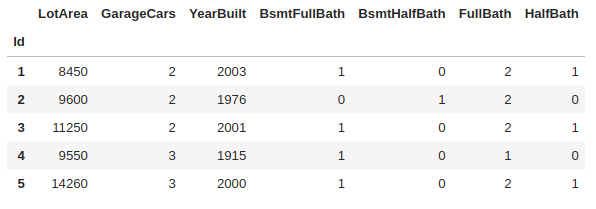
Variáveis representadas por números, que podem ser contínuos ou discretos. Exemplos:
Nesse dataset vamos explorar as seguintes variáveis numéricas:
- Quantidade de quartos: 0, 1, 2, etc.
- m² do imóvel: 100, 72.5, 64.7, etc.
Variáveis Numéricas
df['LotArea'].describe()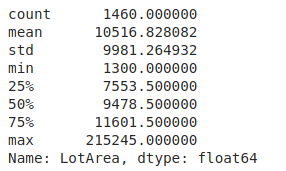
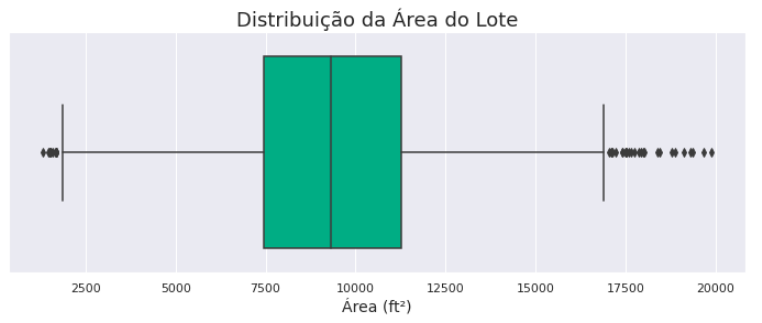
ax = sns.boxplot(x = 'LotArea',
data = df,
orient = 'h')
ax.set_title('Distribuição da Área do Lote',
fontsize=18)
ax.set_xlabel('Área (ft²)',
fontsize=14)
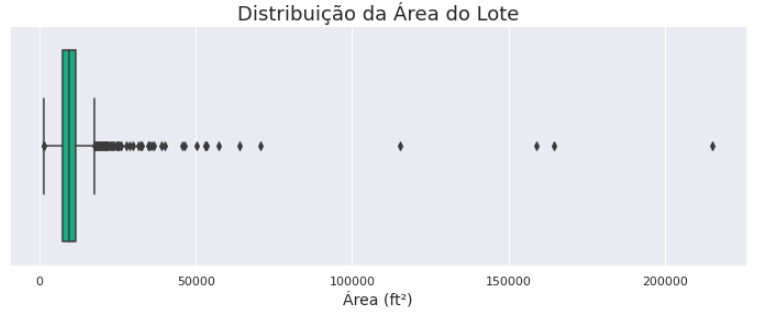
Vamos ver como está a distribuição da área dos lotes?
ax = df.plot.scatter(x = 'LotArea', y='SalePrice')
ax.set_title('Área do Lote x Preço', fontsize=18)
ax.set_xlabel('Tamanho (ft²)', fontsize=14)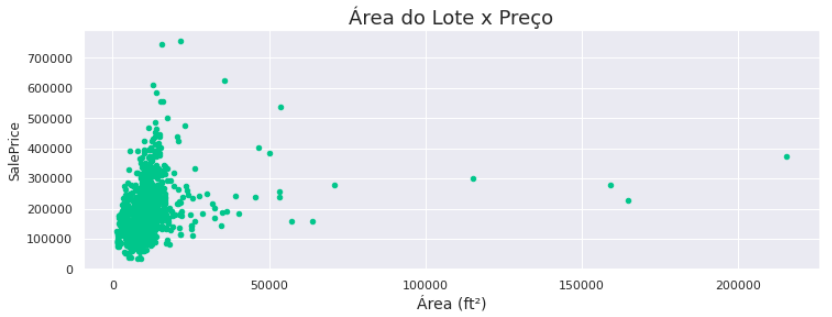
Um dado outlier pode ser o que mais atrapalha sua análise, mas também pode ser exatamente aquilo que você está procurando.
E qual será o preço desses super lotes?
- Excluir: remoção dos erros ou casos que não são relevantes
- Realizar uma análise separada: útil para investigar casos extremos
- Alterar o valor: dar novos valores aos outliers e, assim, não perdemos o exemplo
O que podemos fazer com esses outliers?
Após o tratamento dos outliers, nosso boxplot ficará assim:
#Calculando a idade do imóvel
from datetime import date
today = (date.today()).year
df['Age'] = today - df['YearBuilt']
#Analisando a nova variável
df['Age'].describe()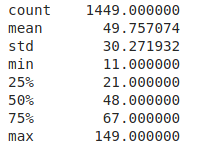
Também podemos fazer um tratamento em algumas variáveis para poder analisá-las
#Dividindo a idade do imóvel em faixas
bins = [0, 25, 50, np.inf]
names = ['<25', '25-50', '50+']
df['AgeRange'] = pd.cut(df['Age'], bins, labels=names)
# Distribuição
bar_plot_with_population_proportion(df,x='AgeRange',y='SalePrice',plot_title='Preço x Idade do Imóvel',
circle_diameter=100)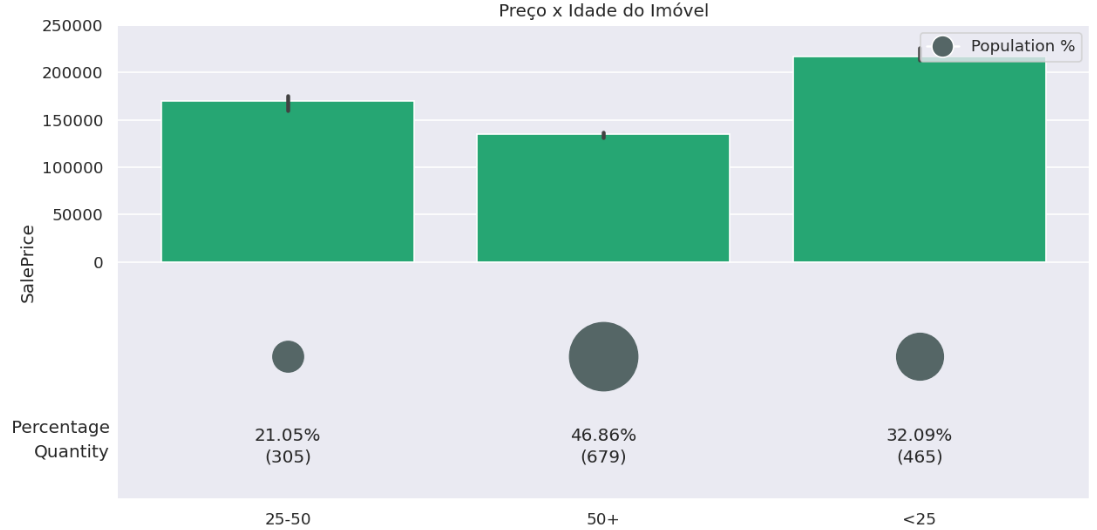
Podemos fazer ainda mais um tratamento para "converter" essa variável numérica para categórica
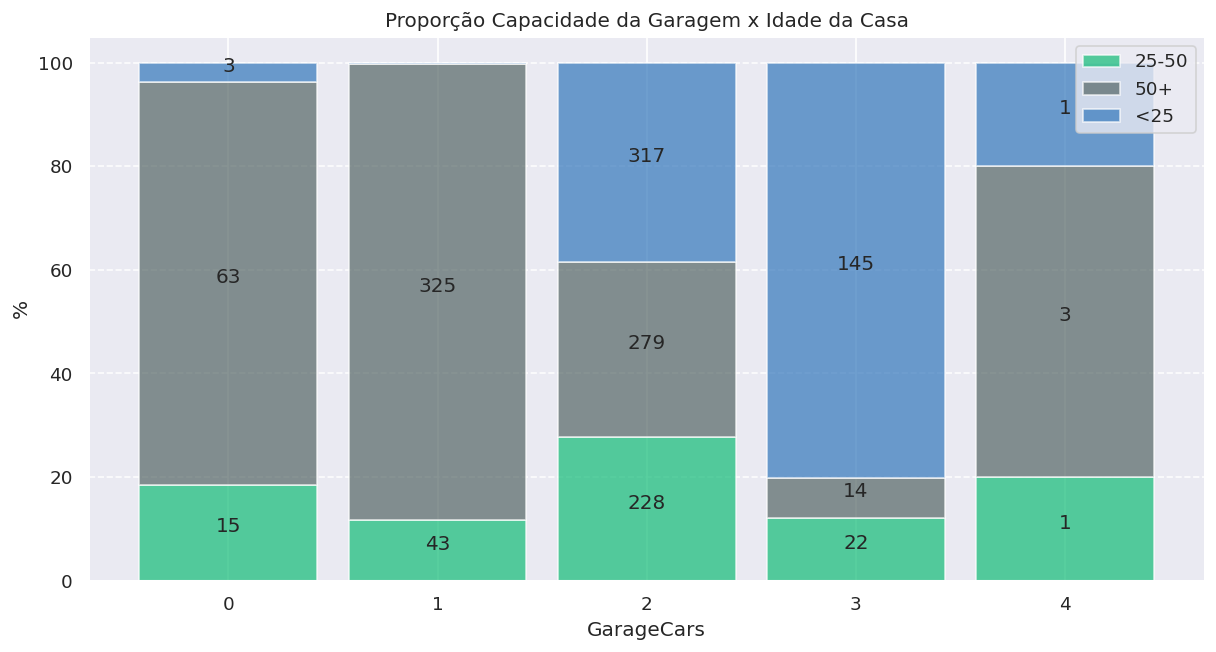
stacked_percentage_bar_plot(
df,
categorical_feature='GarageCars',
hue='AgeRange',
annotate=True,
plot_title='Proporção Capacidade da Garagem x Idade da Casa')Além de analisar as variáveis com relação ao target, também podemos relacionar variáveis umas com as outras
Conclusões
- Precisamos tomar cuidado ao utilizar um determinado tipo de gráfico que pode acabar nos levando a uma conclusão incorreta porque só estamos olhando um aspecto nele. Por isso, geralmente utilizamos mais de um gráfico para fazermos nossas análises e tirar conclusões!
Conclusões
- Precisamos tomar cuidado ao utilizar um determinado tipo de gráfico que pode acabar nos levando a uma conclusão incorreta porque só estamos olhando um aspecto nele. Por isso, geralmente utilizamos mais de um gráfico para fazermos nossas análises e tirar conclusões!
- Muito cuidado com a qualidade dos seus dados! O dado incorreto pode te levar a uma conclusão também incorreta!
Conclusões
- Precisamos tomar cuidado ao utilizar um determinado tipo de gráfico que pode acabar nos levando a uma conclusão incorreta porque só estamos olhando um aspecto nele. Por isso, geralmente utilizamos mais de um gráfico para fazermos nossas análises e tirar conclusões!
- Muito cuidado com a qualidade dos seus dados! O dado incorreto pode te levar a uma conclusão também incorreta!
- Tome cuidado ao tirar conclusões com base na média, principalmente se há casos de dados muito discrepantes em sua base!
Conclusões
- Precisamos tomar cuidado ao utilizar um determinado tipo de gráfico que pode acabar nos levando a uma conclusão incorreta porque só estamos olhando um aspecto nele. Por isso, geralmente utilizamos mais de um gráfico para fazermos nossas análises e tirar conclusões!
- Muito cuidado com a qualidade dos seus dados! O dado incorreto pode te levar a uma conclusão também incorreta!
- Tome cuidado ao tirar conclusões com base na média, principalmente se há casos de dados muito discrepantes em sua base!
- Veja também o tamanho da sua amostra e se ela é representativa para não tirar conclusões incorretas e se preocupe também em não pegar uma amostra enviesada!
Quer saber mais?
Há muitas outras "ferramentas" que podemos utilizar em nossas análises exploratórias:
- Podemos aplicar testes estatísticos e analisar a correlação entre nossas variáveis e targets para decidir se iremos usá-las*.
* Esses dois tópicos e mais algumas outras coisas podem ser encontrados aqui!
Quer saber mais?
Há muitas outras "ferramentas" que podemos utilizar em nossas análises exploratórias:
- Podemos aplicar testes estatísticos e analisar a correlação entre nossas variáveis e targets para decidir se iremos usá-las*.
* Esses dois tópicos e mais algumas outras coisas podem ser encontrados aqui!
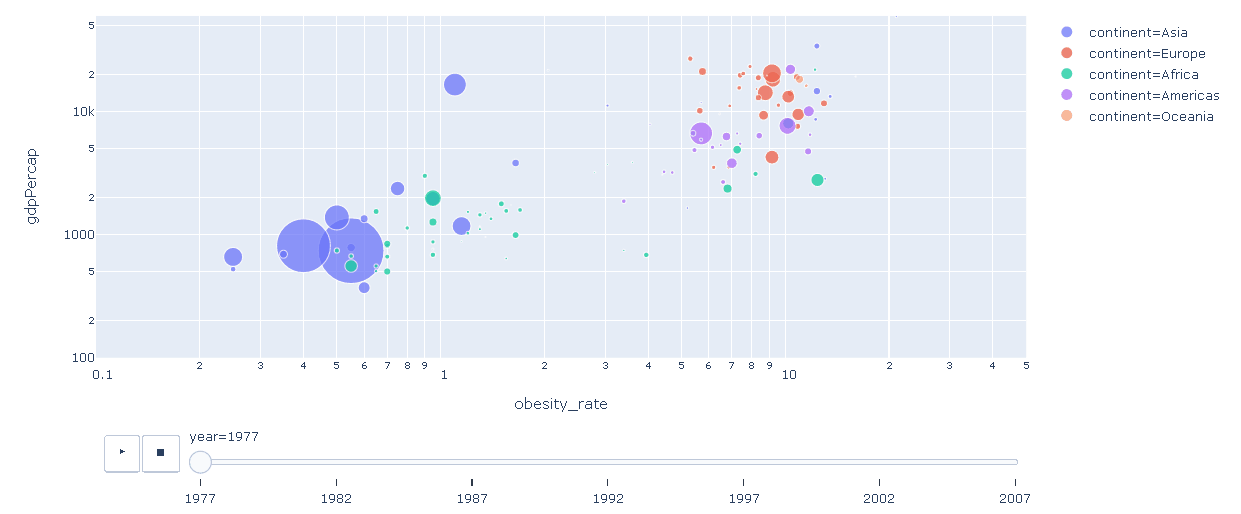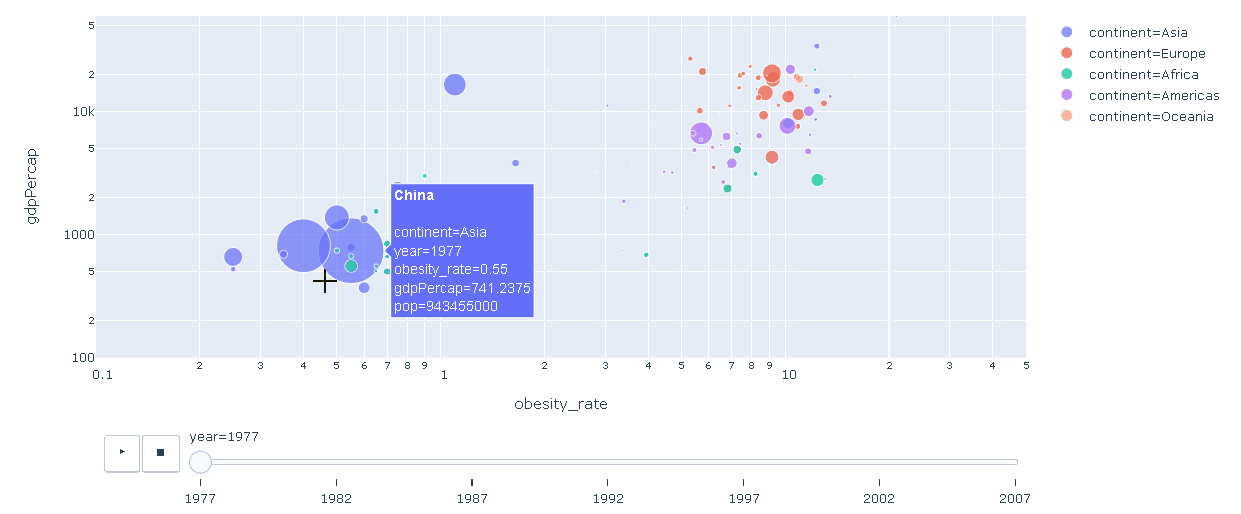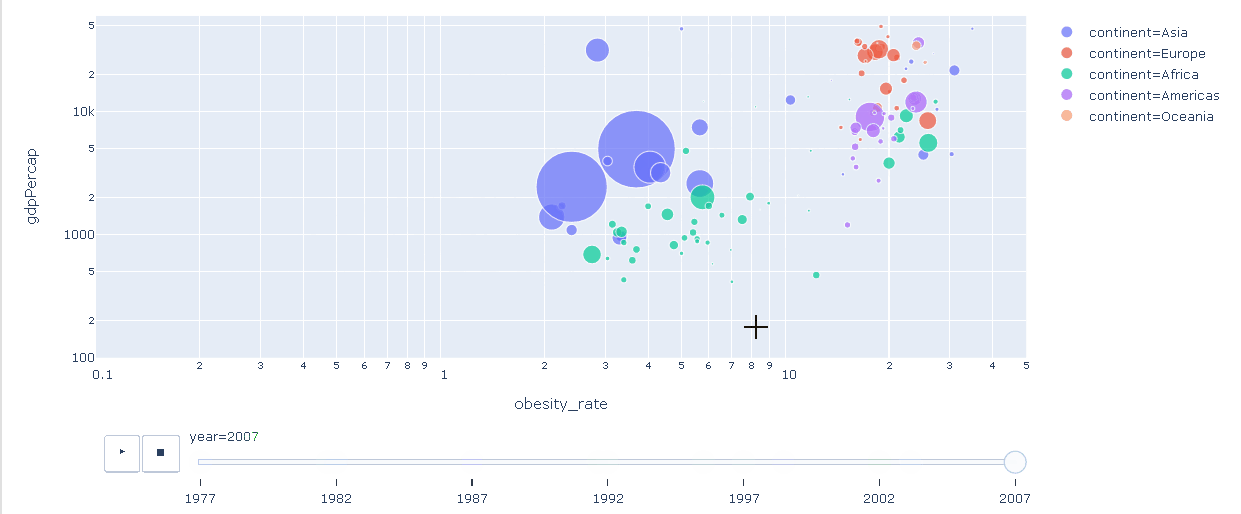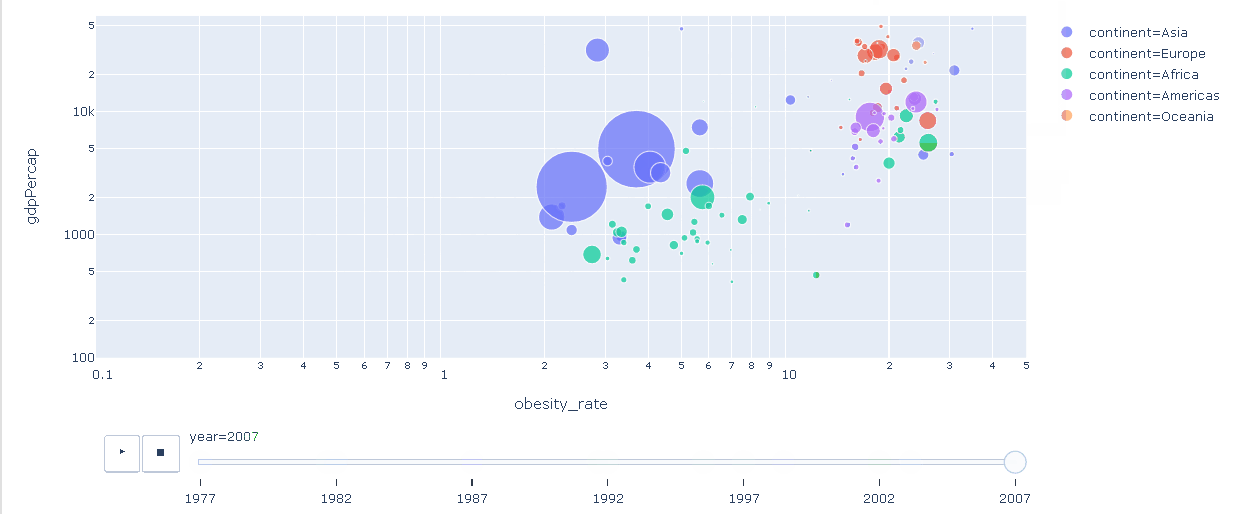
- Podemos utilizar bibliotecas como o Plotly para incrementar nossas análises com gráficos interativos!
Amei o Galeritas! Quero saber mais 💚
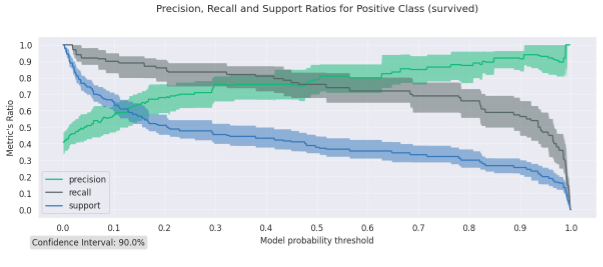
Temos um artigo no Galeritas detalhando as funções que já temos na biblioteca!
Leia no Medium da Creditas 😉
Também temos um gráfico para avaliar precisão, recall e suporte!
E tem mais coisas vindo para o Galeritas! 🎉
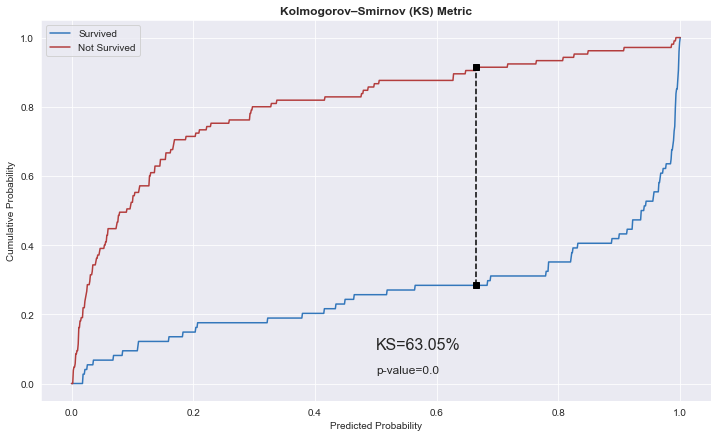
KS
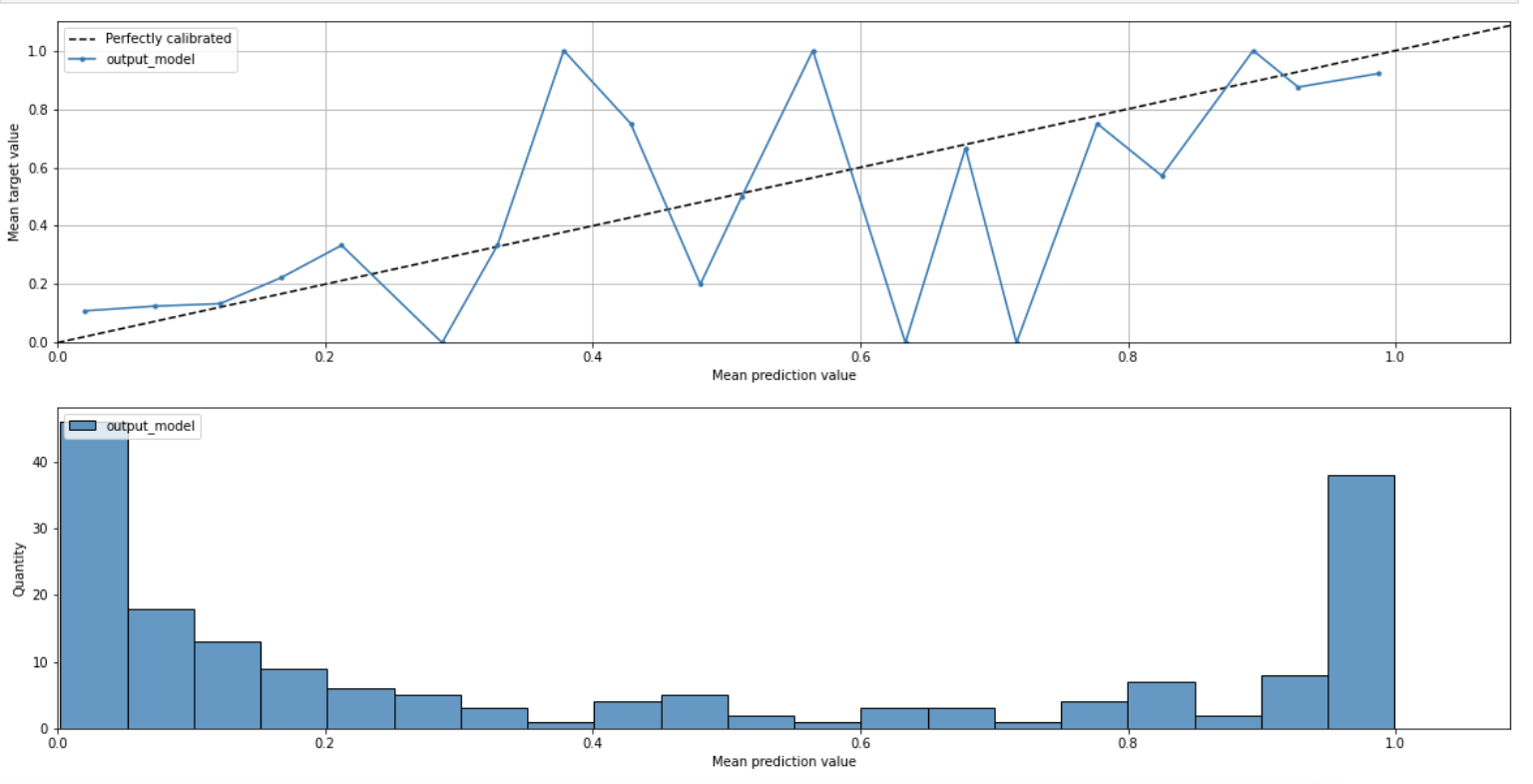
Calibragem de modelos
Como posso contribuir com o Galeritas?
Entre no Discord do projeto! 💚
Como posso contribuir com o Galeritas?
- Resolvendo issues do projeto;
- Revisando pull requests (PR);
- Ajudando a desenvolver algumas sugestões de gráficos;
- Criar e reportar uma issue quando encontrar algum bug ou problema;
- Compartilhar ideias de melhorias ou sugestões de novos gráficos;
- Ajudar a divulgar o projeto para pessoas que conhece e que poderiam usá-lo! 💚

Obrigada! :)
Nossos contatos
Nosso Twitter
Blog sobre Tech
Comunidade no Meetup
Linkedin e Instagram
Vagas
Slides disponíveis em: https://slides.com/vivianmayumiyamassaki/eda-creditas
Estamos com vagas abertas!!! 💚
Obrigada! :)
Nossos contatos
Nosso Twitter
Blog sobre Tech
Comunidade no Meetup
Linkedin e Instagram
Vagas
Slides disponíveis em: https://slides.com/vivianmayumiyamassaki/eda-creditas
Como fazemos a análise exploratória dos dados na Creditas
By Vivian Mayumi Yamassaki

