Binary Semantic Segmentation
Vladimir Iglovikov
Computer Vision Engineer at Lyft, Level5
Approach
- Q: What is the DeepHammer for binary segmentation?
- A: UNet.
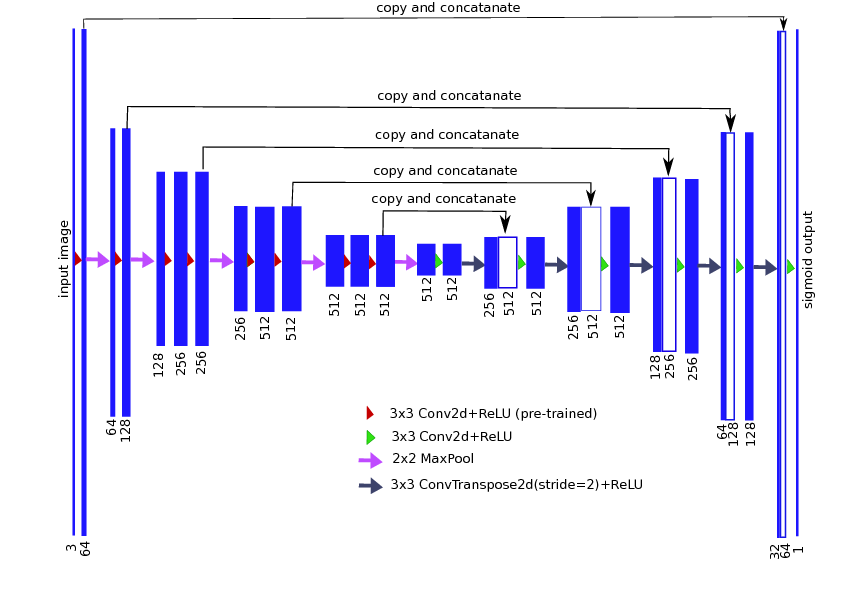

UNet: strong baseline for nearly every binary image segmentation problem





Vladimir's approach
TernausNet (UNet with pre-trained VGG11) encoder.
| arXiv:1801.05746 |

- 5 folds
- Input 1920x1280
- HSV / grayscale augmentations
- Cyclic Learning Rate
- Optimizer: Adam
- Batch size: 4
- Pseudo Labeling

Q: Does pre-trained encoder help UNet?
A: It depends.
- Pre-trained on 8Bit RGB will speed up convergence on 8bit RGB
- Pre-trained on 8bit RGB will not help on 11bit images. (Satellite)
Vladimir Iglovikov, Alexey Shvets TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation
| arXiv:1801.05746 |
Vladimir's approach
TernausNet (UNet with pre-trained VGG11) encoder.
| arXiv:1801.05746 |

Pseudo Labeling (useful at work)
- Train: 5088
- Public Test: 1200
- Private Test: 3664
- Unlabeled in test: 95200
Typically works if:
- A lot of unlabeled data.
- Prediction accuracy is high (in our case 0.997+)
Idea: pick the most confident predictions and add them to train data
Works well if you add more than the train set.
Alexander's approach
Had a set of GTX 1080 (not 1080 Ti) => No UNet in full HD

UNet => LinkNet (VGG encoder => Resnet encoder)
Alexander's approach
- 5 folds, 6 models
- LinkNet
- Augmentations: Horizontal flips, shifts, scaling, rotations, HSV augmentations
- Loss: BCE + 1 - Dice
- TTA: horizontal flips
- Optimizer: Adam, RMSProp
- Cyclic Learning Rate
- Hard negative mining
- CLAHE for preprocessing

Well written fast code for data augmentations: https://github.com/asanakoy/kaggle_carvana_segmentation/blob/master/albu/src/transforms.py
Artsiom's approach
- 7 folds, 2 models
- Initialization: ImageNet / Random
- Loss: Weighted BCE + 1 - Dice
- Optimizer: SGD
- Cyclic learning rate
- Augmentations: translation, scaling, rotations, contrast, saturation, grayscale


Merging and post-processing

- Simple average
- Convex hull for non-confident regions
- Thresholding at 0.5
Conclusion
- 1st out of 735
- $12,000 prize
- 10 evenings spent
- 20 GPUs used
- Full reproduction of training on one Titan Pascal X will take 90 days.
- Full reproduction of inference on one Titan Pascal X will take 13 days.
- We never met each other in person :D

Vladimir's DevBox.
Deep Learning and Crypto mining
- Blog post: http://blog.kaggle.com/2017/12/22/carvana-image-masking-first-place-interview/
- Code: https://github.com/asanakoy/kaggle_carvana_segmentation
- Code and weights for TernausNet: https://github.com/ternaus/TernausNet
Copy of Kaggle: Deep Learning to Create a Model for Binary Segmentation of Car Images
By Vladimir Iglovikov




