Agilité et DevOps
Master Expert Technologie de l'information EPITECH 2020.
Co-fondateur et CTO d'une startup dans l'Edtech 2019 - fin 2022. (+3 ans)
Formation PSPO-1 Agile Scrum 2022.
Co-fondateur et CTO d'une startup dans la Deeptech fin 2022 - aujourd'hui.
Valentin MONTAGNE

1
Découverte de l'Agilité et du guide SCRUM
3
Découverte du DevOps
2
La pratique de l'agilité
Déroulement du cours
4
Soutenance QCM
Chaque séance débutera par la présentation d'un concept et de l'intérêt d'utilisation de celui-ci.
1
Théorie
Après la théorie, nous verrons alors la pratique en réalisant des exercices sur un repository gitlab.
2
Pratique
Nous verrons ensemble la correction des travaux pratiques. N'hésitez pas à poser vos questions.
3
Correction
Déroulement des journées
Connaissez-vous l'agilité ?
QCM en notation individuelle
La soutenance
Découverte de l'Agilité
1.
Qu'est-ce que l'Agilité ?
Une philosophie centrée sur l’humain et l’adaptabilité
Une approche itérative et incrémentale
Un cadre d’équipe collaboratif et responsabilisant



L'Agilité c'est une philosophie, pas un Framework ou une méthodologie !
Une philosophie centrée sur l’humain et l’adaptabilité
L’Agilité repose avant tout sur des valeurs et des principes issus du Manifeste Agile (2001). Elle privilégie :
-
les interactions humaines plutôt que les processus rigides,
-
la collaboration avec le client plutôt que la négociation contractuelle,
-
la réactivité au changement plutôt que la planification exhaustive.
En résumé : on s’adapte en permanence pour créer de la valeur, plutôt que de suivre aveuglément un plan figé.
Une approche itérative et incrémentale
Les projets agiles avancent par petites étapes régulières (itérations ou sprints), à la fin desquelles un résultat concret et testable est livré :
-
Cela permet un retour rapide des utilisateurs,
-
On ajuste au fur et à mesure selon les besoins réels,
-
On réduit le risque d’échec à grande échelle.
En résumé : on apprend en faisant, en livrant souvent, et en s’améliorant à chaque boucle.
Un cadre d’équipe collaboratif et responsabilisant
L’Agilité mise sur :
-
des équipes autonomes et auto-organisées,
-
une communication constante (daily meetings, revues, rétrospectives),
-
une amélioration continue (feedback régulier, rétrospectives, ajustements).
En résumé : l’équipe est au cœur du dispositif et co-construit la solution avec les parties prenantes.
Pourquoi utiliser l'Agilité ?
Mieux répondre aux besoins réels du client
Réduire les risques et gagner en flexibilité
Valoriser les équipes et améliorer la collaboration



C’est une réponse concrète aux limites des méthodes traditionnelles dans un monde complexe et changeant.
Mieux répondre aux besoins réels du client
L’agilité permet une livraison fréquente et rapide de fonctionnalités utilisables. Cela favorise :
-
des retours clients réguliers,
-
des ajustements en continu,
-
et donc une meilleure adéquation avec les attentes.
Résultat : le produit final correspond mieux à ce que le client veut vraiment, même si ses besoins évoluent en cours de route.
Réduire les risques et gagner en flexibilité
Grâce à son approche itérative et incrémentale, l’agilité :
-
limite les gros échecs en fin de projet,
-
détecte les problèmes tôt,
-
et permet de s’adapter rapidement à de nouveaux contextes (marché, technologie, changement interne...).
Résultat : on minimise les pertes et on maximise la capacité à s’adapter.
Valoriser les équipes et améliorer la collaboration
L’agilité repose sur des équipes responsabilisées, auto-organisées, avec des rituels réguliers (daily, rétrospective, sprint review...). Cela :
-
renforce la motivation et l’implication,
-
améliore la communication interne et avec les parties prenantes,
-
et encourage une amélioration continue.
Résultat : une meilleure cohésion d’équipe et une dynamique positive de travail.
Les méthodologies Agile
Scrum
Axée itérative centrée sur des sprints pour livrer un produit fonctionnel.
Kanban
Axée visuelle de gestion de flux, basée sur un tableau de tâches
Extreme Programming
Axée sur la qualité du code et la collaboration développeurs-client.



Qu'est-ce que SCRUM ?
Une organisation par itérations courtes : les Sprints
Des rôles bien définis pour une équipe autonome
Des rituels pour structurer et améliorer le travail


Pourquoi utiliser SCRUM ?
Pour livrer rapidement de la valeur
Pour s’adapter en continu au changement
Pour renforcer la collaboration et l’autonomie des équipes


Des questions ?
Découverte du guide SCRUM
1.2
Le guide SCRUM
Je vous invite à lire le document officiel :
Synthèse du guide
Nous allons réaliser une rapide synthèse du guide pour revoir ensemble les points clés.
Le guide ne doit pas être une série de règles à suivre scrupuleusement, son but est de guider votre équipe et vous pouvez ajouter, retirer, modifier tout élément pour améliorer votre organisation.
Bien sûr, les modifications doivent suivre la philosophie Agile pour ne pas tomber dans de mauvaises dérives.
Théorie de Scrum
Scrum repose sur la théorie empirique de la gestion de projet, appelée empirisme. L’empirisme signifie que la connaissance vient de l’expérience et des décisions basées sur l’observation.
Trois pilliers :
-
Transparence - Tout le monde partage une compréhension claire et commune de ce qui est fait et comment.
-
Inspection - L’équipe observe fréquemment son travail et son avancement.
-
Adaptation - Si un écart est détecté, l’équipe s’adapte rapidement pour corriger la trajectoire.
Les 5 valeurs de Scrum
Les membres de l’équipe respectent ces valeurs au quotidien :
-
Engagement - Chacun s’engage à atteindre les objectifs de l’équipe.
-
Courage - L’équipe a le courage de faire ce qui est juste, de dire la vérité, de soulever les obstacles.
-
Focus (Concentration) - L’équipe se concentre sur le travail du Sprint et les priorités définies.
-
Openness (Ouverture) - Les membres sont ouverts aux idées, aux retours et aux changements.
-
Respect - Chacun respecte les compétences, opinions et rôles des autres.
Les 3 rôles de Scrum : Le Scrum Team
Dans Scrum, il n’y a qu’une seule équipe appelée Scrum Team, composée de 3 rôles complémentaires :
Product Owner (PO)
Scrum Master (SM)
Développeurs



Product Owner
Responsable de maximiser la valeur du produit.
Il gère le Product Backlog, c’est-à-dire :
-
Il définit et priorise les besoins (les User Stories),
-
Il est l’interface avec les parties prenantes (clients, métier...),
-
Il valide que ce qui est produit apporte de la valeur.
Il "décide" quoi faire, pas comment le faire.
Scrum Master
Facilitateur du cadre Scrum, garant du bon fonctionnement de l’équipe dans l’esprit agile.
Son rôle :
-
Aider l’équipe à comprendre et appliquer Scrum correctement,
-
Éliminer les obstacles à l’avancement,
-
Favoriser l’amélioration continue (notamment via les rétrospectives),
-
Coacher l’équipe et l’organisation sur l’agilité.
Il n’a aucun pouvoir hiérarchique, mais un rôle de support.
Développeurs
Ce sont les membres de l’équipe qui construisent l’incrément à chaque sprint.
Ils :
-
Planifient le travail du Sprint avec le PO,
-
S’auto-organisent pour atteindre l’objectif,
-
Garantissent la qualité de l’incrément livré.
Ce sont des experts techniques ou fonctionnels, responsables collectivement du résultat.
Attention, c'est un sens large, dès que quelqu'un contribue au développement du produit !
Les rituels (évènements)
Scrum possède plusieurs rituels (évènements à faire à chaque itération) :
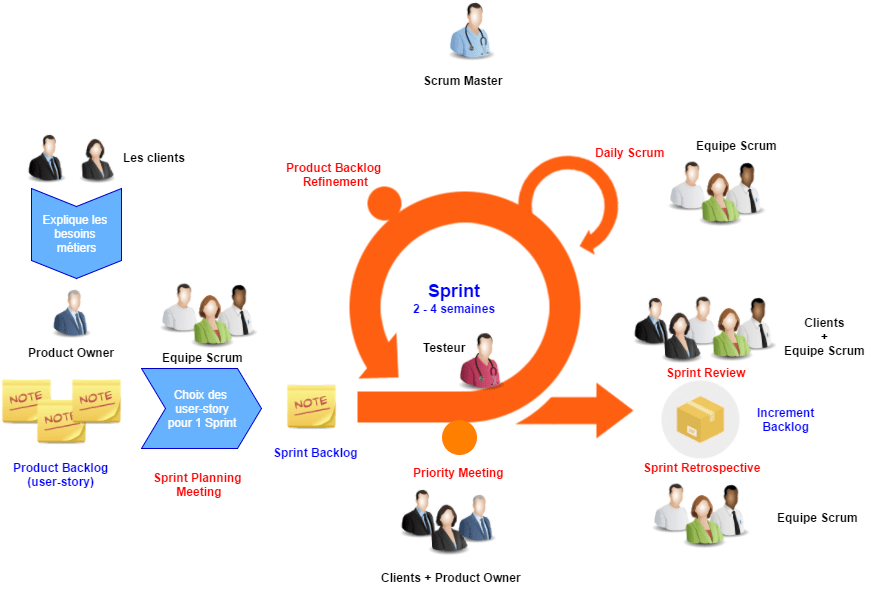
Les rituels
Les rituels clés :
-
Sprint - Cadre de travail
-
Sprint Planning - Démarrage
-
Daily Scrum - Suivi quotidien
-
Sprint Review - Bilan produit
-
Sprint Retrospective - Bilan d’équipe
Les rituels annexes :
- Backlog Refinement - Trier et prioriser
- Example Mapping - Définir les US
- Priority Meetings - Définir les priorités
Le Sprint
Le Sprint est l’unité de base du temps dans Scrum.
C’est une itération fixe, durant laquelle l’équipe produit un incrément utilisable et potentiellement livrable.
De 1 à 4 semaines, toujours de durée constante pour assurer un rythme stable.
Objectifs du Sprint :
Atteindre un Sprint Goal (objectif clair)
Livrer un incrément de qualité
Favoriser l’adaptation rapide
Le Sprint - Contenu et Règles
Le Sprint contient tous les événements Scrum :
-
Sprint Planning - planifier le travail,
-
Daily Scrum - suivre et ajuster chaque jour,
-
Sprint Review - présenter ce qui a été fait,
-
Sprint Retrospective - s’améliorer en équipe.
Règles clés
-
Aucun changement majeur n’interrompt un Sprint en cours.
-
L’objectif du Sprint (Sprint Goal) ne change pas.
-
Le scope (contenu) peut être ajusté si nécessaire par les développeurs avec le Product Owner.
Le Sprint Planning
Le Sprint Planning ouvre chaque Sprint. Il permet à toute l'équipe de décider quoi faire et comment le faire pendant l’itération.
-
Pourquoi ce Sprint est-il important ?
On définit le Sprint Goal, une vision commune et motivante. -
Que pouvons-nous livrer pendant ce Sprint ?
L’équipe sélectionne les items prioritaires du Product Backlog à développer. Ces éléments doivent être clairs, priorisés et estimés. -
Comment allons-nous faire le travail ?
Les développeurs découpent les items sélectionnés en tâches techniques dans un Sprint Backlog. Ils s’auto-organisent pour planifier leur travail.
Le Sprint Planning - Participants et Durée
-
Product Owner : apporte la vision, clarifie les besoins.
-
Développeurs : estiment, s’engagent sur ce qu’ils peuvent livrer.
-
Scrum Master : facilite la réunion, s’assure que Scrum est bien appliqué.
Durée
-
Maximum 8 heures pour un Sprint de 1 mois.
-
Proportionnellement moins pour un Sprint plus court (ex. 4h pour 2 semaines).
Daily Scrum
Le Daily Scrum est une réunion courte (15 minutes maximum) tenue chaque jour du Sprint par les développeurs pour synchroniser l’équipe pour atteindre l’objectif du Sprint.
Le Daily Scrum reste centré sur :
-
Ce qui a été fait depuis le dernier Daily,
-
Ce qui sera fait d’ici le prochain,
-
Les obstacles rencontrés,
-
Les ajustements nécessaires pour tenir le Sprint Goal.
Le format est libre, tant qu’il aide l’équipe à inspecter et adapter son plan quotidiennement.
Daily Scrum - Participants et limites
-
Les développeurs uniquement : ce sont eux qui parlent et s’auto-organisent.
-
Le Scrum Master et le Product Owner peuvent y assister, mais ne dirigent pas la réunion.
Ce que le Daily n’est pas :
-
Ce n’est pas un reporting au Scrum Master ou au PO.
-
Ce n’est pas un long débat technique ou une réunion de résolution de problèmes.
Sprint Review
Le Sprint Review (ou revue de Sprint) est une réunion qui a lieu à la fin du Sprint. Elle permet de présenter l’incrément livré et de recueillir des retours concrets des parties prenantes :
-
Présentation de l’incrément terminé (fonctionnalités développées),
-
Échange avec les parties prenantes (clients, utilisateurs, métiers),
-
Ce qui a été fait pendant le Sprint, ce qui a changé dans l’environnement ou les besoins, les prochaines priorités.
Résultat : une vision partagée de l’état du produit, et un Product Backlog mis à jour en fonction des retours.
Sprint Review - Participants et durée
-
Toute la Scrum Team (PO, SM, Développeurs),
-
Parties prenantes invitées par le PO (clients, utilisateurs, responsables métiers, etc.).
Durée
-
Maximum 4 heures pour un Sprint d’un mois (à ajuster selon la durée du Sprint, 2 heures pour 2 semaines).
Sprint Retrospective
La Sprint Rétrospective est la dernière réunion du Sprint.
Elle permet à la Scrum Team de réfléchir sur son fonctionnement et de s’améliorer en continu :
-
Revue de l’ambiance d’équipe, des processus, des outils, de la collaboration,
-
Identification des points positifs et des points à améliorer,
-
Choix d’actions simples et réalistes à tester dès le Sprint suivant.
Ce que ce n’est pas :
-
Ce n’est pas une réunion de blâme.
-
Ce n’est pas une réunion technique.
Sprint Retrospective - Participants et durée
-
Toute la Scrum Team (Product Owner, Scrum Master, Développeurs),
-
Pas de parties prenantes externes : c’est un moment interne de transparence et de confiance.
Durée
-
Maximum 3 heures pour un Sprint d’un mois (moins pour les Sprints plus courts, 1 heure pour 2 semaines).
Backlog Refinement
Le Backlog Refinement (ou "affinage du Product Backlog") est une activité continue, au cours de laquelle la Scrum Team prépare les éléments à venir pour les rendre clairs, compréhensibles et réalisables :
-
Découper des gros items (epics) en éléments plus petits,
-
Ajouter des détails ou critères d’acceptation,
-
Estimer (souvent avec des story points),
-
Clarifier les besoins métier avec le Product Owner,
-
Réévaluer la priorité des éléments si besoin.
Backlog Refinement - Participants et durée
-
Product Owner : responsable du Product Backlog, apporte les besoins.
-
Développeurs : apportent leur expertise technique, posent des questions, estiment.
-
Scrum Master : facilite si nécessaire, surtout si l’équipe débute.
Durée
-
Ce n’est pas un événement officiel Scrum, donc pas de durée fixe. Recommandé : 5 à 10 % du temps du Sprint (ex. : 1 à 2 heures pour un Sprint de 2 semaines).
Les artéfacts
Les artéfacts Scrum servent à rendre le travail visible, à focaliser l’équipe sur la livraison de valeur, et à favoriser l’inspection et l’adaptation :
- Product Backlog - Liste évolutive, priorisée et visible de tout ce qu’il y a à faire sur le produit.
- Sprint Backlog - Sélection d’items du Product Backlog engagés par les développeurs pour le Sprint, + le plan de réalisation + le Sprint Goal.
- Increment - Livrable fonctionnel à la fin de chaque Sprint.
- Definition of Done - Ensemble de critères de qualité partagés que chaque incrément doit respecter pour être considéré comme terminé.
Le Product Backlog
C’est une liste évolutive, ordonnée et transparente de tout ce qui doit être fait pour améliorer le produit.
Son objectif est de maximiser la valeur du produit en définissant, priorisant et rendant visibles les besoins à venir.
Seul le Product Owner est responsable de cet artefact.
Chaque élément est un Product Backlog Item (PBI), par exemple : User Stories, Bugs à corriger, Tâches techniques, Explorations ou prototypes.
Chaque PBI peut contenir une description claire, une valeur métier, des critères d’acceptation, une estimation.
Le Product Backlog - Points clés
-
Évolutif : le Backlog change et s’enrichit constamment,
-
Priorisé : les éléments les plus importants sont en haut,
-
Clair et compréhensible : pour que l’équipe puisse s’y préparer,
-
Affiné régulièrement lors des sessions de Backlog Refinement.
Le Sprint Backlog
Il représente l’engagement des développeurs pour le Sprint en cours. Son objectif est de donner une vision claire et partagée de ce que l’équipe va faire pendant le Sprint, et comment elle va s’y prendre.
Son contenu :
-
Les PBIs sélectionnés pour ce Sprint (objectifs de livraison).
-
Le Sprint Goal (objectif unique, motivant et clair).
-
Un plan d’action pour livrer ces items (souvent sous forme de tâches techniques).
Le Sprint Backlog - Responsabilités et limites
Le Sprint Backlog est créé par les développeurs lors du Sprint Planning. Il est mis à jour librement par les développeurs tout au long du Sprint. Le Product Owner n’intervient pas dans sa gestion, mais il peut clarifier les besoins si nécessaire.
Évolutif mais stable
-
Le Sprint Backlog évolue quotidiennement : les tâches peuvent être affinées ou ajustées.
-
Mais l’objectif du Sprint (Sprint Goal) reste fixe pendant toute la durée du Sprint.
L'Incrément
C’est le livrable produit à la fin du Sprint, qui doit être terminé, testable et potentiellement livrable.
Son objectif est de fournir un pas de plus vers l’objectif produit en livrant une fonctionnalité concrète, utilisable ou testable par les parties prenantes :
-
Il intègre le travail terminé pendant le Sprint,
-
Il respecte la Definition of Done (DoD),
-
Il est potentiellement livrable, même s’il n’est pas encore mis en production,
-
Plusieurs incréments peuvent être créés dans un même Sprint.
La Definition of Done (DoD)
La Definition of Done est un engagement qualité de la Scrum Team. Elle garantit que chaque Incrément livré est vraiment terminé, conforme aux exigences de qualité et prêt à être utilisé ou livré. Elle peut inclure :
-
Code développé et revu,
-
Tests unitaires/passés,
-
Documentation mise à jour,
-
Intégration continue réalisée,
-
Validation métier effectuée.
Tous les éléments sélectionnés dans un Sprint doivent respecter la DoD pour être inclus dans l’Incrément.
Qui peut la définir ?
L’équipe Scrum dans son ensemble, en particulier les développeurs.
Si l’organisation impose une norme de qualité, cette norme devient partie intégrante de la DoD.
En résumé :
La Definition of Done, c’est la checklist qualité de l’équipe Scrum. Elle permet de livrer des incréments vraiment terminés, partagés et sans ambiguïté. C’est une condition non négociable pour valider le travail comme fini.
La gestion du produit
Pour gérer au mieux le produit, le Product Owner doit mettre en place et définir certains éléments comme le Product Goal et les PBIs du Product Backlog, ici nous verrons le format des User Stories.
C'est la responsabilité du PO de maximiser la valeur du produit pour ses utilisateurs et clients et prioriser les éléments les plus importants.
Pour prioriser, on peut réaliser le ratio : Valeur / Complexité.
Pour définir la valeur, on peut utiliser la méthode de MoSCoW.
Product Goal
Le Product Goal (ou objectif produit) est l’engagement du Product Backlog.
Il donne une direction claire à l’équipe Scrum, en définissant ce que l’on veut atteindre à long terme avec le produit :
-
C’est le fil rouge de tous les Sprints : chaque incrément nous rapproche du Product Goal.
-
Il structure la roadmap produit,
-
Il donne du sens à la priorisation des items du backlog.
Le Product Owner est responsable de définir et partager le Product Goal, L’équipe s’y réfère pour prendre des décisions et rester alignée.
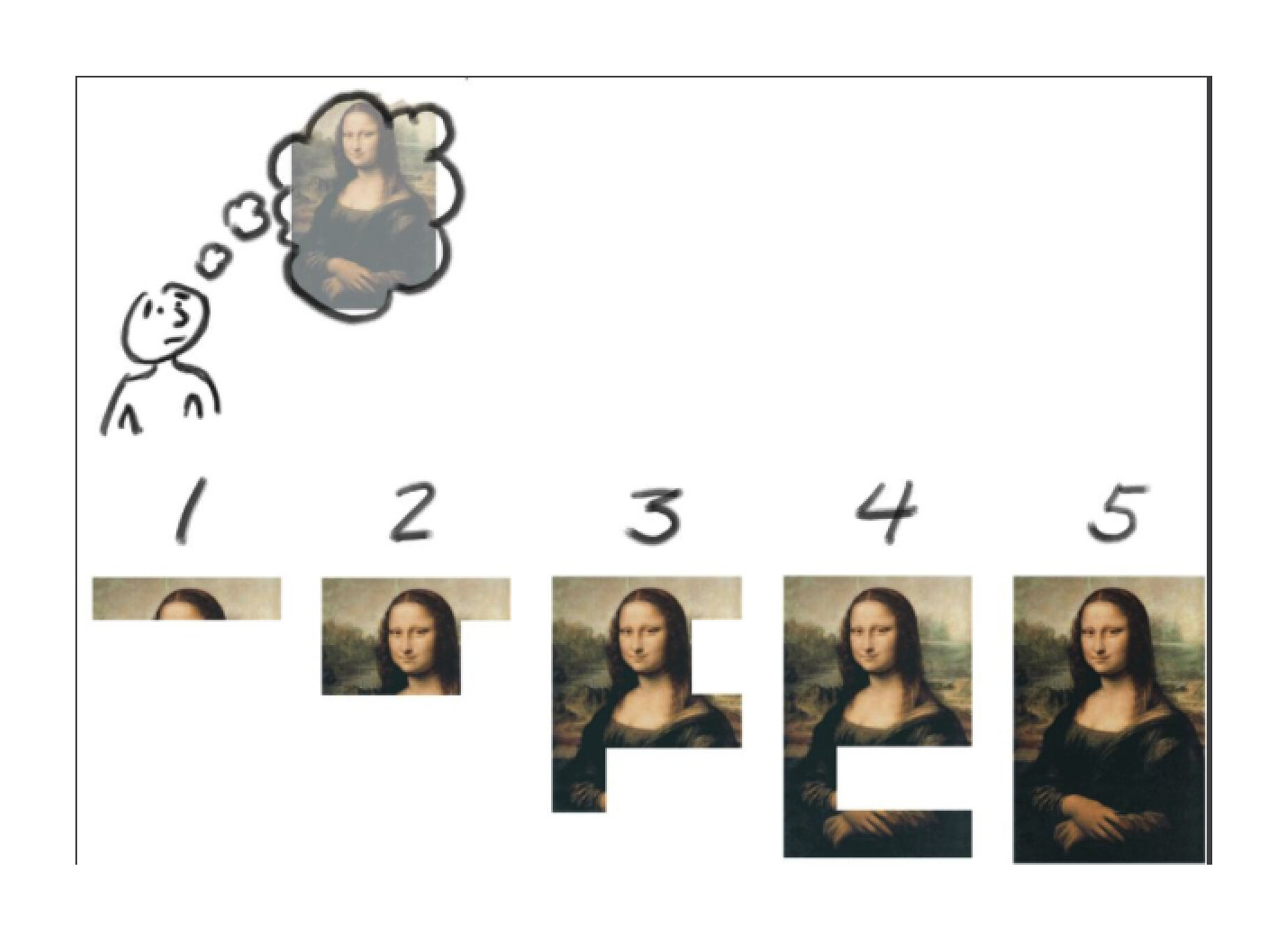
Qu'est-ce qu'une User Story ?
Créé dans Extreme Programming en 1999
Une fonctionnalité la plus minimale possible
Un support de validation du Product Owner et de l'utilisateur


Le format d'une User Story
Format :
En tant que <qui>, je veux <quoi> afin de <pourquoi>.
Exemple :
En tant que particulier, je veux chercher des artisans autour de chez moi pour une intervention rapide.
Que je résume dans mes propres US sous le format :
Titre - Particulier cherche des artisans autour de sa position
Description - Pour une intervention plus rapide, un particulier va chercher les artisans qui sont le plus proche de la position qu'il a enregistré comme étant son logement.
Les critères d'acceptation
Les critères d'acceptation (AC) permet à l'équipe de savoir les critères spécifiques à une US pour être validée. Par exemple, lorsque vous réalisez une identification :
- L'User peut choisir entre la connexion avec e-mail ou compte Google.
- Un message d'erreur apparaît quand l'email n'est pas du bon format.
- L'User peut utiliser le lien "J'ai oublié mon mot de passe" pour récupérer son mot de passe.
- Un message d'erreur apparaît quand l'User n'a pas utilisé le bon mot de passe ou le bon email.
Qu'est-ce que MoSCoW ?
La méthode MoSCoW permet de catégoriser les exigences d’un projet selon leur niveau d’importance.
Le nom est un acronyme basé sur les premières lettres de chaque catégorie :
- Must have : Sans eux, le Sprint ou le produit ne peut pas être livré.
- Should have : Leur absence peut être inconfortable, mais le produit reste fonctionnel.
- Could have : Apportent de la valeur ajoutée ou un petit plus.
- Won’t have : Permet de garder une trace de ce qui a été écarté.
Des questions ?
La pratique
2.
Création des groupes
6 personnes maximum, définissez qui aura le rôle du Product Owner, du Scrum Master et des Développeurs.
Trouvez un nom pour votre groupe !
Présentation des projets clients
Mise en relation entre particulier et artisan
Proposer toutes les prestations d'artisanats
Proposer les artisans proches du chantier
Arty, l'artisanat de demain.


Arty, l'artisanat de demain.
Le problème à résoudre :
Les particuliers qui ont besoin de réaliser des travaux ont du mal à trouver des artisans de confiance et leurs tarifs ; Cela peut conduire à des frais non prévus ou des dégâts quand l'artisan n'est pas professionnel.
Un système de recommendation
Un système de suggestion sur les critères du particulier
Offre détaillée de chaque artisan sur sa prestation
Arty, l'artisanat de demain.



Progresser rapidement grâce à des formations de seniors
Proposer toutes les catégories de formation professionnelle
Formation interactive avec exercices et corrections
Wisdom, devenir meilleur.


Wisdom, devenir meilleur.
Le problème à résoudre :
Les particuliers qui ont un plan de carrière difficile à atteindre ont du mal à monter en compétence quand ils sont isolés dans leur entreprise ; Cela ne leur permet pas de développer leurs compétences aussi vite qu'avec un senior dans leur équipe.
Un système d'éditeur de formation en ligne
Une IA qui réponds aux questions les plus posées ou redirige vers le senior
Notation des formations & recommendation
Wisdom, devenir meilleur.



Résoudre un escape game seul ou à plusieurs en VR de chez soi
Proposer les meilleurs escape games créés par des agences
Un système d'énigme et de mini-jeu poussé
Vscape, l'escape game chez soi.


Vscape, l'escape game chez soi.
Le problème à résoudre :
Les agences d'escape game ont du mal à avoir des revenues récurrents en fidélisant leurs joueurs ; La location de l'espace et du personnels est très coûteux et il n'y a pas beaucoup de re-jouabilité quand le joueur termine un escape game.
Un système d'éditeur d'escape game VR pour les agences
Un système de paiement par abonnement ou d'achat à l'unité
Notation des escape games & recommendation
Vscape, l'escape game chez soi.


Comment créer un produit ?
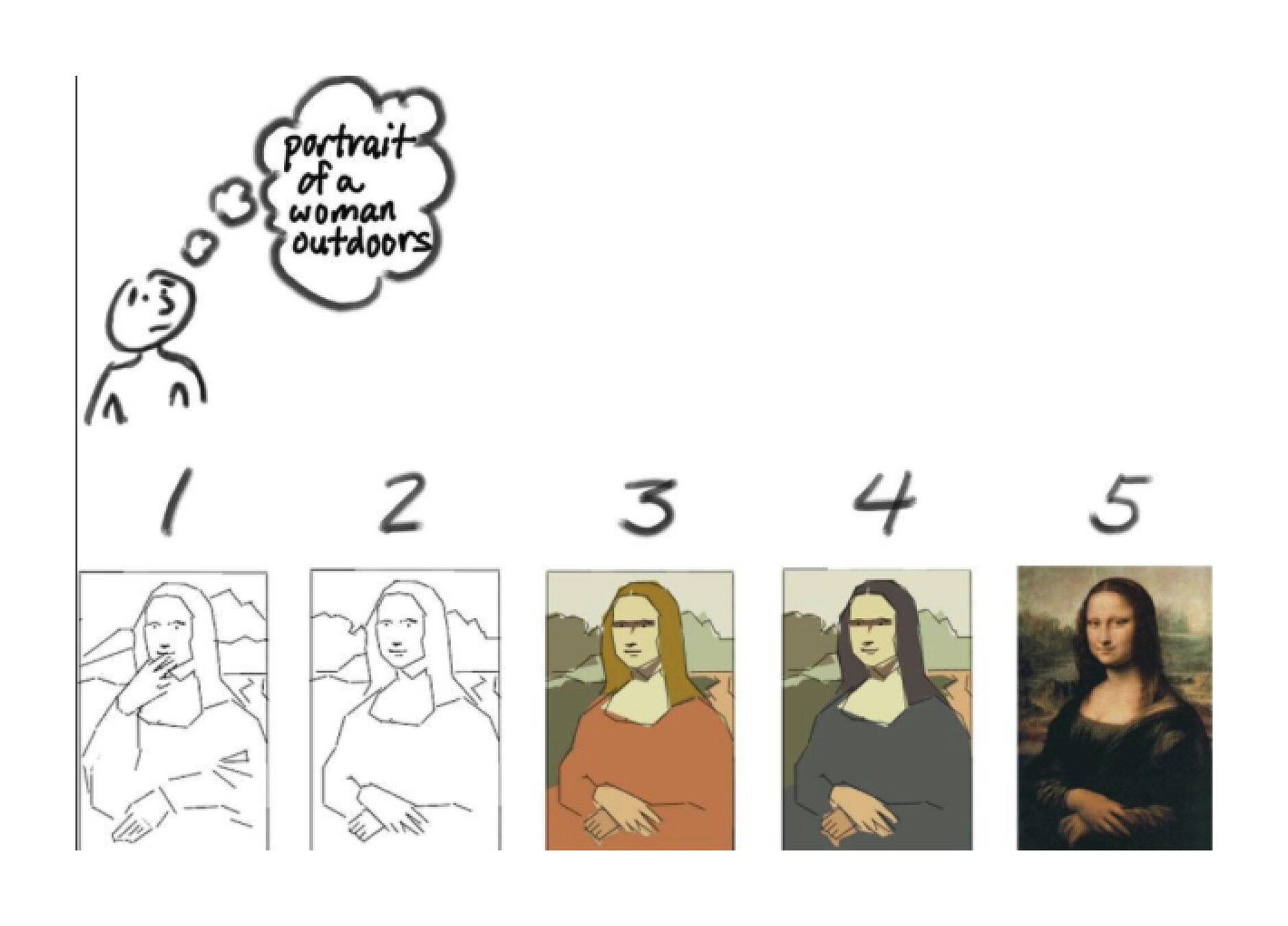
Règles pour l'atelier Scrum
Chaque itération dure 2 heures et comprend :
- Sprint Planning en 15 minutes
- Sprint en 1h15
- Sprint Review en 10 minutes
- Sprint Retrospective en 10 minutes
- Daily Scrum en 3/4 minutes
- Autres en fonction des besoins...
Le Daily Scrum est répété toutes les 20 minutes pendant le Sprint, pour favoriser l’alignement et l’auto-organisation.
Je serais présent en tant qu'Observateur ou Client en fonction du type de rituel, c'est au Scrum Master de m'appeler.
Quel outil pour l'atelier ?
On utilisera Miro tout le long de l'atelier.
L'outil permet de réaliser un Product Backlog et de créer des Sprints.
C'est la responsabilité du Product Owner et du Scrum Master de mettre en place l'outil et de l'expliquer aux équipes.
(Pas de stress, la mise en place se fera au fur et à mesure)
C'est parti !
Le DevOps
3.
Qu'est-ce que le DevOps ?
Une culture, des pratiques et des outils.
Fusionner les équipes de développement (Dev) et d’exploitation (Ops).
Livrer des applications plus vite, plus souvent et plus fiablement.

Pourquoi le DevOps ?
Avant, séparation entre l'équipe de Dev et l'équipe Ops.
Des conflits : "Ça marche sur ma machine !", problème de déploiement et bugs en production.
Assure la collaboration et l'automatisation du déploiement.
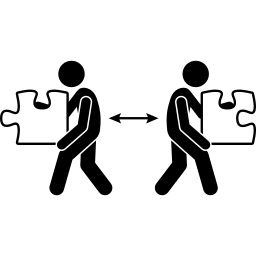


5 Piliers du DevOps
- Collaboration : adieu la séparation Dev et Ops.
- Automatisation : chaque tâche répétitive doit être automatisée.
- Intégration Continue : chaque ajout doit être fonctionnel.
- Déploiement Continue : chaque ajout doit être déployable.
- Monitoring Continue : le système est transparent.
Les phases du DevOps
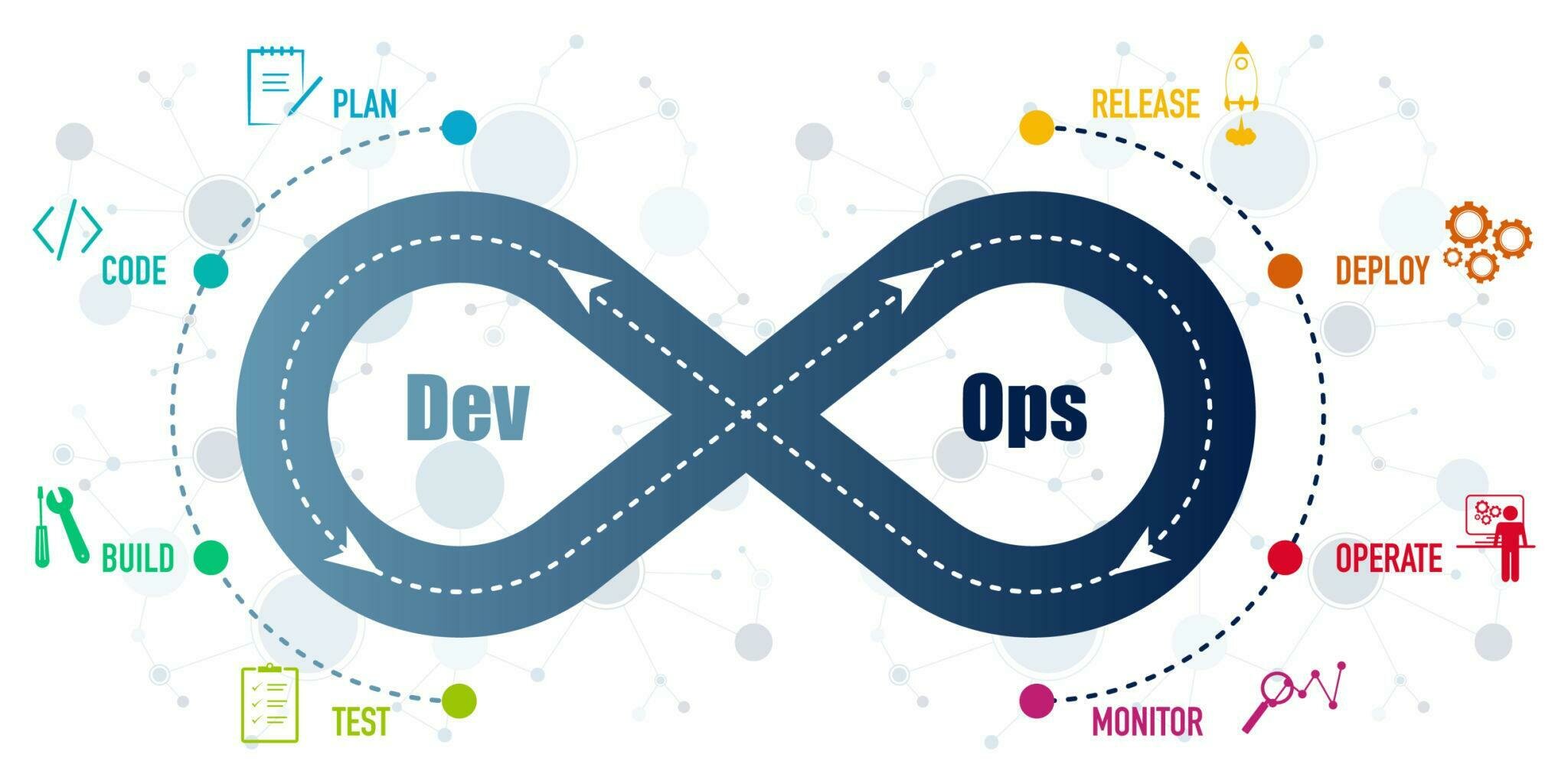
Scientifiquement prouvé
Corrélation entre les performances et le bien-être au travail avec le CI / CD et le Lean
Computers perform repetitive tasks; People solve problems.
Key Indicators
- Delivery lead time
- Deployment frequency
- Time to restore service
- Change fail rate
DORA - DevOps Status
Lean, Agile, etc.
Beaucoup de méthode de gestion d'entreprise, de projet ou de produit se base sur une itération continue où l'apprentissage est la clé.
Pour supporter le Lean et Agile
Google Design Sprint
Grâce au Sprint Design, Google est capable de tester une nouvelle fonctionnalité en 5 jours ouvrés.
Course à l'itération !
Pour cela, les équipes ont besoin de méthodes pour éviter les régressions et augmenter la rapidité des livraisons.
Les outils
Créé par Kohsuke Kawaguchi en 2011 avec Oracle car réalisé en Java.
Open source, s'interface avec des systèmes de versions comme Git.
Automatise le build, les tests et le déploiement.

Créé par Gitlab Inc. en 2014, open source avec une version Entreprise.
Solution tout-en-un du CI / CD avec gestion des issues et pipelines liés aux projets.
Permet d'héberger une version de Gitlab directement sur les serveurs de l'entreprise.


Après l'impulsion du rachat par Microsoft, créations de la partie Actions de Github en 2018.
Leader dans le stockage de dépôt de code et développement de projet Open Source, grande communauté.
Plus limité que Gitlab CI sur la partie DevOps / Docker.



Git Hooks
Les hooks sont des scripts qui s'exécutent automatiquement à des moments précis du Workflow Git, par exemple lors d'un commit, pull ou push des modifications d'un dépôt. Ces scripts peuvent être utilisés pour effectuer diverses tâches, comme la validation du code, le formatage des fichiers ou même l'envoi de notifications.
Il existe deux types de hooks Git :
Côté client : Ils sont exécutés sur votre machine locale avant d'effectuer des modifications.
Côté serveur : Ils sont exécutés sur le serveur distant lorsque vous transférez des modifications.
Nous allons utiliser cet outil côté client pour éviter qu'un développeur ne commit du code qui n'est pas validé par notre CI.
Conteneurs et Orchestration
Docker & Docker Swarm
Kubernetes
Qu'est-ce que le déploiement continu ?
Le code est déployé après chaque modification.
Au vu de la fréquence, on automatise alors le déploiement.
Plusieurs stratégies de déploiement existent. (Blue / Green, Feature Flag, Canary...)

Pourquoi utiliser le déploiement continue ?
Gérer correctement les différents environnements de la solution.
Identifier et corriger rapidement les bugs et régressions.
Améliorer la stabilité de la solution et revenir rapidement à la version d'avant.



Externaliser son infrastructure
Automatiser et monitorer le déploiement des applications
Cloud as a service
Code as Infrastructure
Définir toute son infrastructure via des fichiers de configuration.
Automatiser la création, l'édition et la suppression des ressources de l'infrastructure dans le cloud.
Suivre les différentes versions de l'infrastructure en fonction de la solution.


Automatise le déploiement sur tous les grands Clouds.
Est capable de gérer des grands cluster avec Kubernetes.
S'intègre facilement dans les pipelines CI / CD.


Stratégies de déploiement
Blue / Green
Feature Flag
Canary



1. Comment déployer fréquemment sans interrompre les utilisateurs ?
2. Comment déployer fréquemment sans bugs ou régressions pour les utilisateurs ?
3. Comment tester les changements avec de vrais utilisateurs ?
Stratégie Blue / Green
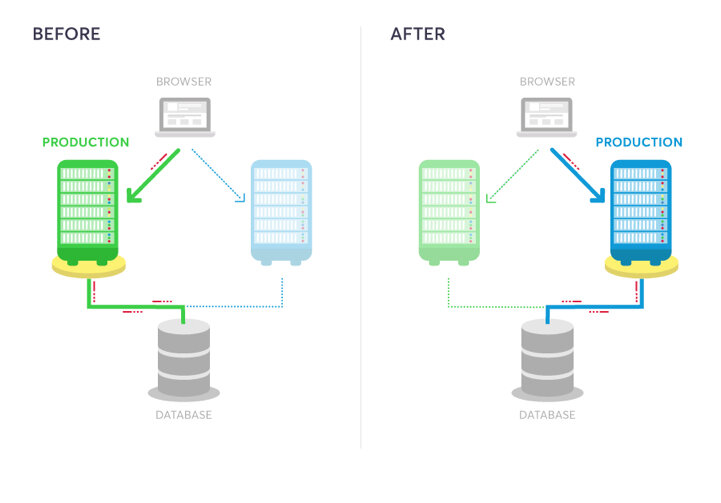
On crée deux environnements distincts mais identiques. Un environnement (Blue) exécute la version actuelle de l'application et un environnement (Green) exécute la nouvelle version de l'application.
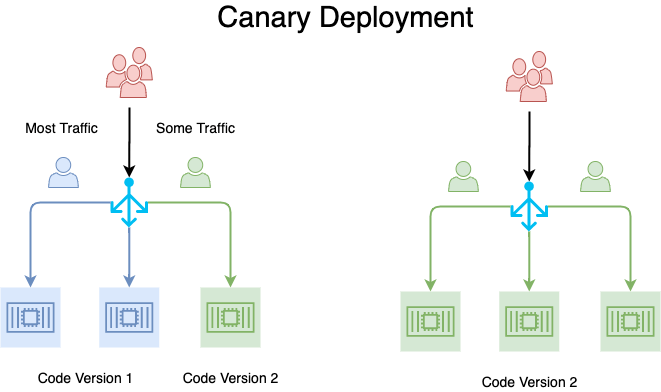
Stratégie Canary
Redirige le trafic d'une portion des utilisateurs en fonction de critères ou d'un simple pourcentage vers la nouvelle version. Après un certain temps ou d'une condition, l'ensemble du trafic est rédirigé.
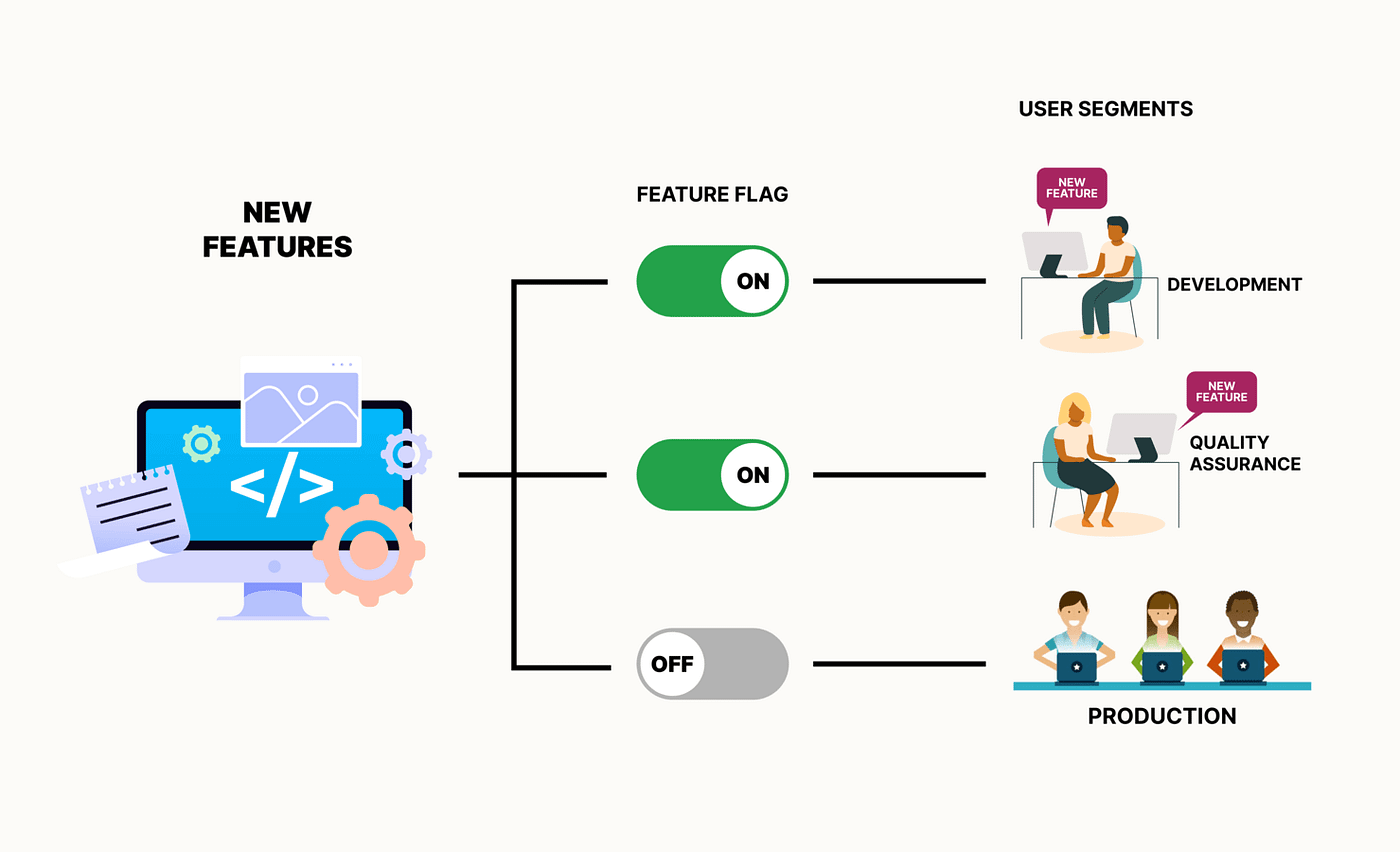
Stratégie Feature Flag
Gère les fonctionnalités dans le code source. Une condition dans le code permet d'activer ou de désactiver une fonctionnalité pendant l'exécution. Voir Unleash.
Des questions ?
La pratique
Rendu des TPs et exercices
Je vais noter votre investissement durant nos séances.
Si votre dépôt Gitlab est en privé, n'oubliez pas de m'ajouter les droits :
vm-marvelab en tant que Développeur.
N'oubliez pas le .gitignore pour éviter d'ajouter les node_modules.
À la fin de la dernière séance, il suffira de m'envoyer un e-mail contenant le lien de votre dépôt.
Création d'une pipeline CI
Création du compte Gitlab
Si vous n'avez pas encore de compte Gitlab, je vous invite pour la suite du TP et des exercices à créer un compte avec votre adresse étudiante.
Récupérer le projet de base
Maintenant que vous avez un compte Gitlab, vous pouvez "Fork" directement le projet ou le cloner sur votre machine et créer un nouveau projet vide pour récupérer le contenu du projet de base pour réaliser ce TP :
https://gitlab.com/vm-marvelab/ci-cd
(Tous les fichiers sont à mettre à la racine de votre dépôt.)
Auth API
Le projet de base est une API très simple en NodeJS, elle utilise Express pour lancer un serveur qui écoute les requêtes sur des routes définies.
N'hésitez pas à lire le README pour comprendre comment fonctionne la route /auth.
Utilisez la commande pour installer les dépendances du projet :
npm install
Ensuite utilisez la commande pour lancer l'API :
npm start
Configuration pipeline CI - 1
Maintenant que notre projet de base fonctionne, nous allons commencer à intégrer notre pipeline CI.
Pour cela, créez à la racine du projet le fichier .gitlab-ci.yml
N'hésitez pas à installer une extension sur votre IDE pour vous aider avec le format du fichier.
Passons à la prochaine étape.
Configuration pipeline CI - 2
Nous devons spécifier avec quel image notre Runner doit s'executer pour lancer notre pipeline CI, étant une API en nodejs, nous allons utiliser une image nodejs.
Nous allons ajouter des informations sur le cache pour éviter qu'à chaque Job de chaque Stage que nous soyons obliger de réinstaller les dépendances.
# .gitlab-ci.yml file
image: node:latest
cache:
key:
files:
- package-lock.json
paths:
- node_modules/
- .npm/
Configuration pipeline CI - 3
Comme vu ensemble, un Job est une étape spécifique du processus, comme exécuter des tests, compiler du code, ou déployer une application. Un job peut être configuré avec des scripts, des environnements d'exécution, et des conditions spécifiques (par exemple, quand il doit être exécuté). Plusieurs jobs peuvent s'exécuter en parallèle ou en séquence, en fonction des dépendances et de la structure du pipeline.
Un Stage est un groupe de Job et permet d'organiser la pipeline, ils s'exécutent dans l'ordre dont ils sont définis.
Configuration pipeline CI - 4
Définissons nos Stages et réalisons notre premier Job qui sera l'installation des dépendances à la suite du fichier :
stages:
- validate
- test
- build
- release
- deploy
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
Ici le stage .pre est un Stage déjà créé par Gitlab, il est obligatoirement le premier à être lancé.
Nos Stages sont les étapes habituelles d'une pipeline de CI / CD.
Configuration pipeline CI - 5
Une fois ajouté, réaliser un git commit et un git push pour envoyer les changements à votre dépôt sur Gitlab.
Une fois fait, allez dans la section Build dans la barre à gauche du dépôt sur gitlab.com et cliquez sur Pipelines, il n'y a pas encore de Pipeline lancée, c'est parce que nous n'avons pas encore de Job hors installation.
Passons à l'étape suivante pour réaliser notre Stage validate.
Configuration pipeline CI - 6
Ajoutons maintenant le Stage de validation, pour cela nous allons ajouter les outils Eslint pour vérifier la qualité de notre code NodeJS :
npm init @eslint/config@latest
Choisissez les options "Style et problems", puis "CommonJS", "None of these", "No" pour Typescript et cochez "Node".
Un nouveau fichier eslint.config.mjs est apparu, passons à l'étape suivante.
Configuration pipeline CI - 7
Changez la configuration du fichier pour ignorer les fichiers de tests et ajouter des règles comme ici ne pas avoir de variables inutilisés, de variable non défini ou de console.log dans le code.
// eslint.config.mjs
import globals from "globals";
import pluginJs from "@eslint/js";
export default [
{
ignores: ["**/*.test.js"],
files: ["**/*.js"],
languageOptions: { sourceType: "commonjs" },
},
{ languageOptions: { globals: globals.node } },
pluginJs.configs.recommended,
{
rules: {
"no-unused-vars": "error",
"no-undef": "error",
"no-console": "error",
},
},
];
Configuration pipeline CI - 8
Ajoutons maintenant le script "lint" au package.json pour pouvoir lancer la commande :
npm run lint
// package.json
// ...
"scripts": {
"start": "node src/index.js",
"lint": "eslint src --max-warnings=0"
},
// ...
Configuration pipeline CI - 9
Ajoutons maintenant un console.log que l'on a "oublié" dans une route de notre API dans le fichier index.js qui affiche la variable secret et qui ne devrait pas être dans nos logs !
const express = require("express");
const auth = require("./modules/authentication");
const app = express();
const port = process.env.PORT || 3000;
app.get("/", (req, res) => {
res.send("Hello World!");
});
app.get("/auth/:secret", (req, res) => {
const { secret } = req.params;
const response = auth(secret);
console.log(secret);
res.status(response.status).send(response.message);
});
app.listen(port, () => {
// eslint-disable-next-line no-console
console.log(`Example app listening on http://localhost:${port}`);
});
Configuration pipeline CI - 10
Lancez la commande npm run lint vous devriez maintenant avoir une erreur.
Ajoutons maintenant un Job dans notre pipeline CI pour lancer cette commande automatiquement. A la suite du fichier .gitlab-ci.yml, ajoutez le Job lint dans le Stage validate.
// .gitlab-ci.yml
// ...
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
lint:
stage: validate
script:
- npm run lint
Configuration pipeline CI - 11
Faites un nouveau commit et faites un push sur la branch main à nouveau et retournez voir les Pipelines de votre dépôt pour voir le résultat.
La même erreur est détecté automatiquement par votre CI maintenant. Enlevez le console.log et faites de nouveau un push pour corriger le problème.
Mais cela serait plus fiable si l'on détectait ce genre de problème avant qu'il n'arrive sur notre pipeline non ?
Mettons en place notre Git hooks à l'étape suivante.
Installation des Git hooks - 1
Maintenant nous allons installer Husky à notre projet, qui permet de mettre en place les Git hooks pour nous permettre d'executer notre validation ou nos tests avant chaque commit. Cela rentre totalement dans l'intégration continue pour éviter de commit du code qui n'est pas fonctionnel ou de mauvaise qualité.
Lancez la commande :
npm install --save-dev husky && npx husky init
Husky génère alors un dossier .husky, ouvrez le fichier pre-commit dans ce dossier et changez npm test par npm run lint.
Installation des Git hooks - 2
Essayez de commit, vous allez maintenant avoir npm run lint qui s'execute automatiquement. Essayez d'oublier à nouveau un console.log dans le code, lors de la tentative de commit vous devriez être bloqué par l'echec de la commande npm run lint.
Maintenant ajoutons les tests à notre pipeline à l'étape suivante.
Ajout des tests - 1
Pour réaliser l'étape des tests, nous allons installer Vitest :
npm install -D vitest
Ensuite, ajoutons dans package.json la commande "test".
// package.json
// ...
"scripts": {
"start": "node src/index.js",
"lint": "eslint src --max-warnings=0",
"prepare": "husky",
"test": "vitest run"
},
"devDependencies": {
// ...
Vérifiez que tout est fonctionnel avec la commande :
npm test
Ajoutez ensuite cette commande au Git hooks.
Ajout des tests - 2
Ensuite, ajoutons notre Job unit-test qui sera dans notre Stage test.
// .gitlab-ci.yml
// ...
install:
stage: .pre
script:
# define cache dir & use it npm!
- npm ci --cache .npm --prefer-offline
lint:
stage: validate
script:
- npm run lint
unit-test:
stage: test
script:
- npm test
Faites un push à nouveau et vérifiez que le job apparait bien dans votre pipeline et qu'il lance les tests.
Variables d'environnement et Rules - 1
Nous allons maintenant permettre de release une version de notre API via notre Pipeline. Ce Job doit alors être manuel pour nous laisser la possibilité d'activer la release au bon moment.
Par sécurité nous allons ajouter des Rules pour éviter que le Job Release se lance sur d'autres branches que main.
Pour créer une nouvelle version nous allons utiliser Release-it :
npm init release-it
Choisissez les réponses "Yes" et "package.json" à l'installation.
Variables d'environnement et Rules - 2
Ajoutez dans le package.json dans le champ "release-it" les informations "git" suivantes :
Voir à l'étape suivante l'ajout au .gitlab-ci.yml du Stage Release.
// package.json
// ...
"dependencies": {
"express": "^4.18.2"
},
"release-it": {
"$schema": "https://unpkg.com/release-it/schema/release-it.json",
"gitlab": {
"release": true
},
"git": {
"commitMessage": "chore: release v${version}"
}
}
// ...Variables d'environnement et Rules - 3
// .gitlab-ci.yml
// ...
unit-test:
stage: test
script:
- npm test
release:
stage: release
when: manual
rules:
- if: '$CI_COMMIT_BRANCH == "main"
&& $CI_COMMIT_TAG == null
&& $CI_COMMIT_TITLE !~ /^chore: release/'
before_script:
- git config user.email $GITLAB_USER_EMAIL
- git config user.name $GITLAB_USER_NAME
- git remote set-url origin
"https://gitlab-ci-token:$GITLAB_TOKEN@$CI_SERVER_HOST/$CI_PROJECT_PATH.git"
- git checkout $CI_COMMIT_BRANCH
- git pull origin $CI_COMMIT_BRANCH --rebase
script:
- npx --yes release-it --ciVariables d'environnement et Rules - 4
// Permet de spécifier que ce Job sera activé manuellement.
when: manual
// Permet d'ajouter des rules au Job pour l'afficher ou non grâce au if.
// Ici le commit doit être sur la branche main, cela ne doit pas être un tag
// et le title du commit doit être différent de ce format.
rules:
- if: '$CI_COMMIT_BRANCH == "main"
&& $CI_COMMIT_TAG == null
&& $CI_COMMIT_TITLE !~ /^chore: release/'Quelques explications :
Variables d'environnement et Rules - 5
Ensuite, pour fonctionner, Release-it a besoin d'une variable d'environnement GITLAB_TOKEN. Pour cela nous allons devoir l'ajouter manuellement, mettez votre souris sur Settings et cliquez sur CI / CD, ensuite ouvrez le menu Variables. Ouvrez sur une autre page vos Access Tokens en mettant votre souris sur votre profil en haut à gauche, puis en cliquant sur Préférences, là vous devez cliquer sur Access Tokens et générer un nouveau Token avec les droits api.
Ajoutez ce token dans une nouvelle variable CI / CD de votre projet GITLAB_TOKEN.
Faites un push et lancez la release.
Appelez-moi quand vous avez terminé pour que l'on valide ensemble le TP.
TP - Déployer Docker
Maintenant que vous avez terminé une partie de l'intégration continue, nous allons maintenant voir le côté déploiement continu.
Pour cela, nous allons rajouter les étapes de builds pour l'image Docker et du déploiement de celle-ci.
Vous devez réaliser un fichier Dockerfile pour build le projet.
Ensuite, ajoutez l'étape suivante build-image :
# If your language needs to build you can create another build job before
# Add docker job to build the image
# Only for testing purpose, you can add a docker run + command to check health
# Gitlab has a lot of variables to use in the pipeline
# Here we are using $CI_REGISTRY_IMAGE and $CI_COMMIT_SHORT_SHA
build-image:
stage: build
image: docker:20.10.16
services:
- docker:20.10.16-dind
variables:
IMAGE_TAG: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
script:
- docker image build -t $IMAGE_TAG .
TP - Déployer Docker - 2
Ici, nous utilisons un service spécial docker:20.10.16-dind pour permettre l'utilisation de Docker dans un container Docker.
On pourrait ici build plusieurs images si besoin durant cette étape.
Vérifiez que cette étape fonctionne en réalisant un push sur votre branche.
Ajoutez ensuite l'étape deploy-image :
deploy-image:
needs:
- release
image: docker:20.10.16
stage: deploy
rules:
- if: '$CI_COMMIT_BRANCH == "main" && $CI_COMMIT_TAG == null && $CI_COMMIT_TITLE !~ /^chore: release/'
services:
- docker:20.10.16-dind
variables:
IMAGE_TAG: $CI_REGISTRY_IMAGE:$CI_COMMIT_SHORT_SHA
script:
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY
- docker image build --platform=linux/amd64 -t $IMAGE_TAG -t $CI_REGISTRY_IMAGE:latest .
- docker push $CI_REGISTRY_IMAGE --all-tags
environment: productionExemple de déploiement
Vérifiez après avoir push à nouveau les changements que votre image est bien ajoutée dans votre Container Registry en allant dans le menu Deploy sur votre dépôt Gitlab. C'est terminé !
Voici un exemple pour déployer sur un serveur distant, ceci n'est pas la meilleure méthode mais elle est très simple.
deploy:
needs:
- deploy-image
stage: deploy
rules:
- if: '$CI_COMMIT_BRANCH == "main" && $CI_COMMIT_TAG == null && $CI_COMMIT_TITLE !~ /^chore\(release\): publish/ && $CI_COMMIT_TITLE !~ /^chore\(pre-release\): publish/'
before_script:
- 'which ssh-agent || ( apt-get update -y && apt-get install openssh-client -y )'
- mkdir -p ~/.ssh
- eval $(ssh-agent -s)
script:
- ssh-add <(echo "$SSH_PRIVATE")
- ssh -o StrictHostKeyChecking=no "$SSH_SERVER" 'which docker || (sudo yum update -y && sudo yum install -y docker && sudo service docker start)'
- <SAME> "sudo docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY"
- <SAME> "(sudo docker rm -f example || true) && sudo docker run -p 80:3000 -d --name example registry.gitlab.com/vm-marvelab/docker-cicd:$CI_COMMIT_SHORT_SHA"
environment: productionExercice 1 : lancer l'image Docker
Lancez l’image Docker que vous avez générée avec votre pipeline CI/CD directement sur votre machine afin de vérifier son bon fonctionnement.
Exercice 2 : plusieurs applications
Maintenant, on part sur une autre base pour créer une nouvelle pipeline CI / CD qui va elle aussi jusqu'à la création des images Docker en partant de ce projet :
https://gitlab.com/vm-marvelab/ci-cd/-/tree/example?ref_type=heads
Ce projet comporte deux applications : un backend et un frontend, qui devront tous deux être testés par la pipeline.
4.
N'hésitez pas à me donner votre avis.
Merci!
Agilité et DevOps
By Valentin MONTAGNE



