Foundations for Decentralization:
Data with IPLD
interplanetary
linked
data
Some neat specs for: serialization, canonical hashing, immutable linking, and protocol design
-
motivations
-
thE STUFF
- The Codec Layer
- The Data Model
- The Schema Layer
-
wHERE TO NEXT?
history
but first,
a little
IPLD originated from the IPFS project group
IPFS is for files, right?

Well, yeah. But what are "files" but a particular case of of some tree structures?
IPFS is for files, right?
Each of the points in this graph is
an IPLD object.
much like git is just a blob store,
IPFS is just an IPLD store.
They both just "happen" to have some porcelain
that makes them good at storing and manipulating files.
And IPLD objects are a bit like a structured format
for making new objects like git's internals, but more generally!
motivations
let's be honest...
scratching our own itch.
We needed this in IPFS.
Our needs aren't that rare.
Why not make it reusable?

Building should be easier.
We want to make building applications easier.
Building should be easier.
We want to make building *distributed* applications easier.
linking -- by hash -- needs to be first-class
Immutable links are a powerful primitive.
Content-addressable systems are good.

Formats shouldn't matter
JSON.
CBOR.
Protobuf.
Git packs.
Chain blocks.
Whatever.

protocols need schemas
We need tools for data-description that are
decentralization-friendly,
language agnostic,
and grok immutable links.
Most existing systems are very 'cathedral'; do not want

building the next git...
should take hours, not days.
overall,
-
MOTIVATIONS
-
THE STUFF
- The Codec Layer
- The Data Model
- The Schema Layer
-
WHERE TO NEXT?
-
MOTIVATIONS
-
THE STUFF
- The Codec Layer
- The Data Model
- The Schema Layer
-
WHERE TO NEXT?
"codecs" in IPLD are pretty familiar
- Decoding: bytes go in, trees come out
- maps and lists and ints and strings, etc
- Encoding: trees go in, bytes come out
- JSON! CBOR! Msgpack? Protobufs. etc...
"codecs" in IPLD are pretty familiar
So what if we could standardize this?
EVERYONE ACTUALLY AGREES ON THIS ALREADY
(Defacto, at least)
(WHICH IS AWESOME!)
building towards the data model
- So we basically took the typical things...
- maps...
- lists...
- ints...
- strings...
- bytes (!)...
- bools...
- And made that into a standard "Data Model",
- which all of our Codecs map onto and from!
one more thing
links
MANY OF THE INTERESTING APPLICATIONS...
have links.
So we hoist links into the model
- A "link" is an opaque concept that means
"something I can load later". - Links in IPLD must be immutable.
- generally, a hash.
- This describes Git. This describes IPFS.
This describes Eth. This describes BTC.
This describes .......
So we hoist links into the model
... as `CID`s.
<cid> ::= <cid-version><multicodec><multihash>
CID -- Content Identifiers -- are a simple standard for content-addressable links.
They provide for future-proof versioning at the lowest levels, choice of hash, etc!
So we hoist links into the model
... as `CID`s.
<cid> ::= <cid-version><multicodec><multihash>
We map other systems (e.g. Git, which has its own native hashing scheme) into CID space by assigning them a "multicodec" marker number.
cid is context-free

Text
CIDs can be represented as strings or bytes.
Pictured: unpacking the prefixes, you can see this this CID refers to raw bytes, uses a sha-256 hash, etc.
wrangling codecs
Some codecs can represent any arrangement of maps and lists and whatever map keys you want, etc. JSON and CBOR and other general serialization formats can do this.
native vs Partial
Some codecs have opinions about what they can store. Protobufs, for example, must have pre-enumerated fields. Git, for example, can be seen as IPLD, but only with some known fields.
Both of these are fine.
wrangling codecs
And so now we have the multicodec table.
It contains a lot of things.
And we're ready to move onto the Data Model.
https://github.com/multiformats/multicodec/blob/master/table.csv

-
MOTIVATIONS
-
THE STUFF
- The Codec Layer
- The Data Model
- The Schema Layer
-
WHERE TO NEXT?
the data model
- maps...
- lists...
- ints...
- strings...
- bools...
It's basically the JSON you know and love, but specified abstractly so we can use other representations too.
{
"hi": "hello",
"list": ["indeed"],
"ints": 42,
"strings": "so many",
"bools": true
}
the data model
- maps...
- lists...
- ints...
- strings...
- bools...
It's basically the JSON you know and love, but specified abstractly so we can use other representations too.
A5 # map(5)
62 # text(2)
6869 # "hi"
65 # text(5)
68656C6C6F # "hello"
64 # text(4)
6C697374 # "list"
81 # array(1)
66 # text(6)
696E64656 # "indeed"
64 # text(4)
696E7473 # "ints"
18 2A # uint(42)
67 # text(7)
737472696E6 # "strings"
67 # text(7)
736F206D616 # "so many"
65 # text(5)
626F6F6C73 # "bools"
F5 # true
the data model
A shared model of the data isn't just great for internal library abstractions (though it is!)...
You can choose one format for storage and internal use and canonical hashing (say, CBOR, because it's fast)...
And use still use something human-readable (like JSON) for display, web APIs, and other place binary doesn't go.
this was useful to unite the codecs
so, obviously,
...
what else?
unite the codecs
generic programming
foundation for schemas
generic programming
over the data model
generic
(adjective) Very comprehensive; pertaining or appropriate to large classes or their characteristics; -- opposed to specific.
(adjective -- computing, of program code) Written so as to operate on any data type
more runtime errors
more shared code
more compile time checks
hypergenericism
the 'Any' type
mechanisms for parameterized types
extremely verbose types everywhere
node
All of the Data Model kinds (map, list, int, str, etc) are a `Node`.
So a JSON document is just a Node tree.
(Including links, it's a Node Graph -- specifically, a DAG!)
... is hypergeneric
You can operate on Nodes by asking them what type they are at runtime.
This is a lot like the 'reflect' capabilities in strongly-typed programming languages you're already familiar with.
node
All of the Data Model kinds (map, list, int, str, etc) are a `Node`.
Nodes are immutable!
nodebuilder
Is the mutable counterpart for a Node.
Any Node can return a NodeBuilder which can build a new, similar Node in a copy-on-write fashion.
* these statements may vary based on your client library of choice. go-ipld-prime is based on these immutable/COW designs.
node is a simple interface
Kind() // returns 'map', 'list', 'int', etc TraverseField(key) // steps across a map TraverseIndex(idx) // steps across a list MapIterator() // iterates a map ListIterator() // iterates a list AsString() // unboxes native string (or errors) AsInt() // unboxes native int (or errors) AsBool() // unboxes native bool (or errors) AsBytes() // you get the idea AsLink() // returns a content-ID you can load..!
why bother with an interface?
- `Node` can be implemented by a fully parsed tree...
- `Node` can be implemented as a lazy-parsing generator doing just-in-time deserialization on large structures (!)...
- `Node` can be implemented on native types if you have a language with compile-time native types (we'll get to codegen options when we get to Schemas!)...
- `Node` can be implemented by Advanced Layouts (hold onto that thought for just one minute!)...
tl;dr: choose an in-memory working representation that's good to you.
traversals are generic
over node
We can make deep traversals generically.
Even works agross link boundaries!
func (p Progress) Traverse(
start Node,
pathSegments []string,
do func(
target Node,
p2 Progress,
),
)
traversals are generic
over node
Updates? Why not?
func (p Progress) Update(
start Node,
pathSegments []string,
doReplace func(
target Node,
p2 Progress,
) (replacement Node),
)
traversals are generic
Over node
(basically, we're saying you can build `jq` here... and it would work equally well over JSON, CBOR, or any other codec you can provide.)
{your ideas} are generic
Over node
What other generic algorithms would you like to write?
Graph transformers?
Toposorters?
Do it.
selectors
A query "language"?
Why not.
We built one that's actually an AST that's also represented in IPLD.
(You can bring your own DSLs.)
selectors
Bears some vague resemblance to GraphQL queries...
Is regular IPLD.
We're putting this in the core library so you can use it for more traversals!
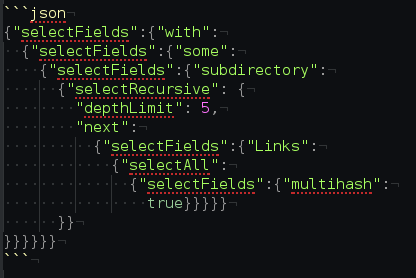

selectors <3 traversal
We can use these selectors to guide visits to subsections of a graph.
This is a useful building block for many other algorithms and applications.
func (p Progress) Walk(
start Node,
selector Selector,
atEach func(
target Node,
p2 Progress,
),
)
Replication
In IPFS, replicating IPLD objects over the network and between storage pools works totally generically.
Soon: using those generic selectors and traversals,
we can easily sync around graphs and subgraphs.
Say what you want with a selector: get it all in one stream, with minimum RTTs.
Neat!
-
MOTIVATIONS
-
THE STUFF
- The Codec Layer
- The Data Model -- There's more! ADVANCED LAYOUTS
- The Schema Layer
-
WHERE TO NEXT?
I want to shard things?
what if...
(remember how we said that Node interface was going to have another purpose?)
"advanced layouts"
act like one
Data model 'Kind'...
Imagine we want a map...
serialize as another.
But it's backed by a...
- B+ tree.
- Or HAMT (Hash Array Mapped Trie).
- Or... whatever.
It can even be several 'blocks', connected by Links...
"advanced layouts"
- Work for maps, lists, and bytes!
- Think of it like how Java has
`HashMap<K,V> implements Map<K,V>`...
except the parameters are all flipped:
we think of it like
`Map<K,V><HashMap>`. - You have to provide the code.
"advanced layouts"
-
You have to provide the code.
- Advanced Layouts operate via a plugin system.
- Serialized data can indicate it's using an Advanced Layout by signaling in-band (e.g. `"_adv":"HAMT"`),
or by using schemas (we'll cover that later).
wilder ideas
- Advanced Layouts were originally designed for sharding stuff...
- What if we used them for... encryption?
- ... What else?
use this sparingly
- Being able to do generic containers for large maps and lists and byte blobs is important...
- Using this kind of algorithmic plugin means all clients will need to have that plugin implemented in order to work with your data!
- So, it's our plan to ship a few "good" sharding algos in common libraries, and you can bring your own...
- But be conscious of what this will do to fragmentation!
-
MOTIVATIONS
-
THE STUFF
- The Codec Layer
- The Data Model
- The Schema Layer
-
WHERE TO NEXT?
building on the data model
schemas are just another (big) example of something that's "generic over the data model"
which is cool and wholesome
we want a
Type system
- hypergenericism is hard to reason about
- type systems are good
- structs are good
- unions are good
- let's have good things
- having a schema for validation of my data saves me oooooodles of time as a programmer!
and...
- documentation, documentation, documentation!
- facilitate design discussion
- must be language agnostic
we want a
Type system
and...
All of the existing systems are hard to apply here.
Immutable links are consequential.
We care about migration...
And we care about migration that works for decentralized protocols and distributed development practices.
(Which means strict version numbers are *out* -- requires central coordination.)
let's get specific
- kinds:
- map (now typed)
- list (now typed)
- string
- int
- (...all the same scalars from DM...)
- struct
- union
- enum
- types:
- When you assign a name to one of the above.
typed primitives
## MyString is a named type. type MyString string ## MyInt is another one. type MyInt int ## and so on
typed maps
type MyString string
## "String" is the key type;
## "MyString" is the value type.
type MyMap map {String:MyString}
## or inline in other things:
type MyStruct struct {
aField {String:MyString}
}
typed lists
- Bullet One
- Bullet Two
- Bullet Three
type MyString string
## Looks familiar already, right?
type MyList list [MyString]
## or inline in other things:
type MyStruct struct {
aField [MyString]
}
... plus 'nullable'
## Without the 'nullable' keyword, ## this list can *only* contain ## strings! type MyList list [String] ## This list can contain either ## a string or a 'null' at each ## entry in the list. type HoleyList list [nullable String]
'nullable' can be applied to map values,
list values, and struct fields.
structs
## Structs have a known set of fields.
type MyStruct struct {
x Int
y String
z nullable MyStruct
}
... plus 'optional'
'optional' is distinct from 'nullable'!
Means the field can be *missing* entirely.
'optional' only applies to struct fields.
## Structs have a known set of fields.
type MyStruct struct {
x Int
y optional nullable String
z optional MyStruct
}
cardinality
a quick word on...
| Schema | Valid Matching Representations | Cardinality |
|---|---|---|
| type Foo struct { bar Bool } |
{"bar": true} {"bar": false} |
2 |
| Schema | Valid Matching Representations | Cardinality |
|---|---|---|
| type Foo struct { bar Bool } |
{"bar": true} {"bar": false} |
2 |
| type Foo struct { bar nullable Bool } |
{"bar": true} {"bar": false} {"bar": null} |
3 = 2+1 |
| type Foo struct { bar optional Bool } |
{"bar": true} {"bar": false} {} |
3 = 2+1 |
| type Foo struct { bar optional nullable Bool } |
{"bar": true} {"bar": false} {"bar": null} {} |
4 (!) = 2+1+1 |
| type Foo struct { bar Bool (default "false") } |
{"bar": true} {} |
2 |
cardinality
a quick word on...
Cardinality-counting is an important design foundation.
If the cardinality of two parts of a model aren't the same, then that means one of them is less expressive.
Can use this to reason about compatibility and completeness of models!
... plus defaults
Defaults are a neat feature for reducing serialized verbosity... without changing cardinality.
(This means encountering the 'default' in the serial data is rejected...! Otherwise, the transform would be lossy!)
## 'defaults' can be used to elide
## common values when serializing;
## they *don't* change cardinality.
type MyStruct struct {
y Bool (default false)
z String (default "word")
}
... with representations
## Structs are represented as maps
## by default! So you dont need to
## say it.
type MyStruct struct {
x Int
y Bool
z String
} representation map
Everything we've seen so far has had an implicit "representation" -- instructions for how it maps onto the Data Model kinds.
... with representations
## This type will serialize as a list!
type MyStruct struct {
x Int
y Bool
z String
} representation tuple
We can customize these.
... with representations
## This will serialize as a STRING!
type MyStruct struct {
x String
y String
} representation stringjoin {
delim ":"
}
... And it can change the kind of representation entirely.
... with representations
## This will serialize as a STRING!
type MyStruct struct { ... }
representation stringjoin { ... }
## So this map can use it as a key...!
type WildMap map {MyStruct:Whatever}
This is an important feature:
with it, we can use structs as map keys, for example.
unions
Unions (also often known as "sum types") can contain data from any one of their member types...
but only one at a time.
type NeatUnion union {
| MemberTypeOne "one"
| MemberTypeTwo "two"
| MemberTypeThree "three"
} representation keyed
unions always must define a representation
- keyed
- envelope
- inline
- kinded
enums
type MyEnum enum {
| One "one"
| Two "two"
| Three "3"
}
let's talk about
representations
- Representations allow simple, deterministic, bi-directional transformations.
- These transformations take us between the
schema kind and the Data Model's kind.
- Most kinds have default representations...
- Some (namely, unions) don't, because there's no popular universal agreement about unions in contemporary design patterns.
back to "advanced layouts"
- Compared to Schema Representations:
- AdvLayouts allow arbitrary, turing-complete code. Representations don't, and are all fast.
- AdvLayouts can split data into more blocks; Representations can't.
- Representations are a must-have feature for an IPLD library that supports Schemas; AdvLayouts lean on out-of-band components.
- Representations correspondingly are strictly specified core specs; will be stable over time.
back to "advanced layouts"
- Schemas are another way to indicate their usage!
- Alternative to in-band signaling with magic keywords.
## This map will be sharded.
type MyMap map {String:MyString}<HAMT>
## Additional config here.
advanced HAMT {
implementation "experimental/HAMT/v1"
bitwidth 14
hashalgo "murmur"
}
back to "advanced layouts"
- Schemas are another way to indicate their usage!
- Alternative to in-band signaling with magic keywords.
- Unlocks a cool property....
You can choose whether or not you want to "see through" an advanced layout and address it's individual blocks, or not, by doing traversals with a schema that indicates it, or not.
Useful for "grab me the left-leaning tree"...
(This maps to "stream the beginning of a file"..!)
mi
gra
tions
migrations
- Core concept: "schema 'try stacks'"
- Try to fit the data to the first schema...
- if it fits, you're done
- Try to fit the data to the second schema...
- if it fits, you're done
- Continue like so...
Gives us the ability to do "structural typing" -- it detects matching data, without the use of explicit version numbers!
Where to next?
we're doing development in the open.
- A lot of the stuff discussed here is recent.
- We're still firming up and ratifying lots of the details when it comes to Advanced Layouts and Schemas especially.
- Come join the discussion!
More
Language
implementations
- go-ipld
- js-ipld
- java-ipld?
- rust-ipld?
- haskell-ipld?
- ocaml-of-ipld?
Many community implementations already exist; more are wanted!
More
Advanced
Layouts
Advanced layouts are a recent feature; many explorations required!
More
code
generation
Codegen is a recent feature in go-ipld.
Other languages could benefit from similar categories of tooling!
More
cool
applications!
What can you dream of building with a decentralized protocol-building toolkit?
contributing!
and keeping in touch
ipld on github
Especially the `specs` repo!

ipld on irc
freenode: #ipld
or just me
twitter: @warpfork
github: warpfork
etc: probably warpfork
sometimes responds to 'eric' when shouted
A snaazy website!
https://ipld.io/
Thank you!
https://github.com/ipld/
https://ipld.io/
comparisons
- Bazaar, not Cathedral. Fork-only protocols are bad.
- a matter of 'tendencies', but... some things sure tend
- looking at you, Protobufs
- Format agnostic. The three-layer model is neat.
- looking at you, literally everything else
- Migrations *and* clarity, not migrations *or* clarity.
- looking at you, Protobufs
- First class immutable links.
- looking at you, literally everything else
- Symmetric protocols: neither client nor server is special.
- looking at you, GraphQL
Foundations for Decentralization: Data with IPLD
By warpfork
Foundations for Decentralization: Data with IPLD
Intro to IPLD talk, with focus on how IPLD is decentralization-friendly, for GPN'19.




