Speech Project
Week 17 Report
b02901085 徐瑞陽
b02901054 方為
Task 5:
Aspect Based Sentiment Analysis (ABSA)
We focus on slots 1 and 3 of subtask 1 first
Subtask 1: Sentence-level ABSA
Given a review text about a target entity (laptop, restaurant, etc.),
identify the following information:
-
Slot 1: Aspect Category
- ex. ''It is extremely portable and easily connects to WIFI at the library and elsewhere''
----->{LAPTOP#PORTABILITY}, {LAPTOP#CONNECTIVITY}
- ex. ''It is extremely portable and easily connects to WIFI at the library and elsewhere''
-
Slot 2: Opinion Target Expression (OTE)
- an expression used in the given text to refer to the reviewed E#A
- ex. ''The fajitas were delicious, but expensive''
----->{FOOD#QUALITY, “fajitas”}, {FOOD#PRICES, “fajitas”}
-
Slot 3: Sentiment Polarity
- label: (positive, negative, or neutral)
Slot1 : Aspect Detection
Subtask1: Sentence-level
Slot1 : Aspect Detection
bag of word : 62 %
glove vector : 61 %
bag of word + glove vector : 64 %
Restaurant
bag of word : 48 %
glove vector : 42%
bag of word + glove vector : 47 %
Laptop
Linear SVM
Slot1 : Aspect Detection
bag of word : %
glove vector : 61 %
bag of word + glove vector : 64 %
Restaurant
bag of word : %
glove vector : %
bag of word + glove vector : %
Laptop
RBF SVM
Experiment in Slot1 (Cross Validation)
Without LSI :
- With Tf-Idf indexing
restaurant : 61% (12 category)
laptop : 52% (81 category)
- Without Tf-Idf indexing
restaurant : 60% (12 category)
laptop : 50.05% (81 category)
Experiment in Slot1 (Cross Validation)
With LSI : (reduce dimension to 1000)
restaurant : 60% (12 category)
laptop : 52% (81 category)
Need more time...
Seems no improvement ,
but the 1000 dimension seems preserve the essential info
Experiment in Slot1 (Cross Validation)
Bigram
| 9000/? (origin size) |
3000 (unigram size) |
|
|---|---|---|
| restaurant | 61% | 61% |
| laptop | 51% | 51% |
seems high input dimension is not a problem :p
| 15k/17k (origin size) |
3000 (unigram size) |
|
|---|---|---|
| restaurant | 61% | |
| laptop | 51% |
Trigram
Experiment in Slot1 (Visualization of LSI)
Experiment in Slot1 (Visualization of LSI)
Experiment in Slot1 (Visualization of LSI)
Nothing special :p
Experiment in Slot1 (unsupervised LDA)
Experiment in Slot1 (supervised LDA)
Experiment in Slot1 (Summary)
Two kinds of classifier
- discriminative model :
- generative model :
something like dimensionality reduction
use sample to classify directly
use sample to guess hidden model's param <learn a model>
use these models to predict unseen sample <classify>
Slot3 : Polarity Detection
Subtask1: Sentence-level
Slot3 :
Polarity Detection
| Restaurant | Laptop | |
|---|---|---|
| Model | 3-class accuracy | 3-class accuracy |
| TreeLSTM | 71.23% | 74.93% |
| Sentinue (SemEval 2015 best) | 78.69% | 79.34% |
- Small Experiment: predict by training a TreeLSTM model
Seems like we're on the right track...
removed conflicting labels for different aspects in a sentence
accuracy tested on dev set of training data where conflicting labels are removed, so it cannot completely reflect real acc.
Slot3 : Polarity Identification
Proposed Model
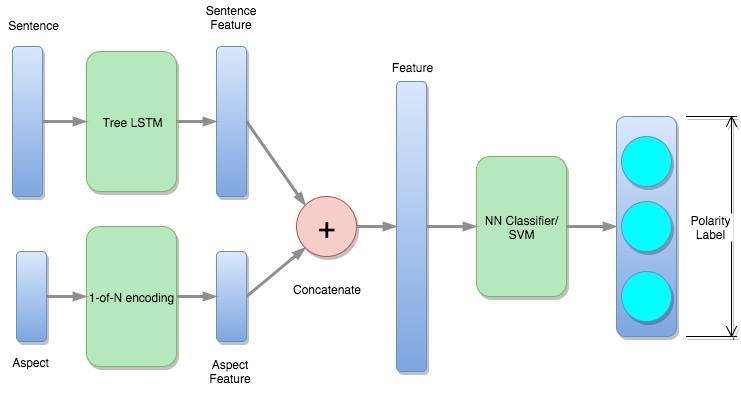
Slot3 :
Polarity Detection
- Predict by training the proposed model
- Details:
- Word embedding: GloVe vectors
- Target: 5 classes
- structure: dependency tree
- learning rate: 0.005; embedding learning rate: 0.1
- dropout: 0.5; activation: tanh
- restaurant: 2 layers, 300 hidden
- laptop: 3 layers, 300 hidden
- sentence Features obtain from last layer of TreeLSTM
- Stage 1: TreeLSTM
- when training TreeLSTM, conflicting labels for different aspects in a sentence are removed
- To extract sentence features for next stage
Slot3 :
Polarity Detection
- Details:
- Target: 3 classes
- learning rate: 0.0001
- dropout: 0.3
- 3 layers, 256 hidden
- activation: relu
- Experimented with NN, will try SVM in the future
- Stage 2: Classifier
- conflicting labels can be trained in this stage
Slot3 :
Polarity Detection
| Restaurant | Laptop | |
|---|---|---|
| Model | 3-class accuracy | 3-class accuracy |
| Our model | 83% | 84.5% |
| Sentinue (SemEval 2015 best) | 78.69% | 79.34% |
Note: accuracy obtained through cross-validation
Results
Exciting results!!! Though we have yet to check whether the data for this year and last year are the same
Future Work
Before submission deadline (1/31)
Slot 1: Aspect Detection
Subtask 1: Sentence-level
Slot 2: OTE detection
Structured Learning
Subtask 1: Sentence-level
Slot 3: Polarity Detection
- SVM in stage 2
- Label internal nodes when training stage 1 TreeLSTM
- Use other resources
- Write our own TreeLSTM so our model can be trained end-to-end (if time permits...)
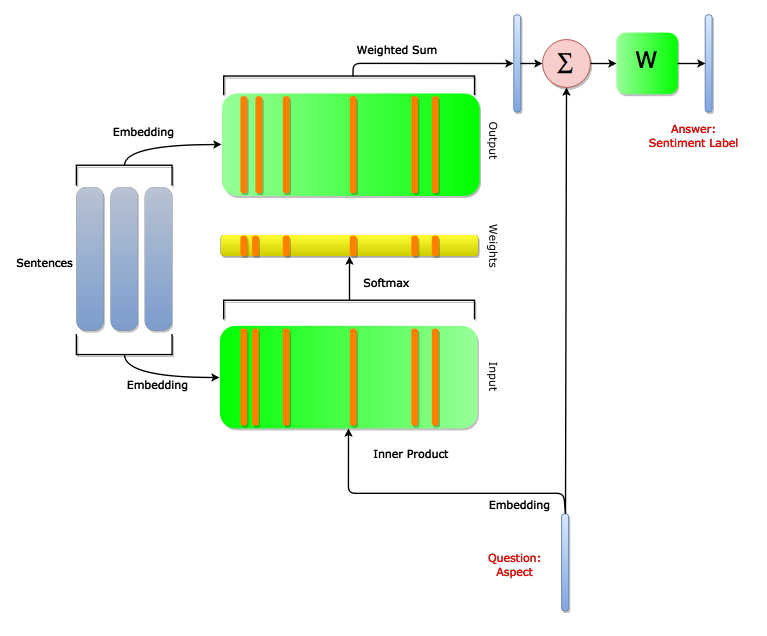
- QA memory network (if time permits...)
Subtask 1: Sentence-level
sentence
\rightarrow
Subtask1-slot1 SVM
See if sentence contains aspect
\rightarrow
\rightarrow
if yes
predict polarity by Subtask1-slot3 model
For each sentence:
Finally, combine all aspect and polarity pairs
Subtask 2: Text-level
Subtask 3: Out-of-domain
Copy of SpeechProject-week17
By Wei Fang




