검색엔진의 기본
검색팀 송원석
YSM 사내 교육자료

검색엔진이란?
사용자의 검색요구를 받아들이고 색인 내에 있는 내용과 비교한뒤 검색 결과를 돌려 주는 프로그램
출처 : 텀즈
그냥 간단히 검색하면
"빠르게" 나와야한다.
?어떻게?

일반 RDB index 구조
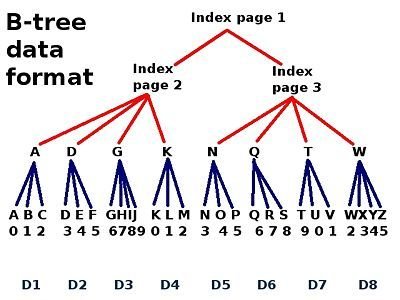
-
긴 텍스트를 처리하기 적합하지 않음
-
BTREE는 시작부분부터
검색해야 좋은 속도가 나옴
-
검색엔진은 TERM(Tokenizer)
단위로 인덱스를 생성
검색엔진은 문서를 효율적으로 색인하기위한 다양한 tokenizer제공
형태소란?
의미가 있는 단어만
색인한다
아버지가방에들어가신다

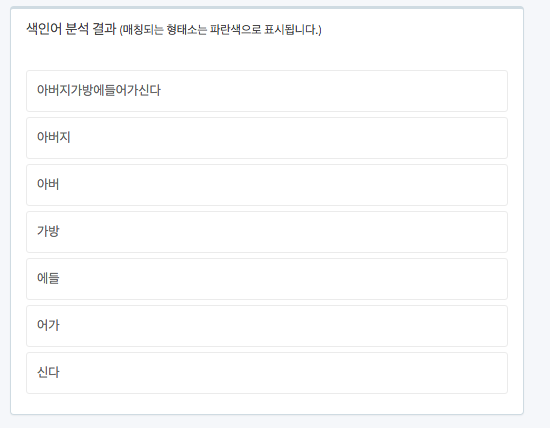
갈길이 아직 많이 남았습니다
- 안녕
- 안녕하세요
- 안녕하십니까
- 안녕하시렵니까
- 안녕하신가요
- 안녕할까요
- 안녕하다
명사를 제외한 형용사 부사등의
꾸밈단어를 제거하고 색인
@#$%^&*() 같은 특수기호도 모두 제외하고 색인
각종 검색엔진들은
형태소를 정확히
분해하기 위해
여러 설정값을 제공
Lucene arirang 형태소사전
-
total.dic
- 사전의 형식
예) 납부, 10011X
콤마를 중심으로 좌측은 단어, 우측은 단어정보임.
- 단어정보 사용규칙
단어정보는 여섯글자로 이루어지고 순서에 따른 내용은 다음과 같음.
1-명사 2-동사 3-기타품사 4-하여동사 5-되어동사 6-불규칙변형
- 불규칙 변형의 종류
-
extension.dic - 사전을 보완해야 할 경우 추가 단어 등록을 위해 사용되는 확장사전
-
josa.dic - 조사 모음.
-
eomi.dic - 어미 모음.
-
prefix.dic - 복합명사 분해 시 사용할 접두어 모음. "과소비"의 경우 "과"를 접두어로 분리해 "과소비" 와 "소비"를 색인어로 추출
-
suffix.dic - 복합명사 분해 시 사용할 접미어 모음. "현관문"의 경우 "문"을 접미어로 분해해 "현관문"과 "현관"을 색인어로 추출
-
compounds.dic - 최장일치법에 의해 분해가 불가능한 복합명사를 등록하기 위한 사전
(예- “근로자의날:근로자,날”)
Elastic 은전한닢 형태소 태그목록
사전이란?
언어의 변형으로 새롭게 탄생한 단어
김천 (약어)
냉장고바지 (합성어)
곰탕 (신조어는 아니지만)
EDM = Electronic Dance Music(약어)
극혐, 닉언죄 (인터넷 유행어 + 약어)
indexer는 기존 단어분석보다 우선하여
신조어 형태소 분석을 처리
사전적으로 의미가 같은 단어
남자 = 남성 (의미적)
가방 = 백 (외래어)
티비 = TV (외래어)
노페 = 노스페이스 (약어)
Query에서는 OR조건 처리
('남성' OR '남자')
19금 단어나 나오지 말아야 될 상품에 사용
해당 TERM에 대해서 색인을 하지 않음
("성인" 불용어 등록시 "성인가요"는 "가요" 만 색인)
해당 TERM을 REPLACE 해서 검색
(원본 텍스트를 검색X)



색인
무엇을 색인하나?
- DATABASE
- HTML
- CSV, DOC, PDF, EXCEL
- 텍스트가 있는 모든것
색인의 종류
| 전체(bulk)색인 | - 모든 데이터를 전부 색인하고 색인볼륨을 변경하는 방식 - 많은 소요시간. 많은 부하 |
|---|---|
| 증분(delta)색인 | - 데이터가 변경된 부분만 색인하여 원래 볼륨에 추가하는 방식 - 데이터의 변경분만 체크할 수 있는 데이터 구조 설계 필요 - 추가된 데이터 뿐만 아니라 삭제분에 대한 처리도 고려 |
-
검색엔진은 Large Data처리. 데이터 최적화 필수. 색인사이즈를 최대한 작게 만들어야 이득 (ex : indexed=false, stored=false, type=string)
- 색인 및 검색에 걸리는 부하 때문에 GC 튜닝 필수 (쿠차 solr는 G1GC 적용으로 stop the world최소화)
- 캐시를 적절하게 사용
- 충분한 BMT테스트 후 서버 적용
주의사항
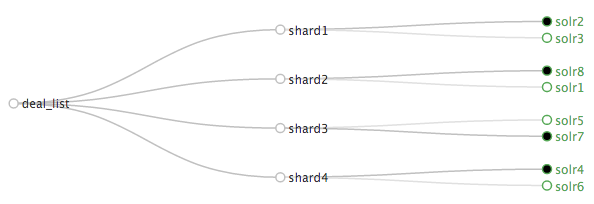
Shading
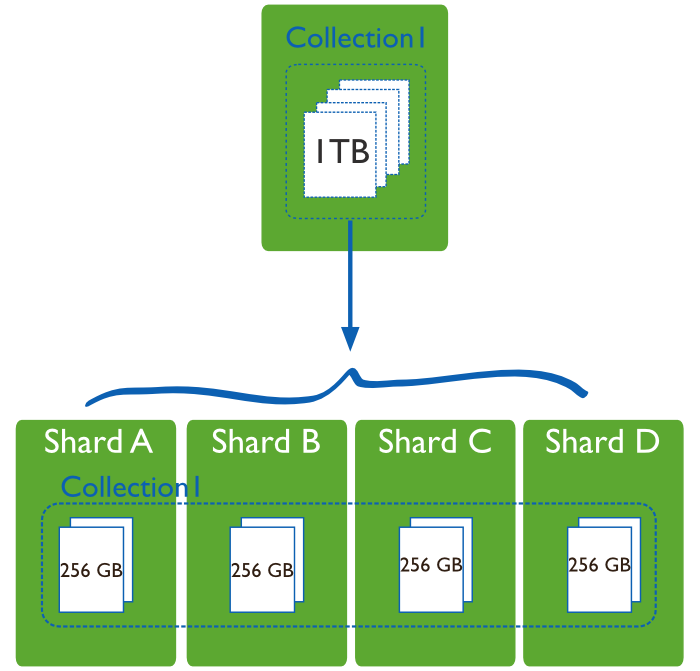
Shading 문제점
- 각 서버당 호출. 네트워크 트래픽UP(모든 서버에 request)
- 한 서버가 죽으면 그 서버의 데이터 서비스 못함
- 한 서버라도 느려지면 다같이 느려짐!
- 데이터가 어느 서버에 있는지 찾아야함!
replication
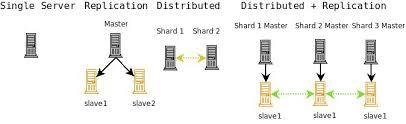
replication 문제점
- 스토리지 낭비! (서버마다 데이터가 필요)
- 데이터를 복제하는데 시간 및 부하 소요
그래서?

적절히 섞어씀
Scoring
검색되는것도 중요하지만
어떤 문서가 상단에
노출되는지도 매우 중요하다
어떤 문서가 과연 사용자가 원하는 문서일까?
BM25

Lucene Similarity
| TF(term frequency) | 한 문서에서 같은 검색어(term)가 많이 나타날수록 높은 점수를 부여 |
| IDF(inverse document frequency) | 많은 문서에서 공통으로 출현하는 term일수록 낮은 점수를 부여 |
| coord(coordination factor) | 검색질의가 여러개의 term으로 이루어졌을 경우 문서에서 매치되는 term갯수가 많을수록 높은 점수 부여 |
| lengthNorm | term이 크기가 작은 필드에서 출현할 수록 높은 점수 부여 |
| index-time boost | 색인시 특정 문서에 가중치를 적용했을 경우 |
| query clause boost | 검색시 특정 검색어에 가중치를 적용했을 경우 |
해당 수치는 solr debug에서 확인 가능
"debug": {
"rawquerystring": "dealname:라면",
"querystring": "dealname:라면",
"parsedquery": "dealname:라면",
"parsedquery_toString": "dealname:라면",
"explain": {
"5625843": "\n4.4504166 = (MATCH) weight(dealname:라면 in 561088) [DefaultSimilarity], result of:\n 4.4504166 = fieldWeight in 561088, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.5 = fieldNorm(doc=561088)\n",
"6248703": "\n4.72038 = (MATCH) weight(dealname:라면 in 568727) [DefaultSimilarity], result of:\n 4.72038 = fieldWeight in 568727, product of:\n 1.4142135 = tf(freq=2.0), with freq of:\n 2.0 = termFreq=2.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.375 = fieldNorm(doc=568727)\n",
"14044929": "\n4.4504166 = (MATCH) weight(dealname:라면 in 83267) [DefaultSimilarity], result of:\n 4.4504166 = fieldWeight in 83267, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.5 = fieldNorm(doc=83267)\n",
"14071124": "\n4.4504166 = (MATCH) weight(dealname:라면 in 81939) [DefaultSimilarity], result of:\n 4.4504166 = fieldWeight in 81939, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.5 = fieldNorm(doc=81939)\n",
"14126350": "\n4.4504166 = (MATCH) weight(dealname:라면 in 64613) [DefaultSimilarity], result of:\n 4.4504166 = fieldWeight in 64613, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.5 = fieldNorm(doc=64613)\n",
"14219326": "\n4.4504166 = (MATCH) weight(dealname:라면 in 7463) [DefaultSimilarity], result of:\n 4.4504166 = fieldWeight in 7463, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.5 = fieldNorm(doc=7463)\n",
"16909636": "\n5.5071096 = (MATCH) weight(dealname:라면 in 72164) [DefaultSimilarity], result of:\n 5.5071096 = fieldWeight in 72164, product of:\n 1.4142135 = tf(freq=2.0), with freq of:\n 2.0 = termFreq=2.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.4375 = fieldNorm(doc=72164)\n",
"18559950": "\n4.4504166 = (MATCH) weight(dealname:라면 in 11059) [DefaultSimilarity], result of:\n 4.4504166 = fieldWeight in 11059, product of:\n 1.0 = tf(freq=1.0), with freq of:\n 1.0 = termFreq=1.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.5 = fieldNorm(doc=11059)\n",
"20439049": "\n4.72038 = (MATCH) weight(dealname:라면 in 26163) [DefaultSimilarity], result of:\n 4.72038 = fieldWeight in 26163, product of:\n 1.4142135 = tf(freq=2.0), with freq of:\n 2.0 = termFreq=2.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.375 = fieldNorm(doc=26163)\n",
"20601084": "\n4.72038 = (MATCH) weight(dealname:라면 in 36798) [DefaultSimilarity], result of:\n 4.72038 = fieldWeight in 36798, product of:\n 1.4142135 = tf(freq=2.0), with freq of:\n 2.0 = termFreq=2.0\n 8.900833 = idf(docFreq=886, maxDocs=2394484)\n 0.375 = fieldNorm(doc=36798)\n"
}사이트 특성과 데이터의
특성을 많이 타기 때문에
매우 꾸준한
튜닝 및 커스터마이징 필요

Q&A

다음주제선정
- Basic of Javascript
- Expert Eclipse IDE
- Apache Zeppelin
- Spring WebSocket
검색엔진의 기본
By wonseok
검색엔진의 기본
내부발표자료_2015.11.19



