Writing a Generalized concurrent Queue
Choi Wonseok
2013-06-04
WAT?

CASE
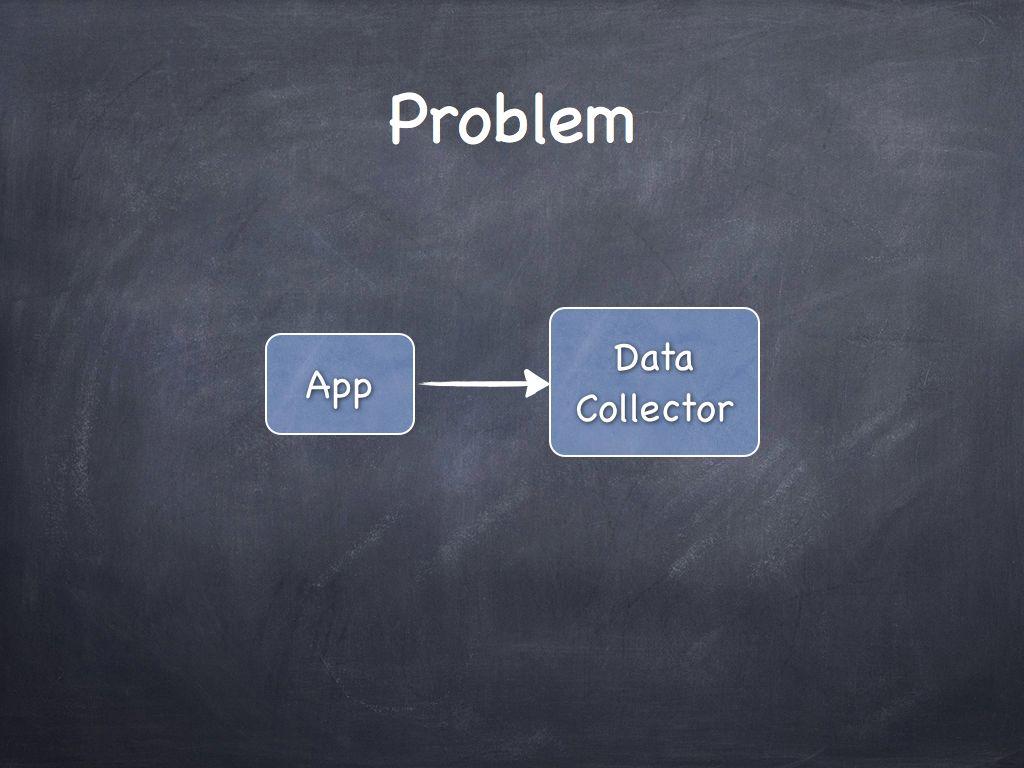
CASE
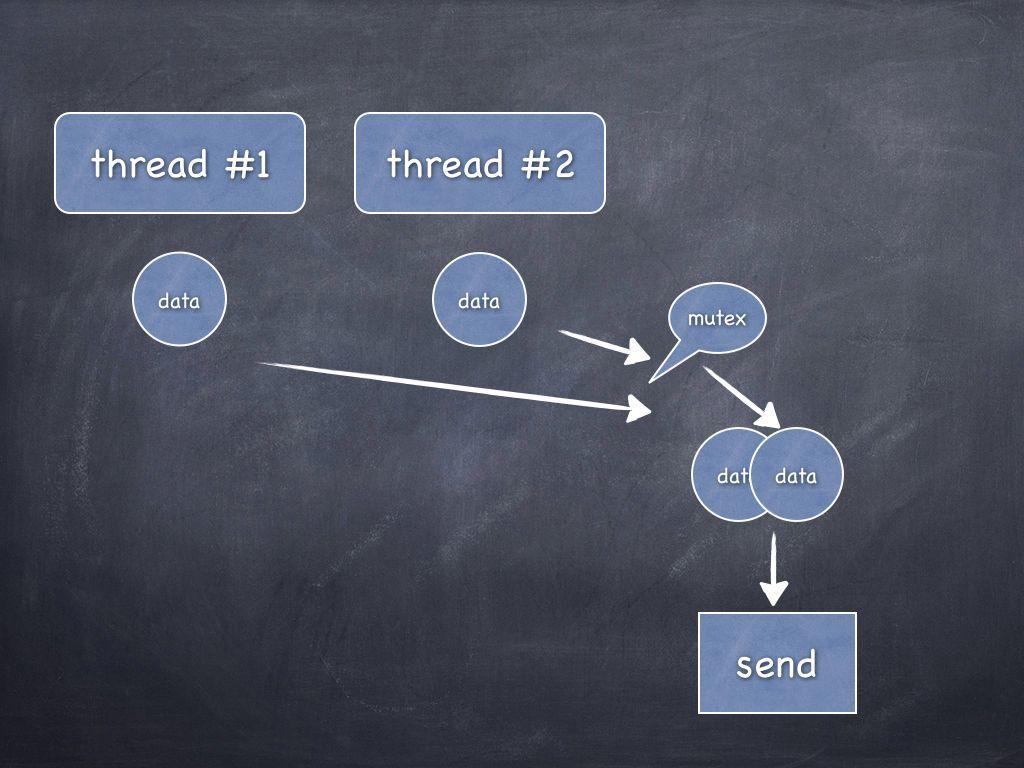
case
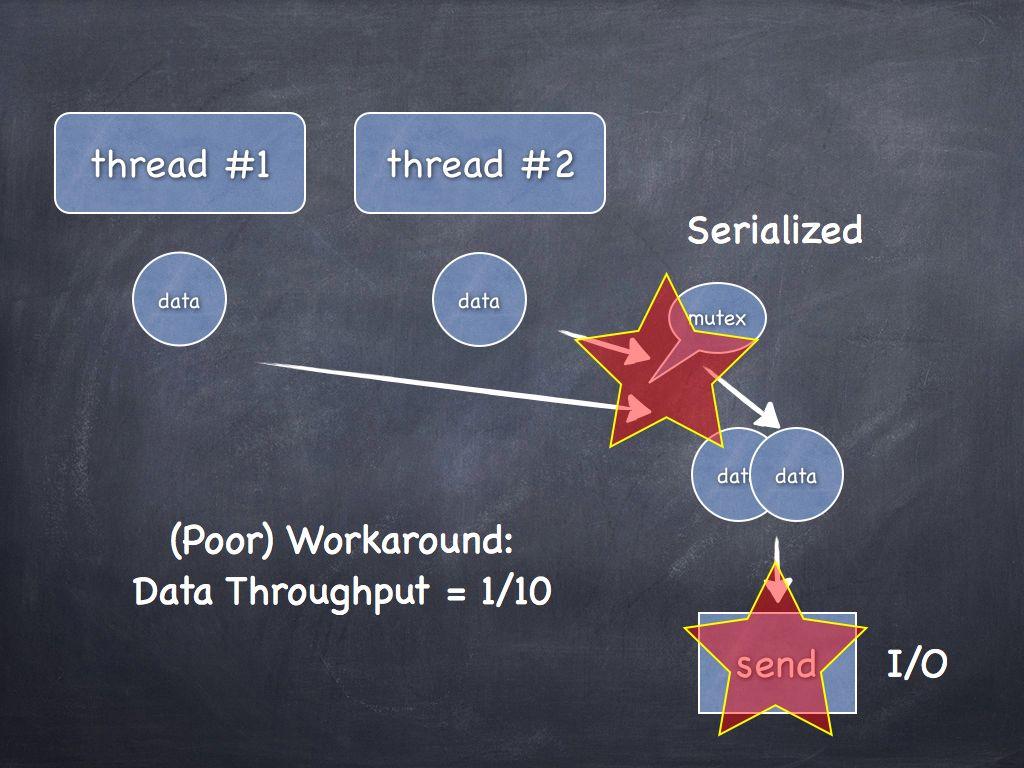
CASE
How CPUs Works
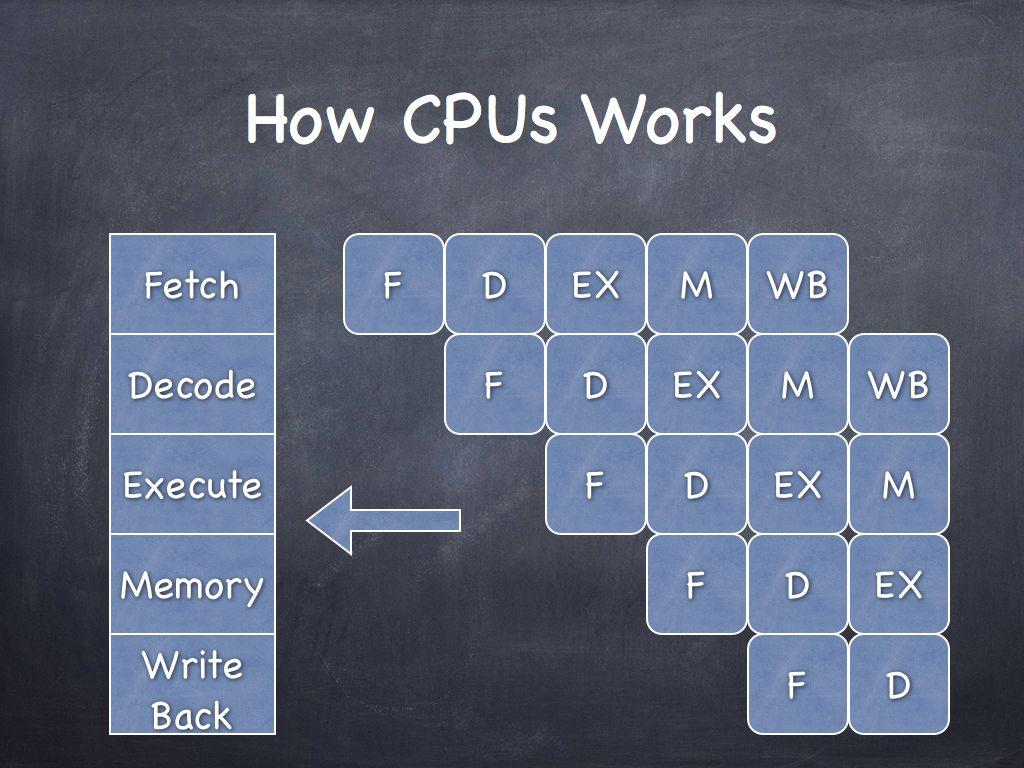
How cpus works

How CPUs Works

How CPUS WORKS
out of Order
Execution
HOW CPUs works
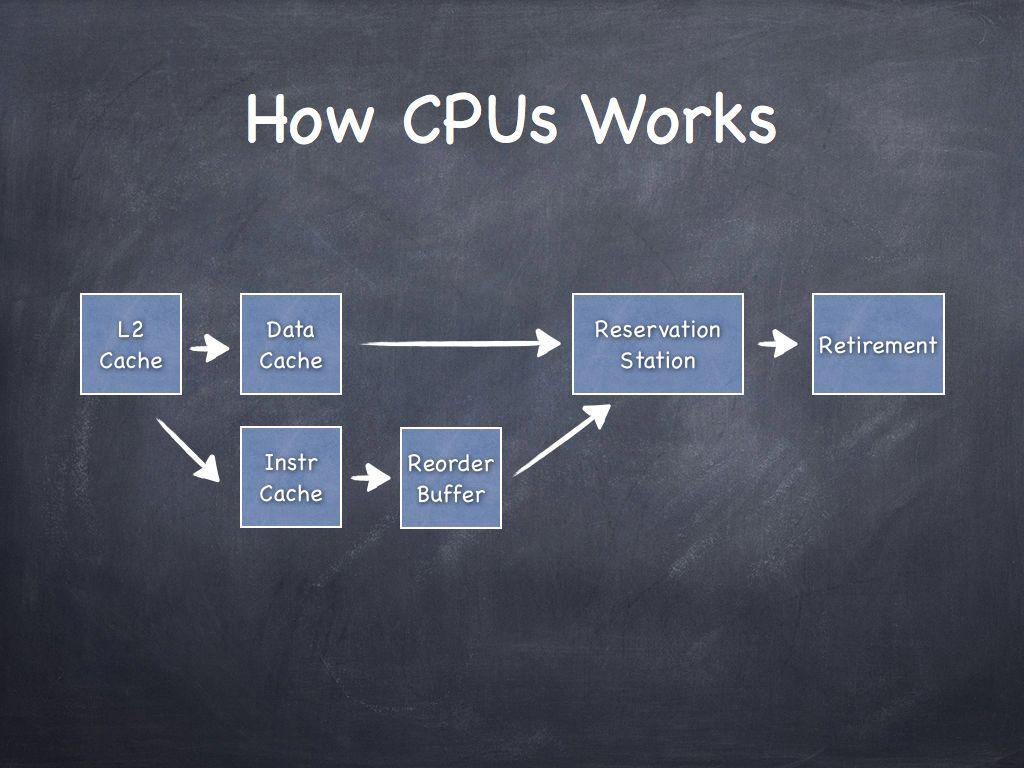
Memory ordering
It is a type of out-of-order execution.
Loads can be reordered after Loads.
Loads can be reordered after Stores.
Stores can be reordered after Stores.
Stores can be reordered after Loads.
Memory barrier
To enforce correct memory ordering
inline assembly directives
asm volatile("lwsync" ::: "memory")Win32 interlocked operation
C++11 atomic types (with memory model)
POSIX mutexes
Understanding atomic operation
void NonAtomicAND(tS32 *Value, tS32 Op){*Value &= Op;}
translates to this on x86
mov eax, dword ptr [Value]mov ecx, dword ptr [eax]and ecx, dword ptr [Op]mov dword ptr [eax], ecx
CAS
Compares a memory location with a given value,
and if they are the same
the new value is set.
On x86,
the lock instruction prefix makes some instructions
atomics.
CAS
void AtomicAND(volatile tS32* Value, tS32 Op){while (1) {const tS32 OldValue = *Value;const tS32 NewValue = OldValue & Op;// If the result is the original value, the new value was// stored.if (CAS(Value, NewValue, OldValue) == OldValue) {return;}}}
false sharing

silently degrade performance and scalability
false sharing

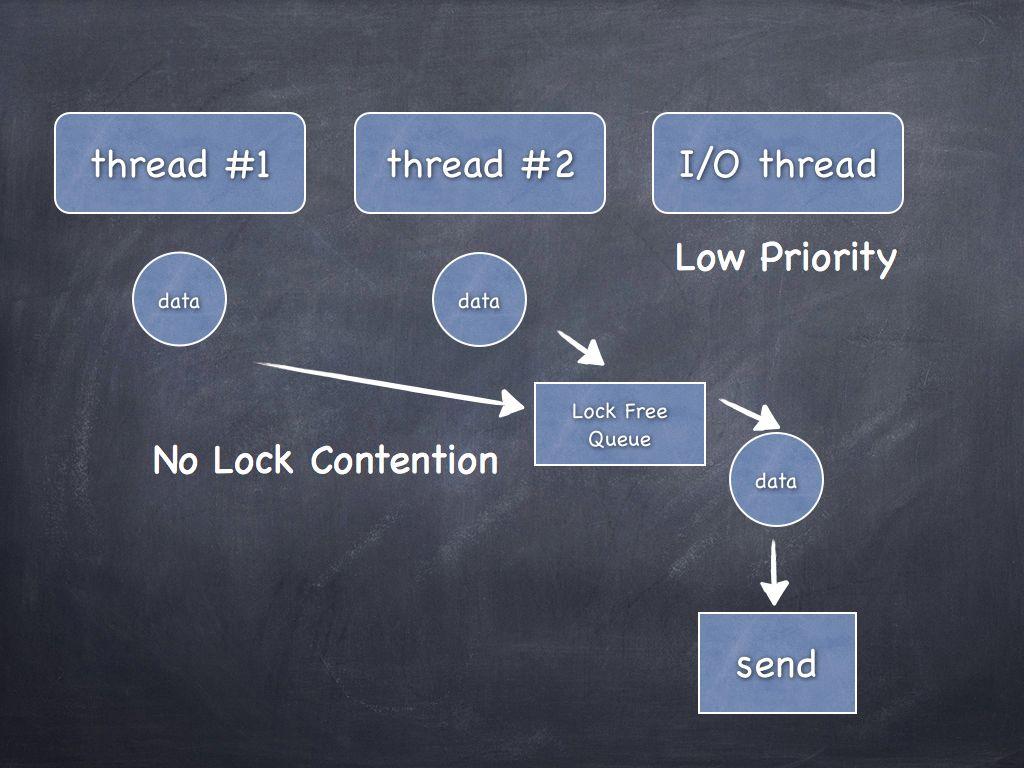
Queue

Dummy Node
QUEUE

QUEUE
Add padding to make sure hat data used by different threads stay physically separate in memory and cache...
Avoid False Sharing!
Node* volatile first_;
uint8_t pad6[MQ_CACHE_LINE_SIZE - sizeof(first_)];
volatile unsigned int receiveLock_;
uint8_t pad7[MQ_CACHE_LINE_SIZE - sizeof(receiveLock_)];
Node* volatile last_;
uint8_t pad8[MQ_CACHE_LINE_SIZE - sizeof(last_)];
volatile unsigned int sendLock_;
uint8_t pad9[MQ_CACHE_LINE_SIZE - sizeof(sendLock_)];Queue
Macros
#include <x86/smpxchg.h>
#define MQ_CAS_LOCK(x) do {} while (_smp_cmpxchg(&(x), 0, 1) == 1)
#define MQ_CAS_UNLOCK(x) do {_smp_cmpxchg(&(x), 1, 0);} while (0)// Assumption:
// - 32bit pointer and 32bit integer operation is atomic.
// - cache line size is 64 bytes.
// Consider using std::atomic (e.g., std::atomic<Node*> ...).
// On Linux, you can check cache line size:
// /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
//
#define MQ_CACHE_LINE_SIZE 64QUEUe
Produde
void Send(const T& t)
{
Node* tmp = new Node(new T(t));
MQ_CAS_LOCK(sendLock_);
last_->next_ = tmp; // publish to consumers
last_ = tmp; // swing last forward
MQ_CAS_UNLOCK(sendLock_);
return;
}QUEUE
Consume
bool Receive(T& data) { MQ_CAS_LOCK(receiveLock_); Node* first = first_; Node* next = first_->next_; if (next != NULL) { // if queue is nonempty T* val = next->value_; // take it out next->value_ = NULL; // of the Node first_ = next; // swing first forward MQ_CAS_UNLOCK(receiveLock_); data = *val; // now copy it back delete val; // clean up the value delete first; // and the old dummy return true; // and report success } MQ_CAS_UNLOCK(receiveLock_); return false; // report queue was empty}
references
Writing a Generalized concurrent Queue
By Won Seok Choi
