Tim Sherratt PRO
Historian and hacker. All the slide decks available here are licensed under a Creative Commons Attribution 4.0 International License. Fee free to reuse and share!
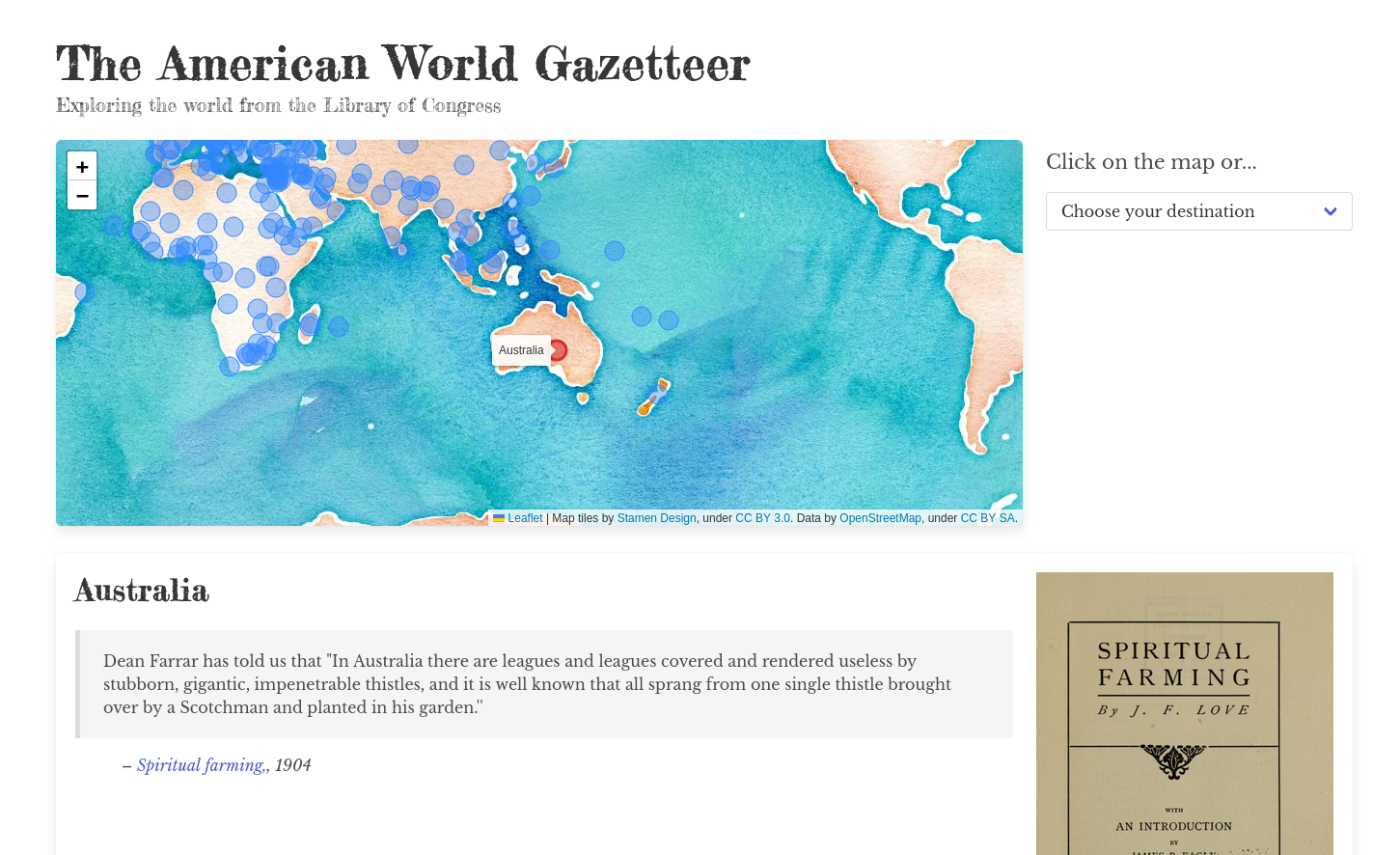
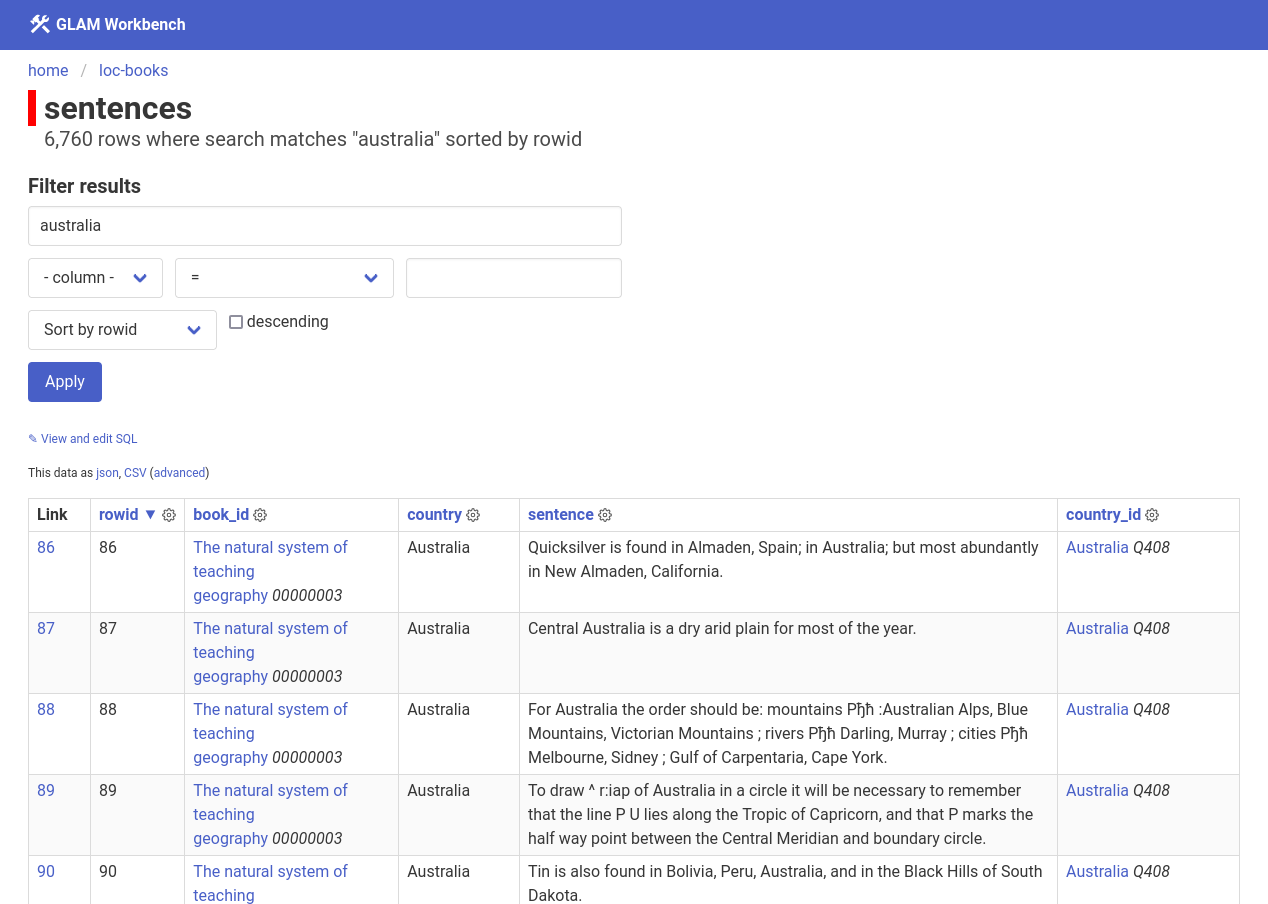
or too much text, too little time...
Tim Sherratt · @wragge
By Tim Sherratt




