




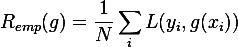

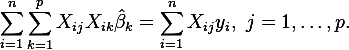





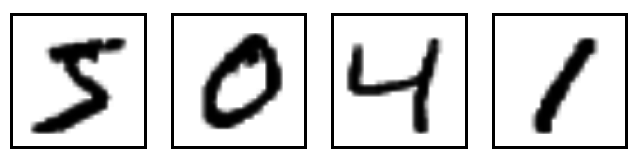

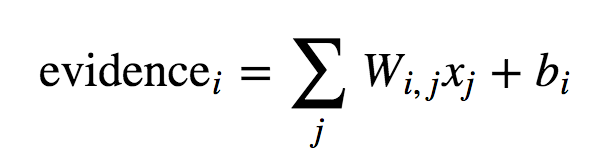
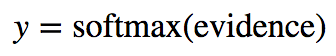
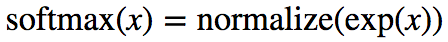
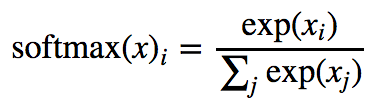
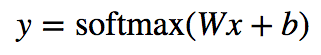
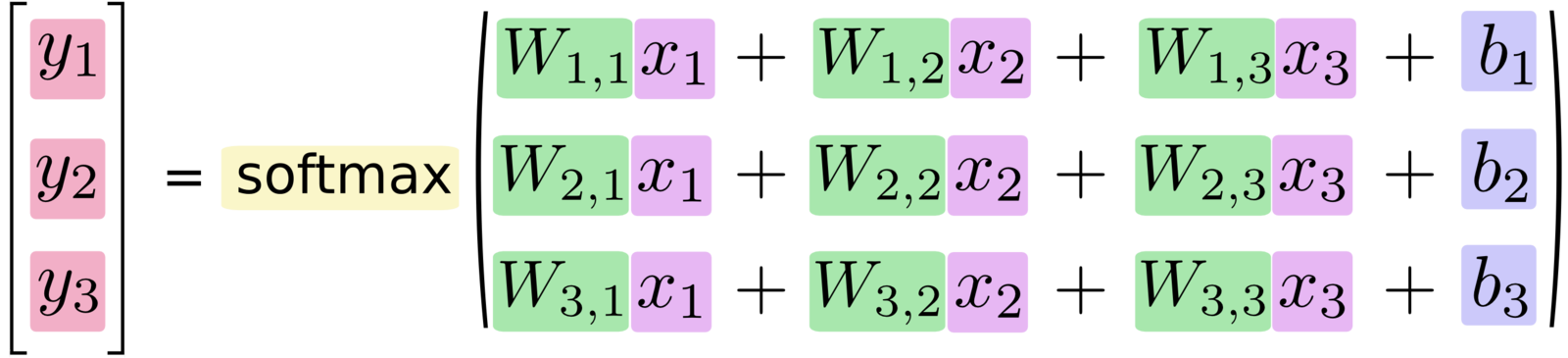
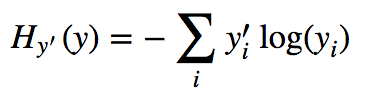
Moisés Gabriel Cachay Tello
Creator, destructor.
(y un poquito de TensorFlow)
Un campo de estudio con el propósito de crear sistemas capaces de realizar tareas
¡Sin programarlos para hacerlas!
(explícitamente)
En ML, el sistema aprende cosas sobre la información que recibe.
Como producto de este proceso de aprendizaje, el sistema logra crear relaciones entre la información recibida.
Sabiendo cómo se relaciona la información recibida, se puede realizar un sinnúmero de tareas.
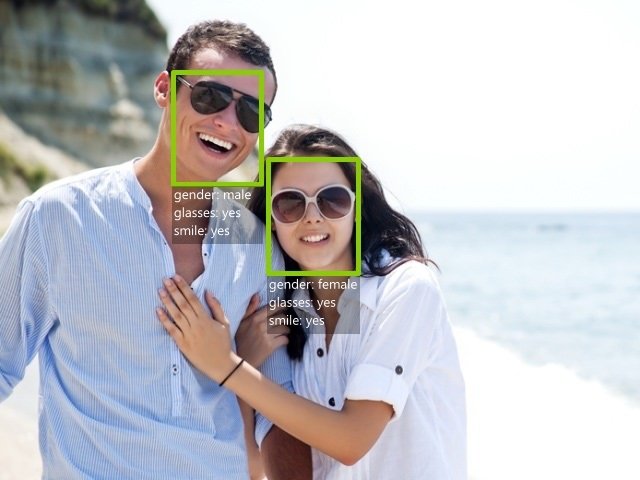
Face Recognition:
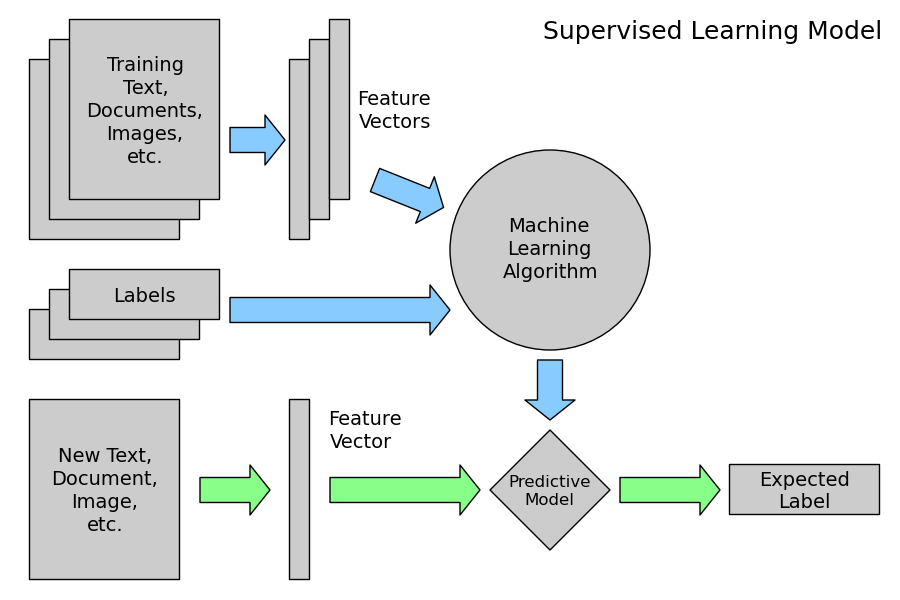
Entrenamiento Supervisado
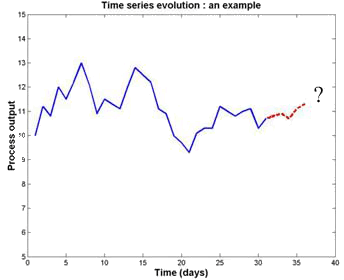
Interpolación o Estimación de resultados:
Aprendizaje supervisado
Machine Translation:
Aprendizaje semi-supervisado
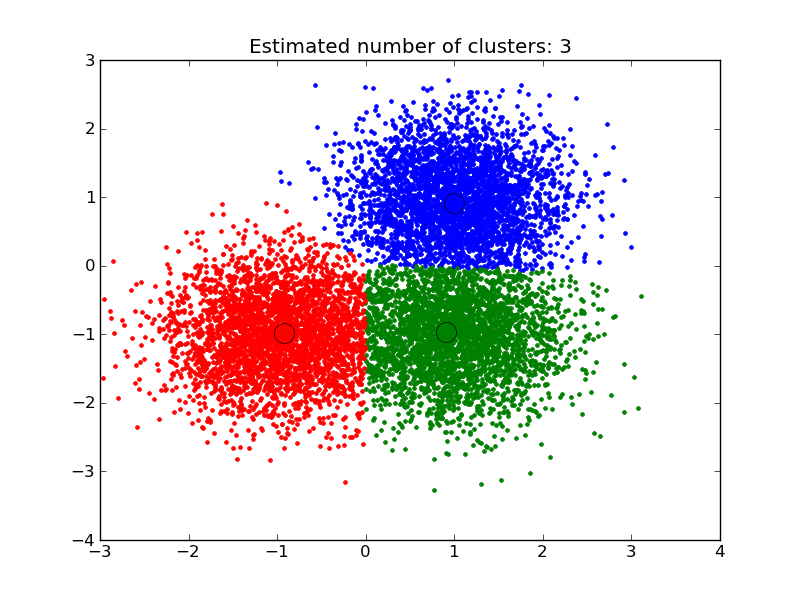
Clustering (Categorización):
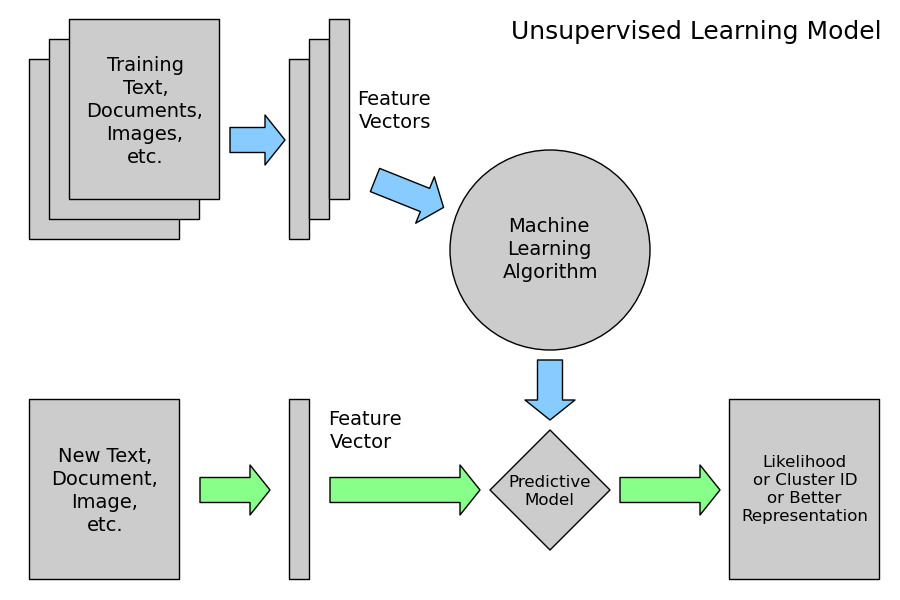
Aprendizaje sin supervisión.
Estadística inferencial
Minería de datos
Optimización Matemática
Algoritmos genéticos
etc...
Neural Network
(aprendizaje sin supervisión)
Google's Deep Dream:
Aprendizaje semi-supervisado
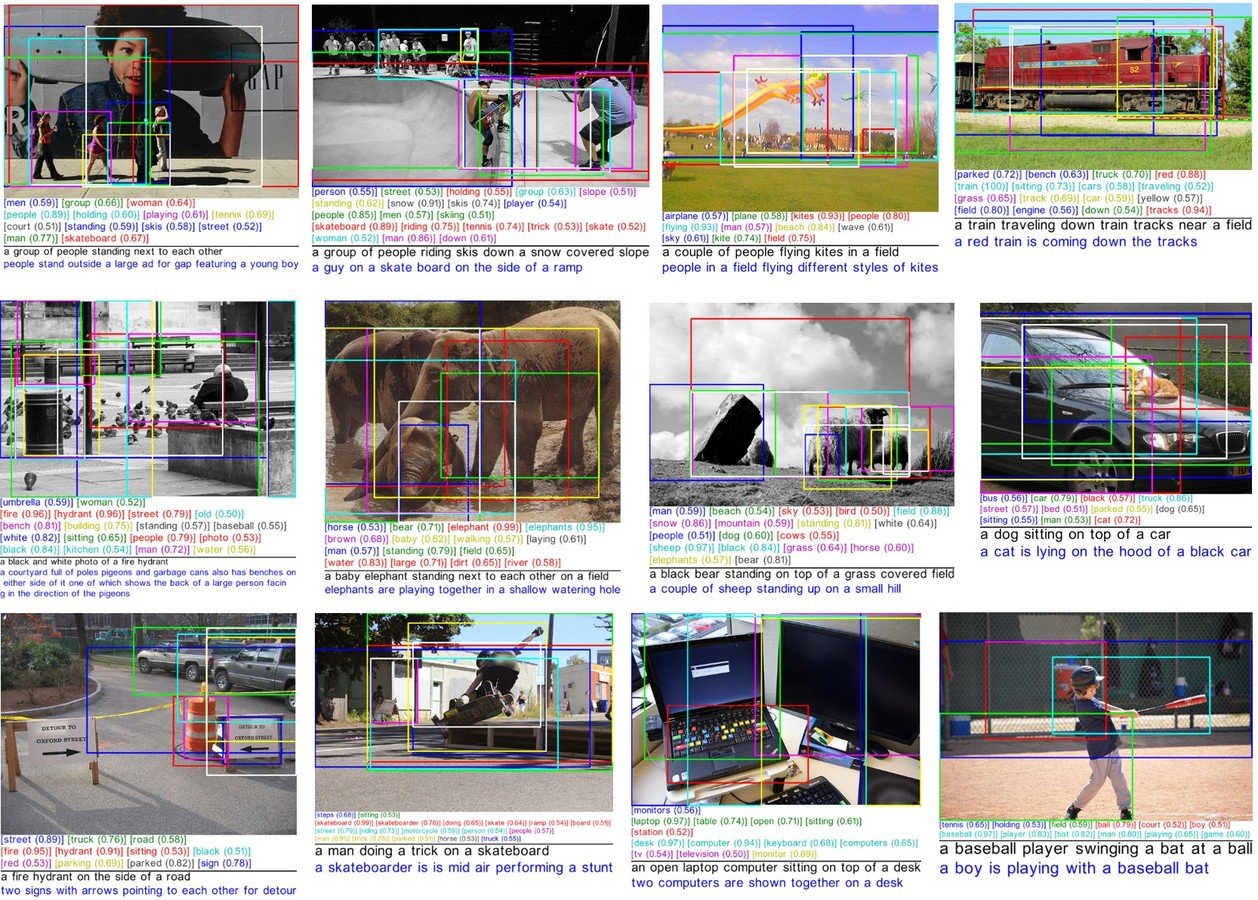
Automatic Image Captioning:
Object recognition
+ Object Classification
+ NLP Sentence Generation
Sentiment Analysis
Image Poetry Generator
Music Generation via RNN
(link externo)
?
Python +:
Cada una de ellas tiene un propósito en particular, y pueden usarse complementándose.
import numpy as np
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
clf.fit(X, Y)
print(clf.predict([[-0.8, -1]]))
# [1]
Herramienta de facto para modelar sistemas de ML
import theano.tensor as T
from theano import function
x = T.dscalar('x')
y = T.dscalar('y')
z = x + y
f = function([x, y], z)
f(2, 3)
# array(5.0)
f(16.3, 12.1)
# array(28.4)Herramienta para crear, optimizar y calcular expresiones matemáticas.
from __future__ import print_function
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.utils import np_utils
batch_size = 128
nb_classes = 10
nb_epoch = 12
# input image dimensions
img_rows, img_cols = 28, 28
# number of convolutional filters to use
nb_filters = 32
# size of pooling area for max pooling
nb_pool = 2
# convolution kernel size
nb_conv = 3
# the data, shuffled and split between tran and test sets
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols)
X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
model = Sequential()
model.add(Convolution2D(nb_filters, nb_conv, nb_conv,
border_mode='valid',
input_shape=(1, img_rows, img_cols)))
model.add(Activation('relu'))
model.add(Convolution2D(nb_filters, nb_conv, nb_conv))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adadelta')
model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch,
show_accuracy=True, verbose=1, validation_data=(X_test, Y_test))
score = model.evaluate(X_test, Y_test, show_accuracy=True, verbose=0)
print('Test score:', score[0])
print('Test accuracy:', score[1])Herramienta para modelar redes neuronales.
import tensorflow as tf
# Basic constant operations
# The value returned by the constructor represents the output
# of the Constant op.
a = tf.constant(2)
b = tf.constant(3)
# Launch the default graph.
with tf.Session() as sess:
print "a=2, b=3"
print "Addition with constants: %i" % sess.run(a+b)
print "Multiplication with constants: %i" % sess.run(a*b)
# Basic Operations with variable as graph input
# The value returned by the constructor represents the output
# of the Variable op. (define as input when running session)
# tf Graph input
a = tf.placeholder(tf.types.int16)
b = tf.placeholder(tf.types.int16)
# Define some operations
add = tf.add(a, b)
mul = tf.mul(a, b)
# Launch the default graph.
with tf.Session() as sess:
# Run every operation with variable input
print "Addition with variables: %i" % sess.run(add, feed_dict={a: 2, b: 3})
print "Multiplication with variables: %i" % sess.run(mul, feed_dict={a: 2, b: 3})Herramienta para generar grafos de procesamiento de datos.
from sklearn import datasets, cross_validation, metrics
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import skflow
### Download and load MNIST data.
mnist = input_data.read_data_sets('MNIST_data')
### Linear classifier.
classifier = skflow.TensorFlowLinearClassifier(
n_classes=10, batch_size=100, steps=1000, learning_rate=0.01)
classifier.fit(mnist.train.images, mnist.train.labels)
score = metrics.accuracy_score(classifier.predict(mnist.test.images), mnist.test.labels)
print('Accuracy: {0:f}'.format(score))
Conjunto de librerías que simplifican el trabajo en TensorFlow con un API similar al de scikit-learn.
?
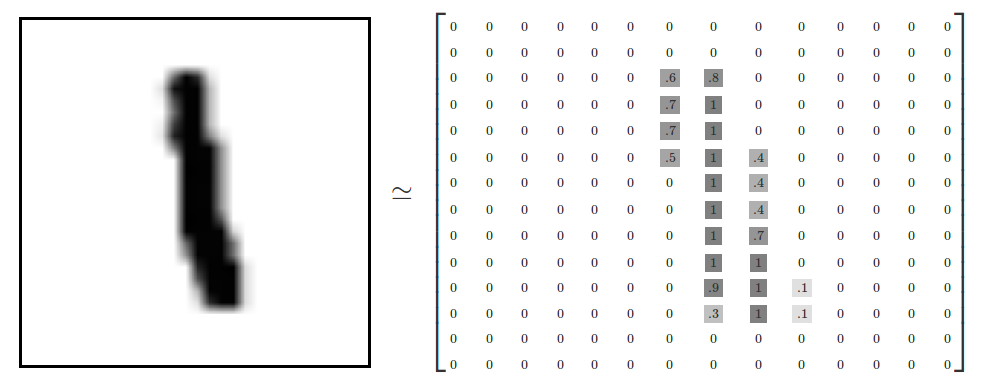
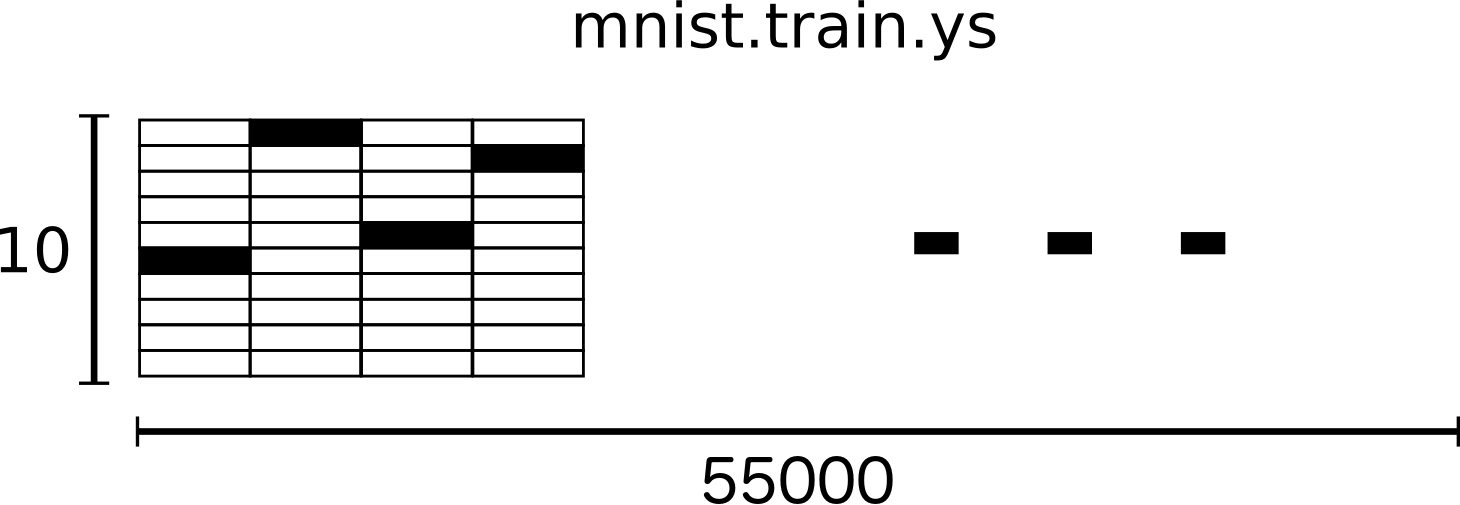
55000 Imágenes de entrenamiento. (mnist.train)
10000 Imágenes de prueba. (mnist.test)
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)Implementando el modelo con TensorFlow
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# Un placeholder es una entidad simbólica de información
# tomará un valor cuando se ejecute el grafo.
x = tf.placeholder(tf.float32, [None, 784])
# Una variable es un contenedor temporal de uso interno del grafo
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
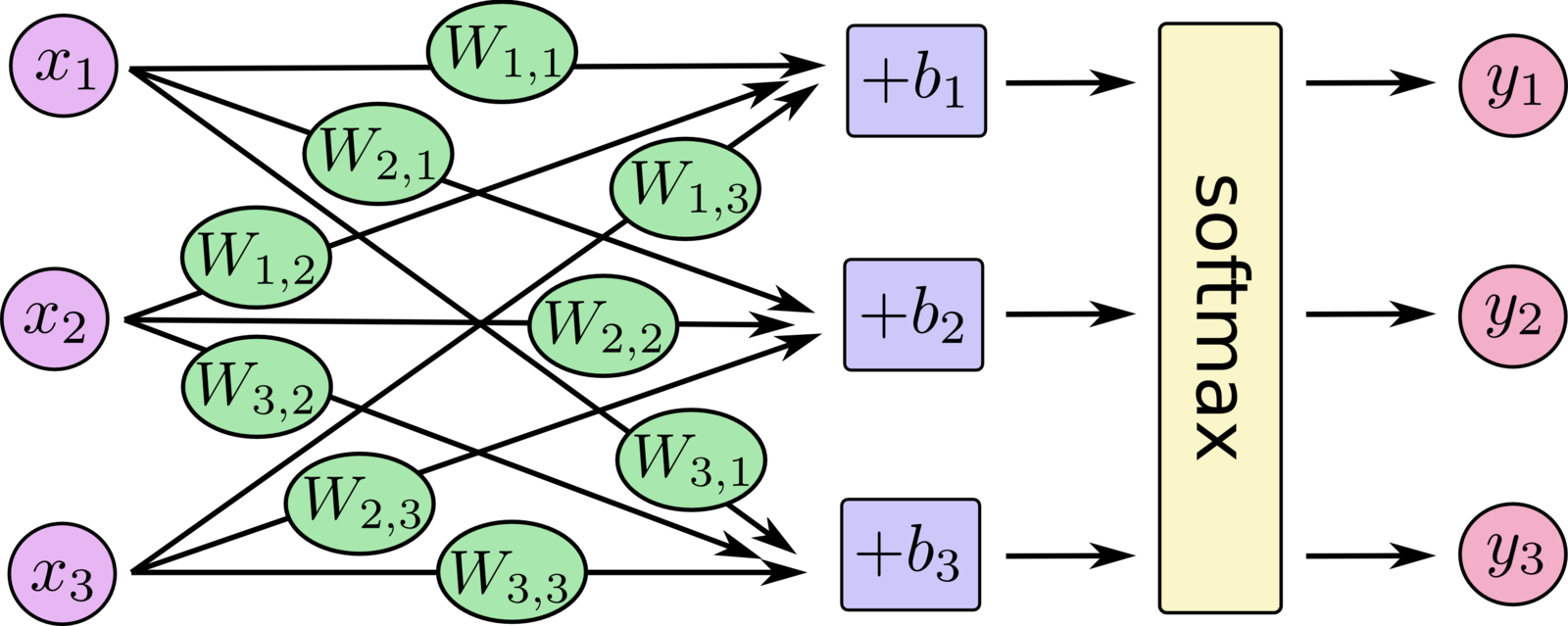
# Las predicciones se hacen en base a softmax con x, W y b
y = tf.nn.softmax(tf.matmul(x, W) + b)# Definimos el contenedor del vector de números de entrenamiento
y_ = tf.placeholder(tf.float32, [None, 10])
# Procedemos a definir la función de costo
# este costo corresponde a toda la data de entrenamiento
cross_entropy = -tf.reduce_sum(y_ * tf.log(y))# La retropropagación se realiza alterando en una pequeña cantidad los valores
# que cambian la función dee costo.
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)Concluimos con la implementación del entrenamiento
# Una vez listo el método de entrenamiento se procede a su ejecución
# con un paso inicial que consiste en inicializar todas las variables.
init = tf.initialize_all_variables()
# Todo el grafo computacional está representado por una 'sesión'
sess = tf.Session()
sess.run(init)
# Entrenaremos el modelo en lotes de 1000 imágenes
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
# Alimentamos el grafo de procesamiento con lotes extraidos
# del conjunto de imágenes de prueba.
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})Evaluamos el desempeño del modelo entrenado
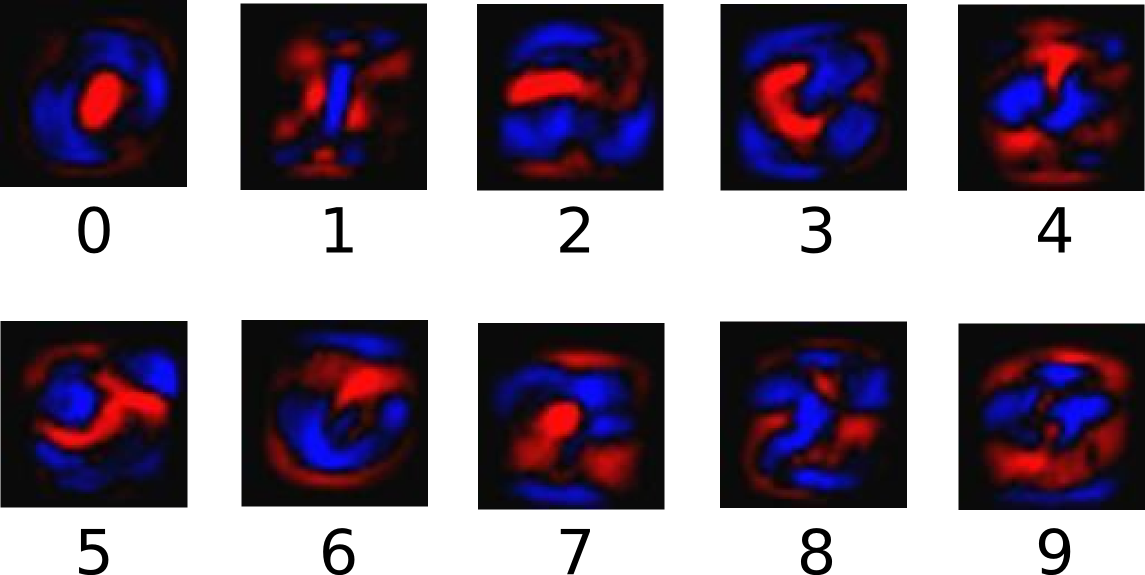
# Obtenemos la cantidad de predicciones correctas de nuestro modelo
# tf.argmax se usa para obtener la predicción más acertada de cada imagen
# y tf.equal se usa para compararla con el valor real de la imagen
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
# correct_prediction es una lista de Booleanos, de las cuales podemos
# calcular la mediana de valores verdaderos para obtener el porcentaje
# de aciertos.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
# Finalmente imprimimos esta cantidad de aciertos suministrando los
# datos de prueba.
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
?
By Moisés Gabriel Cachay Tello




