Python 爬蟲
資工大四 楊翔鈞
2020.05.07
- Language: Python 3.7.4
-
Packages:
- requests
- beautifulsoup4 (建議版本 < 4.9.0)
- lxml
- re
- scrapy (今天不會特別介紹)
requests
- pip install requests
-
用來發 HTTP request
- e.g., GET, POST, PUT, DELETE, ...
- synchronous / 同步
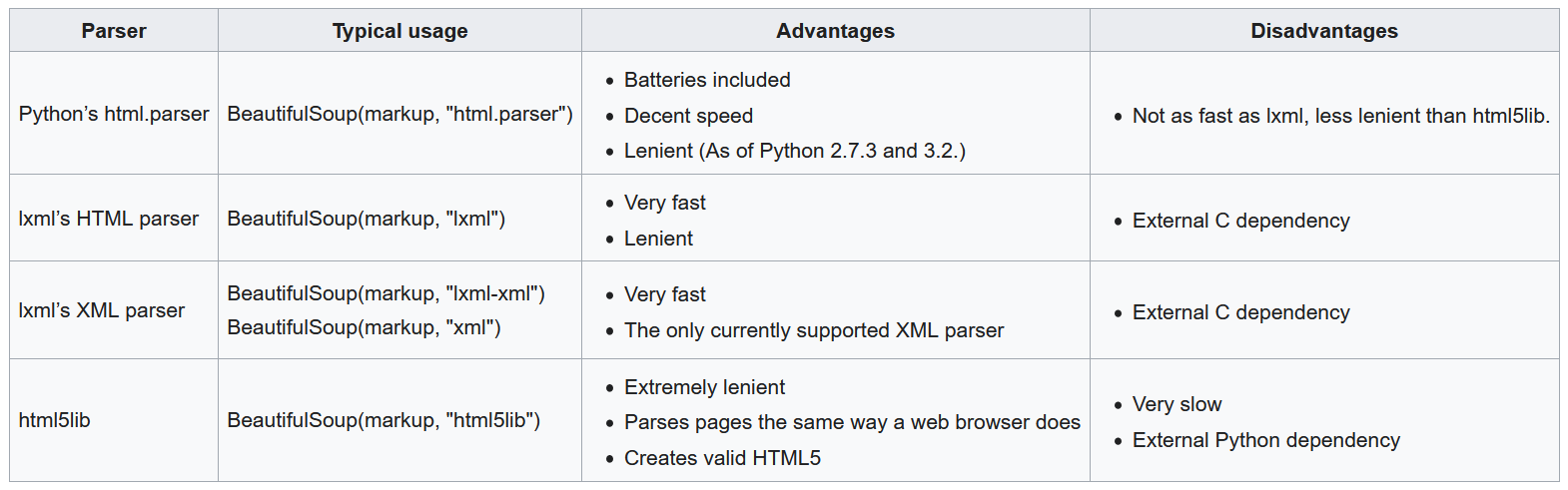
beautifulsoup4
- pip install beautifulsoup4==4.8.0
- parse HTML
. . .
. . .
body
div
div
table
span
div
class="ooxx"
id="xxoo"
class="abc"
id="div2"
class="abc"
id="div1"
lxml
-
apt-get install python-lxml
-
easy_install lxml
-
pip install lxml
re
就 regular expression
scrapy
- web crawling framework
- asynchronous / 非同步
requests 常用 method
- requests.get(url, ...)
- requests.post(url, data={'key': 'value', ...})
beautifulsoup4 常用 method
- 搜尋
- find_all(name, attr, ...)
- find(name, attr, ...)
- select() - https://www.crummy.com/software/BeautifulSoup/bs4/doc/#css-selectors
- select_one()
CSS selector
beautifulsoup4 常用 method
node.decompose()
node
參考資源
DEMO :))))
Crawler
By Yang Eugene
Crawler
爬蟲的社課:) @ ccca
