DML
Data Manipulation Language
Las operaciones mas relevantes en este lenguaje son:
- Select
- Insert
- Update
- Delete
Cláusula Select
Select básico
Una de las tareas más comunes, cuando se trabaja con PostgreSQL, es consultar los datos de las tablas mediante la instrucción SELECT.
La instrucción SELECT es una de las declaraciones más complejas en PostgreSQL. Tiene muchas cláusulas que puedes combinar para formar una consulta potente.

Select básico
Comencemos con lo básico de la instrucción SELECT que recupera datos de una sola tabla.
Su sintaxis es:
SELECT
columna_1,
columna_2,
...
FROM
nombre_tabla;Select básico
Examinemos la declaración SELECT con más detalle:
- Se deben especificar las columnas de la tabla que se desea consultar por medio de la cláusula SELECT. Si se recuperan datos de varias columnas, se debe usar una coma para separarlas. En caso de que se quiera consultar datos de todas las columnas, se puede usar un asterisco (*) como abreviatura (Pero esto no es recomendado, puesto que por debajo la consulta debe identificar el nombre de las columnas, ademas, se impide el uso de índices de forma eficiente).
- La palabra clave FROM indica el nombre de la tabla de donde se obtendran los datos para ser mostrados.
Nota:
Tengamos en cuenta que el lenguaje SQL no distingue mayúsculas de minúsculas. Esto significa que SELECCIONAR o seleccionar tiene el mismo efecto. Por convención, se debe usar palabras clave de SQL en mayúsculas, con el fin de que el código sea más fácil de leer.
Es bueno que todas las consultas terminen en punto y coma (;) para que los querys se puedan ejecutar sin ningún problema.
Ejemplos dvdrental

SELECT city_id,
city,
country_id,
last_update
FROM city;SELECT *
FROM customer;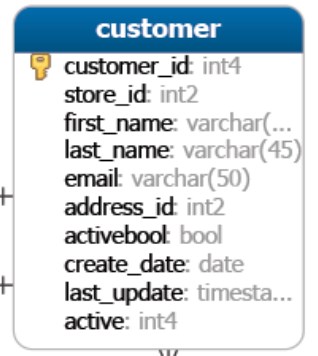
SELECT first_name,
last_name,
email
FROM customer;Order By
Cuando consultamos datos de una tabla, PostgreSQL nos devuelve las filas en el orden en que se insertaron. Por esto, para ordenar el conjunto de resultados, usamos la cláusula ORDER BY en la instrucción SELECT.
La cláusula ORDER BY nos permite ordenar las filas devueltas desde la instrucción SELECT en orden ascendente o descendente en función de los criterios especificados.
SELECT columna_1,
columna_2
FROM tbl_nombre
ORDER BY
columna_1 ASC,
columna_2 DESC;Order By
Examinemos la sintaxis de la cláusula ORDER BY con más detalle:
- Se especifica la columna que se desea ordenar en la cláusula ORDER BY. Si ordena el conjunto de resultados en función de varias columnas, use una coma para separar entre dos columnas.
- El ASC se utiliza para ordenar el conjunto de resultados en orden ascendente y DESC para ordenar el conjunto de resultados en orden descendente. Si lo deja en blanco, la cláusula ORDER BY utilizará ASC por defecto.
Ejemplos dvdrental
SELECT first_name, last_name, email
FROM customer
ORDER BY first_name;
SELECT first_name, last_name, email
FROM customer
ORDER BY first_name ASC;
SELECT first_name, last_name, email
FROM customer
ORDER BY last_name DESC;
SELECT first_name, last_name, email
FROM customer
ORDER BY first_name ASC, last_name DESC;Nota:
Se debe tener en cuenta que el estándar SQL solo permite ordenar filas según las columnas que aparecen en la cláusula SELECT. Sin embargo, PostgreSQL le permite ordenar filas basadas en las columnas que incluso no aparecen en la lista de selección.
Es una buena práctica seguir el estándar de SQL para hacer que el código sea portátil y pueda adaptarse a los cambios que potencialmente puedan ocurrir en la próxima versión de PostgreSQL.
Distinct
La cláusula DISTINCT se usa en la instrucción SELECT para eliminar filas duplicadas del conjunto de resultados.
Esta conserva una fila para cada grupo de duplicados y además se puede usar en una o más columnas de una tabla.
A continuación, se muestra la sintaxis de la cláusula DISTINCT:

Si especifica varias columnas, la cláusula DISTINCT evaluará el duplicado según la combinación de valores de estas columnas.
SELECT DISTINCT columna_1
FROM nombre_tabla;SELECT DISTINCT columna_1, columna_2
FROM nombre_tabla;SELECT DISTINCT ON (columna_1), columna_2
FROM nombre_tabla
ORDER BY columna_1, columna_2;En esta declaración, los valores en la columna columna_1 se usan para evaluar el duplicado.
PostgreSQL también proporciona DISTINCT ON (expresión) para mantener la "primera" fila de cada grupo de duplicados con la siguiente sintaxis:
En esta última sintaxis, el orden de las filas devuelto por la instrucción SELECT es impredecible, por lo tanto, la "primera" fila de cada grupo del duplicado también es impredecible. Es una buena práctica usar siempre la cláusula ORDER BY con DISTINCT ON (expresión) para hacer que el resultado sea obvio.
Observe que la expresión DISTINCT ON debe coincidir con la expresión más a la izquierda en la cláusula ORDER BY.
Nota:
Ejemplos
/*
Para el ejemplo crearemos una
tabla llamada colores
*/
CREATE TABLE public.colores
(
id serial NOT NULL PRIMARY KEY,
color1 character varying(20),
color2 character varying(20)
);
/*
Le vamos a insertar varios registros
para realizar pruebas
*/
INSERT INTO colores(color1, color2)
VALUES ('rojo', 'rojo'),
('rojo', 'rojo'),
('rojo', null),
(null, 'rojo'),
('rojo', 'verde'),
('rojo', 'azul'),
('verde', 'rojo'),
('verde', 'azul'),
('verde', 'verde'),
('azul', 'rojo'),
('azul', 'verde'),
('azul', 'azul');
/*Seleccionamos todos los registros de la
tabla colores: 0 filas afectadas*/
SELECT * FROM colores;
/*Le aplicamos la cláusula solo a una columna:
8 filas afectadas*/
SELECT DISTINCT color1
FROM colores
ORDER BY color1;
/*Le aplicamos la cláusula a las dos columnas:
1 fila afectada*/
SELECT DISTINCT color1, color2
FROM colores
ORDER BY color1;
/*Le aplico la cláusula a la primera columna
pero también quiero que me muestre la columna 2
No olvides que en el order by se deben colocar
en el mismo orden.
8 filas afectadas*/
SELECT DISTINCT ON(color1) color1, color2
FROM colores
ORDER BY color1, color2;
Hasta este punto, hemos identificado como podemos mostrar los datos al usuario y ordenarlos.
Ahora veamos como filtrar estos datos para realizar búsquedas mas precisas.
Where
¿Qué sucede si deseamos consultar solo las filas particulares de una tabla?
En este caso, debemos usar la cláusula WHERE en la instrucción SELECT.
Veamos la sintaxis de la cláusula WHERE de PostgreSQL:
La cláusula WHERE aparece después de la cláusula FROM en la instrucción SELECT.
Las condiciones se utilizan para filtrar las filas devueltas desde la instrucción SELECT.
PostgreSQL le proporciona varios operadores estándar para construir las condiciones. La siguiente tabla ilustra los operadores de comparación estándar:
SELECT columna_1, columna_2, … columna_n
FROM nombre_tabla
WHERE condiciones;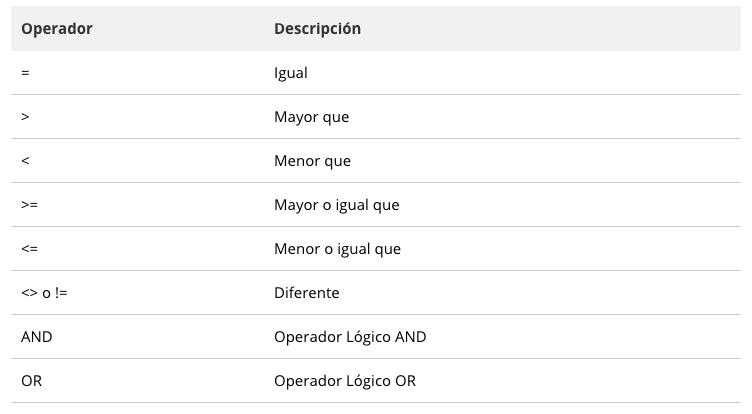
Si utilizamos el operador lógico AND se debe cumplir con todas las condiciones implicadas.
Si por el contrario, utilizamos el operador lógico OR se debe cumplir con al menos una de las condiciones.
Ejemplos
/*
Para obtener todos los clientes cuyos nombres sean Jamie,
puede usar la cláusula WHERE con el operador igual (=) de la
siguiente manera:
*/
SELECT first_name, last_name
FROM customer
WHERE first_name = 'Jamie';
/*
Para seleccionar el cliente cuyo primer nombre es Jamie
y su apellido es Rice, puede usar el operador lógico AND que
combina dos condiciones como en la siguiente consulta:
*/
SELECT *
FROM customer
WHERE first_name = 'Jamie' AND last_name = 'Rice';
/*
Para saber quién pagó el alquiler con un precio inferior a 1 USD
o superior a 8 USD, puede utilizar la siguiente consulta con el
operador OR:
*/
SELECT *
FROM payment
WHERE amount <= 1 OR amount >= 8;Limit
PostgreSQL LIMIT es una cláusula opcional de la instrucción SELECT que obtiene un subconjunto de filas devuelto por una consulta.
A continuación, se muestra la sintaxis de la cláusula LIMIT:
SELECT columna_1, columna_2
FROM nombre_tabla
LIMIT n;Limit
La instrucción devuelve n filas generadas por la consulta. Si n es cero o NULL, la consulta devuelve el mismo conjunto de resultados que omitiendo la cláusula LIMIT.
Veamos algunos ejemplos para comprender mejor el uso de la cláusula LIMIT de PostgreSQL. Usaremos la tabla de films en la base de datos dvdrental.
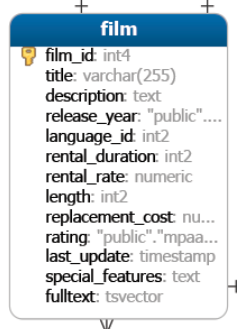
De esta tabla, vamos a obtener las primeras 5 películas ordenadas por film_id.
Ejemplos
SELECT film_id, title, release_year
FROM film
ORDER BY film_id
LIMIT 5;A menudo usamos la cláusula LIMIT para obtener el número de elementos más altos o más bajos en una tabla. Por ejemplo, para obtener las 10 películas más solicitadas.
Para esto, debemos clasificar las películas por la tasa de alquiler (rental_rate) en orden descendente (DESC) y use la cláusula LIMIT para obtener las primeras 10 películas.
La siguiente consulta muestra la idea:
SELECT film_id, title, release_year
FROM film
ORDER BY rental_rate DESC
LIMIT 10;Nota:
Debido a que el orden de las filas en la tabla de la base de datos es impredecible, cuando se utiliza la cláusula LIMIT, siempre se debe utilizar la cláusula ORDER BY para controlar el orden de las filas.
Si no lo hace, obtendrá un conjunto de resultados impredecibles.
Offset
En caso de que desee omitir un número de filas antes de devolver las n filas, utilice la cláusula OFFSET situada después de la cláusula LIMIT. Estas dos cláusulas se utilizan mucho para realizar los famosos paginadores que mejoran el rendimiento al mostrar datos al usuario en una aplicación.
Veamos su sintaxis:
SELECT columna_1, columna_2
FROM tabla
LIMIT n OFFSET m;Tengamos en cuenta que la sentencia anterior salta m filas antes de devolver n filas que serán las generadas por la consulta.
Si m es cero, la sentencia funcionará como si no existiera la cláusula OFFSET.
Si utiliza un OFFSET grande, puede que no sea eficiente porque PostgreSQL todavía tiene que calcular las filas omitidas por el OFFSET dentro del servidor de base de datos, aunque las filas omitidas no sean devueltas.
Ejemplos
SELECT
film_id,
title,
release_year
FROM
film
ORDER BY
film_id
LIMIT 4 OFFSET 3;Vamos a recuperar 4 películas a partir de la tercera fila ordenada por film_id, utilice las cláusulas LIMIT y OFFSET de la siguiente manera:
Cláusula IN
El operador IN de la cláusula WHERE se utiliza para comprobar si un valor coincide con cualquier valor de una lista de valores.
La sintaxis del operador IN es la siguiente:

valor IN (valor1,valor2,...)La expresión devuelve true si el valor coincide con cualquier valor de la lista, es decir, valor1, valor2, etc.
Cláusula IN
La lista de valores no se limita a una lista de números o cadenas, sino que también es un conjunto de resultados de una instrucción SELECT como se muestra en la en la siguiente consulta:
valor IN (SELECT valor FROM tabla);La sentencia dentro de los paréntesis se llama subconsulta, que es una consulta anidada dentro de otra consulta.
Ejemplos
Supongamos que deseamos conocer la información de alquiler de los clientes 1 y 2. Para esto podemos utilizar el operador IN en la cláusula WHERE como se indica a continuación:
SELECT customer_id, rental_id, return_date
FROM rental
WHERE customer_id IN (1, 2)
ORDER BY return_date DESC;La consulta anterior podría realizarse utilizando los operadores igual (=) y OR como se indica a continuación:
SELECT rental_id, customer_id, return_date
FROM rental
WHERE customer_id = 1 OR customer_id = 2
ORDER BY return_date DESC;Operador NOT IN
Podemos combinar el operador IN con el operador NOT para seleccionar filas cuyos valores no coincidan con los de la lista.
La siguiente declaración selecciona los alquileres de clientes cuyo ID de cliente no es 1 o 2.
SELECT customer_id, rental_id, return_date
FROM rental
WHERE customer_id NOT IN (1, 2);También puede reescribir el operador NOT IN utilizando los operadores de diferencia (<>) y AND como se indica a continuación:
SELECT customer_id, rental_id, return_date
FROM rental
WHERE customer_id <> 1 AND customer_id <> 2;Operador IN con Subconsultas
La siguiente consulta devuelve una lista de los clientes que tienen la fecha de devolución del alquiler en 2005-05-27:
SELECT customer_id
FROM rental
WHERE cast(return_date AS DATE) = '2005-05-27'Los identificadores de clientes que devuelve la consulta anterior pueden servir como entrada para el operador IN del siguiente modo:
SELECT customer_id, rental_id, return_date
FROM customer
WHERE customer_id IN(
SELECT customer_id
FROM rental
WHERE cast(return_date AS DATE) = '2005-05-27'
);Between
Utilice el operador BETWEEN para comparar un valor con un rango de valores.
A continuación se ilustra la sintaxis del operador BETWEEN:

VALOR BETWEEN rango_menor AND rango_mayor;Si el valor es mayor o igual que el rango menor y menor o igual que el rango mayor, la expresión devuelve true; de lo contrario, devuelve false.
Puede reescribir el operador BETWEEN utilizando los operadores mayor o igual que (>=) o menor o igual que (<=) como la siguiente sentencia:
Between
valor >= rango_menor and valor <= rango_mayor;Al igual que el operador IN, el operador BETWEEN puede hacer uso del operador NOT. Esto con el fin de comprobar si un valor está fuera de rango:
valor NOT BETWEEN rango_menor AND rango_mayor;A menudo se utiliza el operador BETWEEN en la cláusula WHERE de una sentencia SELECT, INSERT, UPDATE o DELETE.
Ejemplos
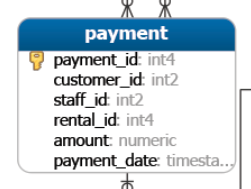
Para este ejemplo, vamos a utilizar la tabla payment de la base de datos dvdrental
Realicemos una consulta donde seleccionemos los pagos que se encuentren entre los 8 y 9 dólares (USD):
SELECT
customer_id,
payment_id,
amount
FROM
payment
WHERE
amount BETWEEN 8 AND 9;Ahora, seleccionemos los pagos que NO se encuentren en ese rango:
SELECT
customer_id,
payment_id,
amount
FROM
payment
WHERE
amount NOT BETWEEN 8 AND 9;Excelente, de esta manera podemos realizar filtros por rangos. Un uso muy común para el operador BETWEEN es realizar filtros para fechas. Por ejemplo decir que personas nacieron entre un rango de años, que pagos se realizaron entre ciertas fechas. Veamos:
Para realizar esta verificación, PostgreSQL nos indica que debemos utilizar la fecha literal en formato ISO 8601, es decir, AAAA-MM-DD. Por ejemplo, para obtener el pago cuya fecha de pago se encuentra entre 2007-02-07 y 2007-02-15, podríamos utilizar la siguiente consulta:
SELECT
customer_id,
payment_id,
amount,
payment_date
FROM
payment
WHERE
payment_date BETWEEN '2007-02-07' AND '2007-02-15';En las próximas sesiones de clase veremos las funciones de fecha para obtener intervalos, el mes, el año, etc.
Like
LIKE es otro operador clave que se utiliza en la cláusula WHERE.
Básicamente, LIKE le permite hacer una búsqueda basada en un patrón en vez de especificar exactamente lo que se desea (como en IN) o determinar un rango (como en BETWEEN).
La sintaxis es la siguiente:
SELECT columna_1
FROM tabla
WHERE columna_1 LIKE {patrón};Like
Supongamos que el gerente de la tienda de dvd le pide que encuentre un cliente que no recuerda exactamente el nombre. Sólo recuerda que el nombre del cliente comienza con algo como Jen. ¿Cómo encuentra usted al cliente exacto que el gerente de la tienda está preguntando? Puede encontrar al cliente en la tabla de clientes mirando la columna de nombre para ver si hay algún valor que comience con Jen. Pero en realidad, esto es un poco tedioso porque hay muchas filas en la tabla de clientes.
Es aquí donde el operador LIKE toma protagonismo y podemos realizar una consulta como estas:
SELECT first_name, last_name
FROM customer
WHERE first_name LIKE 'Jen%';Nota:
Tenga en cuenta que la cláusula WHERE contiene una expresión especial: el first_name, el operador LIKE y una cadena que contiene un carácter de porcentaje (%), que se denomina patrón.
La consulta devuelve filas cuyos valores en la columna de nombre comienzan con Jen y pueden ser seguidos por cualquier secuencia de caracteres.
Esta técnica se llama concordancia de patrones.
Usted construye un patrón combinando una cadena con caracteres comodín y utiliza el operador LIKE o NOT LIKE para encontrar las coincidencias.
Nota:
PostgreSQL proporciona dos caracteres comodín:
- Porcentaje (%): Sirve para coincidir con cualquier secuencia de caracteres.
- Guión bajo (_): Sirve para que coincida con cualquier carácter individual.

Veamos algunos ejemplos para identificar como operan el guión bajo (_) y el porcentaje (%).
-
'A_Z': Toda línea que comience con 'A', otro carácter y termine con 'Z'. Por ejemplo, 'A
BZ' y 'A2Z' deberían satisfacer la condición, mientras 'AKKZ' no debería (debido a que hay dos caracteres entre A y Z en vez de uno).
- 'ABC%': Todas las líneas que comienzan con 'ABC'. Por ejemplo, 'ABCD' y 'ABCABC' ambas deberían satisfacer la condición, mientras 'AABCD' no debería (debido a que la cadena no empieza con ABC).
- '%XYZ': Todas las líneas que terminan con 'XYZ'. Por ejemplo, 'WXYZ' y 'ZZXYZ' ambas deberían satisfacer la condición.
- '%AN%': Todas las líneas que contienen el patrón 'AN' en cualquier lado. Por ejemplo, 'LOS ANGELES' y 'SAN FRANCISCO' ambos deberían satisfacer la condición.
- Si el patrón no contiene ningún carácter comodín, el operador LIKE actúa como el operador igual (=).

Ejemplos
Para este ejemplo, vamos a utilizar la tabla customer de la base de datos dvdrental
Utilicemos el carácter comodín al principio y/o al final del patrón. Por ejemplo, la siguiente consulta devuelve clientes cuyo nombre contiene una cadena 'er', por ejemplo, Jenifer, Kimberly, etc.
SELECT first_name, last_name
FROM customer
WHERE first_name LIKE '%er%';
Podemos combinar el comodín porcentaje (%) con el guión bajo (_) para construir un patrón como el siguiente ejemplo:
SELECT first_name, last_name
FROM customer
WHERE first_name LIKE '_her%';La siguiente consulta nos mostraría los clientes que su nombre comienza con cualquier carácter individual, es seguido por 'her' y termina con cualquier número de caracteres. Por ejemplo:
-
Cher
yl -
Ther
esa -
Sher
y -
Sher
i
No olvides que siempre puedes mezclar el operador NOT. De esta manera obtendrías los clientes que no cumplen con el patrón. Veamos un ejemplo:
SELECT first_name, last_name
FROM customer
WHERE first_name LIKE 'Jen%';ILike
PostgreSQL proporciona el operador ILIKE que actúa como el operador LIKE. La diferencia es que el operador ILIKE no distingue entre mayúsculas y minúsculas.
Veamos el siguiente ejemplo:

SELECT first_name, last_name
FROM customer
WHERE first_name ILIKE 'BAR%';ILike
De esta manera obtendríamos a:
- Barbara
- Barry
Si lo realizáramos con el operador LIKE no obtendríamos resultados, puesto que para este si es muy importante las minúsculas y las mayúsculas.
Hasta ahora, hemos aprendido a seleccionar datos de una tabla, seleccionando qué columnas y filas deseamos o cómo clasificar el conjunto de resultados en un orden determinado.
Es hora de pasar a uno de los conceptos más importantes de la base de datos llamado JOINS que nos permite relacionar los datos de una tabla con los datos de otras tablas.
Joins
Los JOINS se utilizan para recuperar datos de múltiples tablas. Un JOIN se realiza cuando dos o más tablas se unen en una sentencia SQL la cual será mostrada al usuario.
Existen diferentes tipos de JOINS en PostgreSQL:
- INNER JOIN
- LEFT JOIN
- RIGHT JOIN
- FULL OUTER JOIN (o a veces denominado FULL JOIN)
- NATURAL JOIN
- CROSS JOIN
Veamos las diferentes funcionalidades, sintaxis y algunos ejemplos tanto visuales como en sentencias para mejorar la compresión de esta importante cláusula.
¿Qué son los JOINS?
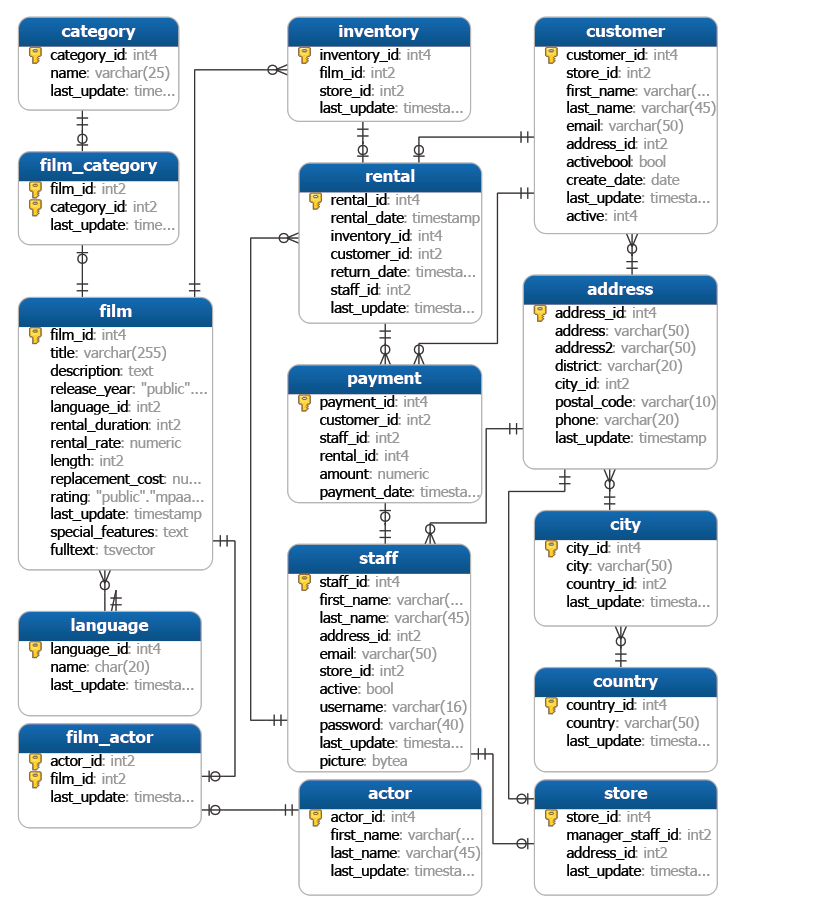
Antes de comenzar con los JOINS revisemos el diagrama con el cual trabajaremos durante la sesión.
Es de suprema importancia conocer las relaciones de una base de datos, pues de esto depende que la sentencia que realices cumpla con los pasos necesarios para acceder a la información.
INNER JOIN
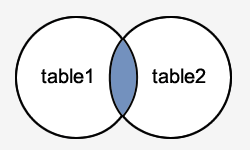
Supongamos que deseamos obtener datos de dos tablas llamadas A y B. La tabla B tiene el campo de clave extranjera (FK) el cual se relaciona con la clave primaria (PK) de la tabla A.
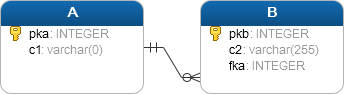
Si aplicamos la cláusula INNER JOIN en la sentencia SELECT esta nos devolvería todas las filas donde se cumple la condición de unión (se intersectan). Es decir, donde la clave primaria de A (pka) encuentra una coincidencia con la clave extranjera de B (fka).
La sentencia sería la siguiente:
SELECT
A.pka,
A.c1,
B.pkb,
B.c2
FROM A
INNER JOIN B
ON A.pka = B.fka;La sentencia anterior estaba permitiendo la unión de la tabla A y de la tabla B. Para esto se tuvo en cuenta lo siguiente:
- Se especificaron las columnas de ambas tablas que se deseaban mostrar en la cláusula SELECT
- Se especifico la tabla principal, es decir, la tabla A (La cual contiene la clave primaria) en la cláusula FROM.
- Se especifico la tabla a la que se une la tabla principal, es decir, B (Donde se encuentra la clave extranjera), en la cláusula INNER JOIN. Además, se debe colocar una condición de unión después de la palabra clave ON, es decir, A.pka = B.fka.
Para cada fila de la tabla A, PostgreSQL explora la tabla B para comprobar si hay alguna fila que coincida con la condición, es decir, A.pka = B.fka. Si encuentra una coincidencia, combina columnas de ambas filas en una fila y añade la fila combinada al conjunto de resultados devueltos.
- A veces, las tablas A y B tienen el mismo nombre de columna, por lo que tenemos que referirnos a la columna en la sentencia como nombre_tabla.nombre_columna para evitar ambigüedad.
- En caso de que el nombre de la tabla sea largo, se puede utilizar un alias de tabla, por ejemplo, tbl y referirse a la columna como tbl.nombre_columna.
La columna de clave primaria (pka) y la columna de clave extranjera (fka) son típicamente indexadas; por lo tanto, PostgreSQL sólo tiene que comprobar la coincidencia en los índices, lo cual es muy rápido.
Recomendaciones
Ejemplos
Veamos la siguiente relación entre las tablas customer y payment de la base de datos dvdrental

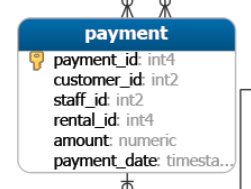
Cada cliente puede tener cero o muchos pagos. Cada pago pertenece a un único cliente. El campo customer_id establece el enlace entre las dos tablas.
Para mostrar la unión de estas dos tablas podemos utilizar la cláusula INNER JOIN de la siguiente manera:
SELECT
customer.customer_id,
first_name,
last_name,
email,
amount,
payment_date
FROM
customer
INNER JOIN payment
ON payment.customer_id = customer.customer_id;Ejemplo 1:
SELECT
c.customer_id,
c.first_name,
c.last_name,
c.email,
p.amount,
p.payment_date
FROM
customer AS c
INNER JOIN payment AS p
ON p.customer_id = c.customer_id;Ejemplo 2 (Recomendado):
No olvide que usted puede mezclar cualquier cláusula vista en la sección anterior, tales como:
- Where (IN, LIKE, BETWEEN)
- OrderBy
- Distinct
El siguiente diagrama ilustra la relación entre tres tablas: STAFF (Empleado), PAYMENT (Pago) y CUSTOMER (Cliente).
- Cada empleado se relaciona con cero o muchos pagos.
- Cada pago es procesado por un solo empleado.
- Cada cliente tiene cero o muchos pagos.
- Cada pago pertenece a un único cliente.


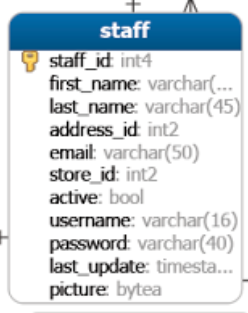
Para unir las tres tablas, se coloca la segunda cláusula INNER JOIN después de la primera cláusula INNER JOIN como se muestra en la siguiente consulta:
SELECT
c.customer_id,
c.first_name customer_first_name,
c.last_name customer_last_name,
c.email,
s.first_name staff_first_name,
s.last_name staff_last_name,
p.amount,
p.payment_date
FROM
customer AS c
INNER JOIN payment AS p ON p.customer_id = c.customer_id
INNER JOIN staff AS s ON p.staff_id = s.staff_id;Para unir más de tres tablas (n tablas), se aplica la misma técnica.
LEFT JOIN
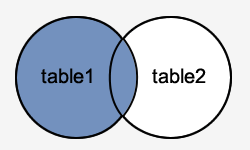
Supongamos que tenemos dos tablas llamadas A y B.
Cada fila en la tabla A puede tener cero o muchas filas correspondientes en la tabla B. Cada fila de la tabla B tiene una y sólo una fila correspondiente en la tabla A.
Si desea seleccionar filas de la tabla A que tienen filas correspondientes en la tabla B, utilice la cláusula INNER JOIN.
Si desea seleccionar filas de la tabla A que pueden o no tener filas correspondientes en la tabla B, utilice la cláusula LEFT JOIN. En caso de que no haya ninguna fila coincidente en la tabla B, los valores de las columnas de la tabla B se sustituyen por el valor NULL.
La sentencia LEFT JOIN combina los valores de la primera tabla con los valores de la segunda tabla.
Siempre devolverá las filas de la primera tabla, incluso aunque no cumplan la condición del JOIN, de ahí su nombre.
La siguiente sentencia muestra la sintaxis de LEFT JOIN que une la tabla A a la tabla B:

SELECT
A.pka,
A.c1,
B.pkb,
B.c2
FROM A
LEFT JOIN B
ON A.pka = B.fka;Para realizar la sentencia anterior debemos tener en cuenta lo siguiente:
- Especifique las columnas de las que desea seleccionar datos en la cláusula SELECT.
- Especifique la tabla izquierda (LEFT), es decir, Una tabla en la que desea obtener todas las filas, en la cláusula FROM.
- Especifique la tabla derecha, es decir, la tabla B en la cláusula LEFT JOIN. Además, especifique la condición para unir las dos tablas.
Ejemplos
Veamos la siguiente relación entre las tablas film(Película) y inventory(Inventario) de la base de datos dvdrental
- Cada fila de la tabla de película puede tener cero o muchas filas en la tabla de inventario.
- Cada fila en la tabla de inventario tiene una y sólo una fila en la tabla de película.
Veamos como utilizar la cláusula LEFT JOIN para unir la tabla de película a la tabla de inventario:
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
film AS f
LEFT JOIN inventory as i
ON i.film_id = f.film_id;Debido a que algunas filas de la tabla de película no tienen filas correspondientes en la tabla de inventario, los valores del inventory_id son NULL.
Para que veamos cuales de las filas de película no corresponden en inventario podemos agregar una cláusula WHERE para seleccionar sólo las películas que no están en el inventario.
Veamos la siguiente consulta:
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
film AS f
LEFT JOIN inventory AS i
ON i.film_id = f.film_id
WHERE i.film_id IS NULL;Esta técnica es útil cuando desea seleccionar datos de una tabla que no coinciden con los de otra.
RIGHT JOIN
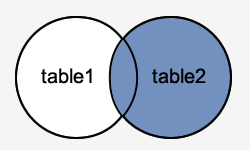
La sentencia RIGHT JOIN combina los valores de la primera tabla con los valores de la segunda tabla.
Siempre devolverá las filas de la segunda tabla, incluso aunque no cumplan la condición.
En algunas bases de datos, la sentencia RIGHT JOIN es igual a RIGHT OUTER JOIN.
Su sintaxis es la siguiente:
SELECT
A.pka,
A.c1,
B.pkb,
B.c2
FROM A
RIGHT JOIN B
ON A.pka = B.fka;Ejemplos
Veamos la siguiente relación entre las tablas film(Película) y inventory(Inventario) de la base de datos dvdrental
- Cada fila de la tabla de película puede tener cero o muchas filas en la tabla de inventario.
- Cada fila en la tabla de inventario tiene una y sólo una fila en la tabla de película.
Veamos como utilizar la cláusula RIGHT JOIN para unir la tabla de película a la tabla de inventario, ademas revisemos cuales son los datos que cambian con respecto a la cláusula anterior:
SELECT
f.film_id,
f.title,
i.inventory_id
FROM
film AS f
RIGHT JOIN inventory as i
ON i.film_id = f.film_id;Debido a que algunas filas de la tabla inventario no tienen filas correspondientes en la tabla de película, los valores del film_id y title son NULL.
En muchas partes encontramos solo ejercicios o explicaciones con LEFT JOIN ya que es el más utilizado y podemos con este solucionar cualquiera de los casos.
FULL JOIN
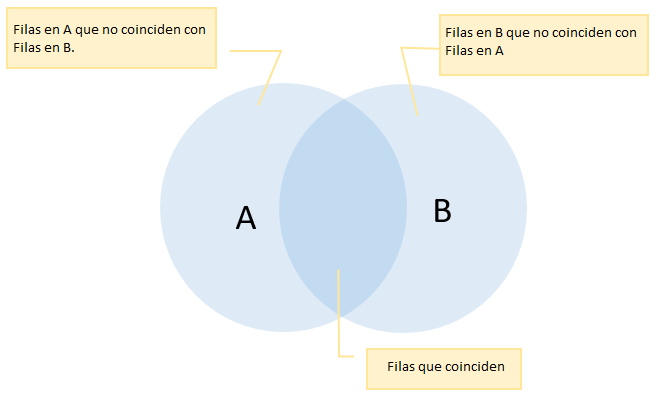
La sentencia FULL JOIN combina los valores de la primera tabla con los valores de la segunda tabla. Siempre devolverá las filas de las dos tablas, aunque no cumplan la condición. Si las filas de la tablas no coinciden, FULL JOIN establece valores NULL para cada columna de la tabla que carece de una fila coincidente.
La sentencia FULL JOIN es la unión de LEFT JOIN y RIGHT JOIN.
Veamos la sintaxis:
SELECT *
FROM A
FULL [OUTER] JOIN B
ON A.id = B.id;La cláusula OUTER es opcional.
Ejemplos
CREATE TABLE IF NOT EXISTS tbl_departamento (
id_departamento serial PRIMARY KEY,
nombre_departamento VARCHAR (255) NOT NULL
);
CREATE TABLE IF NOT EXISTS tbl_empleado (
id_empleado serial PRIMARY KEY,
nombre_empleado VARCHAR (255) NOT NULL,
id_departamento INTEGER NULL,
CONSTRAINT fk_empleado_departamento_id_departamento
FOREIGN KEY (id_departamento)
REFERENCES tbl_departamento (id_departamento)
);
Para realizar el ejemplo, ejecutaremos el siguiente query:
Cada departamento tiene cero o muchos empleados y cada empleado pertenece a cero o a un departamento.
INSERT INTO tbl_departamento
(nombre_departamento)
VALUES
('Ventas'),
('Marketing'),
('Recursos Humanos'),
('Tecnología'),
('Producción');
INSERT INTO tbl_empleado
(nombre_empleado, id_departamento)
VALUES
('Julian Arroyave', 1),
('Christian Serna', 1),
('Jose Guzman', 2),
('Fredy Cuartas', 3),
('Sandra Gomez', 4),
('Yhoan Galeano', NULL);Las siguientes sentencias INSERT añaden algunos datos de muestra a las tablas de departamentos y empleados.
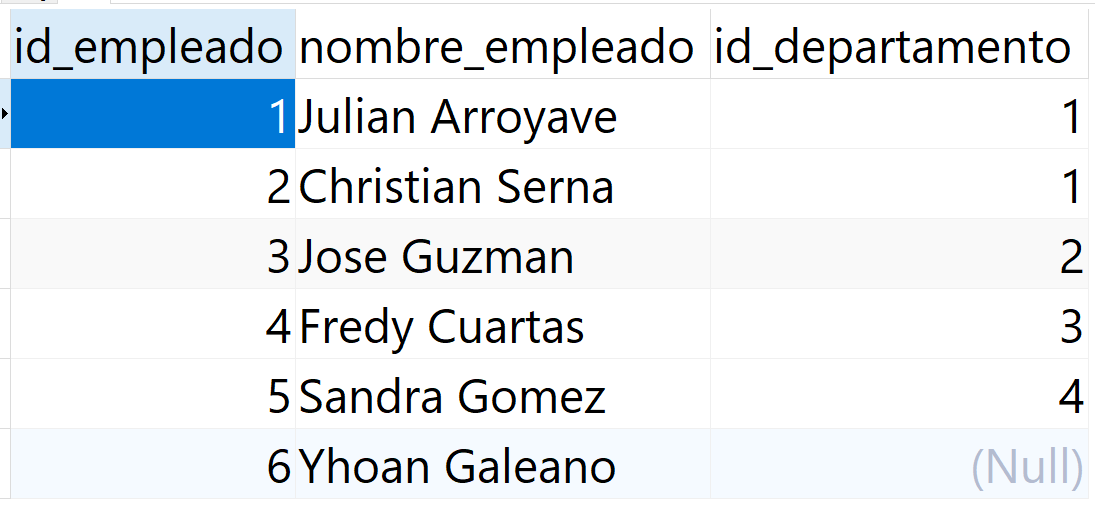
Verifiquemos la información en las tablas:
SELECT
id_departamento,
nombre_departamento
FROM tbl_departamento;SELECT id_empleado, nombre_empleado, id_departamento
FROM tbl_empleado;
SELECT e.id_empleado,
e.nombre_empleado,
d.id_departamento,
d.nombre_departamento
FROM tbl_empleado AS e
FULL JOIN tbl_departamento AS d
ON e.id_departamento = d.id_departamento;Realicemos la sentencia utilizando el FULL JOIN:
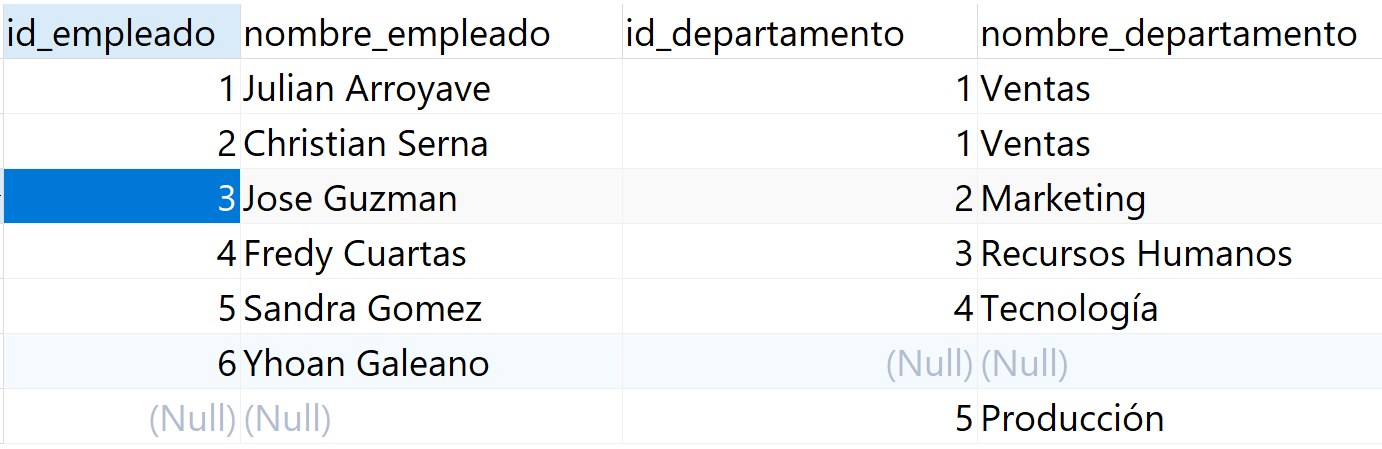
El conjunto de resultados incluye a todos los empleados que pertenecen a un departamento y a todos los departamentos que tienen un empleado. Además, incluye a todos los empleados que no pertenecen a un departamento y a todos los departamentos que no tienen empleados.
Para encontrar los departamentos que no tienen ningún empleado, utilizamos la siguiente cláusula WHERE:
SELECT e.id_empleado,
e.nombre_empleado,
d.id_departamento,
d.nombre_departamento
FROM tbl_empleado AS e
FULL JOIN tbl_departamento AS d
ON e.id_departamento = d.id_departamento
WHERE e.id_empleado IS NULL;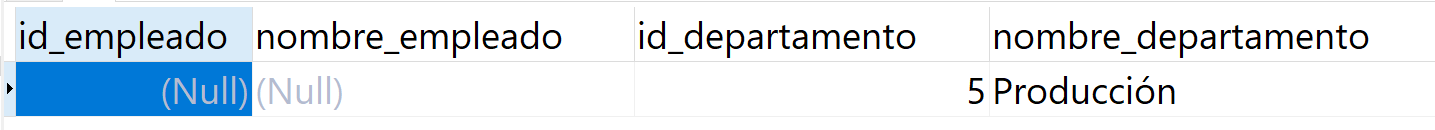
Para encontrar los empleados que no pertenecen a ningún departamento, utilizamos la siguiente cláusula WHERE:
SELECT e.id_empleado,
e.nombre_empleado,
d.id_departamento,
d.nombre_departamento
FROM tbl_empleado AS e
FULL JOIN tbl_departamento AS d
ON e.id_departamento = d.id_departamento
WHERE d.id_departamento IS NULL;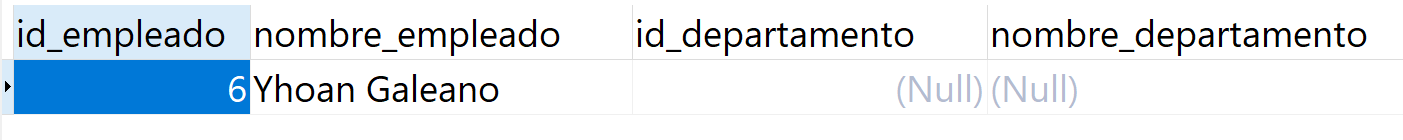
Si quisieras ver todos los registros que no tienen relación en alguna de las tablas podrías ejecutar la siguiente sentencia:
SELECT e.id_empleado,
e.nombre_empleado,
d.id_departamento,
d.nombre_departamento
FROM tbl_empleado AS e
FULL JOIN tbl_departamento AS d
ON e.id_departamento = d.id_departamento
WHERE e.id_empleado IS NULL
OR d.id_departamento IS NULL;

NATURAL JOIN

NATURAL JOIN se usa cuando los campos por los cuales se enlazan las tablas tienen el mismo nombre. La sintaxis es:
SELECT *
FROM T1 NATURAL [INNER, LEFT, RIGHT] JOIN T2;Un NATURAL JOIN puede ser un INNER JOIN, LEFT JOIN o RIGHT JOIN. Si no se especifica una entrada en su declaración PostgreSQL utilizará el INNER JOIN por defecto.
Si utiliza el asterisco (*) en la lista de selección, el resultado contendrá las siguientes columnas:
- Todas las columnas comunes, que son las columnas de las dos tablas que tienen el mismo nombre
- Todas las columnas de la primera y segunda tabla que no son una columna común
Ejemplos
Para demostrar el NATURAL JOIN de PostgreSQL, crearemos dos tablas: categorías y productos. Las siguientes sentencias CREATE TABLE crean la tabla de categorías y productos:
CREATE TABLE tbl_categoria (
id_categoria serial PRIMARY KEY,
nombre_categoria VARCHAR (255) NOT NULL
);
CREATE TABLE tbl_producto (
id_producto serial PRIMARY KEY,
nombre_producto VARCHAR (255) NOT NULL,
id_categoria INT NOT NULL,
FOREIGN KEY (id_categoria)
REFERENCES tbl_categoria (id_categoria)
);Cada categoría tiene cero o muchos productos, mientras que cada producto pertenece a una sola categoría. La columna id_categoria en la tabla de productos es la clave externa que hace referencia a la clave primaria de la tabla de categorías.
La id_categoria es la columna común que usaremos para realizar el NATURAL JOIN.
Estos serán los INSERTS que realizaremos par probar la cláusula:
INSERT INTO tbl_categoria (nombre_categoria)
VALUES ('Celulares Inteligentes'), ('Computadores'), ('Tablets');
INSERT INTO tbl_producto (nombre_producto, id_categoria)
VALUES ('iPhone', 1), ('Samsung Galaxy', 1),
('HP Elite', 2), ('Lenovo Thinkpad', 2), ('iPad', 3);Ahora realicemos la sentencia del NATURAL JOIN:
SELECT *
FROM tbl_producto
NATURAL JOIN tbl_categoria;Los datos que mostraría la sentencia es la siguiente:

La declaración anterior es equivalente a la siguiente declaración que utiliza la cláusula INNER JOIN:
SELECT *
FROM tbl_producto AS p
INNER JOIN tbl_categoria as c
USING (id_categoria);Sin embargo, debe evitar el uso de la NATURAL JOIN siempre que sea posible porque a veces puede causar un resultado inesperado.
Por ejemplo, veamos las tablas de ciudad y departamento.
Ambas tablas tienen la misma columna country_id para que podamos usar el NATURAL JOIN para unir estas tablas como la siguiente sentencia:
SELECT *
FROM city
NATURAL JOIN country;La consulta devuelve un conjunto de resultados vacío.
¿Cual es la razón?


Ambas tablas también tienen una columna común llamada last_update, que no se puede utilizar para la unión.
Sin embargo, la cláusula NATURAL JOIN sólo usa la última columna last_update.

CROSS JOIN
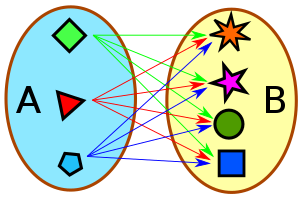
CROSS JOIN hace una multiplicación de todas las filas de una tabla por todas las filas de la otra tabla. O sea que si una tabla tiene 30 filas y la otra tabla tiene 50 filas el resultados tendrá 30 * 50 = 1500 filas.
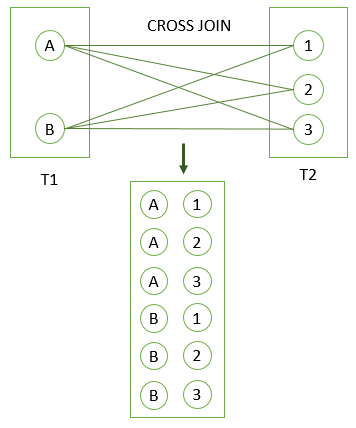
La sintaxis es la siguiente:
SELECT *
FROM T1
CROSS JOIN T2;La siguiente declaración también es equivalente a CROSS JOIN:
SELECT *
FROM T1, T2;Puede usar la cláusula INNER JOIN con la condición como verdadera para realizar el CROSS JOIN de la siguiente manera:
SELECT *
FROM T1
INNER JOIN T2 ON TRUE;SELECT *
FROM city
CROSS JOIN country;
PostgreSQL - DML
By Yhoan Andres Galeano Urrea




