字串
Outline
- Trie
- KMP
- Hash
Trie
Trie
- 字典樹
- 一種樹狀結構,可以儲純一堆字串
- 因為字元種類很少,所以可以建成一棵樹
- 當然也可以存 0-1 位元
每條邊表示要加的字元,每個節點代表從根開始走形成的字串。
h
he
hel
hell
hello
k
ke
key
ken
+h
+e
+l
+l
+o
+k
+e
+y
+n
假設今天要加入 "bee", "yee", "yes", "yuhung", "zap", "zaps"
b
be
bee
y
ye
yee
yes
yu
yuh
yuhu
yuhun
yuhung
z
za
zap
zaps
+b
+e
+e
+y
+e
+e
+s
+u
+h
+u
+n
+g
+z
+a
+p
+s
Trie 實作
- 簡單來說就是每個節點維護 26種字元下一個的位置
最長共同前綴
- 給你 \(n\) 個字串,令\(lcp(i,j)\) 為字串 \(i,j\) 的前綴
- 之後對字串 \(s_i\) 輸出\(max\{lcp(i,j)\}_{j<i}\)
- \(1\leq n,S(\sum_{s_i})\leq 10^6\)
最長共同前綴
- 把這些字串插入到字典樹吧,那這樣詢問時就只要按照字典樹依序走訪,直到沒有相同字源就停止。
- 得到的就會是最長共同前綴
- 插入、詢問時間複雜度會是 \(O(|s_i|)\)
- 總時間複雜度會是 \(O(S)\)
- 空間複雜度會是 \(O(26 \cdot \max(s_i))\)
最長共同前綴
struct Node {
vector<int> c;
Node(): c(26, -1) {}
int &operator()(char nxt) {
return c[nxt - 'a'];
}
};
vector<Node> trie;
int add(string &str, int now, int id) {
// cout<<now<<"now"<<id<<"id\n";
if (id == -1) {
id = tmp++;
}
if (now == str.size())
return id;
trie[id](str[now]) = add(str, now + 1, trie[id](str[now]));
return id;
}
int search(string &str, int now, int id) {
if (now == str.size())
return now;
char c = str[now];
if (trie[id](c) != -1) {
return search(str,now+1,trie[id](c));
}
return now+1;
}LOJ 10050 The XOR Largest Pair
- 給你一個序列 \(a_1, a_2, . . . , a_n\),求 \(\max\{a_i ⊕ a_j\}\)。
- \(n ≤ 10^5、a_i < 2^{31}\)
LOJ 10050 The XOR Largest Pair
- 思考一下對 \(x\) 的 xor 最大配對 \(a\) 有甚麼性質?
- xor 是只有當兩個位元恰是 0,1 個一時才會是1,其餘為0
- 要讓數字最大高位元要儘量是 1
- 也就是說從第一個位元開始, \(a\) 要盡量和 \(x\) 恰好相反
- Trie 搞定
LOJ 10050 The XOR Largest Pair
//Author: Woody
#include <bits/stdc++.h>
#define int long long
#define mp make_pair
#define eb emplace_back
#define rep(n) for(int i=0;i<n;i++)
#define rep2(n) for(int j=0;j<n;j++)
#define F first
#define S second
#define all(v) v.begin(),v.end()
#define SZ(x) (int)(x.size())
#define lowbit(x) (x&-x)
#define SETIO(s) ifstream cin(s+".in");ofstream cout(s+".out");
#define quick ios::sync_with_stdio(0);cin.tie(0);
using namespace std;
typedef pair<int, int> pii;
template <class t1, class t2>
inline const pair<t1, t2> operator + (const pair<t1, t2> &p1, const pair<t1, t2> &p2) {
return pair<t1, t2>(p1.F + p2.F, p1.S + p2.S);
}
template <class t1, class t2>
inline const pair<t1, t2> operator - (const pair<t1, t2> &p1, const pair<t1, t2> &p2) {
return pair<t1, t2>(p1.F - p2.F, p1.S - p2.S);
}
const int INF = 1e18;
const int N = 1e5 + 7;
const int D = 31;
string s[N];
string bin(int num) {
string S;
while (num > 0) {
if (num & 1)
S += "1";
else
S += "0";
num >>= 1;
}
S += string(D - S.size(), '0');
reverse(all(S));
return S;
}
int tmp = 1;
struct Node {
vector<int> c;
Node(): c(2, -1) {}
int &operator()(char nxt) {
return c[nxt - '0'];
}
};
vector<Node> trie;
int add(string &str, int now, int id) {
// cout<<now<<"now"<<id<<"id\n";
if (id == -1) {
id = tmp++;
}
if (now == str.size())
return id;
trie[id](str[now]) = add(str, now + 1, trie[id](str[now]));
return id;
}
int search(string &str, int now, int id) {
if (now == str.size())
return 0;
char c = '1' - str[now] + '0';
if (trie[id](c) != -1) {
return (1 << (D - now - 1)) + search(str, now + 1, trie[id](c));
}
return search(str, now + 1, trie[id](str[now]));
}
signed main() {
quick
trie.resize(2e6 + 7);
int n;
cin >> n;
for (int i = 0; i < n; i++) {
int a;
cin >> a;
s[i] = bin(a);
// cout<<s[i].size()<<"l\n";
add(s[i], 0, 0);
}//return 0;
int ans = 0;
for (int i = 0; i < n; i++) {
int P = search(s[i], 0, 0);
// cout<<ans<<","<<P<<"P\n";
ans = max(ans, P);
}
cout << ans << "\n";
return 0;
}KMP (Knuth-Morris-Pratt)
- 給字串 \(T\) 和目標字串 \(S\)
- 要怎麼知道 \(T\) 出現幾次 \(S\) 和出現位置
- \(O(|S||T|)\) 枚舉?
- \(T\) = ababbaabababbaababbabaa
- \(S\)=ababbaababbabaa









- 但其實有很多次不需比
- 當知道第一次是匹配前十個的情況下
- 下一次一定從對齊四個繼續試試看
- 目標字串有特殊性質


Failure function
- \(F(i)=\begin{cases} \max\{k: P[0,k-1]=P[i-k+1,i] ,k < i+1 \} & {if \ i \ \neq 0 \ and \ k \ exists} \\ 0 & {otherwise} \\ \end{cases}\)
- 其實就是位置 \(x\) 的次長前後綴
KMP
- 先假設有了 \(F(x)\) , 那要怎麼做匹配?
- \(F(x)\) 存的是前面的共同長度,因此當位置 \(x+1\) 配對失敗時,可以把 \(x+1\) 和 \(F(x)\) 位置貼齊繼續匹配
KMP
- 實際匹配過程如下:
- 當位置 \(P_i \neq T_{pos} , pos=F(pos-1)\)
- 持續進行直到等號成立,成立後則往下一位置繼續看
- 若匹配完全則成功,當作匹配失敗繼續找
KMP
int KMP(string a,string b){
vector<int> f=buildf(b);
int ans=0;
int n=sz(a);
int m=sz(b);
int pos=0;
rep(i,0,n-1){
while(a[i]!=b[pos]&&pos){
pos=f[pos-1];
}
if(a[i]==b[pos]) pos++;
if(pos>=m){
ans++;
pos=f[pos-1];
}
}
return ans;
}KMP
- 時間複雜度呢 (\(O(n^2)\)?)
- 雖然pos持續往回的迴圈時間不好估
- 但可以保證 \(F(x)<x\), 因此會遞減
- 但只有在配對成功時會增加
- 時間複雜度 \(O(n)\)
KMP
- 有了 \(F(x)\) 我們會做匹配
- 那要如何建 \(F(x)\)
- 假設已算完 \(F(0) \sim F(x-1)\)
- 當 \(P[x]=P[F(x-1)+1]\) \(F(x)=F(x-1)+1\)
- 反之則代表配對失敗,那就和前面一樣,從 Failure function 繼續往前找
- 和匹配 code 很類似
KMP
vector<int> buildf(const string&p){
int n=sz(p);
vector<int> f(n);
int pos=0;
rep(i,1,n-1){
while(p[i]!=p[pos]&&pos){
pos=f[pos-1];
}
if(p[i]==p[pos]) pos++;
f[i]=pos;
}
return f;
}int KMP(string a,string b){
vector<int> f=buildf(b);
int ans=0;
int n=sz(a);
int m=sz(b);
int pos=0;
rep(i,0,n-1){
while(a[i]!=b[pos]&&pos){
pos=f[pos-1];
}
if(a[i]==b[pos]) pos++;
if(pos>=m){
ans++;
pos=f[pos-1];
}
}
return ans;
}Rolling Hash
字串匹配的唯一選擇
Rolling Hash
- \(H(s)=\sum_s(s_i \cdot p^{n-i}) \pmod{M}\)
- \(p\) 通常選字元數量以上的質數,或是隨機選
- \(M\) 會是 int 範圍內的質數
- ex:
- \(10^9+7,998244353,2147483647,19260817\)
Rolling Hash
- \(H(s)=\sum_s(s_i \cdot p^{n-i}) \pmod{M}\)
- 可以想像成倒三角形

區間詢問呢
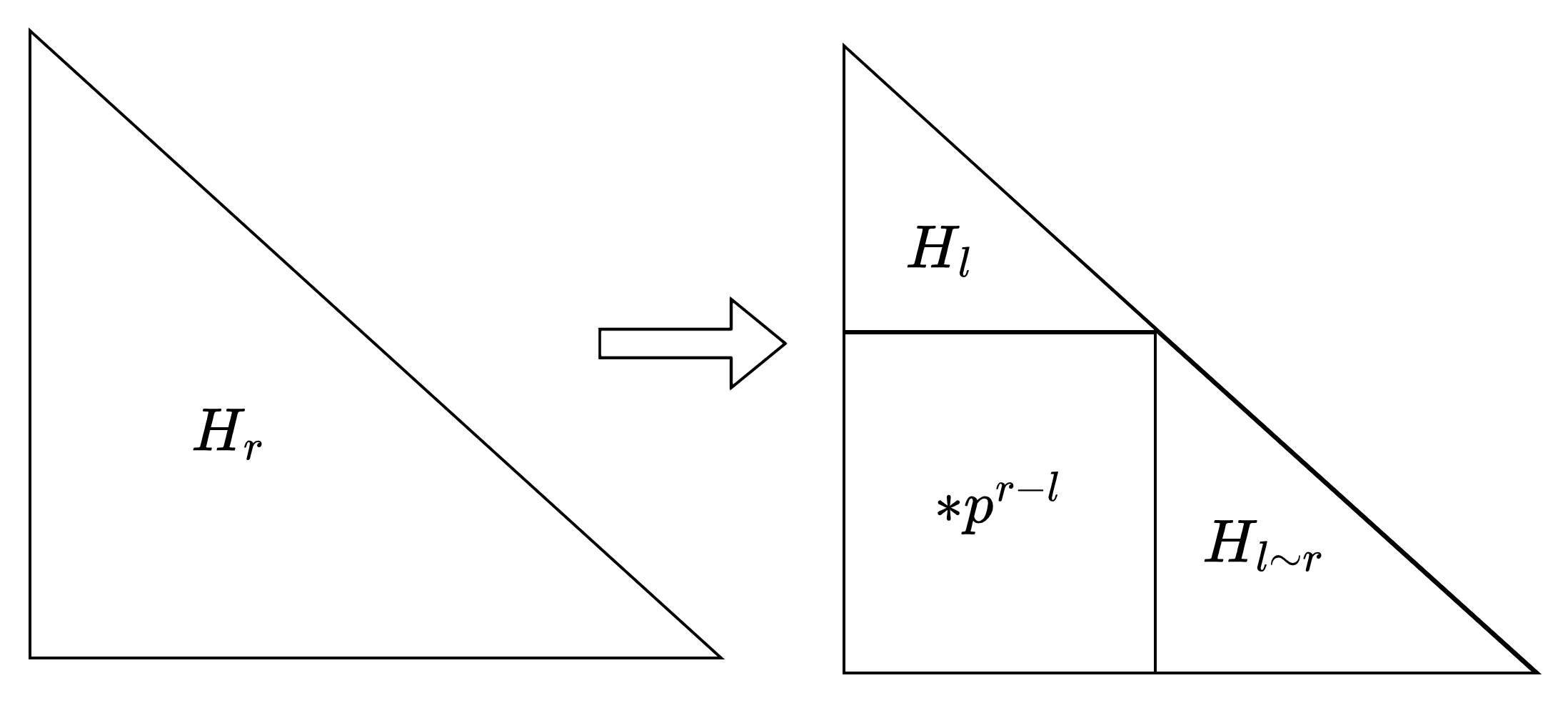
\(H_{l\sim r}=H_r-H_l\cdot p^{r-l}\)
Birthday Attack
- 一個房間至少要有 \(n\) 個人,存在兩個人是同一天生日機率 \(>50\%\)
- \(n=23\)
- 當 \(n\) 個人均勻從 \(1\sim N\) 選一個數字
- 存在兩人選擇數字相同 \(p(n)\sim 1-1/exp(n^2/2N)\)
Birthday Attack
- 一個房間至少要有 \(n\) 個人,存在兩個人是同一天生日機率 \(>50\%\)
- \(n=23\)
- 當 \(n\) 個人均勻從 \(1\sim N\) 選一個數字
- 存在兩人選擇數字相同 \(p(n)\sim 1-1/exp(n^2/2N)\)
避免碰撞
- \(n=10^5, M=10^9+7\)
- \(p(n)=1-1/exp(n^2/2M) \sim 99\%\) ?
- 既然一個模數不夠,那就兩個
- 求字串 \(S\) 的最長迴文
- \(1 \leq |S| \leq 10^6\)
- 迴文的性質就是從中間切開後左右兩字串是相等的
- 也就是 \(Hash_{pref}(L)=Hash_{suff}(R)\)
- 所以可以暴力枚舉中間點,剩下要怎麼找到最長的左右相等字串?
- 二分搜
#pragma GCC optimize("O3,unroll-loops")
#pragma GCC target("avx,popcnt,sse4,abm")
#include<bits/stdc++.h>
#define int long long
#define quick ios::sync_with_stdio(0);cin.tie(0);
#define rep(x,a,b) for(int x=a;x<=b;x++)
#define repd(x,a,b) for(int x=a;x>=b;x--)
#define lowbit(x) (x&-x)
#define sz(x) (int)(x.size())
#define F first
#define S second
#define all(x) x.begin(),x.end()
#define mp make_pair
#define eb emplace_back
using namespace std;
typedef complex<int> P;
#define X real()
#define Y imag()
typedef pair<int,int> pii;
void debug(){
cout<<"\n";
}
template <class T,class ... U >
void debug(T a, U ... b){
cout<<a<<" ",debug(b...);
}
const int N=1e6+7;
const int INF=1e18;
pii operator + (pii a,pii b){
return mp(a.F+b.F,a.S+b.S);
}
pii operator + (pii a, int b){
return mp(a.F+b,a.S+b);
}
pii operator - (pii a,pii b){
return mp(a.F-b.F,a.S-b.S);
}
pii operator * (pii a,int k){
return mp(a.F*k,a.S*k);
}
pii operator * (pii a,pii b){
return mp(a.F*b.F,a.S*b.S);
}
pii operator % (pii x,pii y){
return mp(x.F%y.F,x.S%y.S);
}
bool operator == (pii a,pii b){
return a.F==b.F&&a.S==b.S;
}
const pii Mod={1234567891,998244353};
int p;
pii pw[N];
pii pref[N];
pii suff[N];
pii q(int l,int r,bool pf){
if(pf){
return (pref[r]-pref[l-1]*pw[r-l+1]%Mod+Mod)%Mod;
}
return (suff[l]-suff[r+1]*pw[r-l+1]%Mod+Mod)%Mod;
}
bool ok(int posl,int pos,int pos2,int posr,int n){
if(posl<=0||posr>n) {return false;}
return q(posl,pos,true)==q(pos2,posr,false);
}
bool ok(int ln,int pos,int pos2,int n){
return ok(pos-ln,pos,pos2,pos2+ln,n);
}
int qry(int pos,int pos2,int n){
int l=0;
int r=n+1;
while(l+1<r){
int mid=(l+r)>>1;
if(ok(mid,pos,pos2,n)) l=mid;
else r=mid;
}
return l;
}
signed main(){
quick
string s;
cin>>s;
int n=sz(s);
s=' '+s;
mt19937 rand;
p=rand()%17+29;
pw[0]=mp(1,1);
rep(i,1,n){
pw[i]=pw[i-1]*p%Mod;
}
rep(i,1,n){
pref[i]=(pref[i-1]*p+(s[i]-'a'+1))%Mod;
}
repd(i,n,1){
suff[i]=(suff[i+1]*p+(s[i]-'a'+1))%Mod;
}
int L,R;
L=R=0;
int ans=0;
rep(i,1,n){
int l1=qry(i,i,n);
if(l1*2+1>ans){
ans=l1*2+1;
L=i-l1;
R=i+l1;
}
if(i+1<=n&&s[i]==s[i+1]){
int l2=qry(i,i+1,n);
if(l2*2+2>ans){
ans=l2*2+2;
L=i-l2;
R=i+l2+1;
}
}
}
rep(i,L,R) cout<<s[i];cout<<"\n";
return 0;
}
字串演算法
By yuhung94



