Apache Spark overview
MapReduce reprise
Welcome to Scala
trait MapReduceAlgorithm[K1, V1, // Generics
K2, V2,
K3, V3] {
// One key-value pair to list of key-value pairs
// (K, V) means pair
def mrMap(key: K1, value: V1): Seq[(K2, V2)]
// ....Magic in between...
// list of values to list of key-values
def mrReduce(key: K2, values: Seq[V2]):
Seq[(K3, V3)]
// ....
}WordCount
class WordCountMapReduce
extends MapReduceAlgorithm[Long, String, String, Int, String, Int] {
def mrMap(key: Long, line: String) =
line
.split("\\W+") // Seq[String]
.map { x => (x, 1) } // Seq[(String, Int)]
def mrReduce(word: String, count: Seq[Int]) =
Seq(
(word, count.sum) // (String, Int)
) // Seq[String, Int]
}MR flaws
- Counterintuitive
- Disk IO
- Imperative on high-level
Aside: Tachyon

Scala functional collections
Lingua franca of functional languages
Using higher-order functions to be declarative
val numbers = (1 to 1000) // 1, 2, 3, 4, .... 1000
val twice = numbers map { x => x * 2 } // 2, 4, 6, ... 2000
val even = numbers filter { x => x % 2 == 0 } // 2, 4, 6, ... 1000
val sum = numbers reduce { (x, y) => x + y } // 500500
val craziness = numbers flatMap { x => (1 to x) } // 1, 1, 2, 1, 2, 3, ... 1000Applicable to number of collections
- option (list of 0 or 1 element)
- single-linked list
- set
- array
- queue
- par*
Spark RDD
Quiz: what is an “RDD”?
- distributed collection of objects on disk
- distributed collection of objects in memory
- distributed collection of objects in Cassandra
Resilient Data Set
trait RDD[T] {
// Public API
def filter(p: T => Boolean): RDD[T]
def map(m: T => B): RDD[B]
def flatMap(m: T => Seq[B]): RDD[B]
// ...
// Implementation details
}Transforms
trait RDD[A] {
def map(m: A => B): RDD[B]
def filter(p: A => Boolean): RDD[A]
def flatMap(m: A => Seq[B]): RDD[B]
def sample: RDD[A]
def union(other: RDD[A]): RDD[A]
def intersection(other: RDD[A]): RDD[A]
def distinct: RDD[A]
def pipe(command: String): RDD[String]
def cartesian(other: RDD[B]): RDD[(A, B)]
}Pair Transforms
trait PairRDD[K,V] extends RDD[(K, V)] {
def groupByKey: RDD[K, Seq[V]]
def reduceByKey(f: (V,V)=>V): PairRDD[K, V]
def aggregateByKey(zero: W, m: (W, V) => W, p: (W,W) => W): PairRDD[K, W]
def join(other: PairRDD[K, W]): PairRDD[K, (V,W)]
def cogroup(other: PairRDD[(K,W)]): PairRDD[K, (Seq(V), Seq(W))]
}Actions
trait RDD[A] {
def reduce(f: (A, A) => A): A
def collect: Seq[A]
def count: Long
def first: A
def take(n: Int): Seq[A]
def takeSample: Seq[A]
def takeOrdered: Seq[A]
def saveAsTextFile(file: String)
def saveAsSequenceFile(file: String)
def saveAsObjectFile(file: String)
}Word Count
val sc: SparkContext // This is our cluster
val linesRDD = sc.textFile("hdfs://file.txt")
val counts = linesRDD.flatMap { x => x.split("\\W+") }
// I would merge flatMap and map in real life
.map { x => (x, 1) }
.reduceByKey { (x, y) => x + y }
// Counts is an RDD
counts.saveAsTextFile("hdfs://counts.txt")
// Action
counts.collect // Another action - may not fitCaching
val words = linesRDD.flatMap(x => x.split("\\W+")).cacheUnder the hood
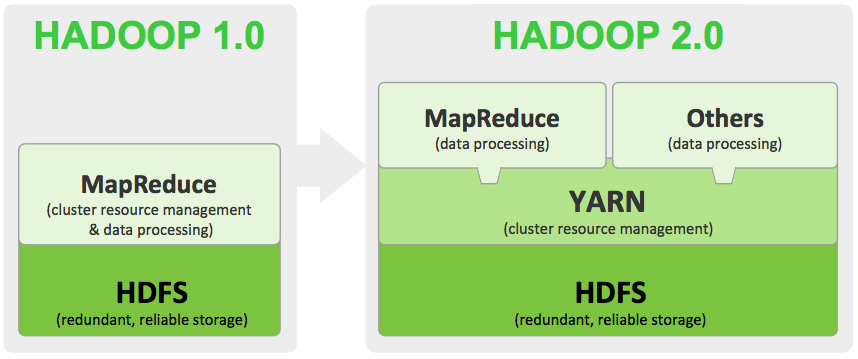
Title Text
SQL
Streaming
Machine learning
Graphs
deck
By Yura Taras



