Scaling your Rails
with AWS Auto Scaling
gotchas and tips
Abhishek Yadav
Ruby developer and meetup organizer
Dec 2020
Scaling ... the content
-
Intended audience / relevance
- The various species of scaling (horizontal, vertical, web app, static website etc)
-
The constraints
- Original architecture
- Scaling/cost expectations
- You are in a better/worse place if ...
-
The strategy - part 1
- The maths
- The endpoint profile
- Testing
Scaling ... the content
-
The strategy - part 2
- The load-balancer
- The web worker
- The database
-
The product: AWS auto scale groups
- Caliberating
- Testing
-
The aftermath
- Deployments
- Price optimization
- The role of code
- Things to disregard, forget, before we even begin
Scaling ... the intended audience
Reddit: 54 million users per day
few paying users a month
my blog
you are somewhere here
Scaling ... the intended audience
Your traffic looks like this
days of a month
no. of users
$
Scaling ... the intended audience
You need
Sudden scaling
Ad-hoc scaling
Unplanned scaling
Scaling ... the constraints
- The existing architecture
- The scale expectation
- The costs
Scaling ... the constraints
The existing architecture
Puma
Nginx
Sidekiq
DB
Redis
~> Puma can't be scaled horizontally 👎
~> Db is separate 👍
~> No Heroku 👎
AWS EC2
RDS
Scaling ... the constraints
- The existing architecture
- The scale expectation
- The costs
~> How many users are expected to arrive ? 👎
~> How quickly will they arrive ? 👎
~> When will they arrive ? 👍
~> Can we fail gracefully ? Shutdown some parts? Show notices like Reddit ? 👎
Scaling ... the constraints
- The existing architecture
- The scale expectation
- The costs
How much can we afford ?
~> Not a venture funded business - costs have to be under control 👎
~> Incoming business allows some leeway 👍
Scaling ... the first strategy
- Puma threads: p
- Most common response time per request: t
- No. of Puma workers we can run: w
- Peak No. of users arriving at once: n
- The timeout: tx (usually 30 seconds)
Max requests we can serve at any point: p*w
The next batch of p*w requests will have to wait t seconds
No one can be made to wait more than the time out time (tx)
The Arithmetic
Scaling ... the first strategy
Peak viewers: 1500
Response time: 500ms
No. of Puma threads: 15
No. of Puma workers: 10
We can handle 15 * 10 = 150 requests at a time
The next 150 wait for 500ms
Batches in waiting: 1500/150 - 1: 9
The last batch waits for 9 * 500ms: 4.5 seconds
Not so bad 👍
The Arithmetic - a rough example
Scaling ... the first strategy
The Arithmetic - technical constraints
- Puma threads cant go beyond a number - rarely above 32
- Puma workers should match the number of cores in the VM. Practically, it can be 2 or 4 or 8
- Average/Median/worst response times might be widely different, and may not fit
So for the previous example -
- For 10 workers, we'll need 5 VMs (with 2 cores each). (Or 10 with single core)
- We have to be sure about the 500ms response time.
Scaling ... the first strategy
Therefore, the architecture should become somewhat like this:
Puma
Nginx
Sidekiq
DB
Redis
AWS EC2
RDS
Puma
Puma
Puma
Puma
Scaling ... the first strategy
Puma
Nginx
Sidekiq
DB
Redis
AWS EC2
RDS
Puma
Puma
Puma
Puma
And we should be able to add Puma workers quickly as needed
Scaling ... the first strategy
This strategy failed miserably
Me at 3am: 😓😢
while also questioning my life's choices
Scaling ... the first strategy
This strategy failed miserably
Because:
- Nginx should also scale
- Database should also scale
- Architecture should match the request profile
The last point actually worked, more on that later
Scaling ... the first strategy
Nginx
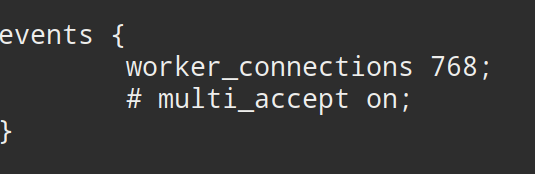
Default setting
By default -
- Each Nginx worker can handle 768 connections at a time
- There are 2 Nginx workers
Which means -
- Nginx gives up after 1536 connections !
Scaling ... the first strategy
Nginx
Default setting
- Defaults can be changed
- But not without planning and testing
And also:
cmd$ ulimit -Sn 1024
Scaling ... the first strategy
Nginx - conclusions
- Nginx on defaults is not that scalable
- Scaling Nginx needs research and testing
- This limitation affects proxied setups more.
For serving static content, default Nginx can scale better
Scaling ... the first strategy
The DB
- Database crashes when overloaded with connections
- Pooling at Rails level is of no use here
-
RDS only manages the database for you.
- It does not scale the database
- The scaling arithmetic is still your job
- Databases usually need to be scaled vertically
Scaling ... the first strategy
The DB - connections
-
How many connections can my Postgresql handle:
-
LEAST({DBInstanceClassMemory/9531392},5000) - With that we'll need about 8 Gb RAM for a 1000 connections. That's an xlarge VM
-
- A 1500 request don't always throw that many DB requests. Its much lower generally. But it also depends on how badly queries are written. N+1s can even make it worse
Ref: https://sysadminxpert.com/aws-rds-max-connections-limit/
Scaling ... the first strategy
The request profile
- Every endpoint gets a different amount of traffic
- Some endpoints are more important than others
- Load balancing can be skewed based on this knowledge
unused features
Highest
Lowest
Traffic
heartbeats
admin functions
login page
suboptimal Api endpoint
Imaginary example
Scaling ... the first strategy
The request profile
Therefore:
- High traffic endpoints can be routed to more Pumas
- Important endpoints can be assigned dedicated VMs (like login)
- Very high traffic endpoints can even have their own separate Nginx
Scaling ... the second strategy
- Use AWS Auto scaling groups
- Use AWS Load Balancer
- Keep the DB scaled up conservatively
- Test and caliberate using ab
- Use cache where possible
Scaling ... the second strategy
The AWS Auto scale groups
The idea is -
- Set up a group of VMs
- Define a launch template - so it knows how to create VMs
- Define an auto-scaling policy - so it know when to scale up/down
- Associate a load-balancer
The magic lies in the auto-scaling policy
Scaling ... the second strategy
The AWS Load Balancer
- There are three kinds of load balancers AWS offers
- Application Load Balancer (ALB) and Classic Load Balancer (CLB) are applicable here
- For ALB: load == request traffic
For CLB: load == VM health (CPU usage) - Pick the ALB
- CLB is slightly easier to setup, but incredibly hard to caliberate
Scaling ... the second strategy
The AWS Load Balancer - ALB
Read up on these to configure ALB -
- Target groups
- Availability zones
- Listeners
- ACM (Amazon certificate Manager) - to handle SSL
Scaling ... the second strategy
The AWS Auto Scaling
Example:
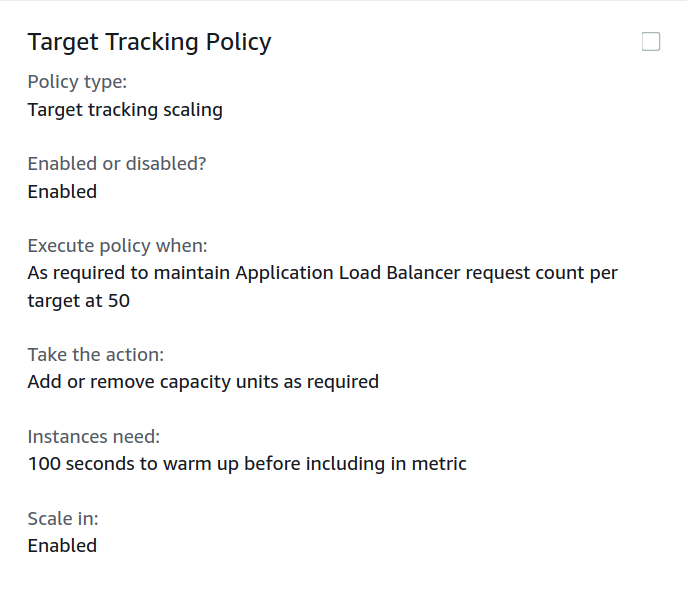
target == Puma VM
Scaling ... the second strategy
The AWS Auto Scaling - calibration/testing
To confirm that scaling actually happens when needed
- Pick an endpoint - with high traffic, median response times, with database calls
- Load it using Apache Bench (ab) with varying concurrency (200, 500, 1000, 1500, 2000 etc)
- Run the tests for 5-6 minutes in a set - so that auto scaling gets the chance to react
Note the following for each test run:
- Failed responses (should be low)
- 95, 99 percentile times
- Number of VMs in the Auto Scale group
- CPU/Connection numbers in the DB
Scaling ... the second strategy
The AWS Auto Scaling - calibration/testing
For the DB:
- After sufficient stress, it will be clear how much the db can hold
- It can usually go further than the max-connection limit, but not much
- There should be a reasonable upper bound on auto scaling such that the max-connection limit is not breached. A database proxy for connection pooling is a better approach
Scaling ... the second strategy
The AWS Auto Scaling - the results
Things worked fine 🥳
- Scaling up and down happen automatically, as expected
- There is no need to manually monitor times of peak
Scaling ... the aftermath
- Deployments have become complicated
- Quick deployments are difficult
- Log gathering needs additional effort.
- Database proxy is needed to be doubly sure
- Cost analysis needs to be done
- Code needs to be optimized
Scaling ... the conclusions/lessons
- Cloud services are hard to configure, but a better investment of effort
- Always plan for the database
- Don't get swayed by language stereotypes (Ruby is slow)
Testing, monitoring lead to better decision making - Optimal code and caching can have critical impact on scaling
Scaling your Rails with AWS Auto scaling
By Abhishek Yadav




