

abdellah Chkifa
Some of my presentations
Abdellah CHKIFA
abdellah.chkifa@um6p.ma
1. Gradient Descent
2. Back-propagation
Gradient Descent: an intuitive algorithm
objective function (also called loss function or cost function etc.)
initial guess
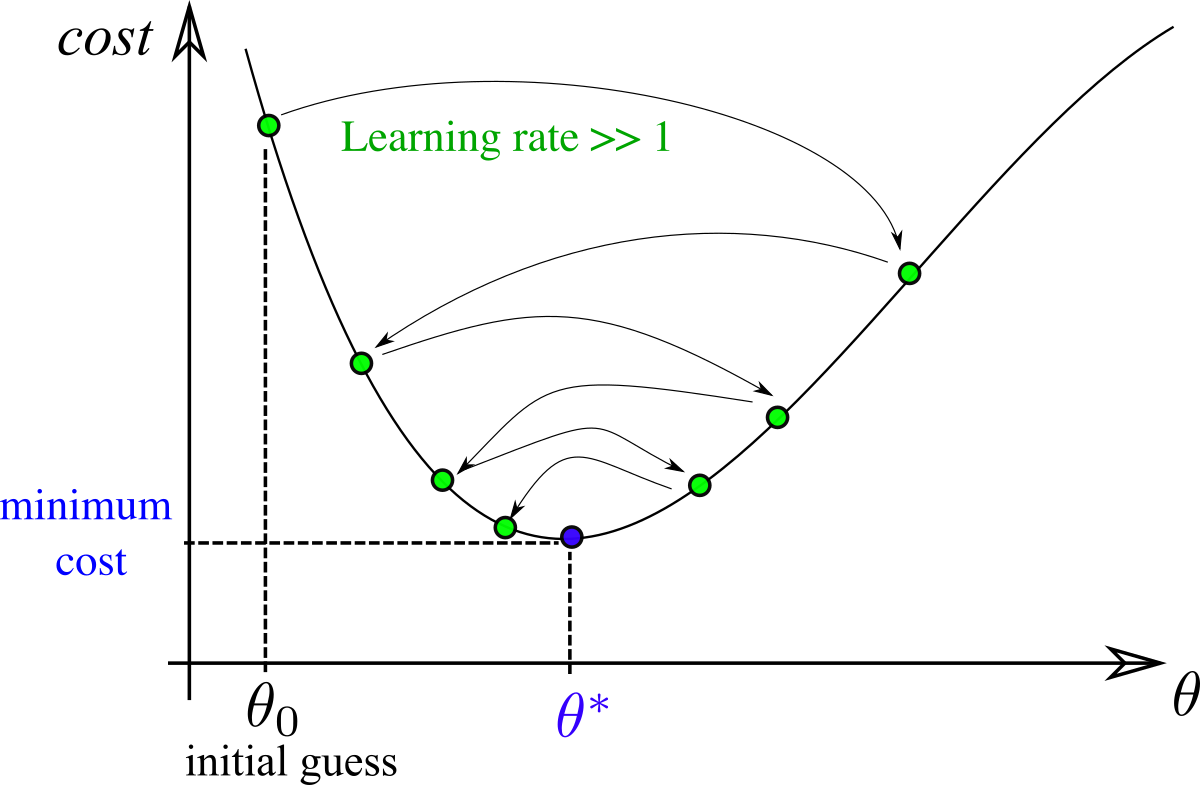
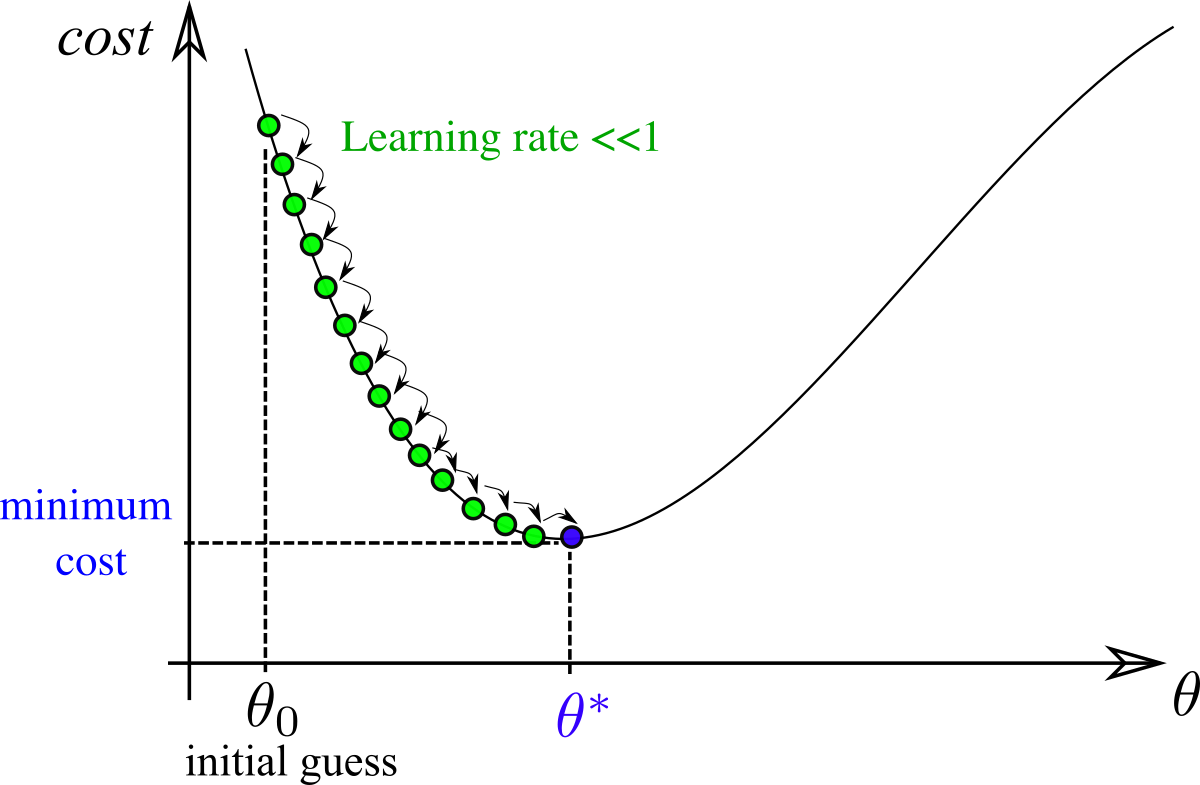
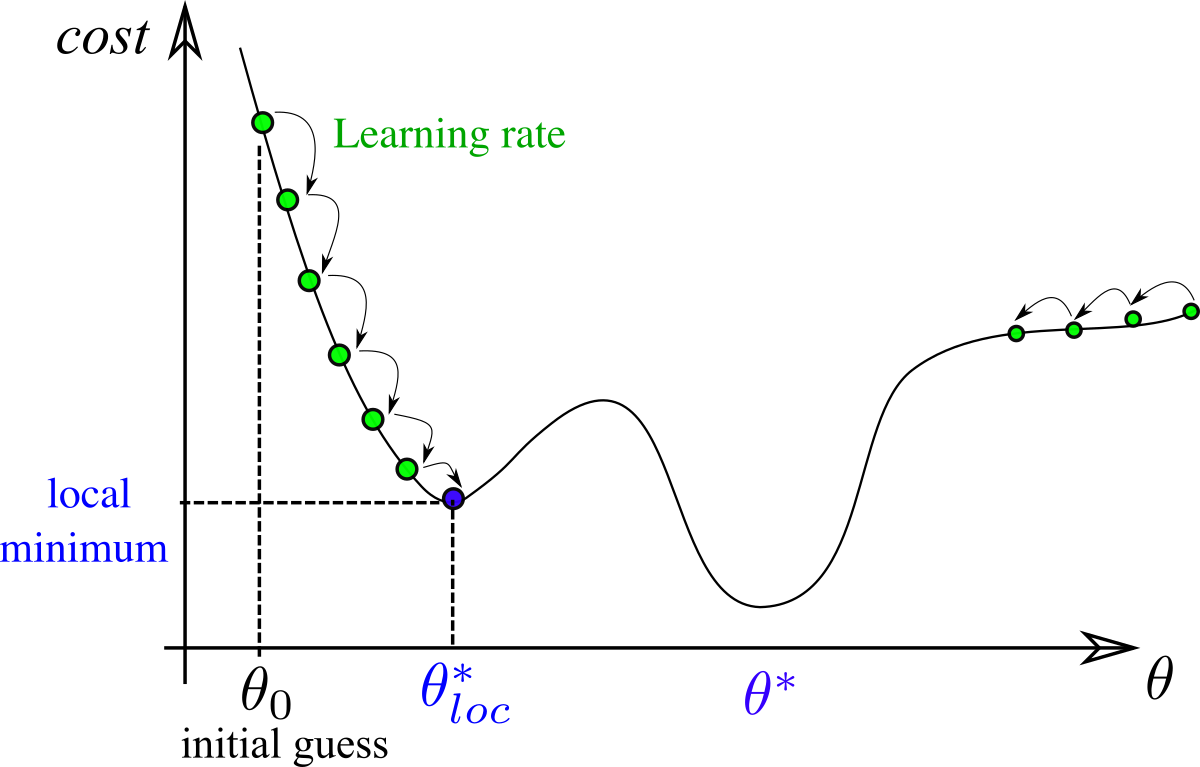
Importance of learning rate
We consider GD applied to
with
and rates
initial guess
f convex:
f L-smooth:
Suppose that f is convex and L-smooth. The gradient descent algorithm with η < 1/L converge to θ* and yields the convergence rate
Theorem
initial guess
f μ-strongly convex:
suppose that f is μ-strongly convex and L-smooth. The gradient descent algorithm with η < 1/L converge to θ* with
Theorem
μ-strong convexity can be weakened to Polyak-Lojasiewicz Condition 🔗
Pros and Cons
Reference
https://www.stat.cmu.edu/~ryantibs/convexopt/
By abdellah Chkifa


