
You Write
Like
You Eat
Angelo Basile
June 11, 2019
Albert Gatt
Malvina Nissim
Stylistic variation
as a predictor
of social stratification
So freaking good. That’s all I’m gonna say. Don’t believe me? Walk
into the place and smell it. [. . . ] Will definitely go back.,Fresh, hand-
made pepperoni rolls. . . .. oh yeah. [...] Parking sucks, but I’m not taking off a point for that! Their marinara is dee-lish,Super tasty!!!
Let me start off saying that 2 years ago my husband and I had a spectac-
ular dinner at L’Atelier by Joel Robuchon and finally got the "Time"
to visit Joel Robuchon.We got a limo service and a nice tour inside
the mansion of Robuchon which was very memorable and the hostess
escorted us to the dining area. Decore: In comparison to L’Atelier this
place was much more chic and elegant. However, I still loved the idea
to see all the chefs preparing and decorating my plates at L’Atelier.
The Problem
The Problem
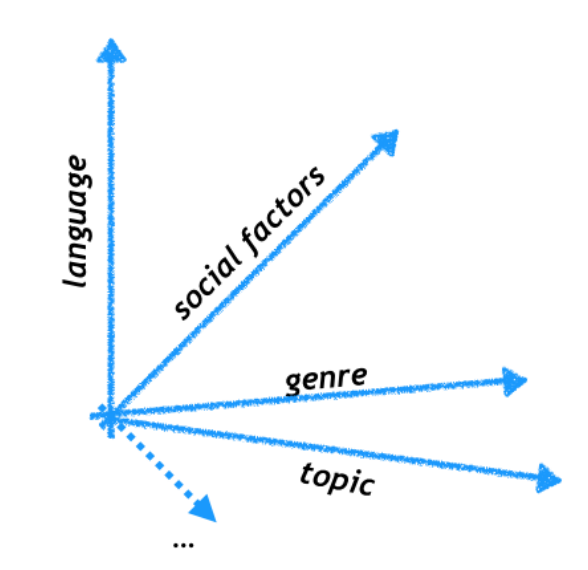
Language variation
patterns of variation in language use are explainable (statistically) at least
in part with reference to social class
Language variation
(Labov, 1962)
age
gender
location
psychology
register
Related work
Background




fourth floor
Theoretical motivation
Do speakers from different social classes use syntax in a different way?
Practical motivation
- Build a new prediction tool
- Build better NLP tools, more resilient to bias issues
Framing
Given a set of labelled texts, grouped by author, predict the label from text.
Text Classification
Data

TEXT
$$
AUTHOR
Distant Supervision
Hypothesis: use the price range of a restaurant as a proxy for the social class of its reviewers
(Historical note: see Labov, 1966)
All the reviews written by an author for different restaurants.
$
$$
$$$
$$
$$
$$
$$
$ - 1
$$ - 5
$$$ - 1
$$$$ - 0
$$
X
Y
LEARN
LABELLING


Education
Readability Metrics
Hypothesis: scores will be sorted (in increasing or decreasing order) from class 1 to 4
Readability Metrics
| Metric | $ | $$ | $$$ | $$$$ | std |
|---|---|---|---|---|---|
| Automated Readability Index | 6.48 | 6.52 | 6.59 | 6.91 | 0.17 |
| Coleman Liau Index | 7.58 | 7.76 | 8.07 | 8.41 | 0.32 |
| Dale-Chall Score | 6.65 | 6.76 | 6.94 | 7 | 0.14 |
| Flesch-Kincaid Ease | 5.42 | 5.55 | 5.59 | 5.82 | 0.14 |
| Gunning Fog score | 13.46 | 13.7 | 14.08 | 14.23 | 0.31 |
| Linsear Write Formula | 6 | 5.8 | 5.83 | 5.72 | 0.1 |
| Lix index | 30.7 | 31.39 | 31.69 | 32.71 | 0.72 |
| Flesch-Reading | 81.06 | 79.93 | 79.1 | 77.39 | 1.34 |
|---|
(all results are significant at p < 0.01)
LANGUAGES
Automatically detect the language of the reviews and assign a language code to an author. Assume that each author writes in only one language.
Work on English only
Use non-English data for multi-lingual experiment
Filtering
An example:
| id | labels | Y |
|---|---|---|
| 1 | $: 15 - $$$$: 1 | $ |
| 2 | $: 15 - $$$$: 14 | $ |
| entropy |
|---|
| 0.23 |
| 0.69 |
Solution: discard authors whose entropy is below mean.
Filtering 2
Discard authors that have less than 40 reviews.
DATA SET
512 authors, 4 balanced classes, more or less clean (i.e. parsable) representative English texts
From ~1 million authors and ~5 millions reviews to...

Features & Modelling
Bag-of-Words (and characters)
POS Tags
Dependency Trees
Abstract features
Readability Scores
Logistic Regression
Convolutional Network
Named Entities only
Words and c h a r a c t e r s
NNS CONJ NNS
[(NNS, cc, CONJ), ...
Cvccc_05_True_117...
0.80
Las Vegas
MODELS
FEATURES
VARIATION?
Dependency Tree

Words
Cvccc - shape
117 - frequency
05 - length
True - alphanumeric?
Cvccc_05_True_117
Bleaching
Results

random
lexical
embeddings
NER
POS
syntax
abstract features
readability scores
all features
CNN w/ abstract
CNN w/ syntax
lexical multi-lingual
CNN multi-lingual
0.25
0.63
0.39
0.38
0.31
0.32
0.55
0.33
0.49
0.52*
0.46*
abstract multi-lingual
0.28
0.25
0.54*
features
accuracy
LR
NN
| $ |
| fast |
| kids |
| coffee |
| customer |
| clean |
| they |
| order |
| came |
| always |
| pizza |
| $$ |
| tried |
| happy |
| staff |
| won |
| put |
| phoenix |
| find |
| try |
| place |
| salsa |
| $$$ |
| at |
| clubs |
| wynn |
| music |
| pretty |
| night |
| club |
| vegas |
| buffet |
| hotel |
| $$$$ |
| excellent |
| gras |
| we |
| las |
| steak |
| tasting |
| foie |
| wine |
| course |
| vega |
Conclusions

Abstract features work well

Positive results
There is significant
variation
between social groups
syntactic

Across languages too
What about interaction?
Shortcomings
Data is still noisy
- Account for interaction
- Manually label some data
- Can humans predict social status?
- Build a POS tagger that accounts for social status
Future Work
Lunchbox presentation
By Angelo




