Big Data

André Claudino
https://www.linkedin.com/in/andreclaudino/
https://github.com/andreclaudino
http://t.me/aclaudino
PhD. Física Computacional
(Física Matemática com IA simbólica)
time: IA Front
Interajam!

Bases de dados
Bases regulares
- Pensados para leitura e escrita
- Muitas leituras concorrentes de poucos dados
- Podem ter um ou mais nós
BAses de Big Data
- Mais leitura que escrita
- Leituras e operações de muitos dados
- Precisa de muitos nós
- Arquitetura mestre-trabalhador
Arquitetura
Worker
Réplica
Worker
Réplica
Worker
Réplica
Worker
Réplica
(...)
bases regulares
Worker
Dados
Worker
Dados
Worker
Dados
Worker
Dados
RW
R
R
R
replica set
- Um nó de escrita vários de leitura
- Nós têm suas cópias de dados
- O Acesso é feito no réplica set, não num único nó
Arquitetura
Worker
trabalhador
Worker
Worker
Worker
(...)
Big Data
Worker
Dados distribuídos
- Todo o acesso é feito pelo nó mestre
- Dados estão num sistema distribuído
- Nó mestre delega pros trabalhador
- Trabalhadores só falam com o mestre
Worker
mestre
trabalhador
trabalhador
trabalhador
Consistência
Disponibilidade
(Availability)
Tolerância
-
Consistência:
Acesso sempre ao dado mais recente
-
Disponibilidade:
A base deve estar disponível durante operações
-
Tolerância:
Deve continuar funcionando mesmo que parte dos nós caia.
CT
TD
CD
Teorema CAP
- É possível ter dois ao mesmo tempo, mas não três
Map-Reduce
Processamento
Mapeadores
- Transformam elementos de uma lista de forma independente
- Facilmente escaláveis
- Usados para transformações de linha
- Mantém a dimensão
- Podem ser compostos
(f \circ g)(a) = f(g(a))
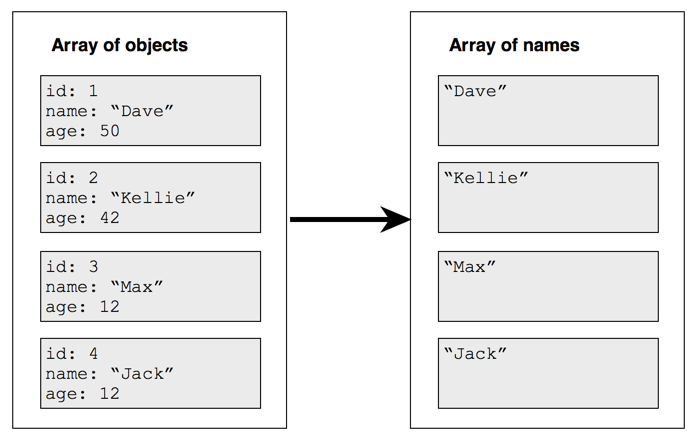
def mapper(person: Person): String = {
return person.name
}Redutores
- Agregam listas num só elemento
- Reduzem a dimensão em 1
- Não podem ser compostos:
(f \circ g)(a) \not = f(g(a))
def menorIdade(idade1: Int, idade2: Int): Int = {
return min(idade1, idade2)
}
val idadesFuncionarios =
Seq(18, 23, 50, 20, 28,
18, 51, 50, 15)
val menorIdade =
idadesFuncionarios
.reduce(menorIdade)
print(menorIdade)
// 18Map-Reduce
Compõe etapas de mapeadores com etapas de redutores.
| Nome | Nascimento | Setor |
|---|---|---|
| Estela | 20/03/2000 | Dev |
| Mário | 30/09/1987 | Infra |
| Breno | 11/01/1986 | Dev |
| Flávia | 10/10/2001 | DB |
| Joaquim | 28/02/1997 | Infra |
// Maior e menor idades dos funcionários
def calculaIdade(pessoa: Pessoa): Int = {...}
val funcionarios: Seq[Pessoa] = Seq(...)
val idades = funcionarios
.map(calculaIdade)
val menorIdade = idades.reduce(min)
val maiorIDade = idades.reduce(max)Map-Reduce
Compõe etapas de mapeadores com etapas de redutores.
| Nome | Nascimento | Setor |
|---|---|---|
| Estela | 20/03/2000 | Dev |
| Mário | 30/09/1987 | Infra |
| Breno | 11/01/1986 | Dev |
| Flávia | 10/10/2001 | DB |
| Joaquim | 28/02/1997 | Infra |
// Conta funcionários no setor específico
def contaFuncionarios(funcionarios:Seq[Pessoas],
setor: String): Int = {
return
funcionarios
.map(functionario => {
if(funcionario.setor == setor)
return 1
else
return 0
})
.reduce(sum)
}Map-Reduce
Versões ocultas
// Operações map
val texto = "Um simples texto, totalmente normal"
val textoCaixaAlta = toUpperCase(texto)
// UM SIMPLES TEXTO, TOTALMENTE NORMAL
val comAcentos = "têxto com palávras chêias de acêntos"
val semAcentos = StringUtils.stripAccents(String input)
// texto com palavras cheias de acentos
val listaDeCoisas: Seq[Coisas] = Seq({...})
listaDeCoisas.count()
val listaDeNumeros: Seq[Int] = Seq({...})
listaDeNumeros.max()
listaDeNumeros.min()
listaDeStrings = Seq("Luke", "eu", "sou", "seu", "pai")
listaDeStrings.mkString(",")
// Luke,eu,sou,seu,pai- Nó mestre delega ações aos trabalhadores
- Trabalhadores operam mapeadores em partes dos dados delegada pelo mestre
- Nós escolhidos, operam redulção e salvam
Map-Reduce
Arquitetura
- Mapeadores podem ser executados de forma independente, nos trabalhadores, compostos ou não, lendo partes dos dados.
- Em casos de falhas no nó, apenas o mapeador falho reinicia
- Escalar implica em adicionar mais nós
Map-Reduce
Trabalhadores
- Cada nó é responsável por parte dos dados
- Os dados devem ser acessíveis por todos os nós
- Preferencialmente, entrada deve estar organizada em vários arquivos e partições
- Preferencialmente, se for de um banco, deve estar organizada em colunas
- Saída será feita por cada processo, então existem vários arquivos
Map-Reduce
Dados
Map-Reduce
Dados
├── domain=brasil.elpais.com
│ ├── data=2019-07-06
│ │ └── hora=22
│ │ └── 7127bcb8c3f6570bb98c23f94dc0d0f2.json
│ ├── data=2019-07-08
│ │ ├── hora=10
│ │ │ └── c9b3e4b269bdb1d3778283a2a0280eca.json
│ │ ├── hora=18
│ │ │ └── 1b17b38eba151a4dfc0519800ce30d87.json
│ │ └── hora=21
│ │ └── 46e0b542c2911c3a79aaf8076a8e1bb0.json
│ ├── data=2019-07-15
│ │ ├── hora=11
│ │ │ └── 28f3ab3d518727b6484d8f2cb86206a2.json
│ │ ├── hora=12
│ │ │ └── a4a684a04bcfcfc51ccb9fa6fe2d4eb5.json
│ │ ├── hora=14
│ │ │ └── 4dfb6dcf40d39e89fe59ac037ab10774.json
│ │ ├── hora=17
│ │ │ └── e3a3e62c9ed402657447405e680fb8ef.json
│ │ ├── hora=21
│ │ │ └── ed49ac957183b66b85d6e283ee124579.json- Muitos arquivos
- Organizados em partições
- Informação vem não só do arquivo, mas da estrutura onde estão
Big Data
By André Claudino



