Construindo pipelines de dados resilientes e eficientes
André Claudino

Dados
Transforma blocos de dados de entrada em blocos de dados de saída
Serviços
Transforma payloads ações impuras e uma saída pro usuário

Dados
Stateful
Serviços
Stateless
S_i = S_j | i \not = j
S_i \not = S_j | i \not = j
Dados
Escalabilidade horizontal planejada na inicialização
Serviços
Escalabilidade horizontal sob demanda
|S| = f(\vec{e}; t)
|S| = c
Dados
- Tempo de requisição longo
- Alta densidade de consumo de recursos
- Resiliência fraca
Serviços
- Tempo de requisição reduzido
- Baixa densidade de consumo de recursos
- Alta resiliência
Aprendendo com microserviços
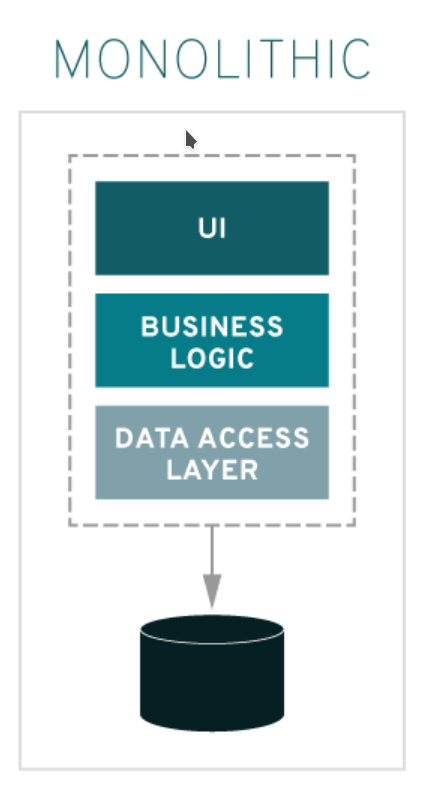
Monolitos
Softwares responsáveis por um grande aspecto do negócio. Como toda uma área ou gerência.
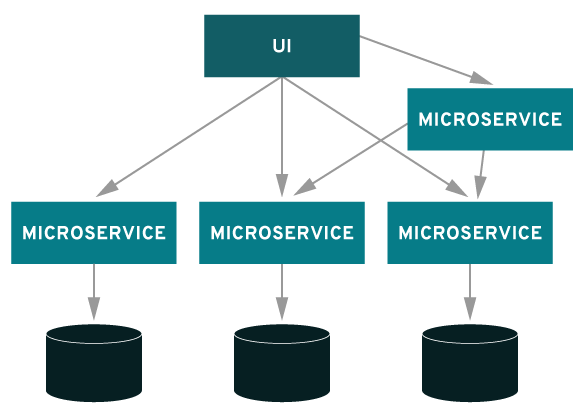
Microserviços
Vários microserviços que juntos representa um pequeno aspecto do negócio.
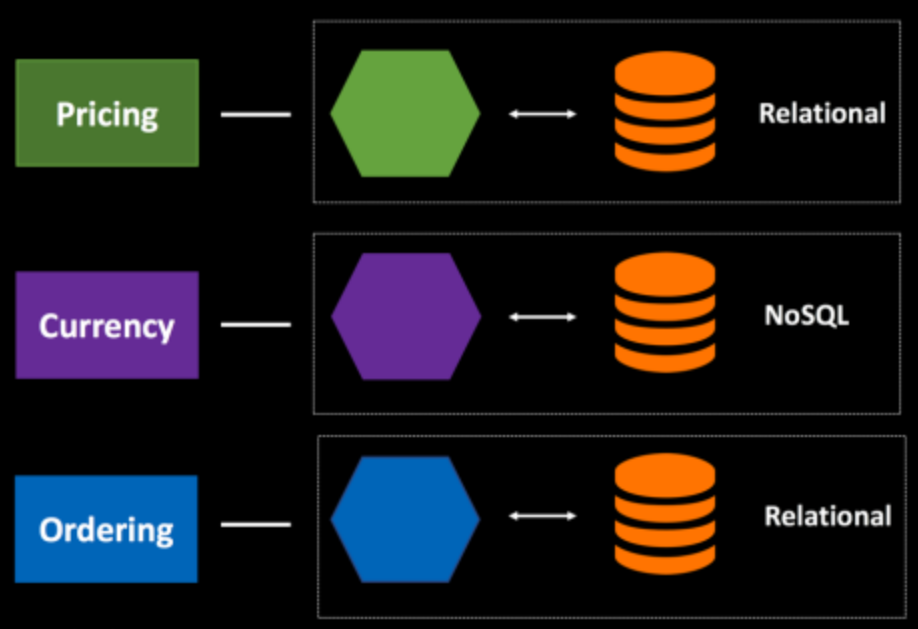
- Softwares menores são mais fáceis de manter
- Escalam mais rápido
- Consomem menos recursos
- Permite escalar de acordo com a demanda.
Mais responsabilidades, implicam em mais pontos de falha
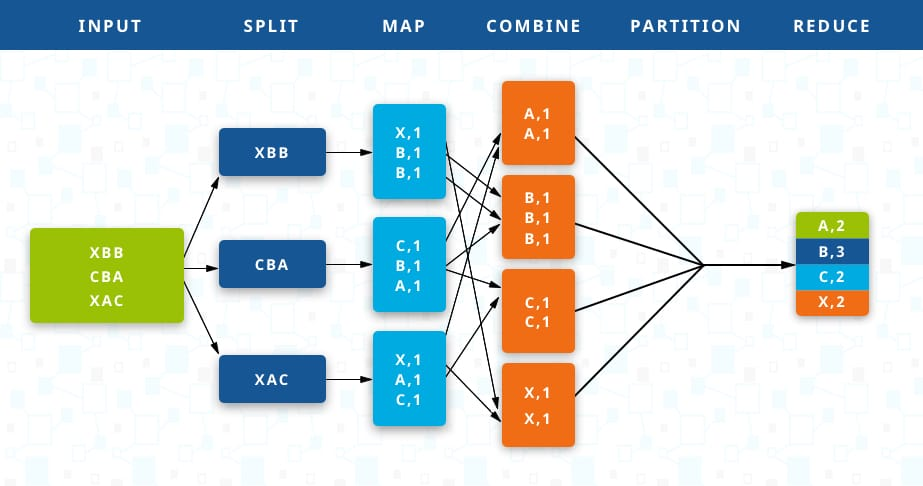
- São mais fáceis de manter
- São mais rápidos, mais escaláveis e mais resilientes
- Permitem melhor gestão de recursos
Por que jobs menores?
Orquestração
Micro componentes
Em lugar de microserviços, microcomponentes representam pequenos estágios
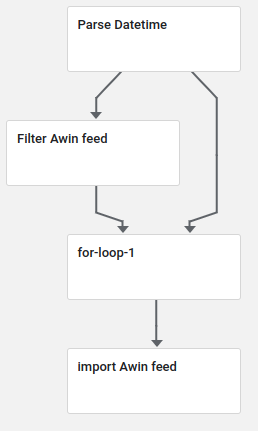
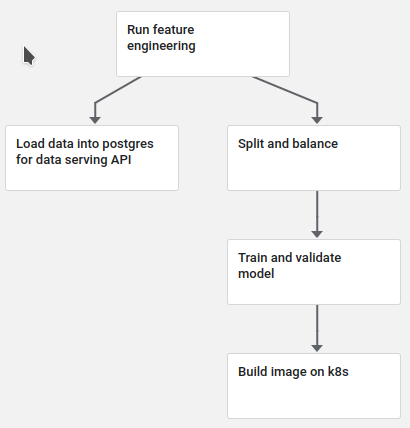
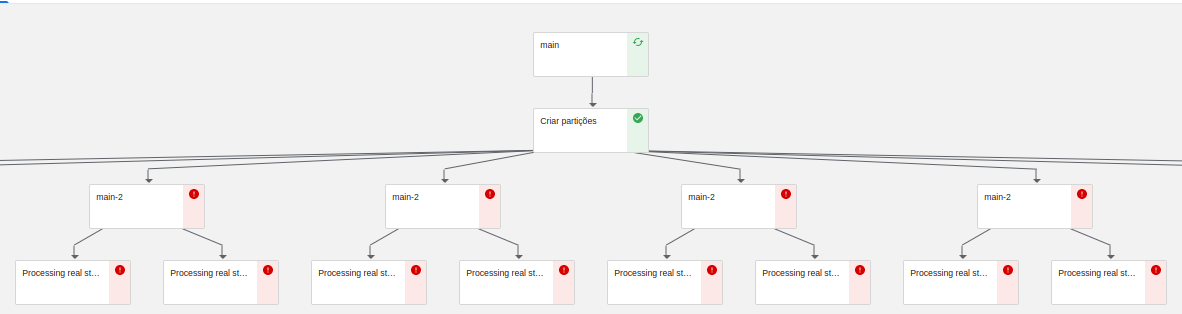
Pipeline
O pipeline é representado como uma função Python
@dsl.pipeline(name="train-classifier", description="")
def training_pipeline(
raw_source_file_path: str = "", base_path: str = "s3a://dev/output", spark_master: str = DEFAULT_SPARK_MASTER,
max_records_per_feature_engineering_file: int = DEFAULT_MAX_RECORDS_PER_ENGINEERING_FILE,
max_records_per_balanced_file: int = DEFAULT_MAX_RECORDS_PER_BALANCED_FILE,
train_validation_split_proportion: float = DEFAULT_TRAIN_VALIDATION_PROPORTION,
min_area_under_roc: float = 0.0, min_area_under_pr: float = 0.0,
db_feature_engineering_data_table: str = "feature_engineering_data", context_path: str = "",
resulting_image_name: str = "registry.com/credit-risk-classsifier",
db_host: str = "", db_port: int = DEFAULT_DB_PORT, db_username: str = "",
db_password: str = "", db_name: str = "", db_schema: str = "",
db_loading_batch_size: int = DEFAULT_BATCH_SIZE):
...Pipeline
Uma vez construído, o pipeline é abstraído num formulário, qualquer um pode executar.
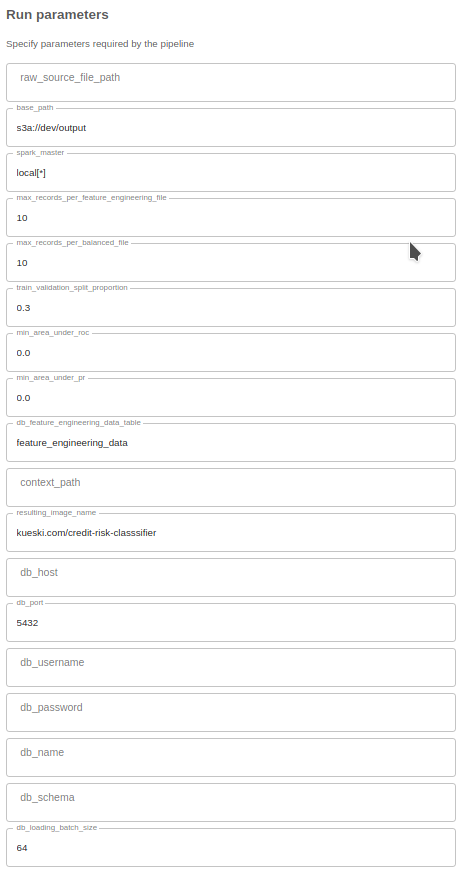
Pipeline
No pipeline temos o fluxo de informação entre os componentes
run_base_path = f"{base_path}/{dsl.RUN_ID_PLACEHOLDER}"
feature_engineering_output_path = f"{run_base_path}/feature-engineering-output"
serving_output_path = f"{run_base_path}/{dsl.RUN_ID_PLACEHOLDER}/serving-output"
feature_engineering_component = make_kueski_feature_engineering(
raw_source_file_path, feature_engineering_output_path, serving_output_path, spark_master,
max_records_per_feature_engineering_file)
feature_engineering_postgres_importer = make_postgres_importer(
DEFAULT_FILE_TYPE, serving_output_path, db_host, db_port, db_username, db_password, db_name,
db_schema,
db_feature_engineering_data_table, db_loading_batch_size)
feature_engineering_postgres_importer.set_display_name("Load data into postgres for data serving API")
feature_engineering_postgres_importer.after(feature_engineering_component)
training_data_folder = f"{run_base_path}/training_data"
balanced_validation_folder = f"{run_base_path}/validation/balanced"
unbalanced_validation_folder = f"{run_base_path}/validation/unbalanced"
balancer_component = make_kueski_balancer(
feature_engineering_output_path, training_data_folder, balanced_validation_folder,
unbalanced_validation_folder, train_validation_split_proportion, spark_master, max_records_per_balanced_file)
balancer_component.after(feature_engineering_component)
model_output_path = f"{run_base_path}/model.onnx"
training_component = make_kueski_training(training_data_folder, unbalanced_validation_folder, model_output_path,
spark_master, min_area_under_roc, min_area_under_pr)
training_component.after(balancer_component)
image_builder_component = make_image_builder(context_path, model_output_path, resulting_image_name,
resulting_image_tag=dsl.RUN_ID_PLACEHOLDER)
image_builder_component.after(training_component)
Código
import logging
import os
import click
from model_training.metrics import calculate_metrics, aprove_metrics
from model_training.persistence.data import load_source_data
from model_training.persistence.model import save_model, create_storage_params
from model_training.spark_helpers import create_spark_session
from model_training.model.trainer import train_model,
from model_training.model.entity import create_model
@click.command()
@click.option("--source-glob", "-s", type=click.STRING, help="Glob pattern to source data")
@click.option("--validation-source-glob", "-v", type=click.STRING, help="Glob pattern to validation data")
@click.option("--model-output-file", "-o", type=click.STRING, help="Path to where trained model will be saved")
@click.option("--spark-master", type=click.STRING, help="Spark master string", default="local[*]")
@click.option("--s3-endpoint", type=click.STRING, envvar="S3_ENDPOINT",
help="Endpoint to S3 objet storage server, defaults to S3_ENDPOINT environment variable")
@click.option("--aws-access-key-id", type=click.STRING, envvar="AWS_ACCESS_KEY_ID",
help="Access key to S3 object storage server, defaults to AWS_ACCESS_KEY_ID environment variable")
@click.option("--aws-secret-access-key", type=click.STRING,
help="Access key to S3 object storage server, defaults to AWS_SECRET_ACCESS_KEY environment variable",
default=get_from_environment("AWS_SECRET_ACCESS_KEY"))
@click.option("--min-area-under-roc", type=click.FLOAT, default="0.0",
help="Smallest value allowed for area under ROC, to consider model aceptable")
@click.option("--min-area-under-pr", type=click.FLOAT, default="0.0",
help="Smallest value allowed for area under PR, to consider model aceptable")
def main(source_glob: str, validation_source_glob: str, model_output_file: str, spark_master: str,
s3_endpoint: str, aws_access_key_id: str, aws_secret_access_key: str, min_area_under_roc: float,
min_area_under_pr: float):
logging.basicConfig(level=os.environ.get("LOGLEVEL", "INFO"))
spark_session = create_spark_session(spark_master, s3_endpoint, aws_access_key_id, aws_secret_access_key)
storage_params = create_storage_params(s3_endpoint, aws_access_key_id, aws_secret_access_key)
source_data_frame = load_source_data(spark_session, source_glob)
model = create_pipeline_model()
trained_model = train_model(source_data_frame)
validation_data_frame = load_source_data(spark_session, validation_source_glob)
metrics = calculate_metrics(validation_data_frame, trained_model)
aprove_metrics(metrics, min_area_under_roc, min_area_under_pr)
save_model(trained_model, model_output_file, spark_session, storage_params)
logging.info(f"Process finished")
if __name__ == '__main__':
main()
Entrypoints
Parametros
Setup de ambiente
Carrega dados
Processamento
Saída
Implementações
Cuidados com o código
_EXTRA_JARS = "com.amazonaws:aws-java-sdk-bundle:1.11.901,org.apache.hadoop:hadoop-aws:3.3.1,mjuez:approx-smote:1.1.0"
def create_spark_session(spark_master: str, s3_endpoint: Optional[str],
aws_access_key_id: Optional[str], aws_secret_access_key: Optional[str]) -> SparkSession:
logging.info("Starting and configuring spark session")
spark_session_builder = SparkSession \
.builder \
.master(spark_master) \
.config("spark.jars.packages", _EXTRA_JARS)
if s3_endpoint:
spark_session_builder.config("spark.hadoop.fs.s3a.endpoint", s3_endpoint)
if aws_access_key_id:
spark_session_builder.config("spark.hadoop.fs.s3a.access.key", aws_access_key_id)
if aws_secret_access_key:
spark_session_builder.config("spark.hadoop.fs.s3a.secret.key", aws_secret_access_key)
spark_session_builder.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem")
spark_session_builder.config("spark.hadoop.fs.s3a.path.style.access", "true")
spark_session_builder.config("spark.hadoop.fs.s3a.multipart.size", "1024")
spark_session = spark_session_builder.getOrCreate()
spark_session.sparkContext.setLogLevel("ERROR")
return spark_sessionCuidados com o código
def load_source_data(spark_session: SparkSession, source_glob: str) -> DataFrame:
logging.info(f"Loading source data from {source_glob}")
source_data_frame = spark_session\
.read\
.json(source_glob)\
.withColumn("features", array_to_vector(col("features")))
return source_data_frame
def save_json_dataset(training_dataset: DataFrame, output_folder: str, max_records_per_file: int):
logging.info(f"Saving dataset to {output_folder}")
training_dataset \
.write \
.option("maxRecordsPerFile", max_records_per_file) \
.mode("append") \
.option("mapreduce.fileoutputcommitter.algorithm.version", "2") \
.json(output_folder)Cuidados com o código
def train_model(training_data: DataFrame) -> PipelineModel:
logging.info(f"Training classifier model")
pipeline = _make_pipeline_model(classifier_model)
pipeline_model = pipeline.fit(training_data)
return pipeline_model
def create_model() -> Classifier:
model = RandomForestClassifier()
return model
def _make_pipeline_model(classifier: Classifier) -> Pipeline:
pipeline = Pipeline(stages=[classifier])
return pipeline
Desacoplamento de tecnologia
def save_model(model: PipelineModel, output_path: str, spark_sesion: SparkSession, storage_params: Dict):
input_schema = [
("features", FloatTensorType(shape=(None, 5))),
]
onnx_model = convert_sparkml(model, 'kueski model', input_schema, spark_session=spark_sesion)
with open(output_path, mode="wb", transport_params=storage_params) as output_file:
output_file.write(onnx_model.SerializeToString())
def create_storage_params(s3_endpoint: Optional[str], aws_access_key_id: Optional[str],
aws_secret_access_key: Optional[str]) -> Dict:
if s3_endpoint:
session = boto3.Session()
client = session.client('s3', endpoint_url=s3_endpoint, use_ssl=False,
aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key)
transport_params = dict(client=client)
else:
transport_params = None
return transport_paramsLazy Loading
e consumo de recursos
Memória bem comportada
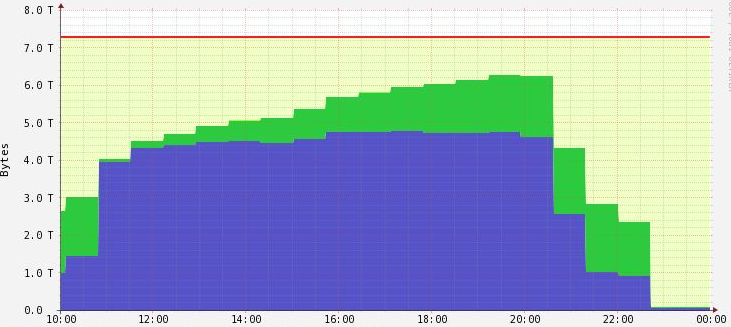
Lazy loading de dados
Sem despercídio de recursos
Sem replicas desnecessárias
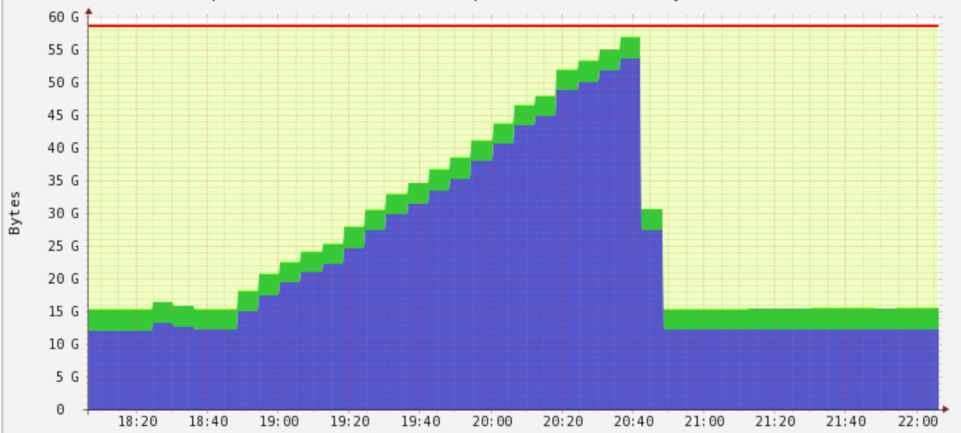
Memória crescente
Sem lazy loading
Despercídio de recursos
Acúmulo desnecessário
Hardware superescalado
Lazy loading de dados + jobs pequenos
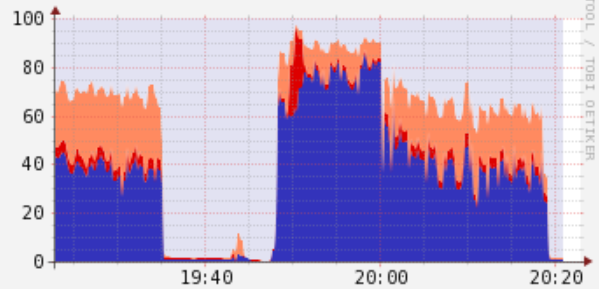
Perguntas?

Construindo pipelines de dados
By André Claudino



