Big Data
André Claudino
Volume
A quantidade de dados gerada é difícil de ser processada por métodos tradicionais.
Velocidade
A transmissão e processamento precisa ser rápida para evitar gargalos ou permitir análises
Variedade
Formatos variados de representaçao (estruturado, ou não, imagens, sons, etc)
Variabilidade
O fluxo de dados é inconsistente (picos de acesso ou demanda)
Complexidade
A combinação dos dados de diferentes fontes não é trivial
Veracidade
Dados precisam estar corretos
Valor
A informação precisa ser útil
Operando dados
SELECT
count(1),
sk_date
FROM
"sk_freight"."calculate"
GROUP BY
sk_date
ORDER BY
sk_date DESC
LIMIT 50;SQL
- Coleta de dados de uma base
- Agregação e preparação inicial
Operando dados
val df = spark
.read
.csv("pedidos.csv")
df
.withColumn("marketplace", col("cnpj") != "00776574000660")
.save("pedidos_com_marketplace.csv")Spark
- Agregações complexas
- ETL
- Machine Learning
Operando dados
val df = spark
.read
.csv("pedidos.csv")
df
.withColumn("marketplace", col("cnpj") != "00776574000660")
.save("pedidos_com_marketplace.csv")Spark
- Agregações complexas
- ETL
- Machine Learning
Criando um Projeto
Spark/Scala
Instalando SBT
echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2EE0EA64E40A89B84B2DF73499E82A75642AC823
sudo apt-get update
sudo apt-get install sbtPreparando VS Code
Clonar projeto base
Processamento distribuídos
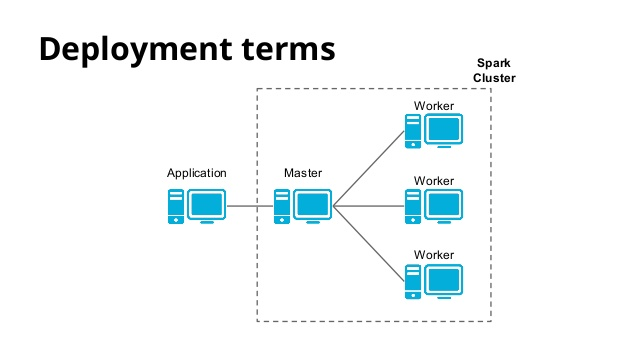
Processamento distribuídos
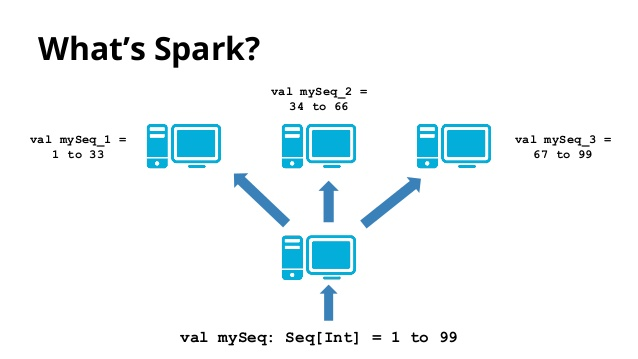
Processamento distribuídos
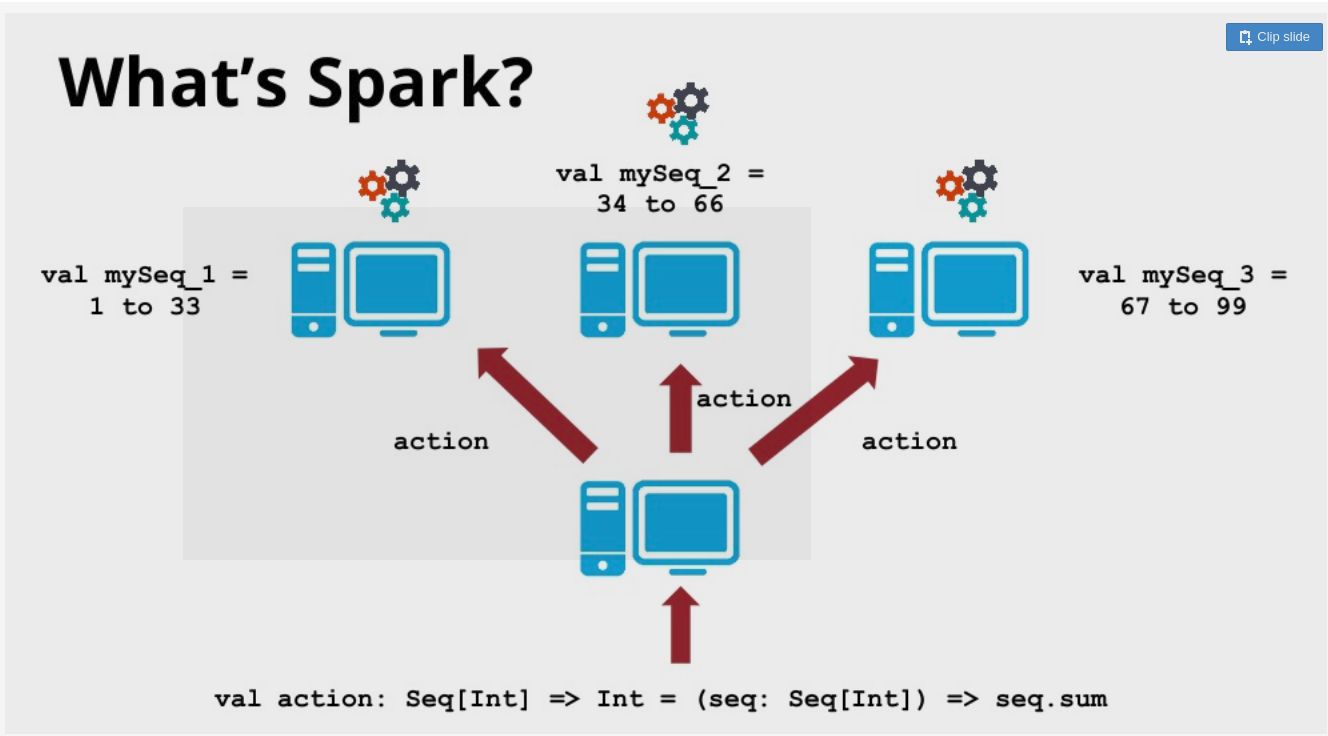
Processamento distribuídos
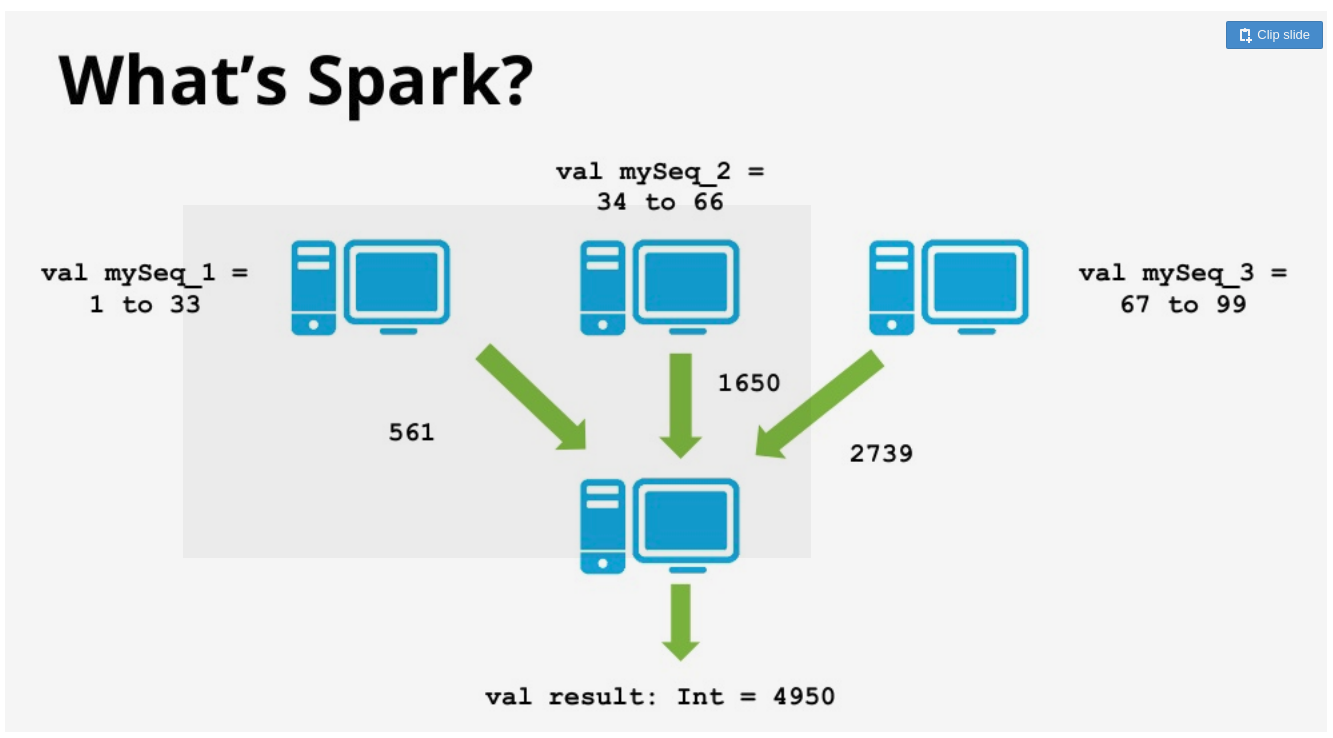
Processamento distribuídos
Map Reduce

deck
By André Claudino



