Frete dinâmico
Time IA Front
Otimização do frete
-
Frete depende do destino e da origem
-
Última barreira na decisão de compra
-
O custo varia muito
Difícil de otimizar
=
Problemas
Muitas variáveis
Baixa coesão
Alta dispersão
}
Restrições legais
Impedem a personaização
Inferência mais difícil
Abordagens
Classificação
Regressão
- Baixa coesão
- Desbalanceamento
- Modelo não injetivo
- Alta dispersão
- Coeficiente de Pearson ruim
- Sem semântica
Alternativa
Aprendizagem sem modelo
- Sem suposições sobre a função
- Baseado em comportamentos
- Baseado em aumentar a recompensa
- Aprende a imitar as decisões de negócio
Problemas
- Departamentos são grandes, e ids são pequenos
- Os Analistas não tem critérios para otimizar o frete
- O ciclo de treinamento no site seria muito lento
- Processar os dados no Stuart é muito custoso
- Não tínhamos estrutura para servir pipelines de IA complexos
- Não tínhamos estrutura para treinar pipelines de IA complexos
Resolvendo os problemas
Departamentos são grandes, e ids são pequenos
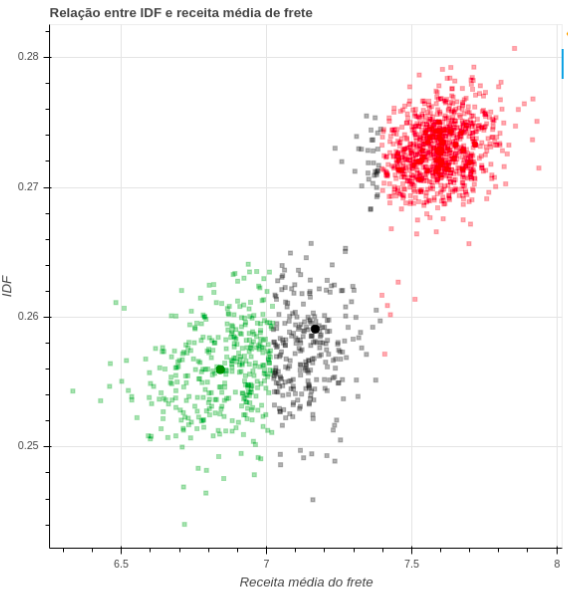
Clusters semânticos
- Particiona o hiperespaço
- Busca conversão similar
- Interpreta a percepção do cliente
- Cria semântica relacional para análises
Clusters semânticos
// Categóricos
visita.marca,
visita.departamento,
visita.linha,
// Numéricos
visita.preco,
visita.prazo,
// numéricos (localização)
cep_geocodes.latitude,
cep_geocodes.longitude,- Busca a visão do usuário
- Usa campos ligados ao produto
- Usa coordenadas do usuário
- considera prazo e preço
Clusters semânticos
object VisitsClustering extends App {
val parsed = new BaseParser(args, Some("TreeFeatureClustering"))
implicit def spark: SparkSession = createSession(parsed.confs.get("sparkMaster"))
spark.setupS3
implicit def sparkContext: SparkContext = spark.sparkContext
(...)
val segmentModel =
VisitsClusterModelGenerator
.run(visitsByFilter(minData, maxData, filter, limit))
private val departamentos =
AthenaSource
.fieldValues[String]("departamento", minData, maxData, filter)
private val regioes =
AthenaSource
.fieldValues[String]("regiao", minData, maxData, filter)
TreeFeatureExperiment
.rules2Df(segmentModel, identificador)
.withColumn("ensaio", lit(essay))
.withColumn("filtro_inicial", lit(filter.getOrElse("")))
.withColumn("data_maxima", lit(maxData.getOrElse("")))
.withColumn("data_minima", lit(minData.getOrElse("")))
.withColumn("departamentos", typedLit(departamentos))
.withColumn("regioes", typedLit(regioes))
.write
.partitionBy("identificador", "ensaio", "profundidade")
.mode(SaveMode.Append)
.json(outputPath)
spark.close- Escrito em Spark
- Adapta MLLib
Clusters semânticos
import org.apache.spark.sql.SparkSession
import com.b2w.ml.spark.athena._
val spark = SparkSession
.builder
.appName("Athena JDBC test")
.master("local[*]")
.getOrCreate
val stagingDir = "s3://bucket/athena-query-results"
val query =
"""
|SELECT data from my table LIMIT 10
""".stripMargin
val df1 = spark
.read
.athena(query, stagingDir)Criamos o athena-spark-driver para conectar o spark ao Athena
Clusters semânticos
applications:
- name: clustering-bot
master: local[*]
deployMode: client
mainClass: com.b2w.iafront.clustering.jobs.VisitsClustering
appArgs: [
"-o", "s3a://ia-front-jobs-data/visits-clustering",
"-c", "minData=2019-10-01",
"-c", "maxData=2019-11-01",
"-c", "filtro=(departamento IN ('Fun Kitchen')) AND (estado IN ('MT', 'GO', 'MS', 'DF'))",
"-c", "identificador=Eletroportáteis Centro-Oeste 2019-10-01 ate 2019-11-01"
]
appResource: local:///startup.jar
confs:
spark.executor.memory: 1g
spark.executor.instances: "3"
spark.driver.host: sinfony
spark.kubernetes.container.image: gcr.io/master-sector-247616/ia-front/clustering:latest
spark.kubernetes.authenticate.driver.serviceAccountName: spark
spark.kubernetes.namespace: sparkCriamos o SparkSinfony, para orquestrar jobs spark no k8s
Clusters semânticos
Temos uma semântica simplificada para análise
Problemas
- Departamentos são grandes, e ids são pequenos
- Os Analistas não tem critérios para otimizar o frete
- O ciclo de treinamento no site seria muito lento
- Processar os dados no Stuart é muito custoso
- Não tínhamos estrutura para treinar pipelines de IA complexos
- Não tínhamos estrutura para servir pipelines de IA complexos
Os Analistas não tem critérios para otimizar o frete
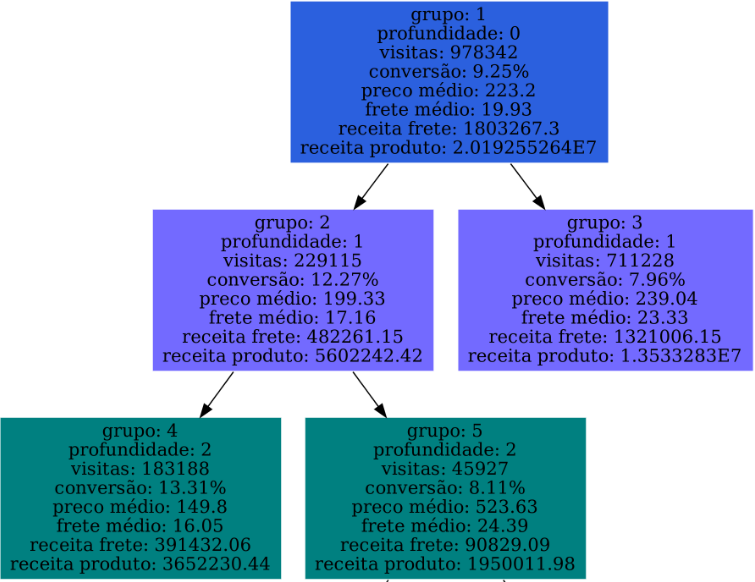
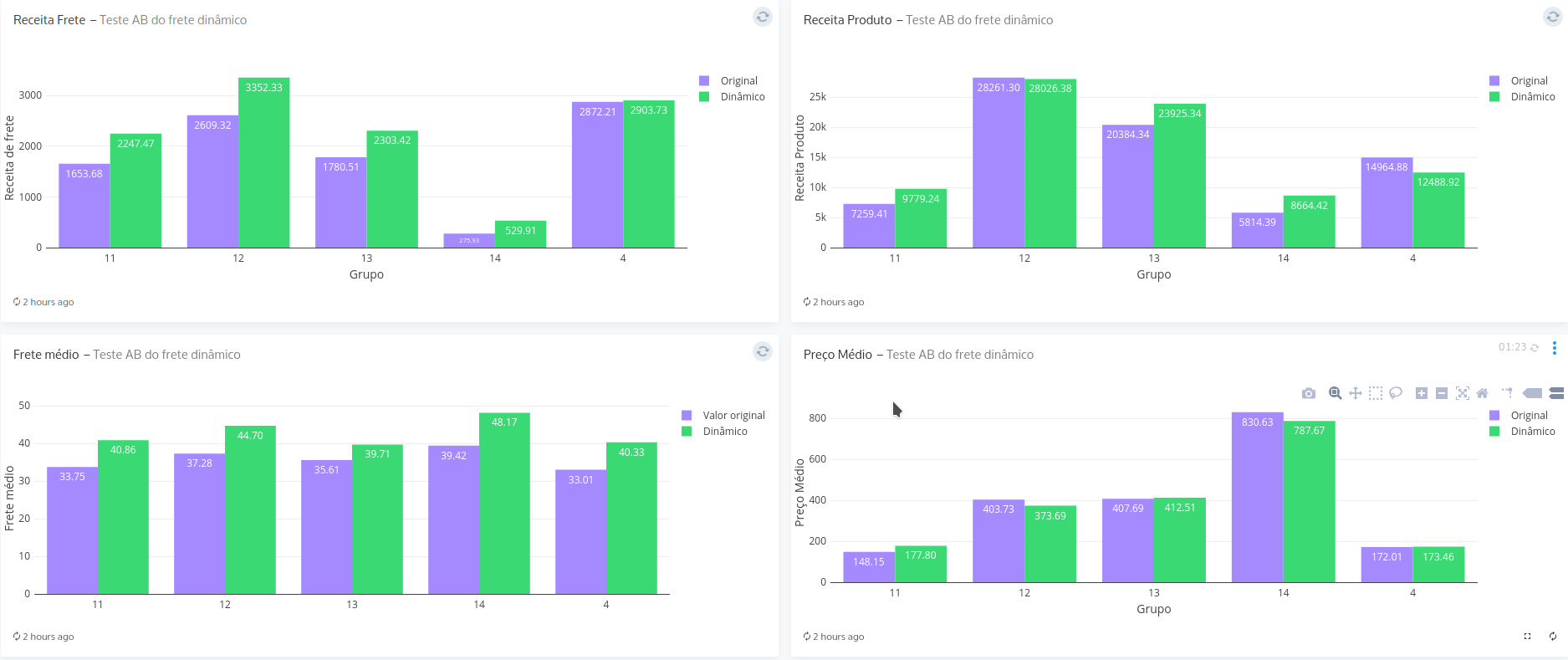
Simulador de Monte Carlo
- Simula cenários iniciais a partir dos dados anteriores
- Busca o maior frete que afeta a conversão dentro de um limite
Simulador de Monte Carlo
Consiste em vários jobs spark com o objetivo de preparar dados de simulação e gerar gráficos para análise
Simulador de Monte Carlo
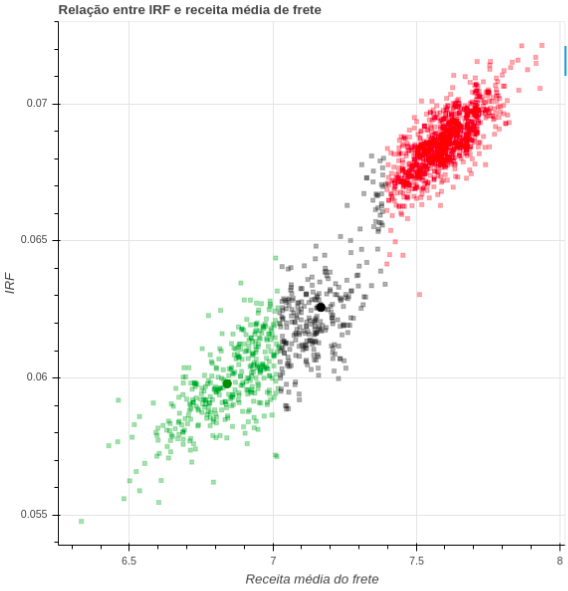
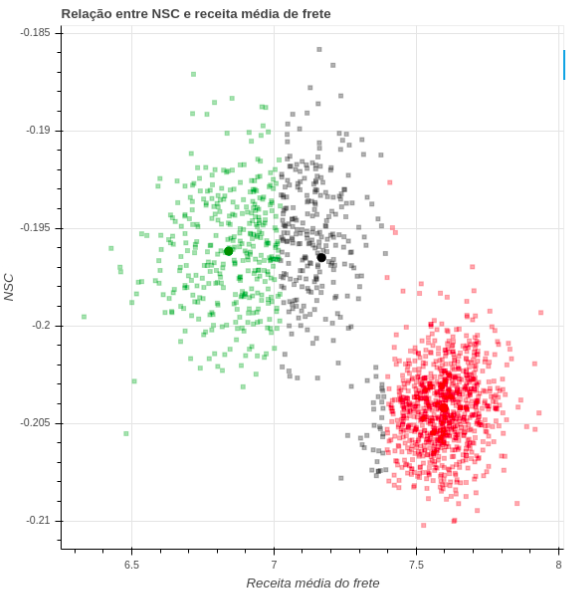
Gera gráficos das métricas de frete contra a receita média dos clusters
Simulador de Monte Carlo
Usa os centroides para determinar cenários iniciais de fretes possíveis

Simulador de Monte Carlo
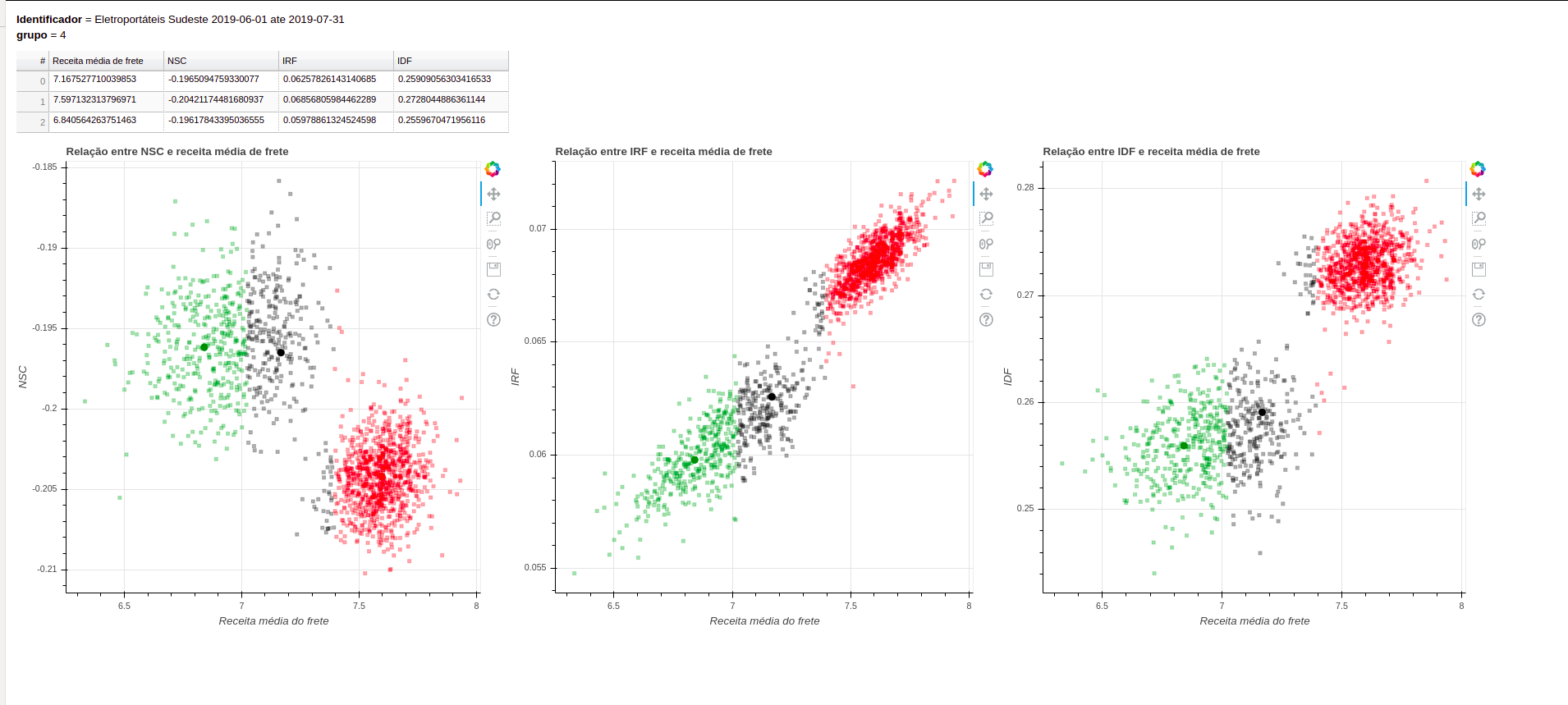
Gera o relatório completo para análise da equipe de negócios
Problemas
- Departamentos são grandes, e ids são pequenos
- Os Analistas não tem critérios para otimizar o frete
- O ciclo de treinamento no site seria muito lento
- Processar os dados no Stuart é muito custoso
- Não tínhamos estrutura para treinar pipelines de IA complexos
- Não tínhamos estrutura para servir pipelines de IA complexos
O ciclo de treinamento no site seria muito lento
Modelo de sonho
- Aprende uma distribuição de probabilidade de conversão
- É um modelo de mistura de densidade
- Usado para simular o universo do site
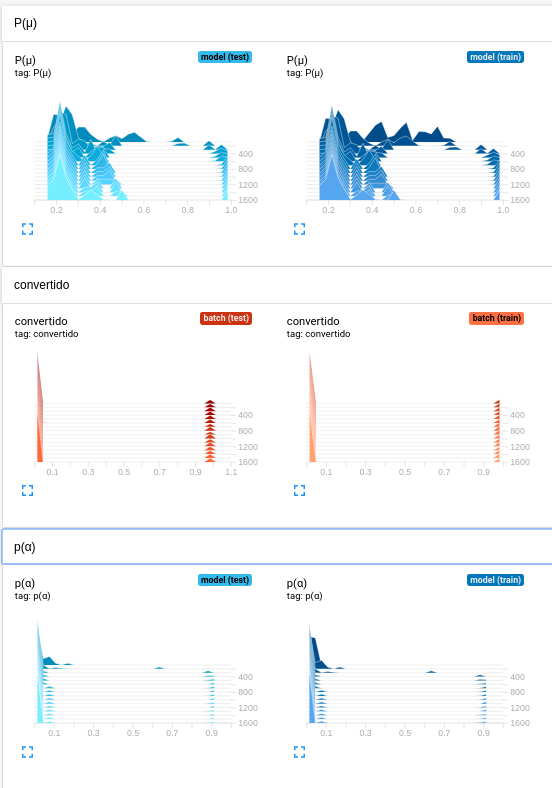
Modelo de sonho
- Usado no modelo de reforço como parte do ambiente
- Escrito em tensorflow
class Mixture(PersistensedModel):
def __init__(self, layers_sizes: Sequence[int], components: int, learning_rate: float, name=None):
super().__init__(name=name)
self.layers_sizes = layers_sizes
self.components = components
self._setup_model(components)
self.learning_rate = learning_rate
self.optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
def _setup_model(self, components: int):
input_size = self.layers_sizes[-1]
with self.name_scope:
self.model: tf.keras.Sequential =\
tf.keras.Sequential([dense_layer(neurons,
activation=tf.nn.tanh,
initializer=tf.keras.initializers.GlorotNormal())
for neurons in self.layers_sizes],
name="dense_layers")
self.alfas = dense_layer(components, activation=tf.nn.softmax, name="alpha")
self.alfas.build([None, input_size])
self.mus = dense_layer(components, activation=tf.nn.sigmoid, name="mu")
self.mus.build([None, input_size])
self.sigmas = dense_layer(components, activation=nnelu, name="sigma")
self.sigmas.build([None, input_size])Problemas
- Departamentos são grandes, e ids são pequenos
- Os Analistas não tem critérios para otimizar o frete
- O ciclo de treinamento no site seria muito lento
- Processar os dados no Stuart é muito custoso
- Não tínhamos estrutura para treinar pipelines de IA complexos
- Não tínhamos estrutura para servir pipelines de IA complexos
Sistema de reforço
- Ambiente encapsula o modelo de mistura
- recompensa baseada em métricas dos clusters
- Replica as ações tomadas pelo usuário
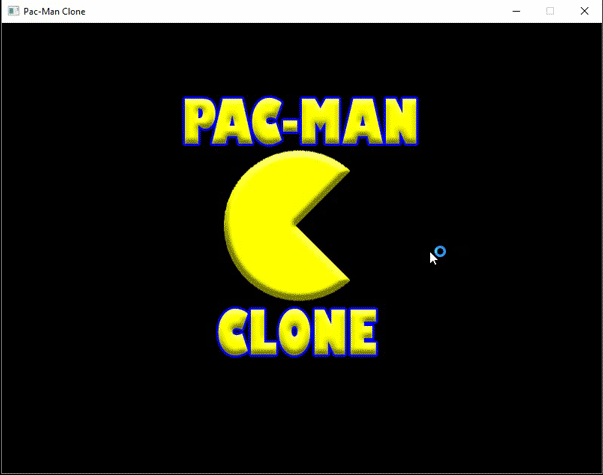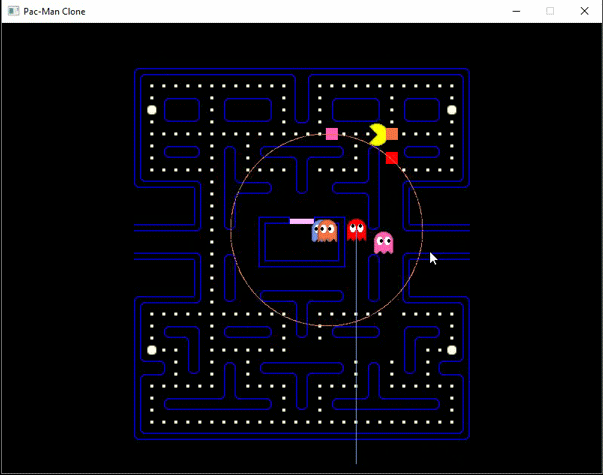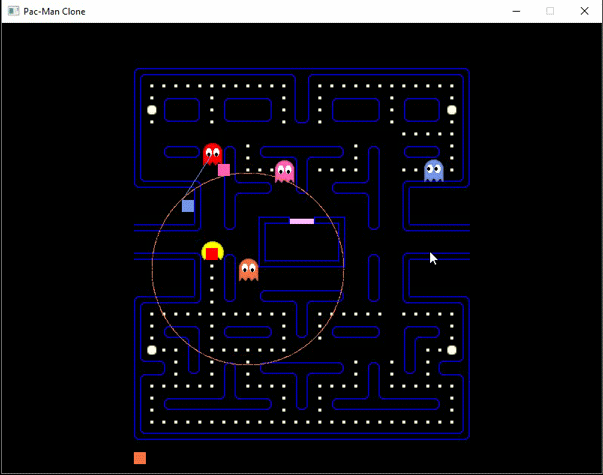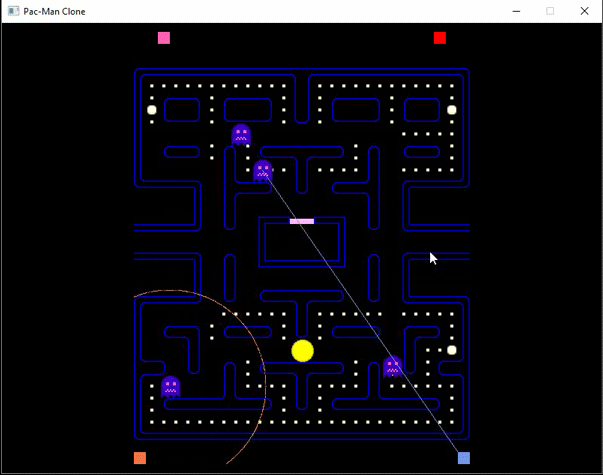
Sistema de reforço
Estado
métricas do cluster

recompensa
kpi baseado nas métricas do cluster
Ação
frete do cluster
Sistema de reforço
- Escrito em Tensorflow
- Usa o sonho para transfer learning
- Devolve como saída a recompensa média associada ao valor de frete
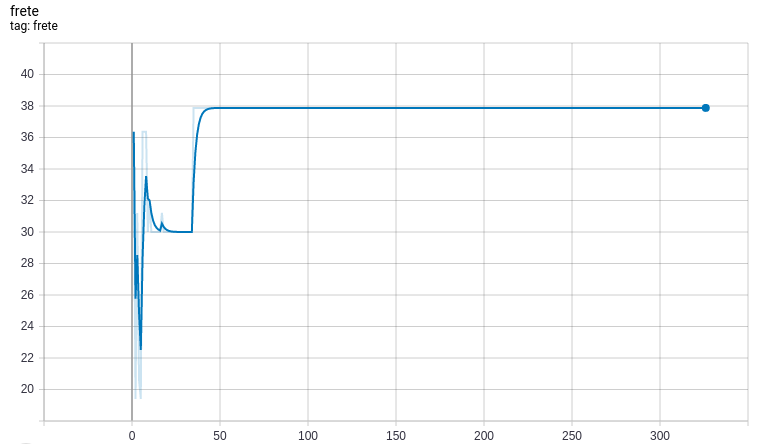
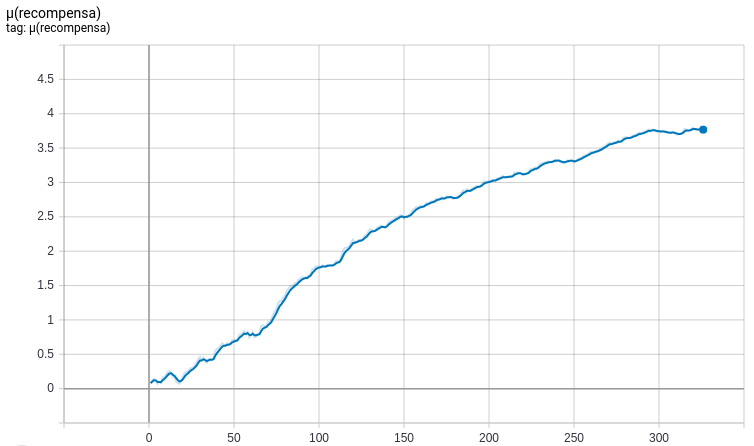
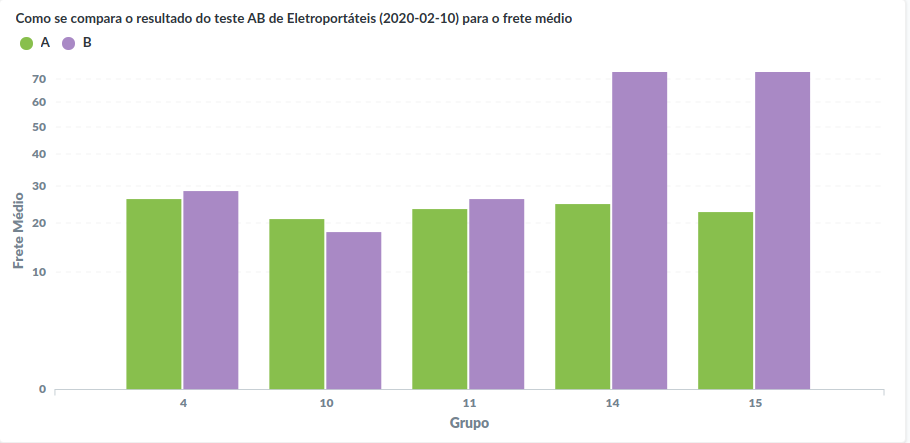
Sistema de reforço
Com base nos resultados, temos um valor de frete para o cluster
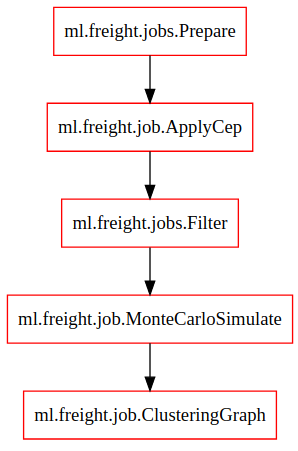
Arquitetura
frete.visitas
Clustering
Evil tree
Monte carlo
ETL + crawler no Glue que extrai visitas a partir de cálculos de frete
Job Spark que calcula regras de separação para entidades semânticas
Geram relatórios para a equipe de negócios decidir quais clusters serão utilizados e preços iniciais
Preparação de clusters
Tagger
freight bot mixture
freight bot reinforcement
Job que marca as visitas associadas a cada cluster posto em produção
Treina o modelo de sonho para usarmos no sistema de reforço
Reforço e dashboards
Treina o sistema de reforço com base nos sonhos e visitas do cluster
Dashboards
Relatórios no Stuart com as métricas de frete
Compilador de regras
freight bot inference
API de frete
Stuart
Compila as regras dos grupos em regras de inferência com frete
API que usa o resultado do compilador de regras para servir funções que inferem o frete de uma visita
Retroalimento o Stuart com os novos cálculos associados aos clusters e reinicia o processo
Inferência
Repassa para o bot quando cair na política dinâmic
Problemas
- Departamentos são grandes, e ids são pequenos
- Os Analistas não tem critérios para otimizar o frete
- O ciclo de treinamento no site seria muito lento
- Processar os dados no Stuart é muito custoso
- Não tínhamos estrutura para treinar pipelines de IA complexos
- Não tínhamos estrutura para servir pipelines de IA complexos
Infra de treino
Ferramentas criadas
- Driver Athena para Spark
- Orquestrador de Spark no k8s
- Reader Tensorflow+Python para resultados particionados (sem spark)
- Reader Tensorflow para Athena
- Imagens base para Spark
- Imagens base para Tensorflow (com e sem GPU)
- Runner de consultas Athena
- Runner kubeflow para Spark
Código aberto
Interno
Kubeflow + Gitlab
- Treinamos pipelines complexos facilmente
- Acompanhamos relatórios de treino para melhorias futuras
- Permite transferir a responsabilidade para o usuário
- Executamos jobs complexos que não podem executar no Glue
- Permite criar interfaces para o usuário analisar resultados
- Permite criar relatórios para o usuário
- Dá ao usuário a decisão de quando treinar o modelo, sem conhecimento de IA.
Desenvolvimento
Usuário
Resultados
- Treinamos pipelines complexos facilmente
- Acompanhamos relatórios de treino para melhorias futuras
- Permite transferir a responsabilidade para o usuário
- Executamos jobs complexos que não podem executar no Glue
- Permite criar interfaces para o usuário analisar resultados
- Permite criar relatórios para o usuário
- Dá ao usuário a decisão de quando treinar o modelo, sem conhecimento de IA.
Desenvolvimento
Usuário
Problemas
- Departamentos são grandes, e ids são pequenos
- Os Analistas não tem critérios para otimizar o frete
- O ciclo de treinamento no site seria muito lento
- Processar os dados no Stuart é muito custoso
- Não tínhamos estrutura para treinar pipelines de IA complexos
- Não tínhamos estrutura para servir pipelines de IA complexos
Resultados
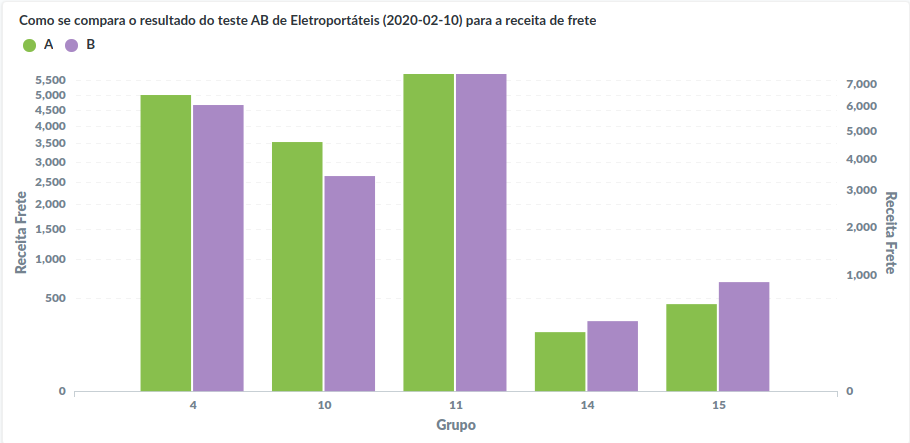
Resultados
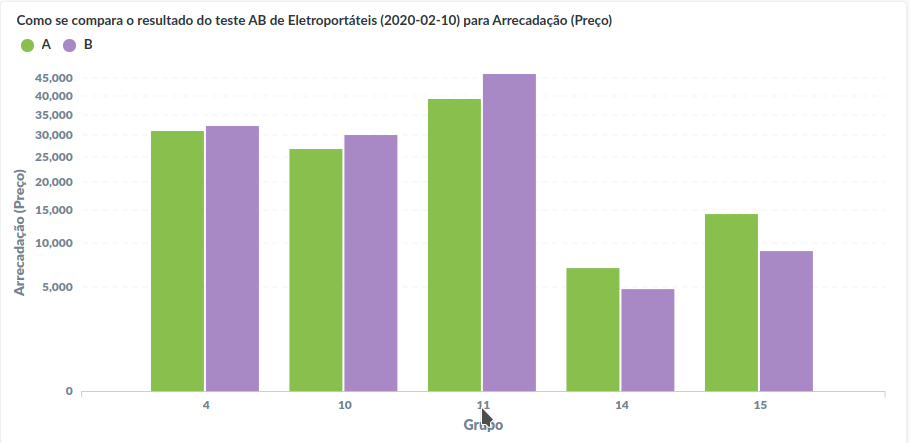
Resultados
Perguntas?
deck
By André Claudino



