Plataforma de IA
IA Front
Universo


Frameworks de (pré)-processamento, IA e Big Data
Armazenamento e pesquisa de dados




Infra de execução


Orquestração
- Usamos kubeflow para orquestrar pipelines
- Execuções podem ser manuais ou agendadas
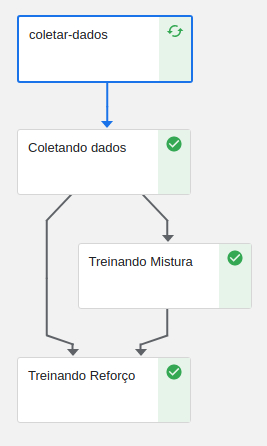
Autonomia
Damos autonomia ao usuário final para criar/executar pipelines com dados próprios
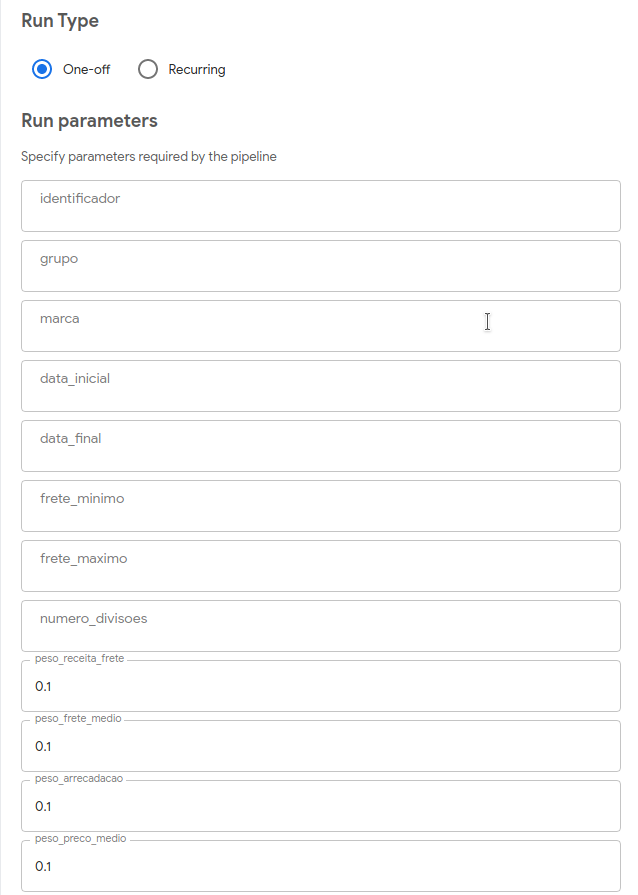
Orquestração
Temos um ambiente centralizado onde o usuário ver os resultados
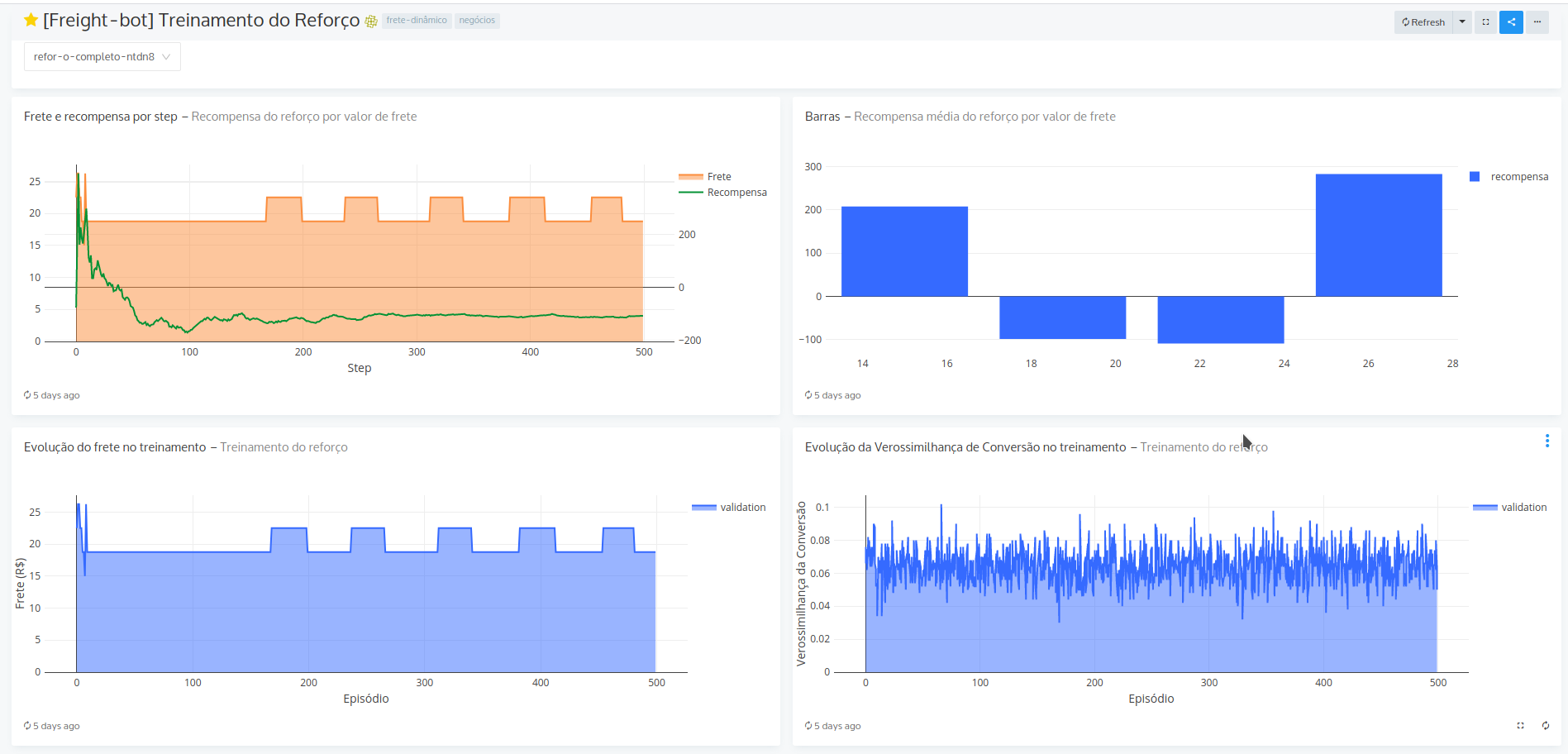
Features
Features são armazenadas nas plataformas de bigdata (Athena e BigQuery) com marcações de tempo
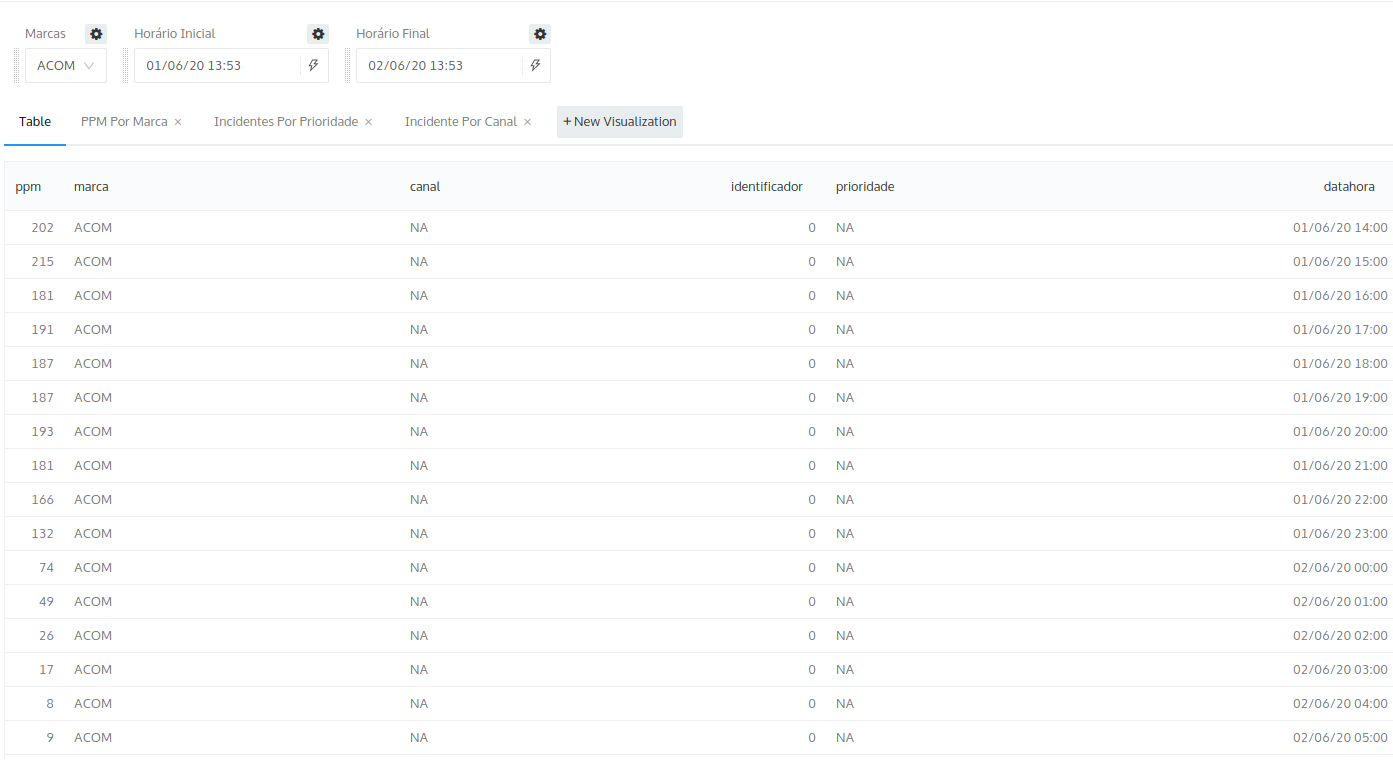
Features
Jobs criam versões vetorizadas das features quando necessário
Reúso de aplicações
Criação de uma plataforma para versionamento e compartilhamento de modelos, ETLs, avaliadores, etc.

Customização
- Tudo executado na forma de containers, criando ambientes isolados
- Troca de dados feita por meio de storages comuns e APIs (integrável a vários serviços e bibliotecas)
- Já temos bibliotecas de suporte isolado e nativo para Spark e Tensorflow
- Isolamento dá liberdade total na escolha das ferramentas
- Estamos desenvolvendo tunning automático de modelos
Necessidades
- Parametrização temporal
- Feature Engineering
- Materialização de dados de treino e validação
- Recomposição de features para inferência
- Consistência entre treinamento e inferência
Necessidades
(bônus)
- Simplificar a execução para equipes de negócio
- Permitir análises sobre as features
- Disponibilização global para a empresa
- Visibilidade dos dados
- Feature importance simplificado
deck
By André Claudino



