









Yu-An, Chung
Computer Science and Information Engineering, National Taiwan University
資訊四 吳肇中、鍾毓安
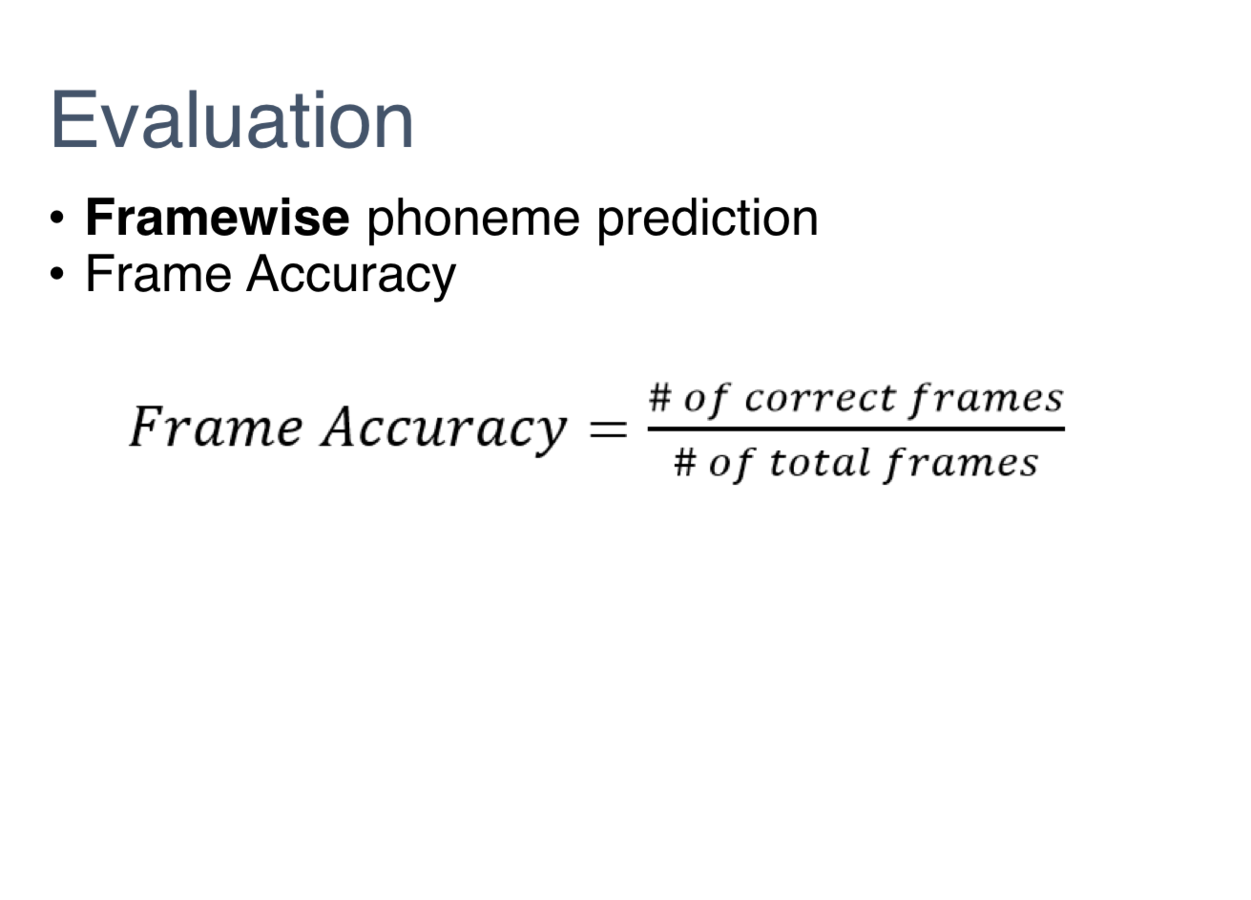
DNN in Speech Recognition
DNN Toolkit: LIBDNN
https://github.com/botonchou/libdnn
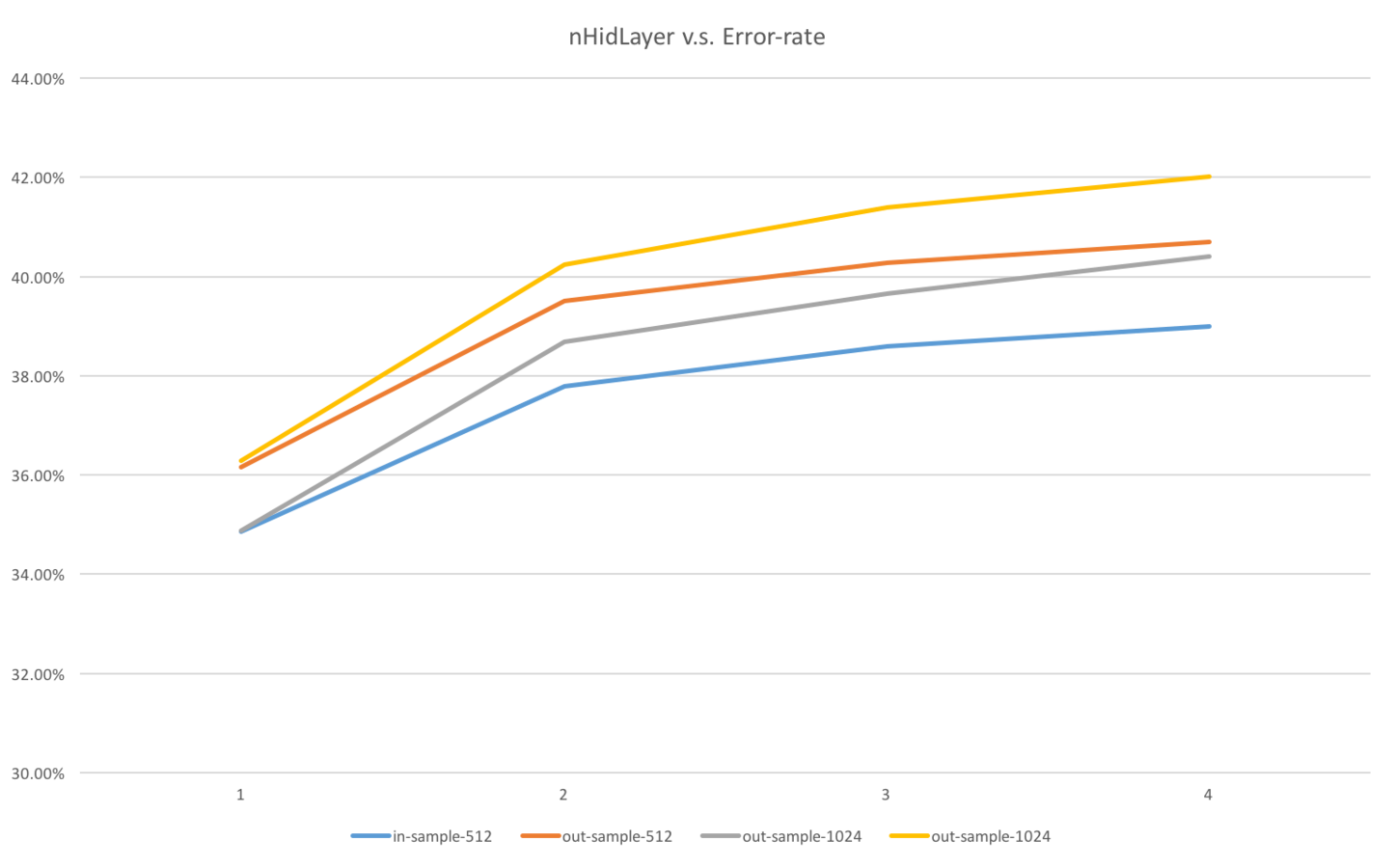
Let's take a DNN structured:
69-1024-1024-1024-48
as an example ...
run.sh: design
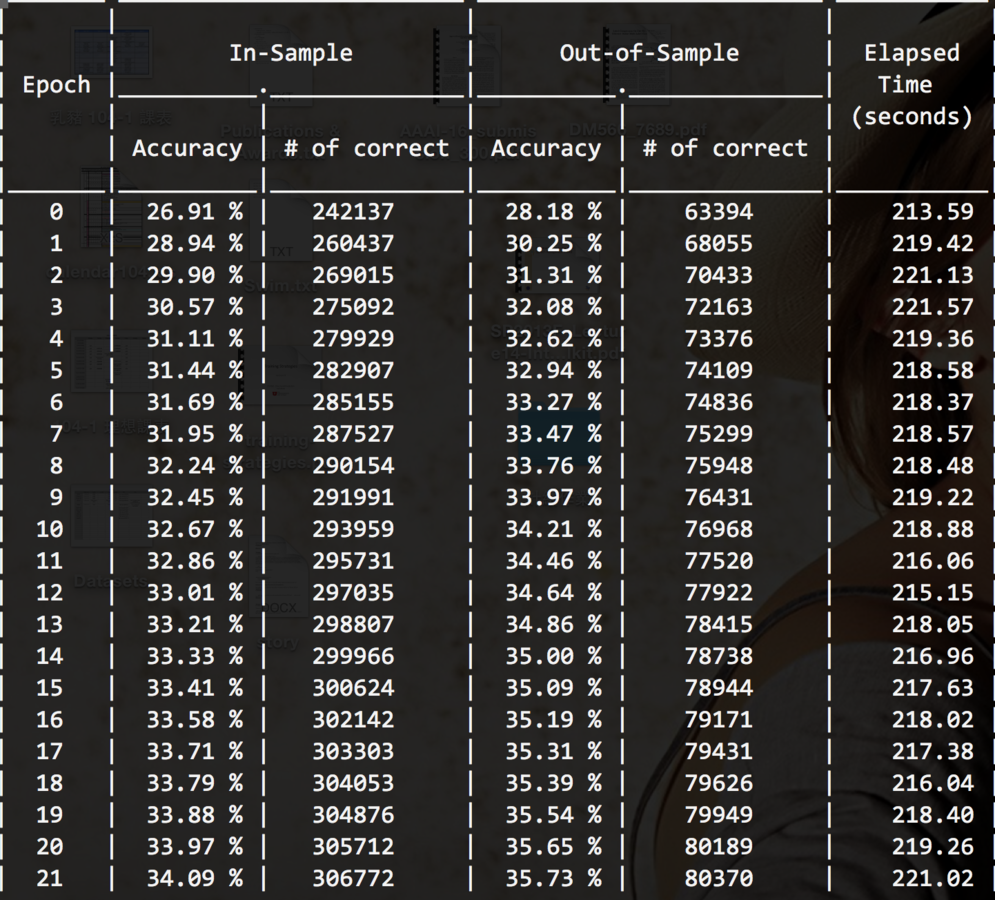
Begin Training ...
Display the result
We didn't plot the error bar since those values are relatively small.
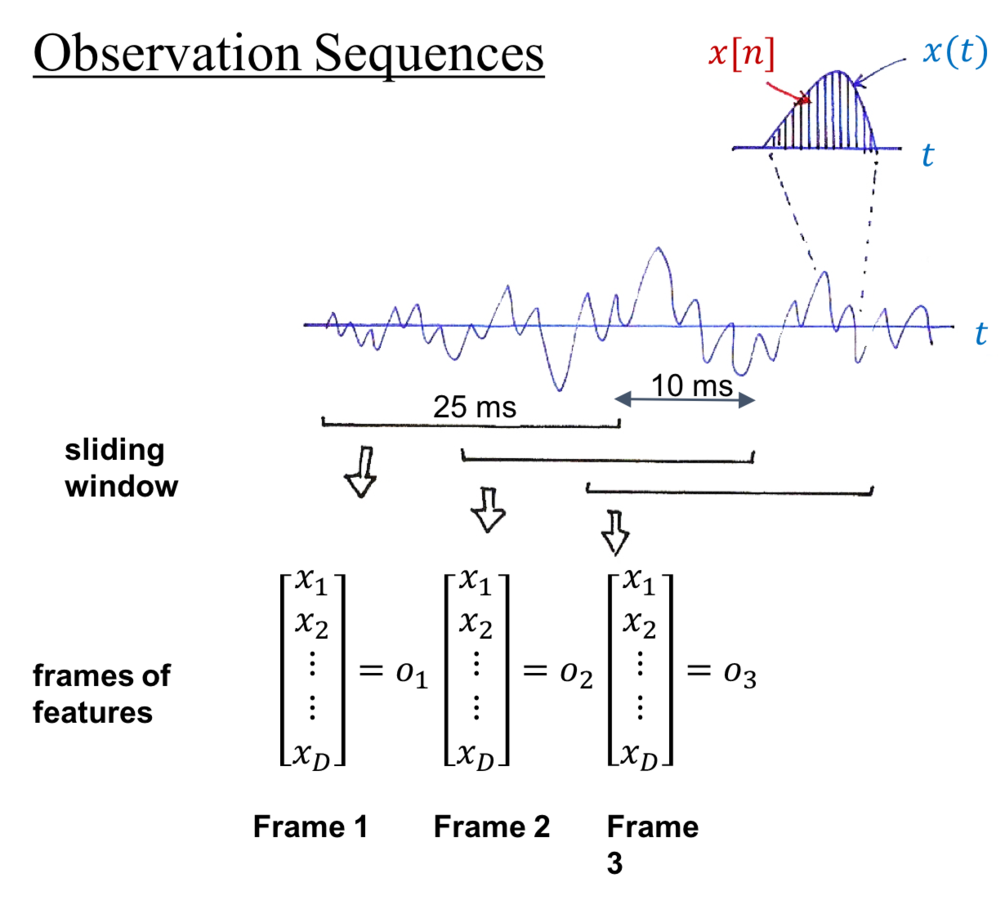
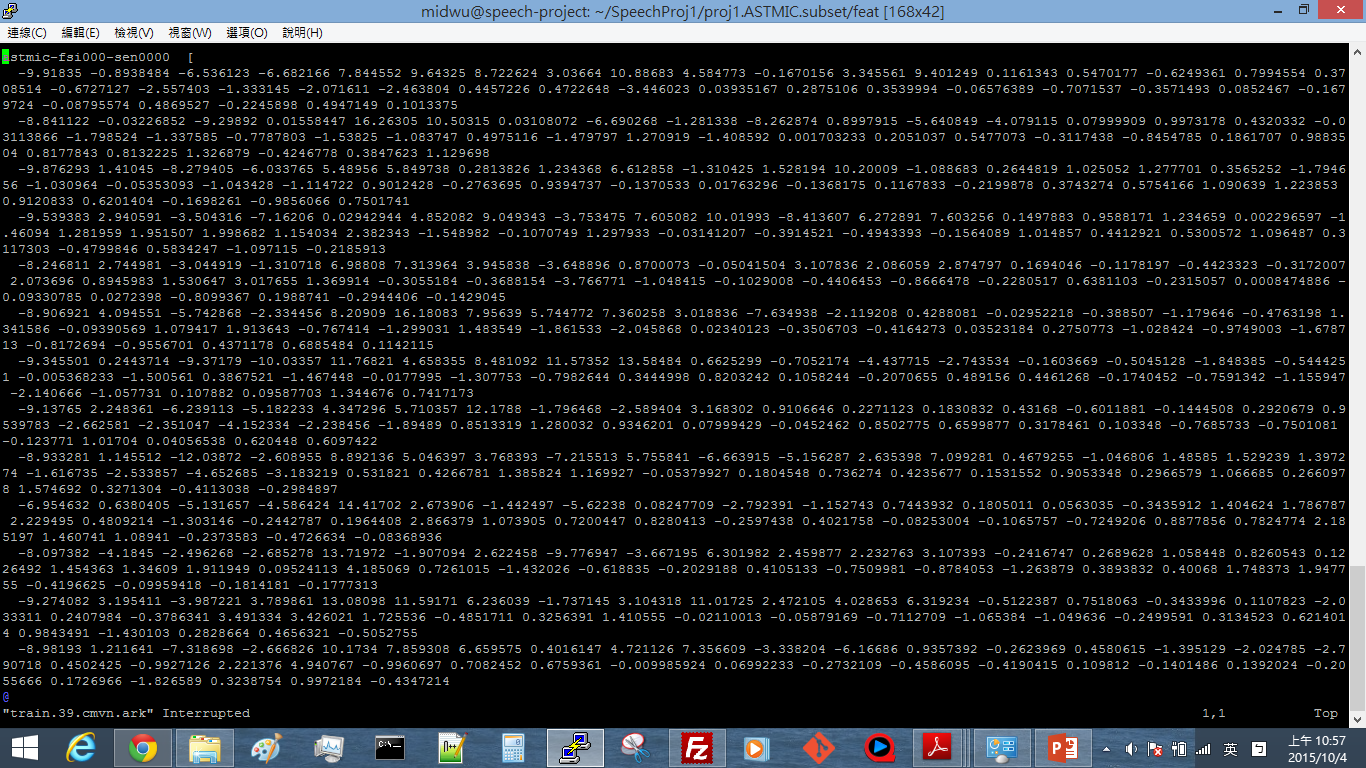
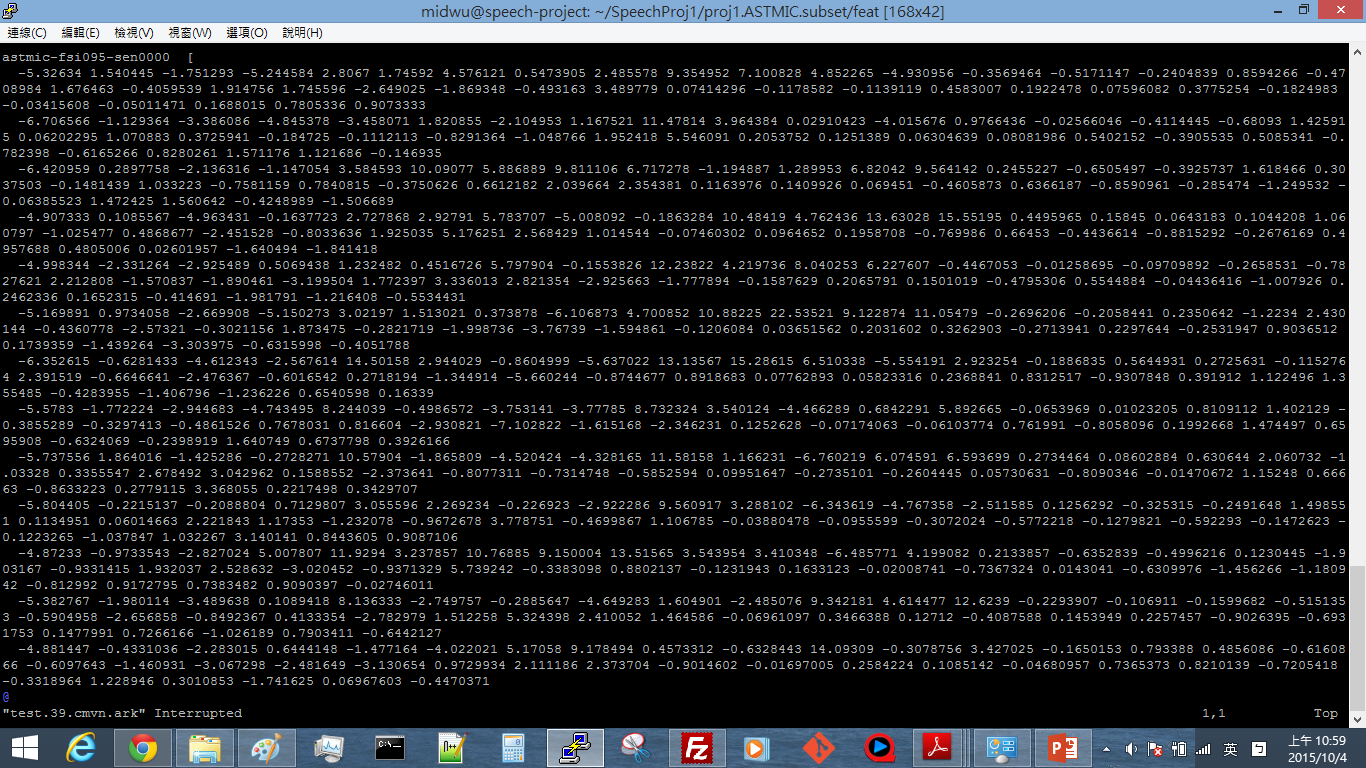
Feature Extraction
1. add-deltas
2. compute-cmvn-stats
3. apply-cmvn
MFCC Extraction
Result 1: Training set MFCC
Result 2: Testing set MFCC
HMM Training
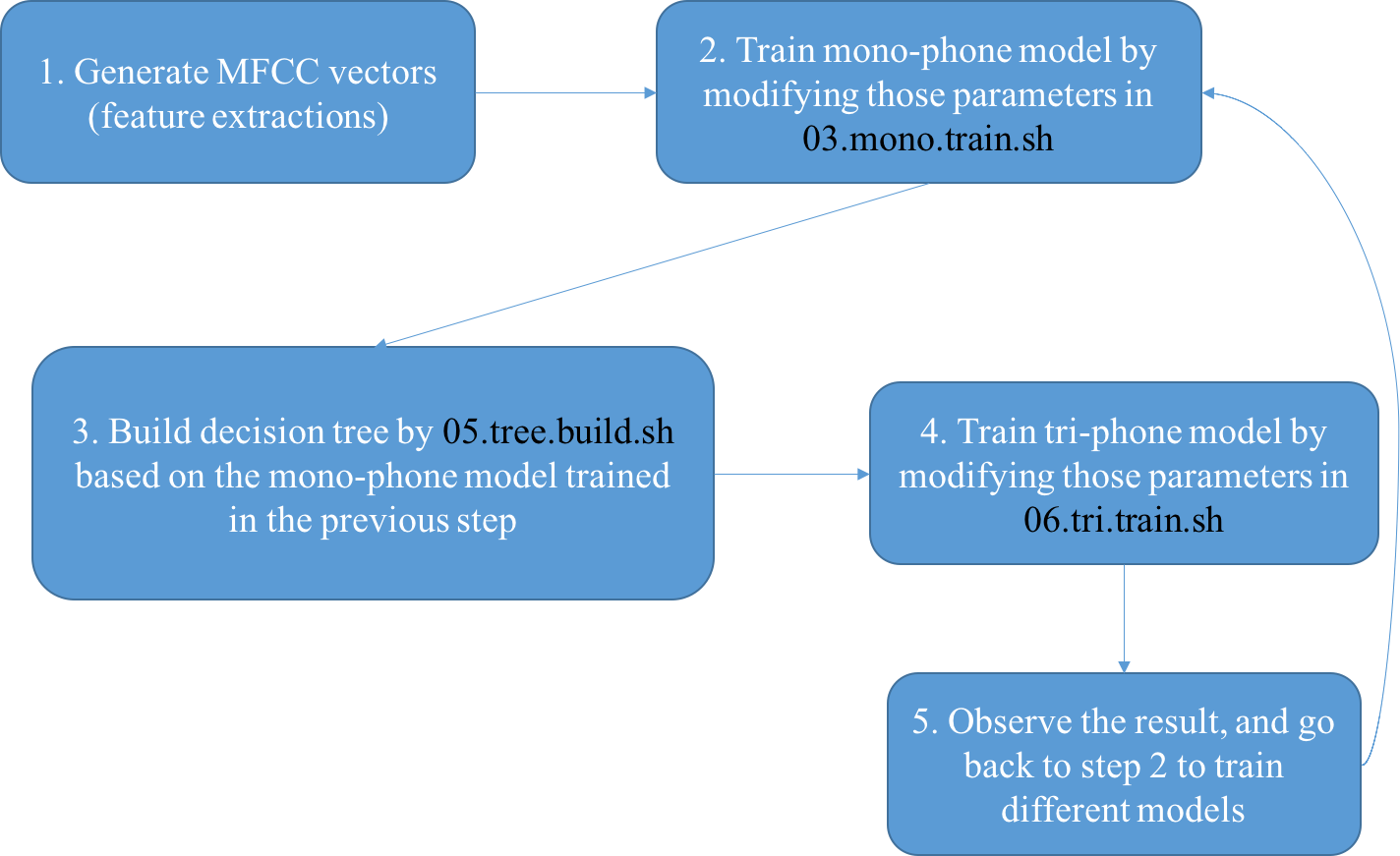
Work Flow
1. MFCC? Already done in proj #1 !
2. Train mono-phone model -- 03.mono.train.sh
We train two mono-phone models, one with
numiters=40 (default by TA), and the other with
numbers=60 (extend training). The rest of the
parameters are fixed.
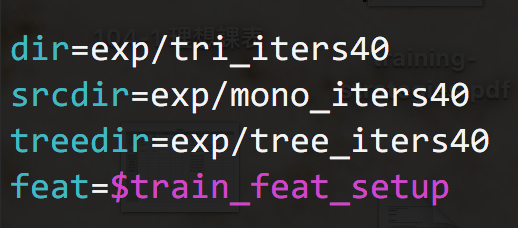
mono_iters40
mono_iters60
We continue training with both models to see their differences.
output model: mono
3. Build decision tree for both mono-phone models
-- 05.tree-build.sh
=> tree_iters40 & tree_iters60
4. Train tri-phone models from tree models trained
previously -- 06.tri.train.sh
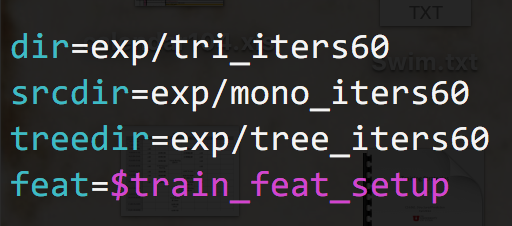
tri_iters40
tri_iters60
output model: tri-phone
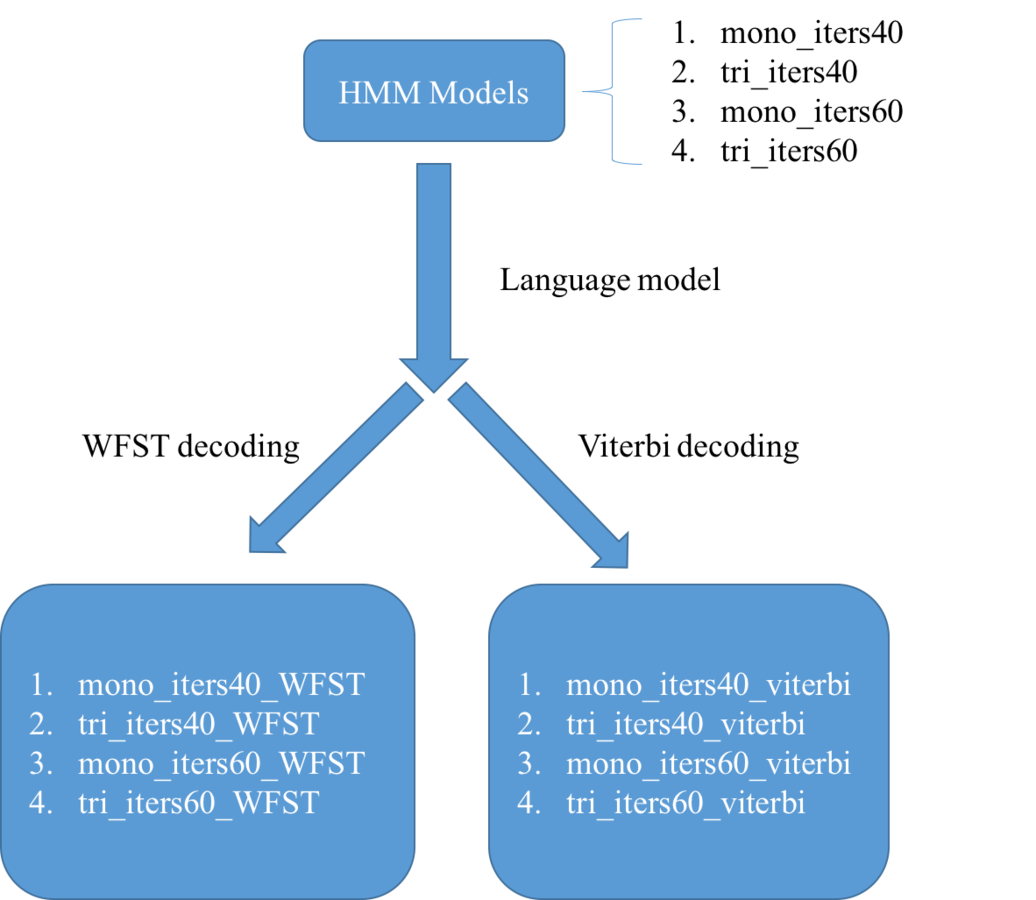
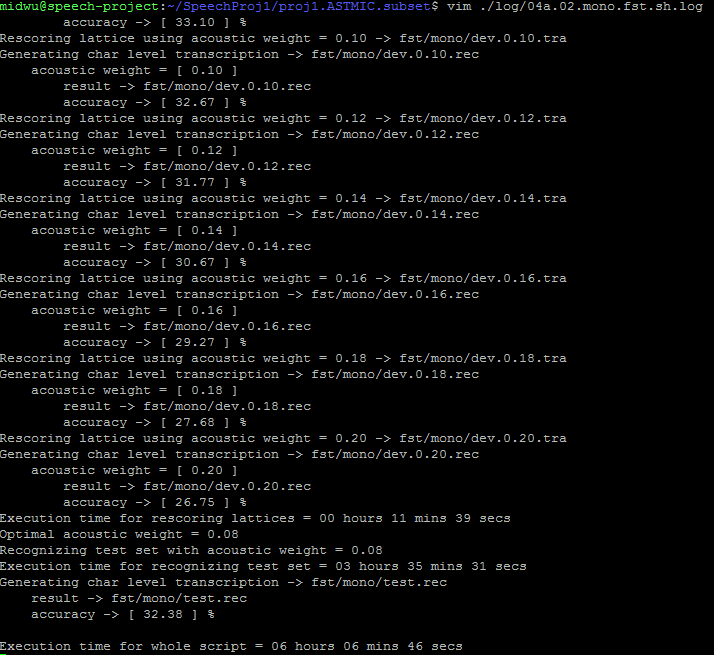
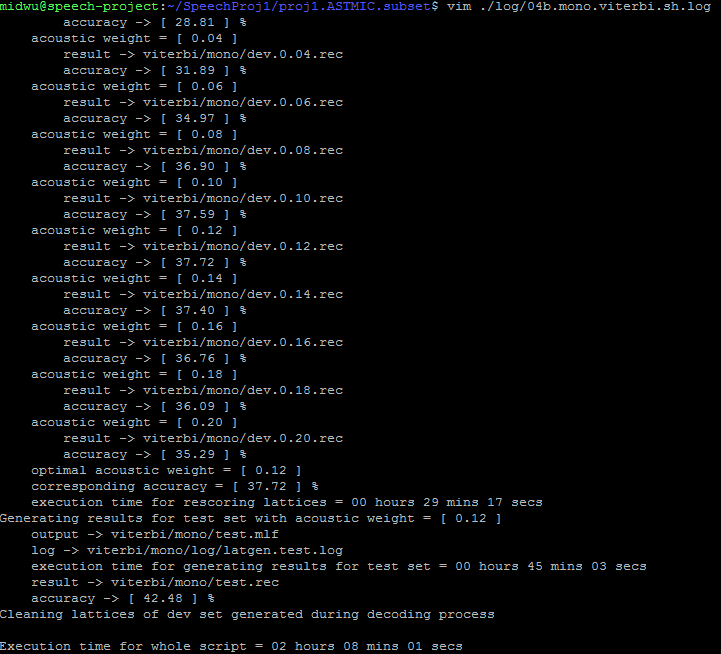
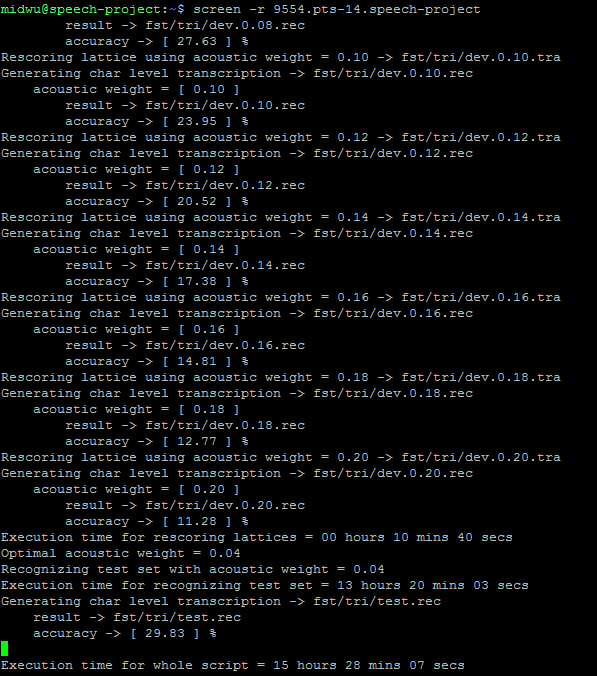
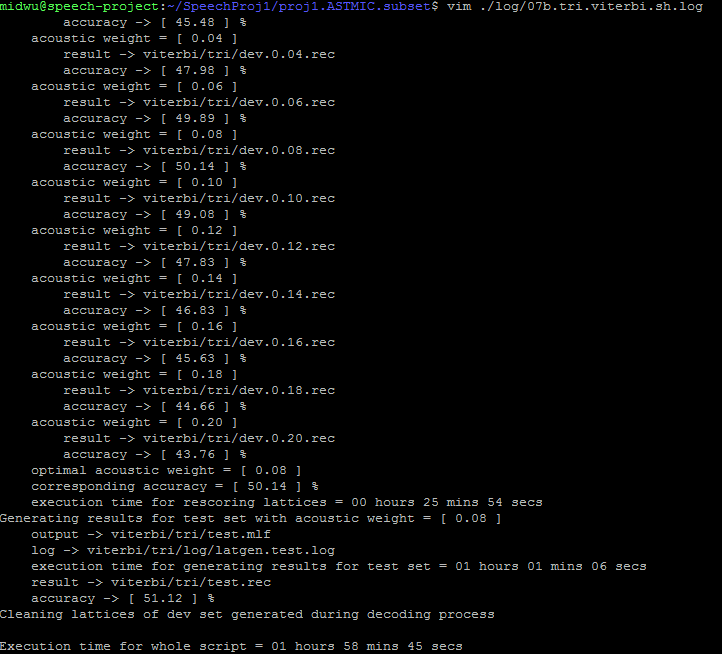
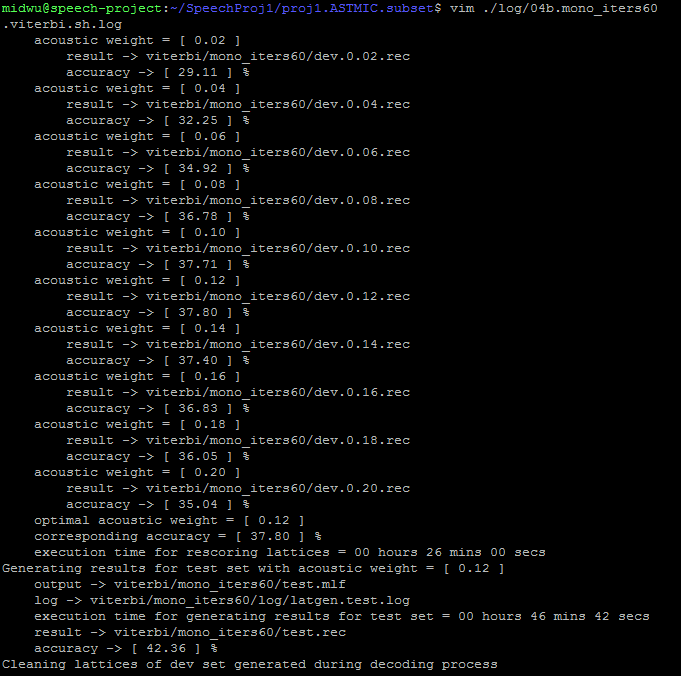
LM training, WFST decoding, Viterbi decoding
Work Flow
mono_iters40_*
WFST
Viterbi
tri_iters40_*
WFST
Viterbi
Observation:
Decoding time of *_WFSTs are too long, and the accuracies are not higher than *_viterbis !
mono_iters60_viterbi
Observation:
Viterbi outperforms WFST, while increasing iterations of HMM training does not result in better performance, and even worser ...
By Yu-An, Chung



