State Representation Learning
for
Reinforcement Learning
Antonin Raffin, Natalia Diaz-Rodriguez, Ashley Hill, René Traoré and David Filliat
INRIA Flowers Deep Reinforcement Learning Workshop
5th April 2018 - Paris
Outline
I. SRL and RL
II. Environment
III. Results
IV. Technical Details
State Representation Learning (SRL)
Jonschkowski, R., & Brock, O. (2015). Learning state representations with robotic priors. Autonomous Robots, 39(3), 407-428.

$$ o_t $$
$$ s_t $$
$$ a_t $$
$$\phi$$
$$\pi$$
Methods
Autoencoder (DAE) / VAE
+ Dual-Cam
Supervised Learning
Robotic Priors
PCA
Robotic Priors
1. Temporal Coherence
2. Proportionality
3. Repeatability
4. Causality
Environments


Baxter
Kuka
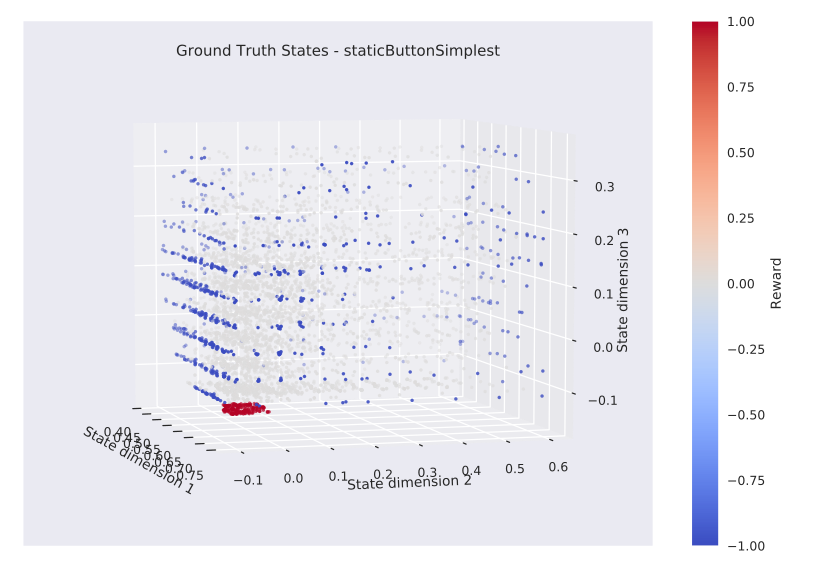
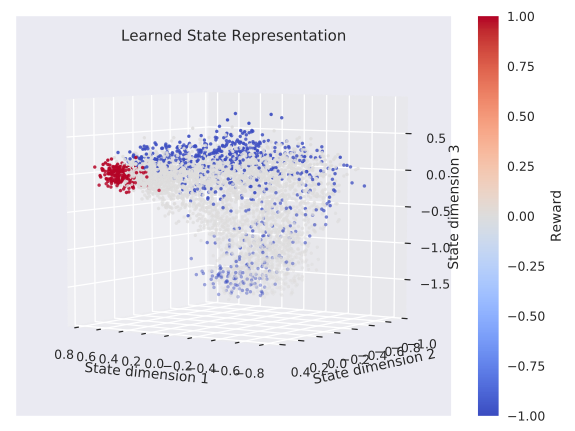
Learned States (Baxter)
Ground Truth
Robotic Priors
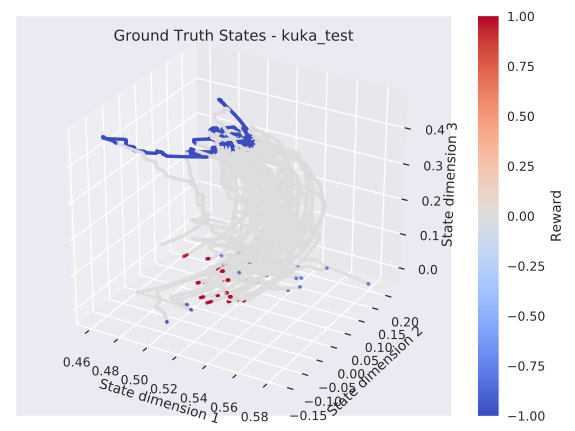
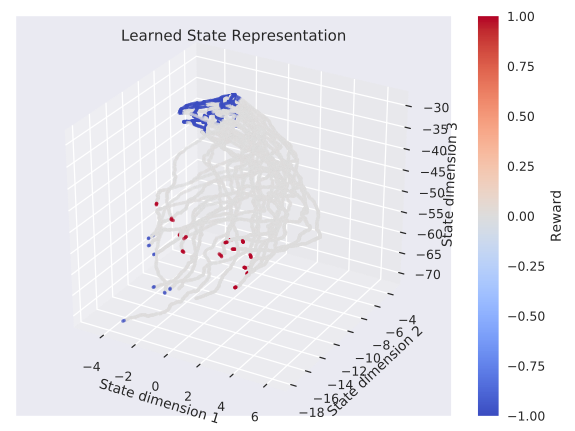
Learned States (Kuka)
Ground Truth
Robotic Priors
Evaluation
states that are neighbours in the ground truth should be neighbours in the learned state space
1. KNN-MSE
2. Reinforcement Learning
KNN-MSE
| Dataset | Ground Truth | Robotic Priors | Autoencoder | VAE | PCA |
|---|---|---|---|---|---|
| Baxter + Distractors | 0.024 | 0.079 | 0.099 | N.A. | N.A. |
| Kuka - static button | 0.00248 | 0.00279 | 0.00281 | 0.00281 | 0.00425 |
RL Algorithms: OpenAI Baselines
DQN and variants
ACER: Sample Efficient Actor-Critic with Experience Replay
A2C: Advantage Actor Critic
PPO: Proximal Policy Optimization
DDPG: Deep Deterministic Policy Gradients
ARS: Augmented Random Search

RL Setting
Input Space
Action Space
Discrete $$(x,y,z)$$
Continuous $$(x,y,z)$$
Raw Pixels
$$o_t$$
Ground Truth $$(x,y,z)$$
Learned States
$$s_t$$
Joints
Continuous (joints space)
Learning Curve
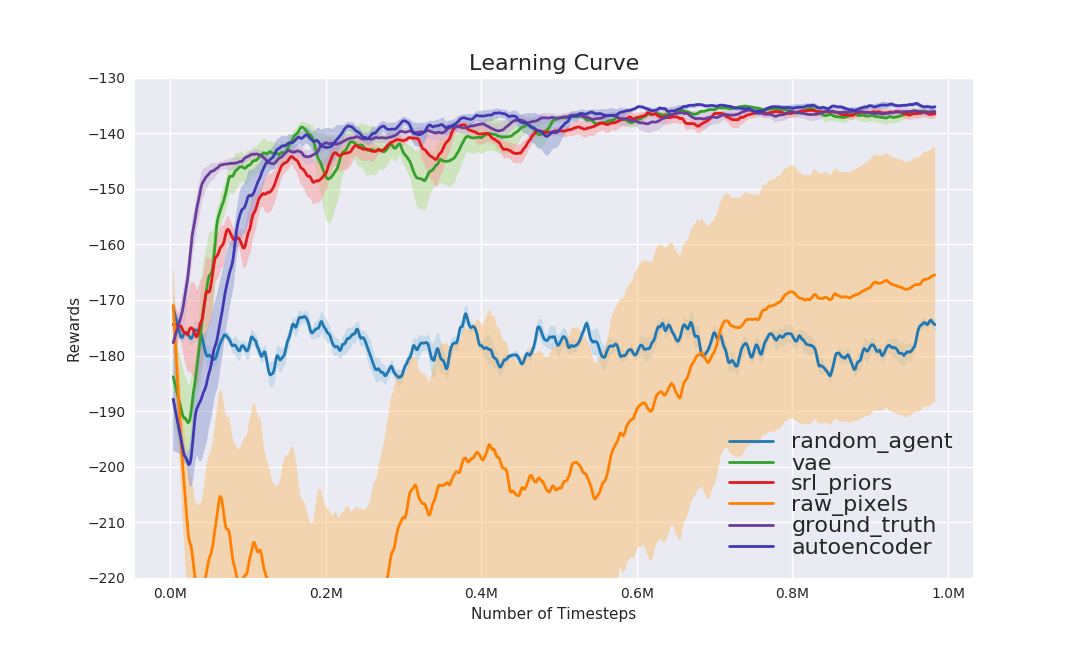
PPO
Tips and Tricks
Remove "up" action
Normalize states!
Exploration for SRL
Tweaking the reward
Software Stack

Simulator Fight
VS
Easy to use
Multiprocessing
No dependency

Documentation
Slow
Non deterministic
Visualization: Vizdom

Workflow: Git

Organization: Trello
Conclusion
SRL for RL: promising approach to reduce sample inefficiency
Ongoing work
- more complex tasks
- dual-cam
- real robot experiment
Thank You!


State Representation Learning for Reinforcement Learning
By Antonin Raffin




