


























Gülçin Yıldırım Jelínek
Staff Database Engineer @Xata, Main Organizer @Prague PostgreSQL Meetup, MSc, Computer and Systems Engineering @ Tallinn University of Technology, BSc, Applied Mathematics @Yildiz Technical University
Site Reliability Engineer @ 2ndQuadrant
Board Member @ PostgreSQL Europe
MSc Comp. & Systems Eng. @ Tallinn University of Technology
Writes on 2ndQuadrant blog
Does some childish paintings
Loves independent films
From Turkey
Lives in Prague
PostgreSQL
252
Database
208
Cloud
116
Upgrade
50
Offline Conversion
Online Conversion
[old-primary]
54.171.211.188
[new-primary]
54.246.183.100
[old-standbys]
54.77.249.81
54.154.49.180
[new-standbys:children]
old-standbys
[pgbouncer]
54.154.49.180
$ ansible-playbook -i hosts.ini pglupgrade.yml
Inventory file host.ini
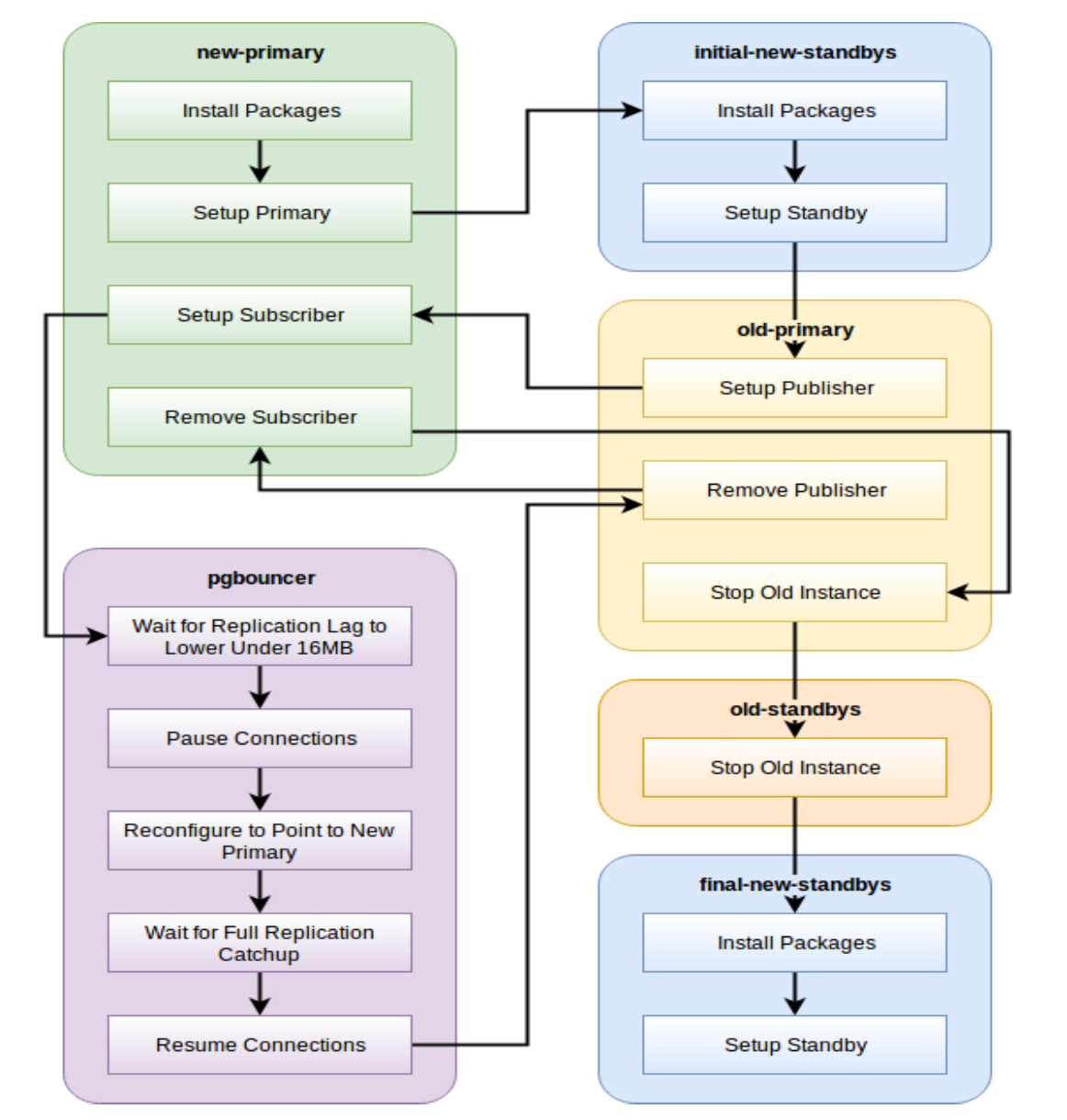
Running pglupgrade playbook
8 plays
config.yml
host.ini
orchestrates
the upgrade
operation
ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user={{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main"config.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| Metric (1st case) | pg_dump/pg_restore | pg_upgrade | pglupgrade |
|---|---|---|---|
| Primary Downtime | 00:24:27 | 00:16:25 | 00:00:03 |
| Partial cluster HA | 00:24:27 | 00:28:56 | 00:00:03 |
| Full cluster capacity | 01:02:27 | 00:28:56 | 00:38:00 |
| Length of upgrade | 01:02:27 | 00:28:56 | 01:38:10 |
| Extra disk space | 800 MB | 27 GB | 10 GB |
| Metric (2nd case) | pg_dump/pg_restore | pg_upgrade | pglupgrade |
|---|---|---|---|
| Primary Downtime | 00:23:52 | 00:17:03 | 00:00:05 |
| Partial cluster HA | 00:23:52 | 00:54:29 | 00:00:05 |
| Full cluster capacity | 00:23:52 | 03:19:16 | 00:00:05 |
| Length of upgrade | 00:23:52 | 03:19:16 | 01:02:10 |
| Extra disk space | 800 MB | 27 GB | 10 GB |
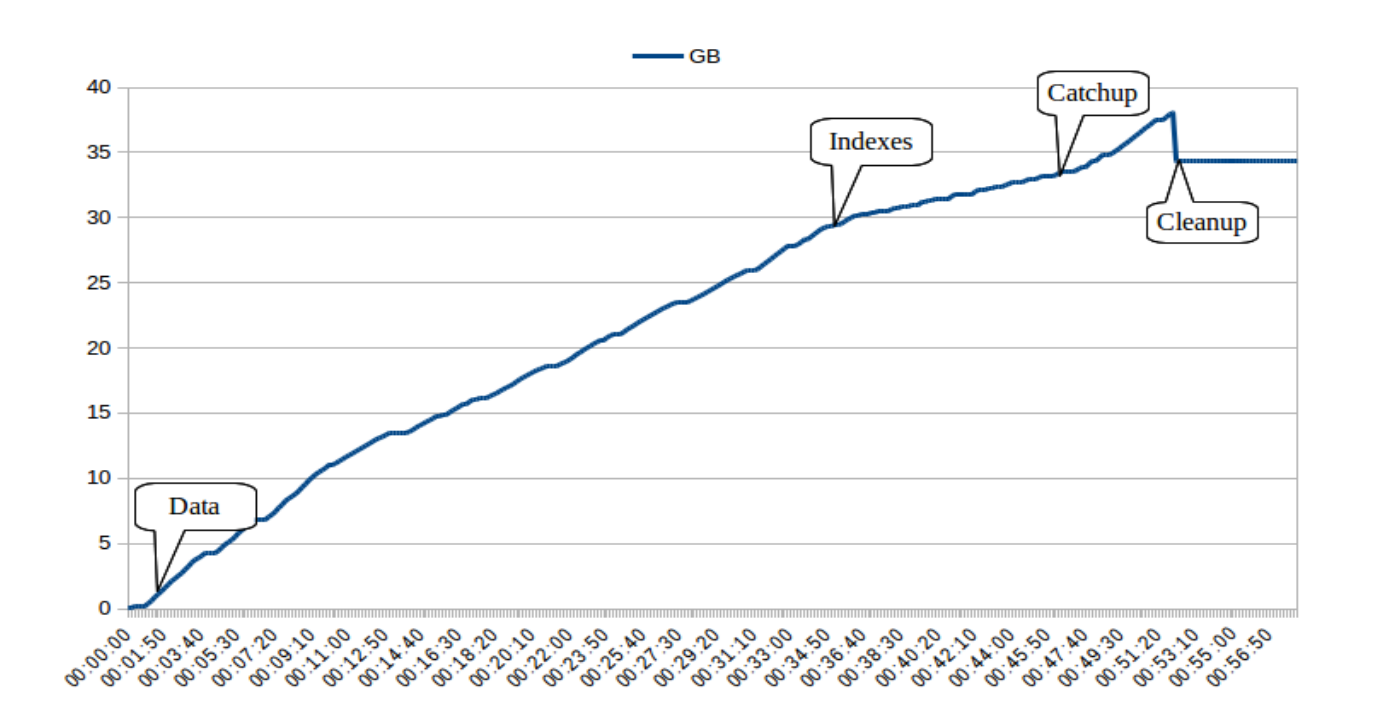
Database size growth during logical replication initialization
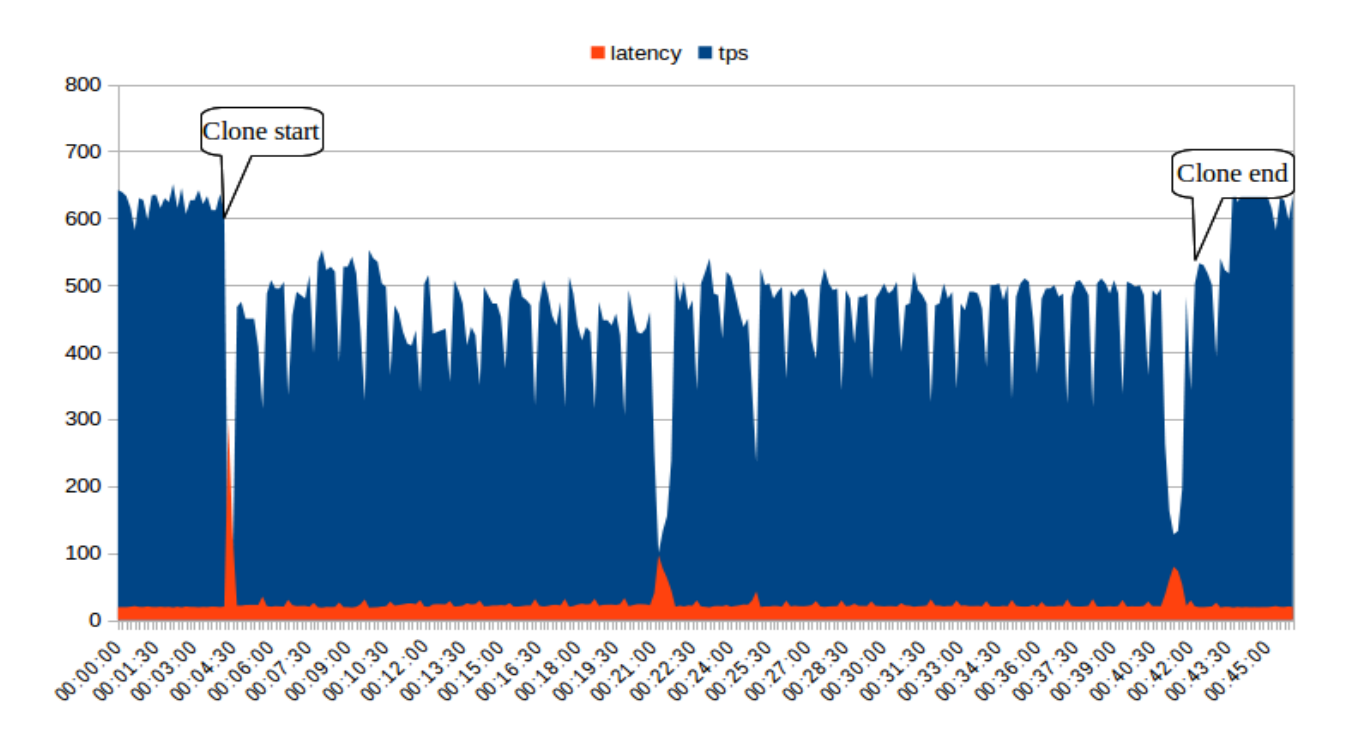
Transaction rate and latency during standby cloning process
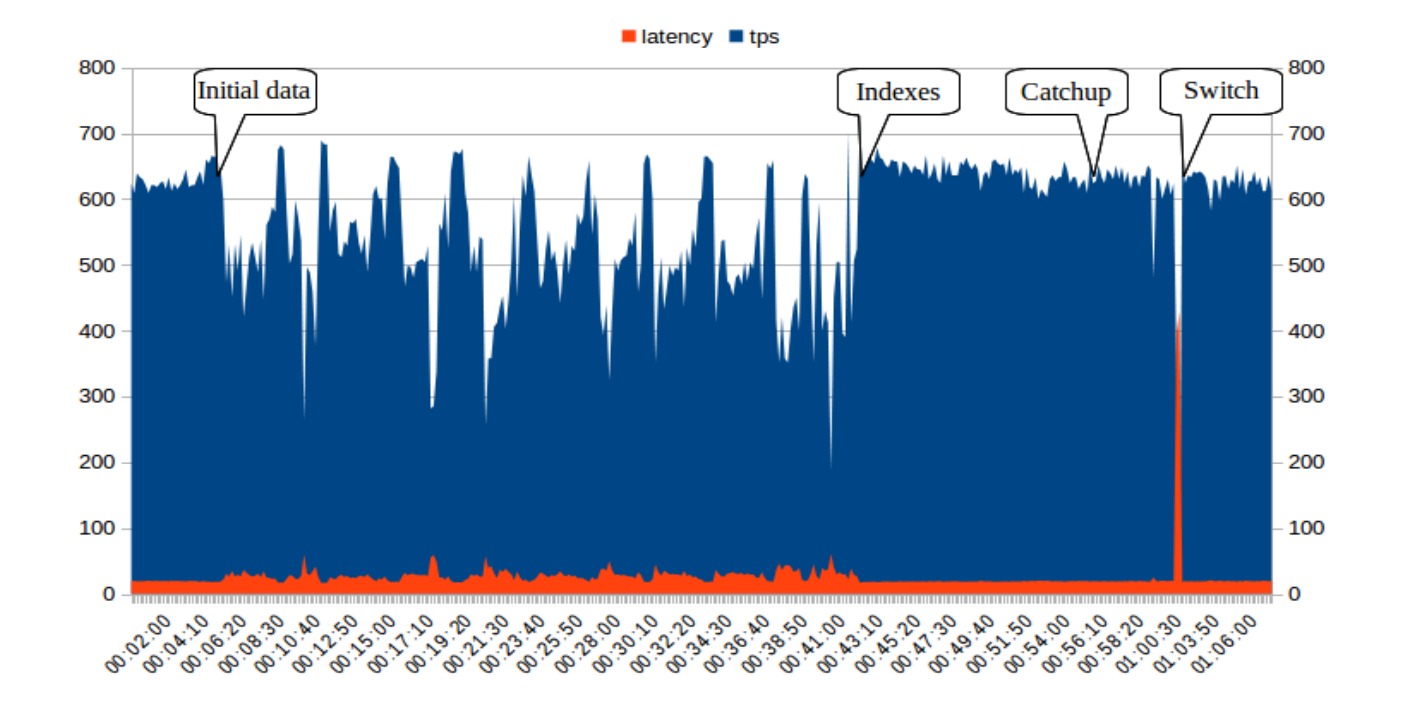
Transaction rate and latency during the upgrade process
Our Cloud offering engineered by
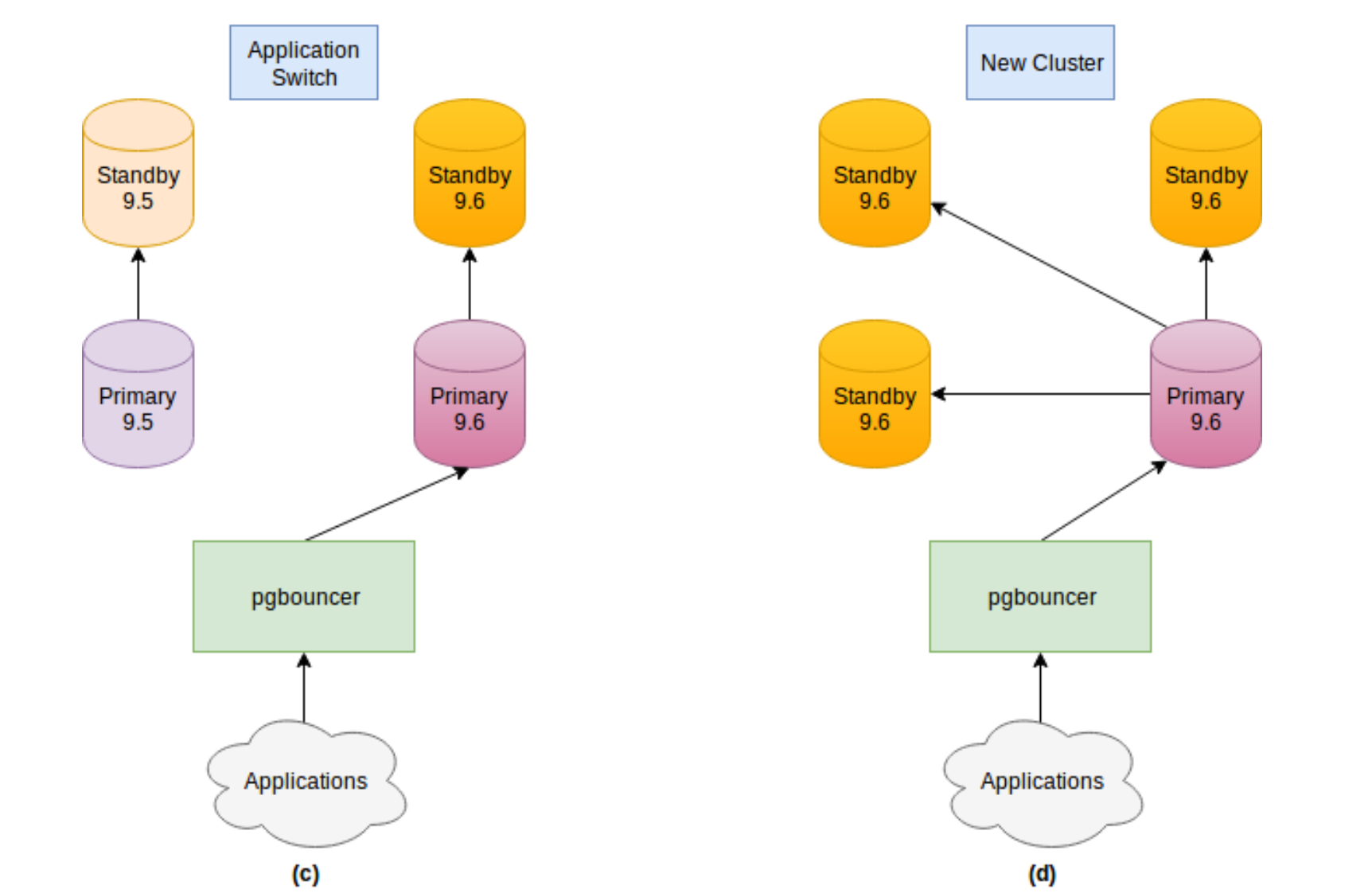
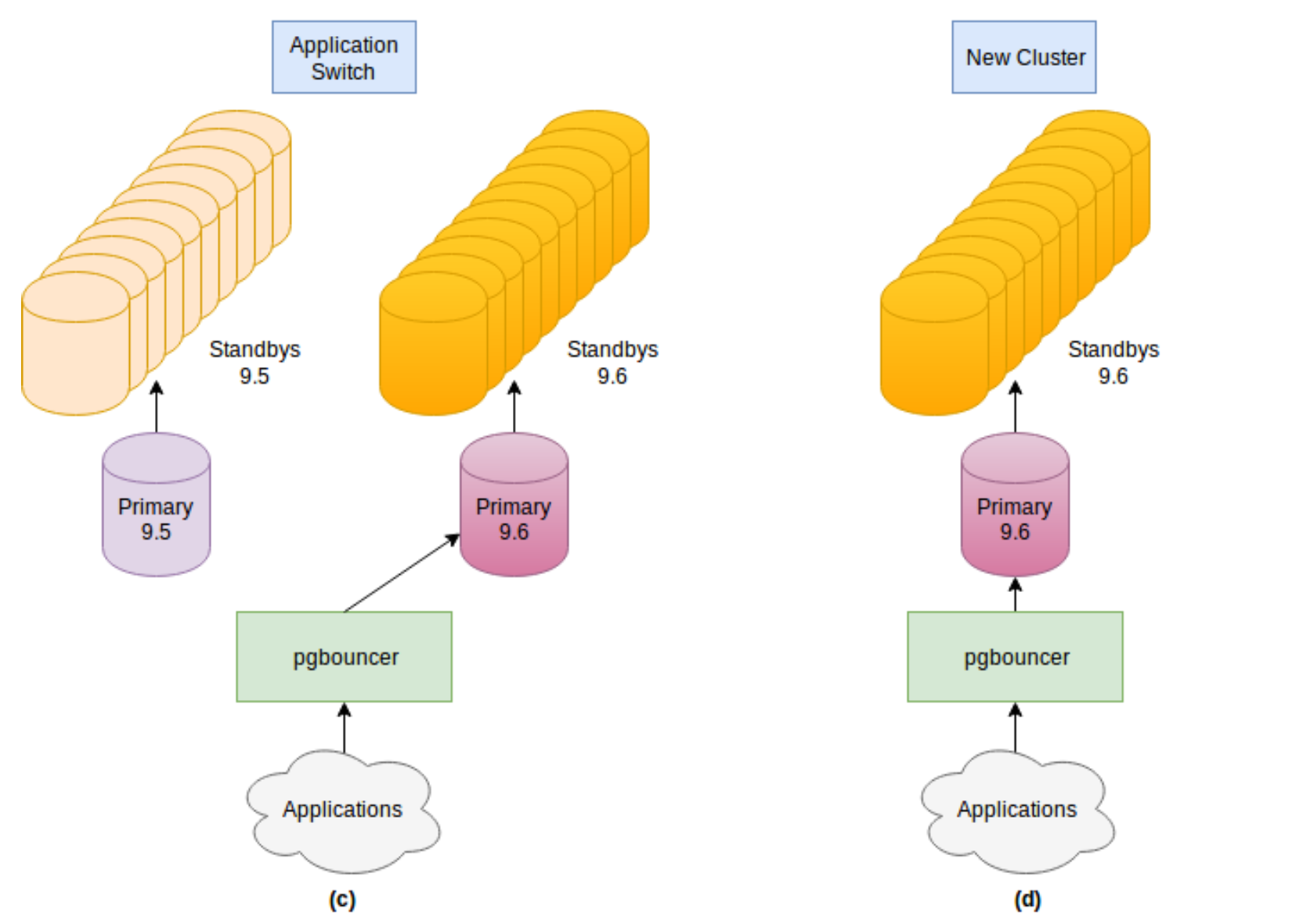
Database clusters can be upgraded with minimal downtime without users being affected while the upgrade is happening.
An application can still respond to the request only with a small drop in performance.
Case studies prove that pglupgrade minimizes the downtime to the level of 3-5 seconds.
By Gülçin Yıldırım Jelínek
This presentation is prepared for PGDay FOSDEM 2018 in Brussels.




