





Gülçin Yıldırım Jelínek
Staff Database Engineer @Xata, Main Organizer @Prague PostgreSQL Meetup, MSc, Computer and Systems Engineering @ Tallinn University of Technology, BSc, Applied Mathematics @Yildiz Technical University
Supports different data models: relational, document (JSON and XML), and key/value (hstore extension)
Highly extensible
All actions on the database are performed within transactions, protected by a transaction log that will perform automatic crash recovery in case of software failure.
Databases may be optionally created with data block checksums to help diagnose hardware faults. Multiple backup mechanisms exist, with full and detailed PITR, in case of the need for detailed recovery. A variety of diagnostic tools are available.
Database replication is supported natively.
Synchronous Replication can provide greater than "5 Nines" (99.999 percent) availability and data protection, if properly configured and managed.
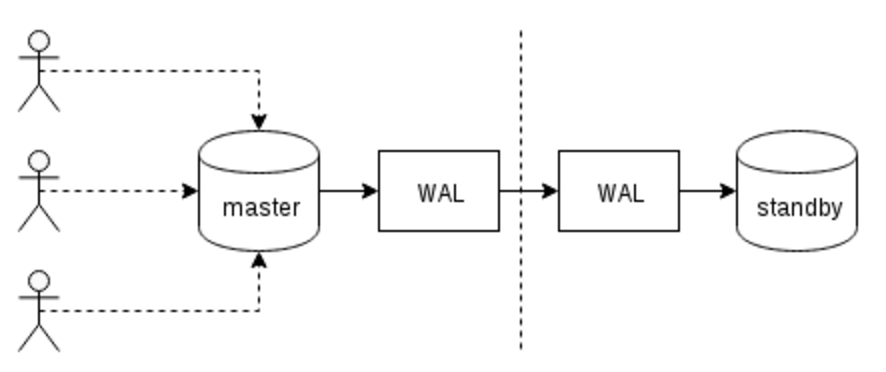
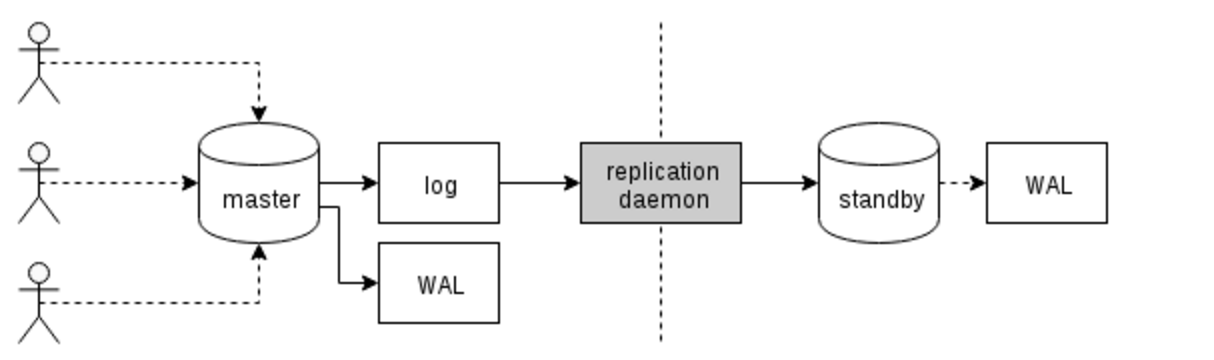
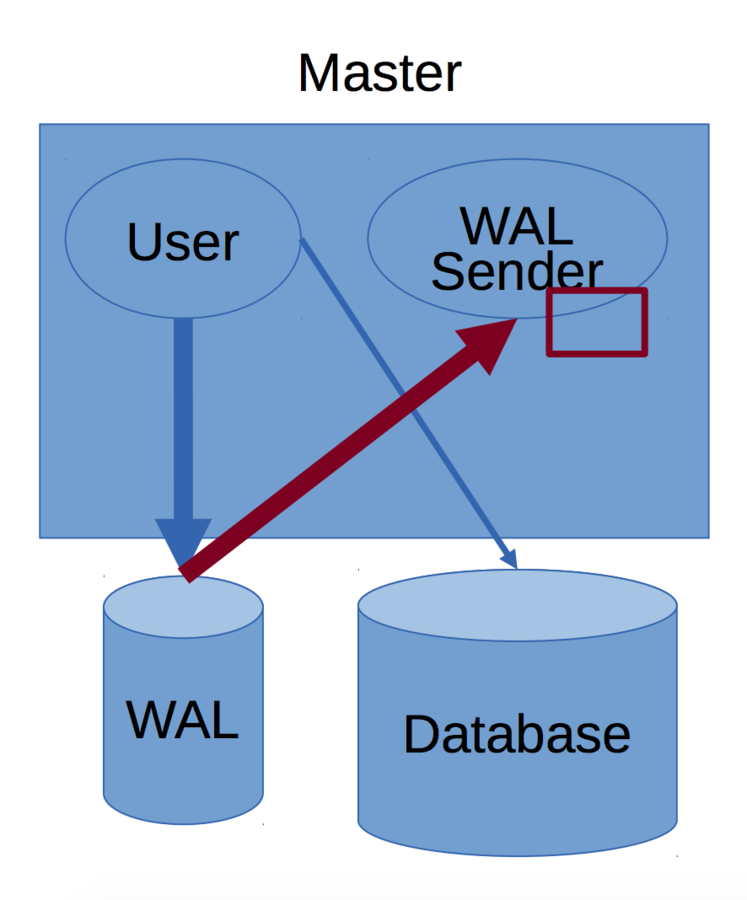
The WAL consists of a series of binary files written to the pg_xlog subdirectory of the PostgreSQL data directory.
Each change made to the database is recorded first in WAL, hence the name "write-ahead" log, as a synonym of "transaction log". When a transaction commits, the default—and safe—behaviour is to force the WAL records to disk.
Should PostgreSQL crash, the WAL will be replayed, which returns the database to the point of the last committed transaction, and thus ensures the durability of any database changes.
Database changes themselves aren't written to disk at transaction commit. Those changes are written to disk sometime later by the background writer on a well-tuned server. (WAL)
Transactions are a fundamental concept of all database systems. The essential point of a transaction is that it bundles multiple steps into a single, all-or-nothing operation.
The intermediate states between the steps are not visible to other concurrent transactions, and if some failure occurs that prevents the transaction from completing, then none of the steps affect the database at all. ( PostgreSQL does not support dirty-reads. )
Crash recovery replays the WAL, but from what point does it start to recover?
Recovery starts from points in the WAL known as checkpoints. The duration of crash recovery depends on the number of changes in the transaction log since the last checkpoint. A checkpoint is a known safe starting point for recovery, since it guarantees that all the previous changes to the database have already been written to disk.
A checkpoint can be either immediate or scheduled. Immediate checkpoints are triggered by some action of a superuser, such as the CHECKPOINT command or other; scheduled checkpoints are decided automatically by PostgreSQL.
Database replication is the term we use to describe the technology used to maintain a copy of a set of data on a remote system.
The existing replication is more properly known as Physical Streaming Replication since we are streaming a series of physical changes from one node to another. That means that when we insert a row into a table we generate change records for the insert plus all of the index entries.
When we VACUUM a table we also generate change records.
Also, Physical Streaming Replication records all changes at the byte/block level, making it very hard to do anything other than just replay everything.
WAL over network from master to standby
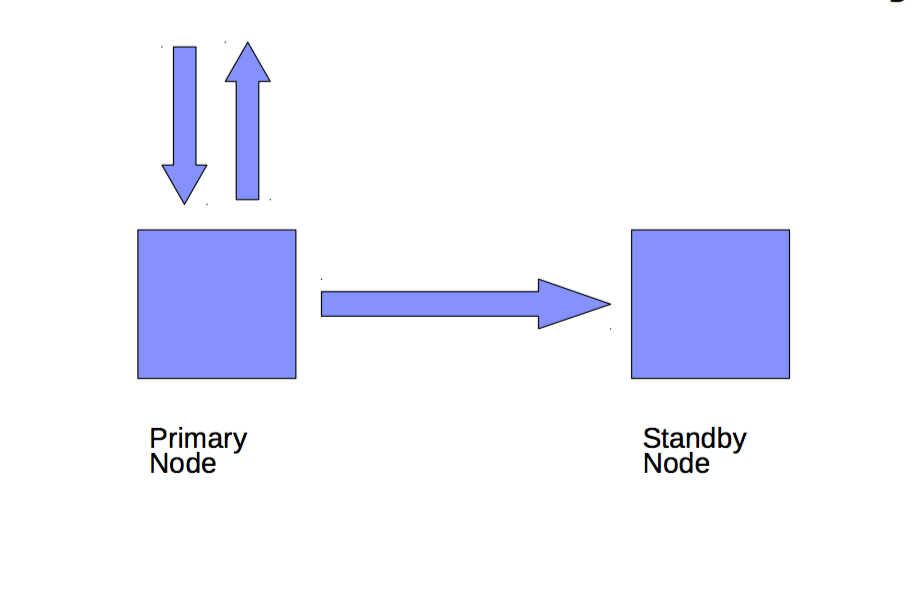
Warm Standby
Can be activated immediately, but cannot perform
useful work until activated
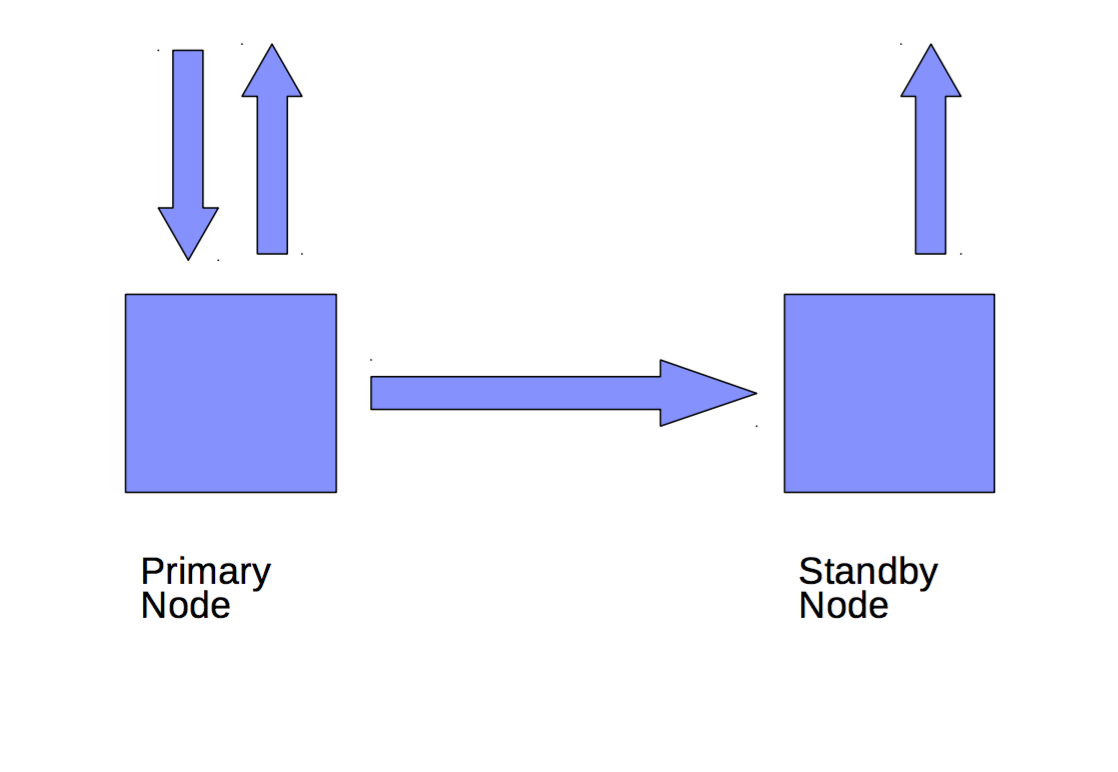
Hot Standby
Node is already active
Read-only queries only
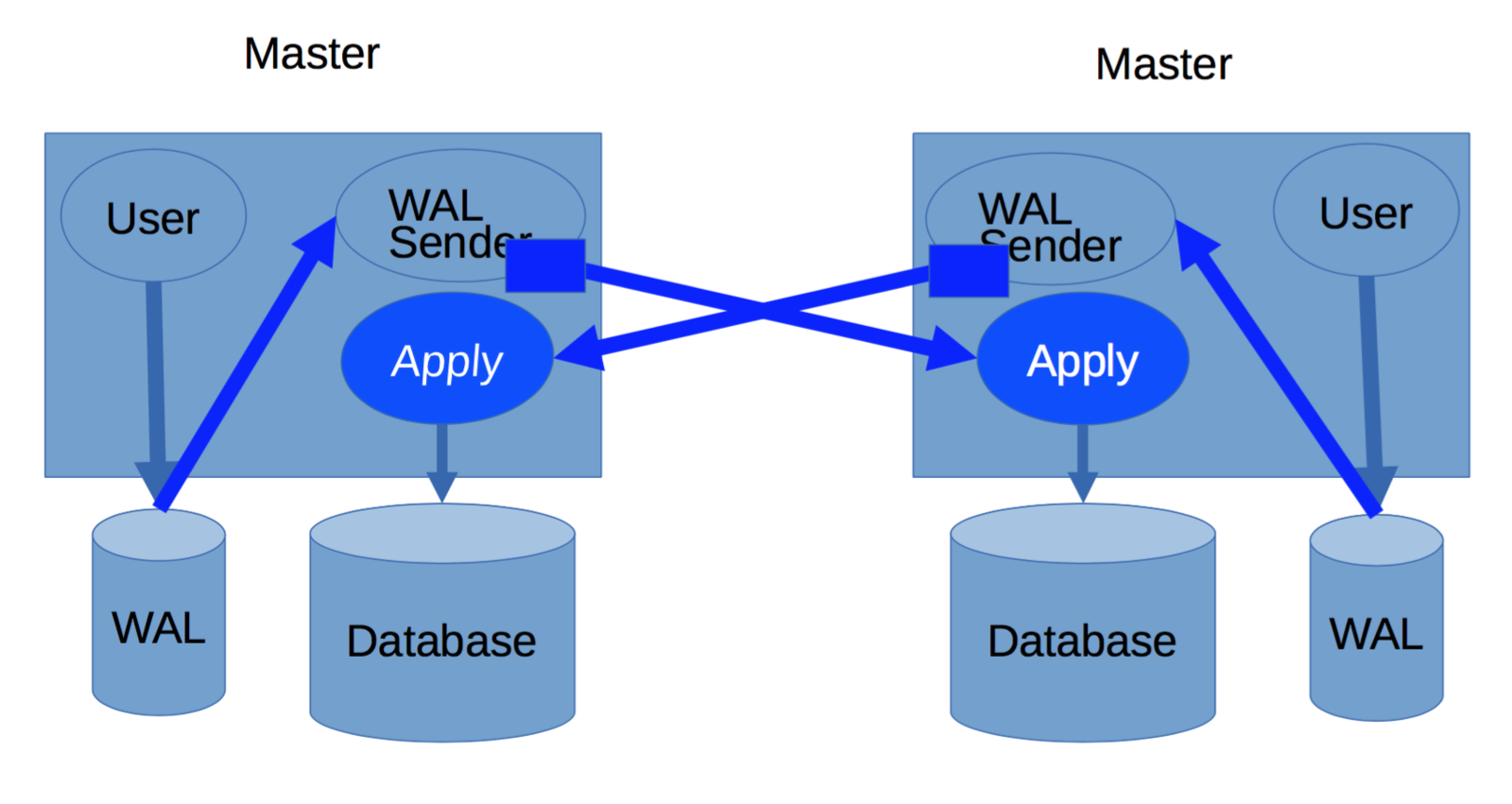
Multi-Master
All nodes can perform read/write work
Warm Standby
Hot Standby
In single-master replication, if the master dies, one of the standbys must take its place ( promotion ). Otherwise, we will not be able to accept new write transactions. Thus, the term designations, master and standby, are just roles that any node can take at some point. To move the master role to another node, we perform a procedure named Switchover.
If the master dies and does not recover, then the more severe role change is known as a Failover. In many ways, these can be similar, but it helps to use different terms for each event.
TL1
TL2
Master (Old master)
Standby (New master)
Failover
TL1
TL2
Master (Old master)
Standby (New master)
Switchover
TL1
TL2
Master (Old master)
Standby (New master)
By default, PostgreSQL implements asynchronous replication, where data is streamed out whenever convenient for the server. As we've seen this can mean data loss in case of failover. It's possible to ask Postgres to require one (or more) standbys to acknowledge replication of the data prior to commit, this is called synchronous replication ( synchronous commit ).
With synchronous replication, the replication delay directly affects the elapsed time of transactions on the master. With asynchronous replication, the master may continue at full speed.
Synchronous replication guarantees that data is written to at least two nodes before the user or application is told that a transaction has committed.
The user can select the commit mode of each transaction, so that it is possible to have both synchronous and asynchronous commit transactions running concurrently.
This allows flexible trade-offs between performance and certainty of transaction durability.
Unlike physical replication which captures changes to the raw data on disk, the logical replication captures the logical changes to the individual records in database and replicates those.
This allows for more complex replication topology than master and standby and also allows for partial replication of the database (selective replication) .
The logical records work across major releases, so we can use this to upgrade from one release to another.
There are two basic approaches to logical replication, the trigger-based and the changeset extraction (called logical decoding in PostgreSQL).
Bi-directional Replication
By Gülçin Yıldırım Jelínek
This presentation is created for Dependability and Fault Tolerance course of Computer Systems Engineering master programme at Tallinn University of Technology.



