









Gülçin Yıldırım Jelínek
Staff Database Engineer @Xata, Main Organizer @Prague PostgreSQL Meetup, MSc, Computer and Systems Engineering @ Tallinn University of Technology, BSc, Applied Mathematics @Yildiz Technical University
Postgres DBA @ 2ndQuadrant
Studying MSc Comp. & Systems Eng. @ Tallinn University of Technology
Studied BSc Maths Eng. @ Yildiz Technical University
Writes blog on 2ndQuadrant blog
Does some childish paintings
Loves independent films
Simple, agentless and powerful open source IT automation tool
The technology: APIs, Cloud Management
Nearly every major service has an API these days.
The need: More and more products are now composed of distributed components. More moving parts. They need to be managed.
The practise: It is now common to automate builds, tests, deployments, integration. Infrastructure is the next thing to automate.
Multiple ssh, control panels, editing config files manually.
apt-get install python-dev python-setuptools
easy_install pip
pip install ansible boto
sudo easy_install pip
sudo pip install ansible boto
Before we start discussing Ansible in more detail,
please check the repo that I created for this talk:
github.com/gulcin/pgconfeu2015
In this example, we will:
Why do we need a better & modern approach?
Continuous delivery means adopting a fast and simple approach for releases.
Ansible helps us with two main aspects:
You need to be sure about security of your:
Once the security policy has been set, Ansible can be used to turn the system back into the compliance mode, instantly.
Ansible is easy-to-use whether it’s about:
Ansible ensures that all tasks are executed in the proper order.
This makes orchestration of complex multi-tier deployments easier.
For example, considering the deployment of a software stack, Ansible makes sure that:
We will see this in action with our demo.
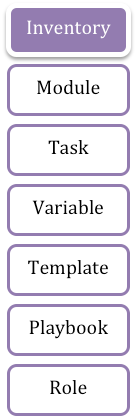
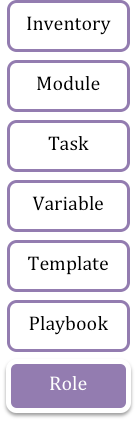
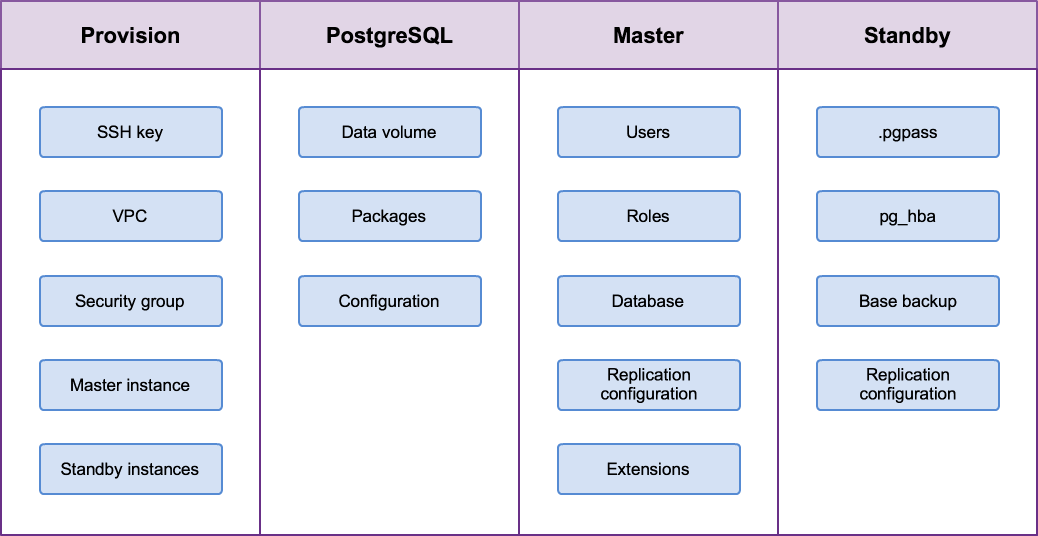
An Ansible solution is composed of one or more items listed on the left side.
Typically, our solutions executes tasks for an inventory, utilizing some modules, using or populating some variables, processing some file templates, in a playbook, which can be organized in roles.
Let's see each of them in detail.
Below inventory file in INI format contains 3 hosts under 2 groups.
There is also a 3rd group which contains other groups and all of the hosts.
# "master" group with 1 host
[master]
postgresql-master ansible_ssh_host=10.0.0.5 ansible_ssh_user=ubuntu
# "standby" group with 2 hosts
[standbys]
postgresql-standby-01 ansible_ssh_host=10.0.0.10 ansible_ssh_user=ubuntu
postgresql-standby-02 ansible_ssh_host=10.0.0.11 ansible_ssh_user=ubuntu
# the "replication" group contains both "master" and "standbys" groups
[replication:children]
master
standbysSome of the most commonly used modules are:
Tasks are responsible for calling a module with a specific set of parameters.
Each Ansible task contains:
They allow us to call Ansible modules and pass information to consecutive tasks.
Below task invokes the "file" module by providing 4 parameters. It ensures 3 conditions are true:
If it doesn't exist, Ansible creates the directory and assigns owner & group. If only the owner is different, Ansible makes it "postgres".
- name: Ensure the data folder has right ownership
file: path="/var/lib/postgresql" state=directory owner=postgres group=postgres
Following example shows relationships between tasks. The first task checks if a device exists and the second task mounts the device depending on the result from the first task.
Please note "register" and "when" keywords.
- name: Check if the data volume partition exists
stat: path=/dev/sdc1
register: partition
- name: Ensure the PostgreSQL data volume is mounted
mount: src=/dev/sdc1 name="/var/lib/postgresql/9.4" fstype=ext4 state=mounted
when: partition.stat.exists is defined and partition.stat.existsVariables in Ansible are very useful for reusing information. Sources for variables are:
There is also discovered variables (facts) and they can be found by using setup module:
You can use variables in tasks, templates themselves and you can iterate over using with_type functions.
ansible -i hosts.ini -m setup hostname- name: Ensure PostgreSQL users are present
postgresql_user:
state: present
name: "{{ item.name }}"
password: "{{ item.password }}"
role_attr_flags: "{{ item.roles }}"
with_items: postgresql_usersWe can think templates as our configuration files. Ansible lets us use the Jinja2 template engine for reforming and parameterising our files.
The Jinja2 templating engine offers a wide range of control structures, functions and filters..
Some of useful capabilities of Jinja2:
*:*:*:{{ postgresql_replication_user.name }}:{{ postgresql_replication_user.password }}
Let's check our pgpass.j2 template:
Let's have a look at pg_hba.conf.j2 file, too:
# Access to user from local without password, from subnet with password
{% for user in postgresql_users %}
local all {{ user.name }} trust
host all {{ user.name }} {{ ec2_subnet }} md5
{% endfor %}
# Replication user for standby servers access
{% for standby_ip in postgresql_standby_ips %}
host replication {{ postgresql_replication_user.name }} {{ standby_ip }}/32 md5
{% endfor %}
Strict dependency ordering: everything in file performs in a sequential order.
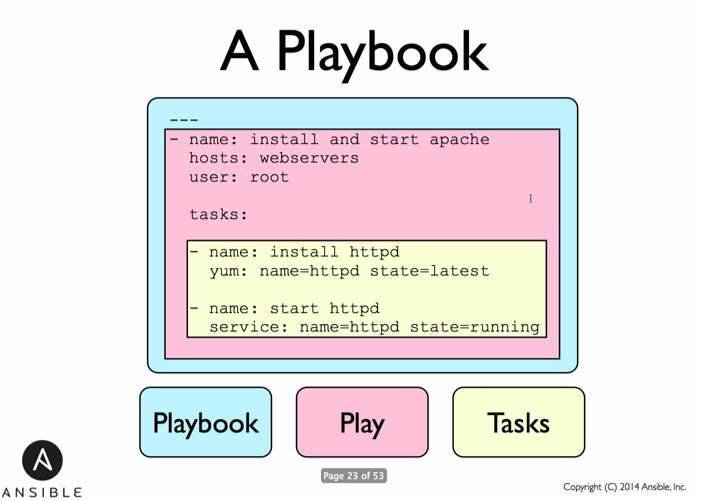
Let's look at our playbook example (main.yml):
---
- name: Ensure all virtual machines are ready
hosts: 127.0.0.1
connection: local
vars_files: # load default variables from YAML files below
- 'defaults/postgresql.yml'
- 'defaults/aws.yml'
tasks:
- include: 'tasks/provision.yml' # load infrastructure setup tasks
- name: Ensure all required PostgreSQL dependencies ready
hosts: postgresql-all # manage all PostgreSQL servers
sudo: yes
sudo_user: root
vars_files:
- 'defaults/postgresql.yml'
- 'defaults/aws.yml'
tasks:
- include: 'tasks/postgresql.yml' # load PostgreSQL setup tasks
...You absolutely should be using roles. Roles are great. Use roles. Roles! Did we say that enough? Roles are great.
In Ansible,
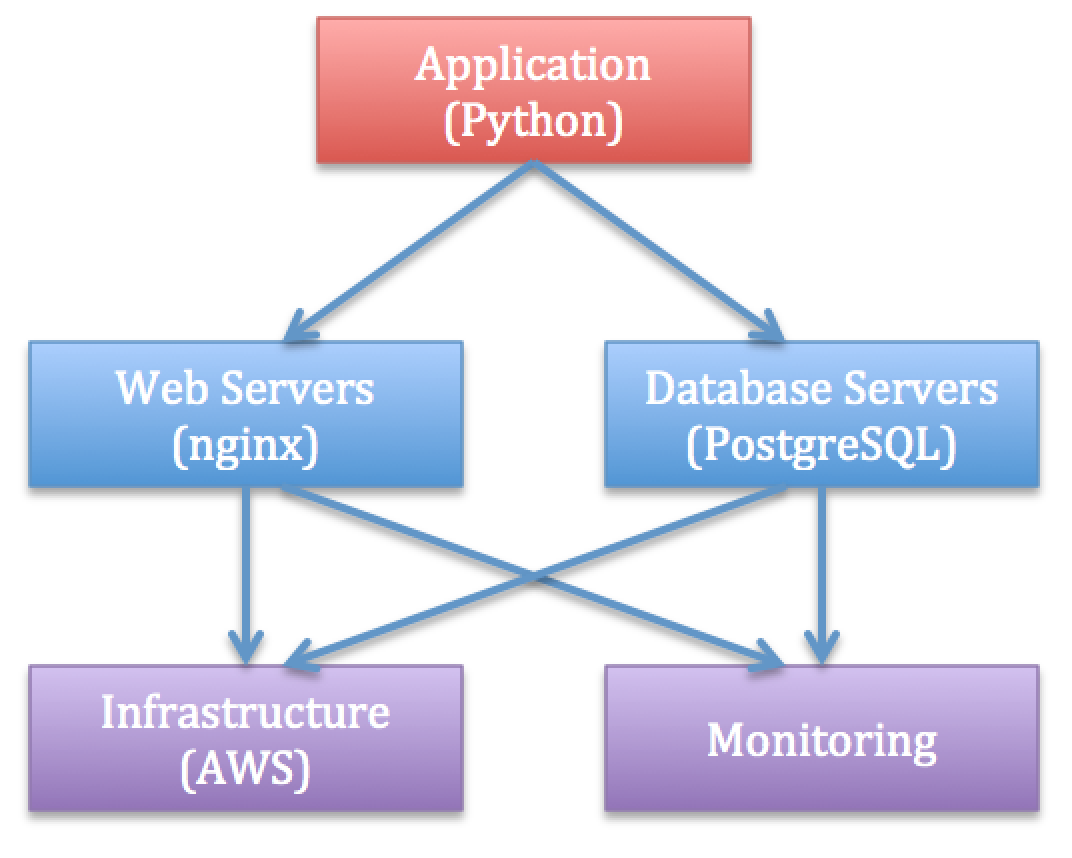
Imagine that we have lots of independent resources to manage (e.g., web servers, PostgreSQL servers, logging, monitoring, AWS, ...).
Putting everything in a single playbook may result in an unmaintainable solution.
To reduce such complexity, roles help us with:
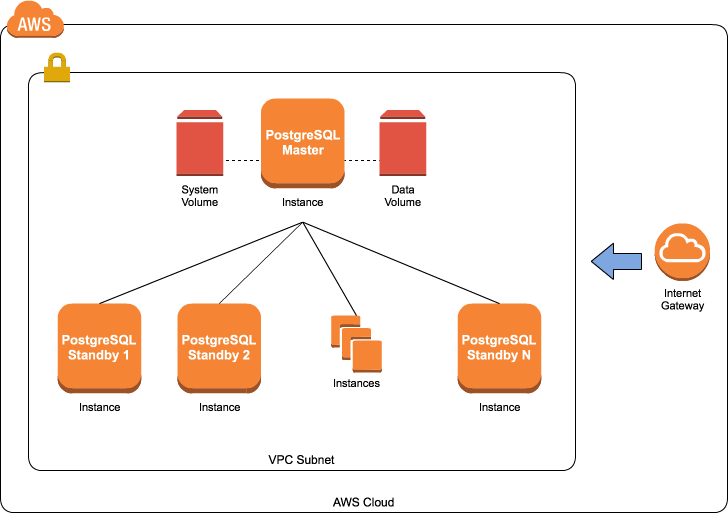
Here you can see a dependency graph and the corresponding role directory structure:
To work with Ansible, we have 2 main alternatives;
Let's check them out one by one.
We can call any Ansible module from the command line, anytime.
The ansible CLI tool works like a single task. It requires an inventory, a module name, and module parameters.
For example, given an inventory file like:
[dbservers] db.example.com
Now we can call any module.
We can check uptimes of all hosts in dbservers using:
ansible dbservers -i hosts.ini -m command -a "uptime"
Here we can see the Ansible output:
gulcin@apathetic ~ # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
For more complex scenarios, we can create playbooks or roles and ask Ansible to run them.
When we run a playbook or a role, Ansible first gathers a lot of useful facts about remote systems it manages. These facts can later be used in playbooks, templates, config files, etc.
We can use the ansible-playbook CLI tool to run playbooks.
Given an inventory file like this:
[dbservers]
db.example.com
We may have a playbook that connects to hosts in dbservers group, executes the uptime command, and then displays that command's output.
Now let's create a simple playbook to see how it can be ran.
Here is the main.yml file for the playbook we just described:
---
- hosts: dbservers
tasks:
- name: retrieve the uptime
command: uptime
register: command_result # Store this command's result in this variable
- name: Display the uptime
debug: msg="{{ command_result.stdout }}" # Display command output here
Now we can run the playbook and see it's output here:
gulcin@apathetic ~ $ ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [retrieve the uptime] ***************************************************
changed: [db.example.com]
TASK: [Display the uptime] ****************************************************
ok: [db.example.com] => {
"msg": " 15:54:47 up 3 days, 14:32, 2 users, load average: 0.00, 0.01, 0.05"
}
PLAY RECAP ********************************************************************
db.example.com : ok=3 changed=1 unreachable=0 failed=0
N.B! register assigns result of a task to a variable.
Ansible supports iterating over facts with loop statements:
Some other with_type functions:
with_together, with_nested, with_subelements, with_sequence,
with_random_choice, with_first_found, with_lines..
- vars:
postgresql_users:
- { name: gulcin, password: apathetic, roles: "SUPERUSER,LOGIN" }
- { name: foo, password: foobarbaz, roles: "CREATEDB,LOGIN" }
- name: Ensure PostgreSQL users are present
postgresql_user:
state: present
name: "{{ item.name }}"
password: "{{ item.password }}"
role_attr_flags: "{{ item.roles }}"
with_items: postgresql_users
- name: Ensure standby hosts have updated IP addresses
add_host:
name: "postgresql-standby-{{ item.0 + 1 }}" # e.g., postgresq-standby-1
groups: "postgresql-standbys"
ansible_ssh_host: "{{ item.1.tagged_instances[0].public_ip }}"
ansible_ssh_user: "{{ ec2_ssh_user }}"
with_indexed_items: ec2_standbys.results
- name: Wait for SSH to become ready
wait_for: host="{{ item.tagged_instances[0].public_ip }}" port=22 timeout=320 state=started
with_flattened:
- [ ec2_master ] # ec2_master is a single item.
# By putting [ and ], we convert it into an array
- ec2_standbys.results
- name: Ensure the SSH key is present
ec2_key:
state: present
region: "eu-central-1" # Amazon's Frankfurt Datacenter
name: "postgresql-key" # we will use this name later
key_material: "{{ item }}"
with_file: "id_rsa.pub" # reads contents of this file to use in "key_material"For some advanced operations, we can use following in our tasks:
My blog post covers Ansible PostgreSQL modules: Ansible Loves PostgreSQL
You can find the related Postgres modules' examples on my github repo.
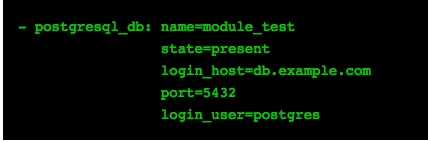
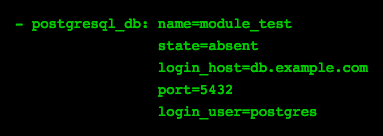
Creates/removes a given db. In Ansible terminology, it ensures that a given db is present or absent.
Create db module_test
Remove db module_test
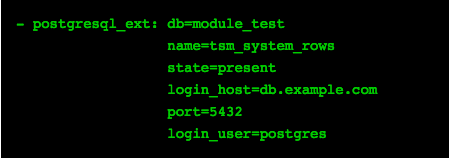
Adds/removes extensions from a db. PostgreSQL offers a wide range of extensions which are extremely helpful.
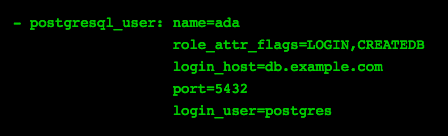
Adds/removes users and roles from a db.
Parameters: name (mandatory), state, connection params, db, password, priv, role_attr_flags ([NO]SUPERUSER, [NO]CREATEDB..)
Creates user
Alters role and gives login and createdb
Grants/revokes privileges on db objects (table, sequence, function, db, schema, language, tablespace, group).
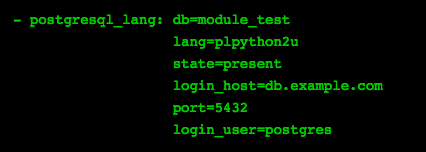
Adds, removes or changes procedural languages with a db.
One of the very powerful features of PostgreSQL is its support for virtually any language to be used as a procedural language.
Params: lang (mandatory), db, connection params, state, cascade, trust
Ansible provides more than 50 modules for provisioning and managing Amazon Web Services resources.
http://docs.ansible.com/ansible/list_of_cloud_modules.html
We have modules for:
Ansible AWS modules are developed using Boto.
Boto is a Python package that provides interfaces to Amazon Web Services.
For more complex workflows, we can use the ec2.py script to discover dynamic inventories for our playbooks:
Manages SSH key pairs that we use to connect to our instances.
Parameters:
- name: Ensure the SSH key is present
ec2_key:
state: present
region: "eu-central-1" # Amazon's Frankfurt Datacenter
name: "postgresql-key" # we will use this name later
key_material: "{{ item }}"
with_file: "id_rsa.pub" # reads contents of this file to use in "key_material"Manages virtual private clouds & networking.
- name: Ensure VPC is present
ec2_vpc:
state: present # Create a VPC
region: "eu-central-1" # Amazon's Frankfurt Datacenter
cidr_block: "10.0.0.0/20"
subnets:
- cidr: "10.0.0.0/20"
route_tables:
- subnets: [ "10.0.0.0/20" ]
routes:
- dest: 0.0.0.0/0 # Everywhere
gw: igw # Name of Amazon's default gateway
internet_gateway: yes # We want our instances to connect to internet
wait: yes # Wait until the VPC is ready
resource_tags: { environment: "production", tier: "DB" }
register: vpc # Store task results in this variable to use in later tasksManages firewalls.
- name: Ensure the PostgreSQL security group is present
ec2_group:
state: present
vpc_id: "{{ vpc.vpc_id }}" # Obtain recently provisioned VPC's ID
region: "eu-central-1" # Amazon's Frankfurt Datacenter
name: "PostgreSQL"
description: "Security group for PostgreSQL database servers"
rules:
- proto: tcp # Allow SSH access from anywhere
from_port: 22
to_port: 22
cidr_ip: 0.0.0.0/0
- proto: all # Allow everything from machines in the subnet
from_port: -1 # Any port
to_port: -1 # Any port
cidr_ip: "10.0.0.0/20"
register: security_group # Use results of this task later
Creates, deletes, starts, stops, restarts virtual machine instances.
{[ device_name: NAME, volume_size: SIZE, delete_on_termination: FLAG ]}
- name: Ensure master EC2 instances & volumes are present
ec2:
assign_public_ip: yes # our machines should access internet
instance_tags: { Name: "pg-master {{ postgresql_master_ip }}", environment: "production" }
exact_count: 1
count_tag:
Name: "pg-master {{ postgresql_master_ip }}"
image: "ami-accff2b1" # Ubuntu Server 14.04
instance_type: "t2.micro"
group_id: "{{ security_group.group_id }}"
key_name: "postgresql-key"
private_ip: "{{ postgresql_master_ip }}" # e.g., 10.0.0.5
region: "eu-central-1" # Amazon's Frankfurt Datacenter
volumes:
- device_name: /dev/sdc
volume_size: "50" # 50GB disk volume
delete_on_termination: false # Volume should remain after instance is deleted
vpc_subnet_id: "{{ vpc.subnets[0].id }}"
wait: yes # Wait until the instance becomes running
register: ec2_master # Register results here so we can use them later
Ansible loves PostgreSQL and Ansible has a very active community.
<wishlist>
That's why more PostgreSQL modules would be helpful for everyone.
Making contributions to Ansible will be appreciated :)
</wishlist>
Ansible quick start video http://www.ansible.com/videos
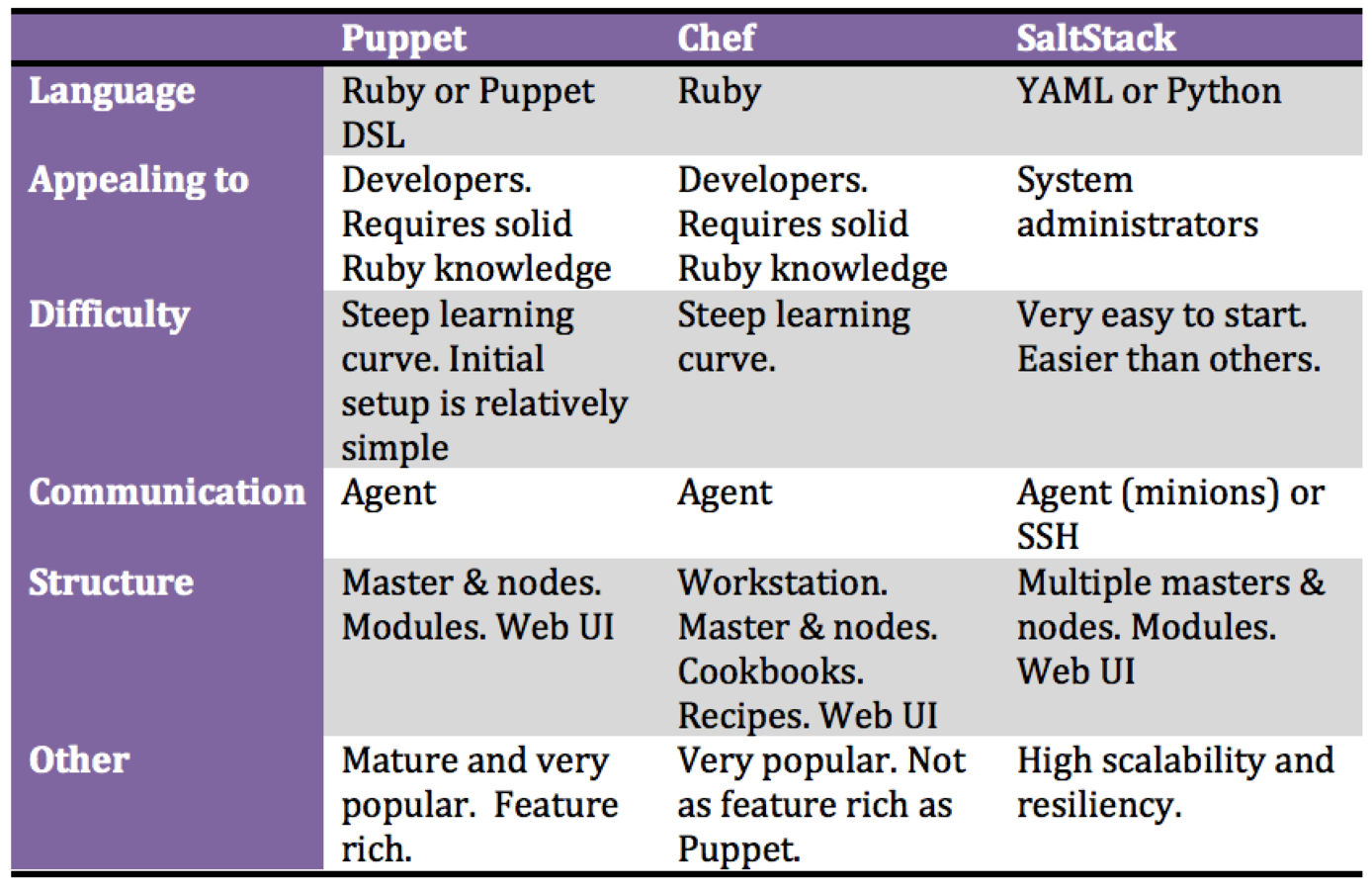
Review: Puppet vs Chef vs Ansible vs Salt http://www.infoworld.com/article/2609482/data-center/data-center-review-puppet-vs-chef-vs-ansible-vs-salt.html
Managing PostgreSQL with Ansible in EC2 https://www.safaribooksonline.com/library/view/velocity-conference-2013/9781449371630/part22.html
Jinja2 for better Ansible playbooks and templates
https://blog.codecentric.de/en/2014/08/jinja2-better-ansible-playbooks-templates/
Edmund The Elephant https://dribbble.com/shots/2223604-Edmund-The-Elephant
By Gülçin Yıldırım Jelínek
This presentation is prepared for PGConf Europe 2015 in Vienna.



