









apl3b PRO
A pleb
Threat Modeling ✨Magic✨
"Threat modeling is a process of identifying potential security threats and vulnerabilities in a system, application, or network infrastructure. It involves a systematic approach to identify, prioritize, and mitigate security risks. The goal of threat modeling is to understand the security posture of a system and to develop a plan to prevent or minimize the impact of potential attacks."
Defining the scope. (What are we working on?)
Building a model of the system.
(Dataflow diagram)
Thinking on what can go wrong.
(Threat scenarios)
Review and Iterate on what we could do better.
(Bypasses and defense in depth)
Design what can we do about it.
(Mitigations)
| Name | Description |
|---|---|
| STRIDE | Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, and Elevation of Privilege |
| DREAD | Damage, Reproducibility, Exploitability, Affected Users, and Discoverability |
| PASTA | Process for Attack Simulation and Threat Analysis |
| CAPEC | Common Attack Pattern Enumeration and Classification |
"Machine learning is a subfield of artificial intelligence that involves developing algorithms and statistical models that enable computer systems to learn and improve from experience without being explicitly programmed."
Data
Data
Data
Data
Most common
Trained on labeled data
Make predictions
Trained on unlabeled data
Identify clusters of similarity
Reduce data dimensionality
Mix of previous two
Improved performance
Based on feedback
Rewards system
Commonly seen on game bots
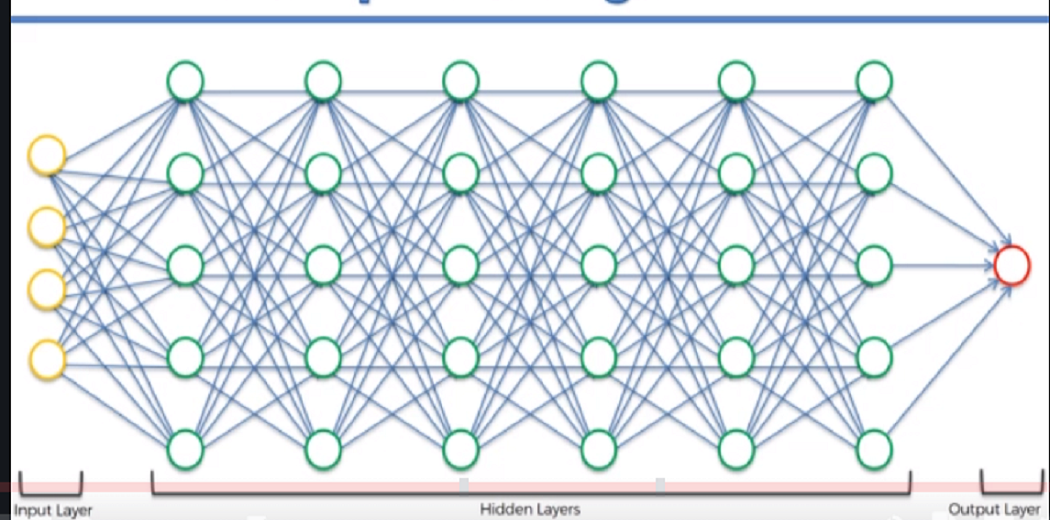
Deep neural networks
multiple layers of nodes
Seen on image and speech recognition, natural processing, recommendations
Based on pre-trained models
Finetuning for performance
| Name | Description |
|---|---|
| Decision Trees | Split the data into smaller subsets and recursively repeat the process, creating a tree of decisions |
| Random Forests | Combination of multiple decision trees |
| SVMs (Support Vector Machines) |
Classification task by separating data into different classes (finding hyperplanes) |
| Naive Bayes | Probabilistic algorithm for classification. Computes probability of data belonging to a given class |
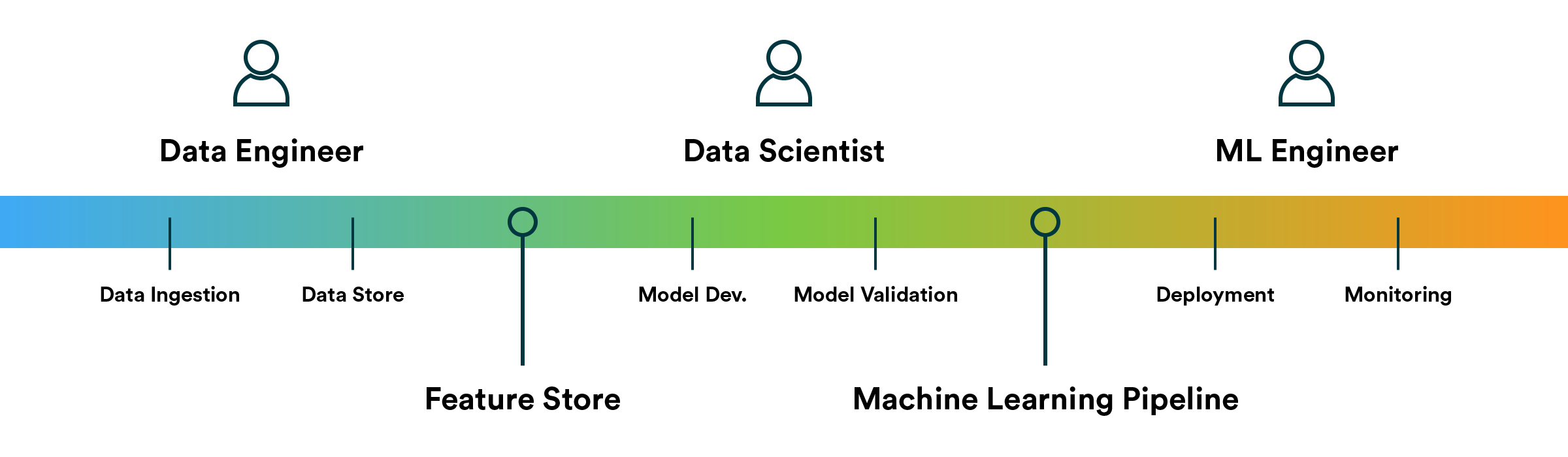
We need to understand what kind of learning will the model use and what kind of data.
We need to understand what kind of usage will this model have. Who is calling it and from where.
We need to understand where is this model running and with what supporting code.
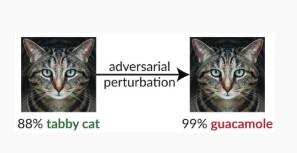
The attacker stealthily modifies the query to get a desired response. Breach of model input integrity, leads to fuzzing-style attacks that compromise the model’s classification performance
On Classification attacks an attacker attempts to deceive the model by manipulating the input data. The attacker aims to misclassify the input data in a way that benefits them.
We have multiple sub-types of this attack:
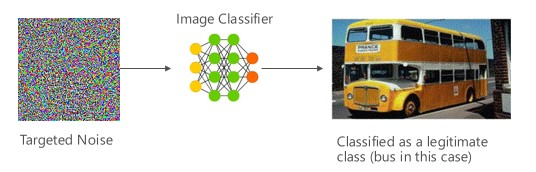
Generate a sample that is not the input class of the target classifier but gets classified as such by the model.
The sample can appear like a random noise to human eyes but attackers have some knowledge of the target machine learning system to generate a white nosie that is not random but is exploiting some specific aspects of the target model.
Causing a malicious image to bypass a content filter by injecting targeted noise
An attempt by an attacker to get a model to return their desired label for a given input.
This usually forces a model to return a false positive or false negative. The end result is a subtle takeover of the model’s classification accuracy, whereby an attacker can induce specific bypasses at will.
The attacker’s target classification can be anything other than the legitimate source classification
Causing a car to identify a stop sign as something else
(Same as Target Misclassification)
An attacker can craft inputs to reduce the confidence level of correct classification, especially in high-consequence scenarios.
This can also take the form of a large number of false positives meant to overwhelm administrators or monitoring systems with fraudulent alerts indistinguishable from legitimate alerts.
(Same as Target Misclassification)
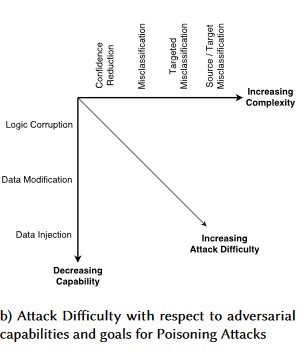
An attacker manipulates the training data used to train the model.
The goal of a poisoning attack is to introduce malicious data points into the training set that will cause the model to make incorrect predictions on new, unseen data
The goal of the attacker is to contaminate the machine model generated in the training phase, so that predictions on new data will be modified in the testing phase.
Submitting AV software as malware to force its misclassification as malicious and eliminate the use of targeted AV software on client systems
Goal is to ruin the quality/integrity of the data set being attacked.
Many datasets are public/untrusted/uncurated, so this creates additional concerns around the ability to spot such data integrity violations in the first place.
A company scrapes a well-known and trusted website for oil futures data to train their models. The data provider’s website is subsequently compromised via SQL Injection attack. The attacker can poison the dataset at will and the model being trained has no notion that the data is tainted.
Same as in Targeted Data Poisoning
The private features used in machine learning models can be recovered.
This includes reconstructing private training data that the attacker does not have access to. (Hill Climbing)
Recovering an image using only the person's name and access to the facial recognition system
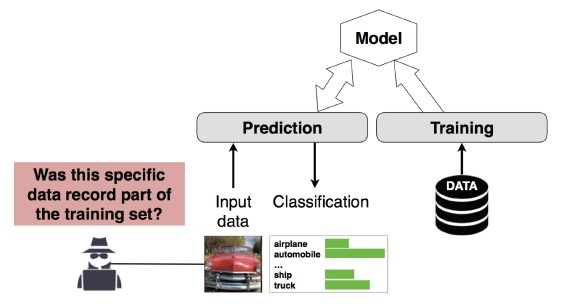
The attacker can determine whether a given data record was part of the model’s training dataset or not.
Predict a patient’s main procedure (e.g: Surgery the patient went through) based on their attributes (e.g: age, gender, hospital)
Differential privacy is a concept in data privacy that aims to provide strong privacy guarantees for individuals whose data is used in statistical analysis. The idea is to design algorithms that can answer queries about a dataset while protecting the privacy of individuals whose data is included in the dataset.
Model stacking, also known as stacked generalization, is a technique in machine learning where multiple predictive models are combined to improve the accuracy of predictions. In model stacking, the output of several individual models is used as input for a final model, which makes the final prediction.
The attackers recreate the underlying model by legitimately querying the model.
Call an API to get scores and based on some properties of a malware, craft evasions
By means of a specially crafted query from an adversary, Machine learning systems can be reprogrammed to a task that deviates from the creator’s original intent.
A sticker is added to an image to trigger a specific response from the network. The attacker trains a separate network to generate the patch, which can then be added to any image to fool the target network and make the car speed up instead of slowdown when detecting a crosswalk.
Owing to large resources (data + computation) required to train algorithms, the current practice is to reuse models trained by large corporations and modify them slightly for task at hand. These can be biased or trained with compromised data.
The training process is outsourced to a malicious 3rd party who tampers with training data and delivered a trojaned model which forces targeted mis-classifications, such as classifying a certain virus as non-malicious
By apl3b




