Browsers and DOM
What is a browser?
The main function of a browser is to present the web resource you choose, by requesting it from the server and displaying it in the browser window.
The resource is usually an HTML document, but may also be a PDF, image, or some other type of content.

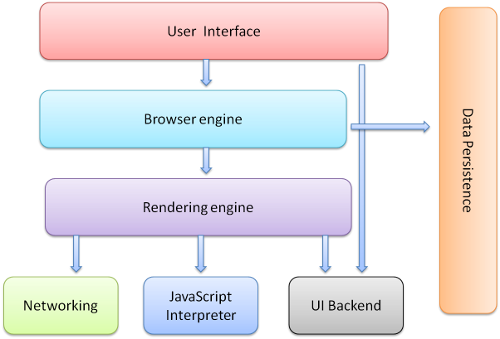
Browser's High Level Structure
- The user interface: this includes the address bar, back/forward button, bookmarking menu, etc. Every part of the browser display except the window where you see the requested page.
- The browser engine: marshals actions between the UI and the rendering engine.
- The rendering engine : responsible for displaying requested content. For example if the requested content is HTML, the rendering engine parses HTML and CSS, and displays the parsed content on the screen.
- Networking: for network calls such as HTTP requests, using different implementations for different platform behind a platform-independent interface.
- UI backend: used for drawing basic widgets like combo boxes and windows. This backend exposes a generic interface that is not platform specific. Underneath it uses operating system user interface methods.
- JavaScript interpreter. Used to parse and execute JavaScript code.
- Data storage. This is a persistence layer. The browser may need to save all sorts of data locally, such as cookies. Browsers also support storage mechanisms such as localStorage, IndexedDB, WebSQL and FileSystem.
Rendering Engine
- displays requested contents on the browser screen.
- By default the rendering engine can display HTML and XML documents and images.
- It can display other types of data via plug-ins or extension; for example, displaying PDF documents using a PDF viewer plug-in.
- Different browsers use different rendering engines
- Internet Explorer uses Trident
- Firefox uses Gecko
- Safari uses WebKit
- Chrome and Opera (from version 15) use Blink, a fork of WebKit.
- Edge uses EdgeHTML
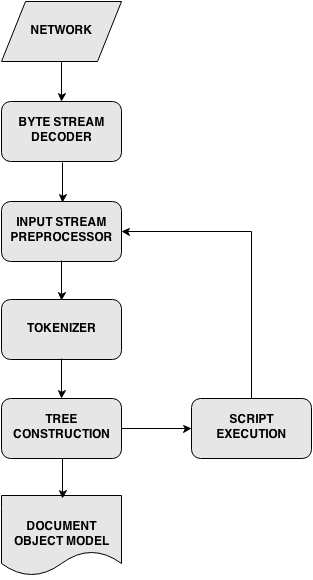
The Main Flow
The rendering engine will start getting the contents of the requested document from the networking layer.

- The rendering engine will start parsing the HTML document and convert elements to DOM nodes in a tree called the "content tree".
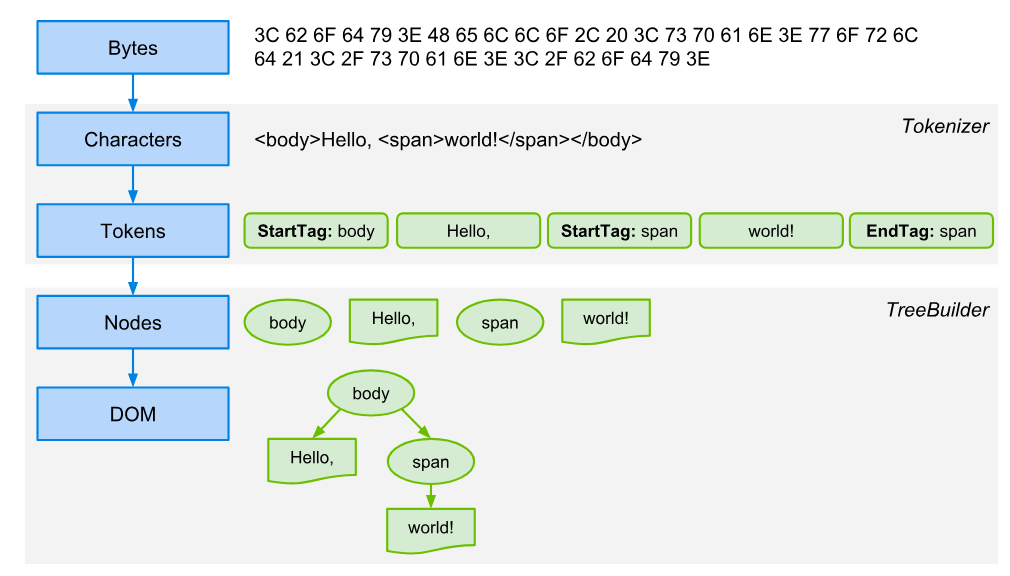
The Main Flow
The rendering engine will start getting the contents of the requested document from the networking layer.
- The rendering engine will start parsing the HTML document and convert elements to DOM nodes in a tree called the "content tree".
- The engine will parse the style data, both in external CSS files and in style elements.
- Styling information together with visual instructions in the HTML will be used to create another tree: the render tree.
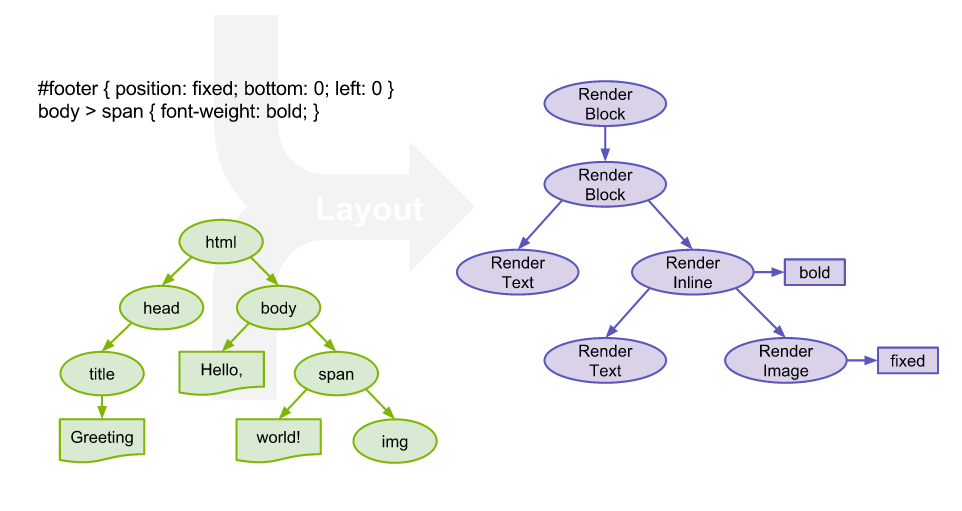
DOM + CSS => Render Tree
Only Visual Elements Are In The Render Tree
- Head
- Display:none
Not Part of Render Tree
switch (style.get().display()) {
case NONE:
style.dropRef();
return nullptr;
case INLINE:
return createRenderer<RenderInline>(element,
WTF::move(style));
...
}
- User Styles
- Inline Styles
- Browser Styles
RESOLVE STYLES - CSS SPECIFICITY
The render tree contains rectangles with visual attributes like color and dimensions. The rectangles are in the right order to be displayed on the screen.
- After the construction of the render tree it goes through a "layout" process.
- This means giving each node the exact coordinates where it should appear on the screen.
Calculate The Position - Size
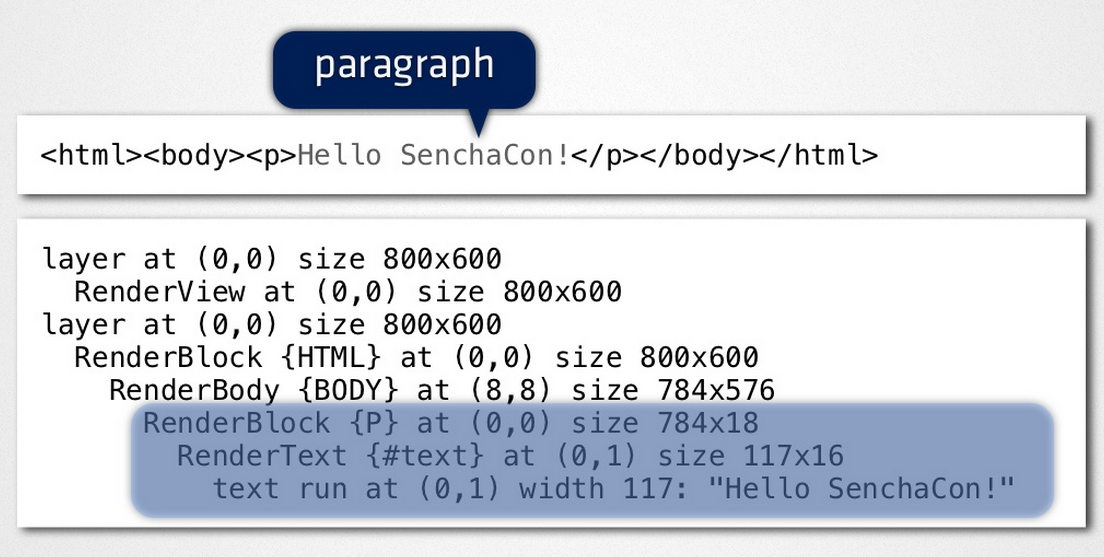
The render tree contains rectangles with visual attributes like color and dimensions. The rectangles are in the right order to be displayed on the screen.
- After the construction of the render tree it goes through a "layout" process.
- This means giving each node the exact coordinates where it should appear on the screen.
- The next stage is painting–the render tree will be traversed and each node will be painted using the UI backend layer.
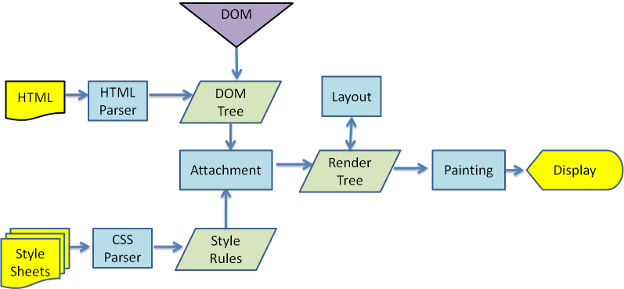
WebKit main flow
CSS Parsing
Unlike HTML, CSS is a context free grammar
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
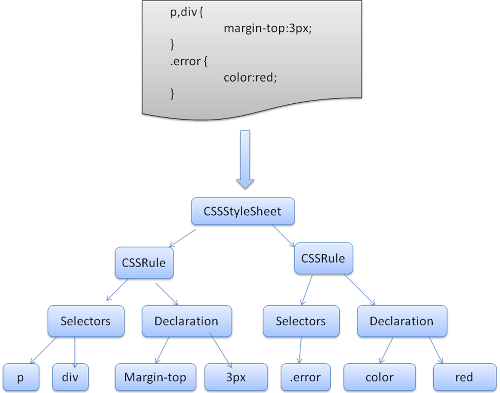
;- Webkit creates a bottom up shift-reduce parser. Firefox uses a top down parser written manually.
- In both cases each CSS file is parsed into a StyleSheet object. Each object contains CSS rules.
- The CSS rule objects contain selector and declaration objects and other objects corresponding to CSS grammar.
Browser Object Model
The Browser Object Model (BOM) is a browser-specific convention referring to all the objects exposed by the web browser.
Browser Object Model
Basically window javascript object in web browsers.
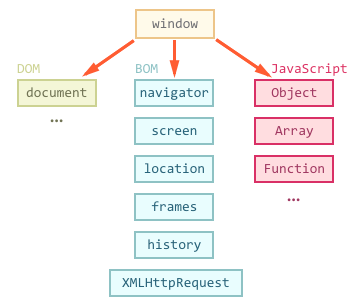
- The window object is the very root element, everything else is attached to it either directly or indirectly. Hence there’s no need to reference it explicitly.
- In tabbed browsers, each tab owns its own window object, i.e.: it is (generally) not shared between tabs in the same window.
- The window object provides certain properties and methods
Timers
- setTimeout
- setInterval
There are two methods for scheduling work after a certain time.
- clearTimeout
- clearInterval
The Location object
- location.hash
- location.host
- location.hostname
- location.href returns the full URL of the current page. We can also write to this property, causing a redirect to the new value.
- location.pathname returns whatever comes after the hostname.
- location.port returns the port number but only if it’s set on the URL.
- location.protocol returns the protocol used to access the page.

- location.search returns whatever comes after the ? in the URL.
- location.assign(url) navigates to the url passed in as a param.
- location.replace(url) is similar to assign, but the replaced site gets removed from the session history.
- location.reload() which has the same effect as clicking the reload button on our browser.
AJAX IS NOT...
- A Library
- A Framework
- A Technology
- Stands for Asynchronous JavaScript And XML
- The term was coined by Jesse James Garrett
AJAX
Ajax is a set of Web development techniques using many Web technologies on the client side to create asynchronous Web applications.
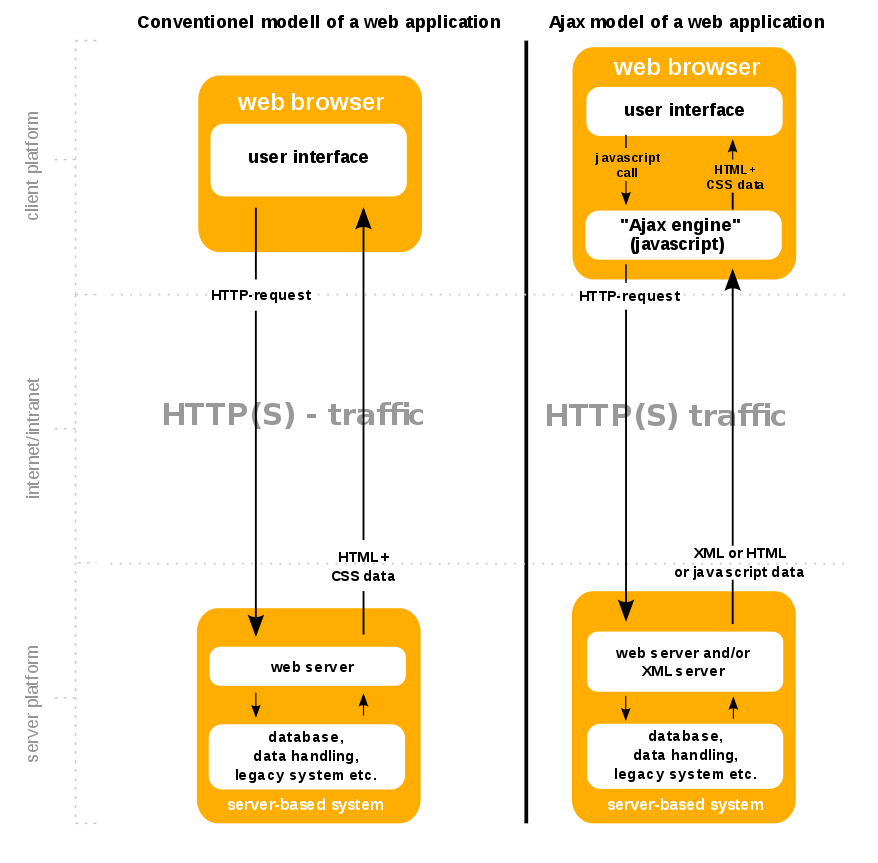
- The following technologies are incorporated:
- HTML (or XHTML) and CSS for presentation
- The Document Object Model (DOM) for dynamic display of and interaction with data
- JSON or XML for the interchange of data, and XSLT for its manipulation
- The XMLHttpRequest object for asynchronous communication
- JavaScript to bring these technologies together
Technologies
- XMLHTTP Request
- The Fetch API
- 3rd Party Libraries: jQuery, Axios, etc.
Making Requests with JavaScript
XMLHTTP Request
const XHR = new XMLHttpRequest();
XHR.onreadystatechange = function() {
if (XHR.readyState == 4 && XHR.status == 200) {
console.log(XHR.responseText);
}
};
XHR.open("GET", "https://api.github.com/zen");
XHR.send();The concept behind the XMLHttpRequest object was originally created by Microsoft.
fetch
fetch('/users.html')
.then(function(response) {
return response.text()
}).then(function(body) {
document.body.innerHTML = body
})The fetch() function is a Promise-based mechanism for programmatically making web requests in the browser.
fetch(url, {
method: 'POST',
body: JSON.stringify({
name: 'blue',
login: 'bluecat',
})
}).then(function (data) {
//do something
}).catch(function (error) {
//handle error
});Data Formats
API's don't respond with HTML. API's respond with pure data, not structure.
More efficient formats such as XML and JSON are used.
XML
<pin>
<title>Adorable Maine Coon</title>
<author>Cindy S</author>
<num-saves>1800</num-saves>
</pin>XML is syntacticly similar to HTML, but it does not describe presentation like HTML does
JSON
JavaScript Object Notation
'pin': {
'title': 'Adorable Maine Coon',
'author': 'Cindy S',
'num-saves': 1800
}
JSON looks (almost) exactly like JavaScript objects
JSON is a syntax for serializing objects, arrays, numbers, strings, booleans, and null.
JavaScript and JSON differences
- Objects and Arrays
- Property names must be double-quoted strings; trailing commas are forbidden.
- Numbers
- Leading zeros are prohibited (in JSON.stringify zeros will be ignored, but in JSON.parse it will throw SyntaxError); a decimal point must be followed by at least one digit.
- Strings
- Only a limited set of characters may be escaped; the Unicode line separator (U+2028) and paragraph separator (U+2029) characters are permitted; strings must be double-quoted.
Browsers Internals
By Arfat Salman



