De Lenguaje Natural a Queries
Cómo hacer Business Intelligence sin saber SQL
#DataDayMx
Adolfo Martínez
Motivación
- Herramientas especializadas
- Tableau, PowerBI, Sisense, SAP BI, etc.
- Equipos especializados en una u otra herramienta
- Costos de licencias
- Fragmentación
- Skills no transferibles
- Ralentización de la toma de decisiones
¿Cómo se hace BI?
¿Qué pasaría si el tomador de decisiones pudiera preguntar directamente lo que quiere saber?
El Problema
¿Cuál es el promedio de ventas diarias para las sucursales de la región "A" durante 2018?
A partir de:
Llegar a:
SELECT
AVERAGE(total)
FROM
daily_sales
WHERE
region = "A" AND year = 2018
Algunos detalles y supuestos
- Formulación arbitraria de la pregunta
- Palabras clave pueden cambiar o no aparecer
- Los valores a buscar se incluyen en la pregunta*
- Sabemos a qué datos se refiere la pregunta*
- Los datos pertinentes están en una sola tabla*
*: Estos son supuestos, en el problema general pueden no cumplirse
Approach: Semantic Parsing
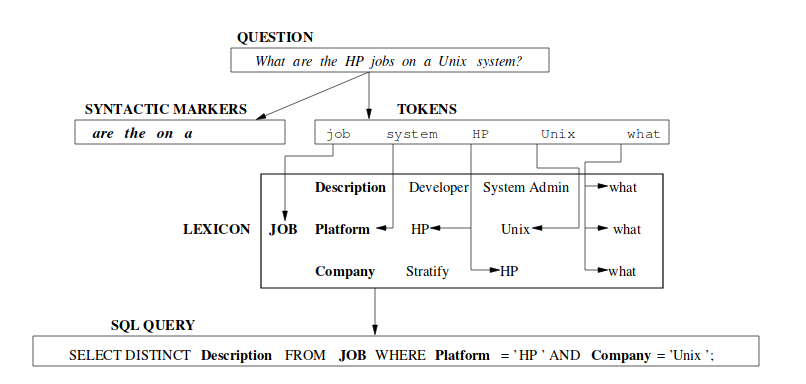
- Gran cantidad de reglas sintácticas
- Lexicones especializados
- Gran variación entre lenguajes
Problema de Machine Learning
Dado un dataset de pares de pregunta/query, construir un modelo de aprendizaje supervisado para encontrar la query apropiada dada una pregunta.
- ¿Qué datos existen?
- ¿Qué clase de modelo necesitamos?
- ¿Qué precisión podemos lograr?
Datos: WikiSQL
Dataset crowd-sourced de 80,564 preguntas anotadas a mano, con el query correspondiente, basadas en tablas de Wikipedia
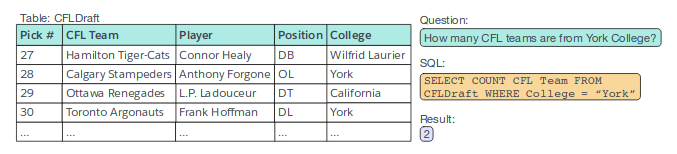
Publicado junto con un script para evaluar soluciones al problema, muchos de los papers en el campo basan sus resultados en WikiSQL
Datos: WikiSQL
- Sólo una columna en SELECT
- Una (o ninguna) agregación de un catálogo
- Uno o varios filtros, unidos con AND
- Sin agrupaciones
- Sin subqueries
- Sin cláusulas JOIN
Solución: Preliminares
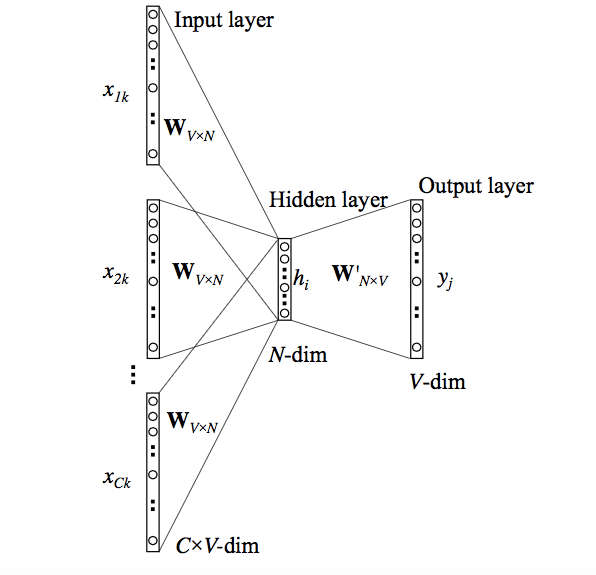
Word Embeddings
Un embedding de una palabra es una representación vectorial de la misma. Una manera de obtenerlos es a través de una red neuronal que prediga una palabra dado su contexto (Word2Vec).
Embeddings similares corresponden a palabras semánticamente similares, (utilizadas en contextos similares).
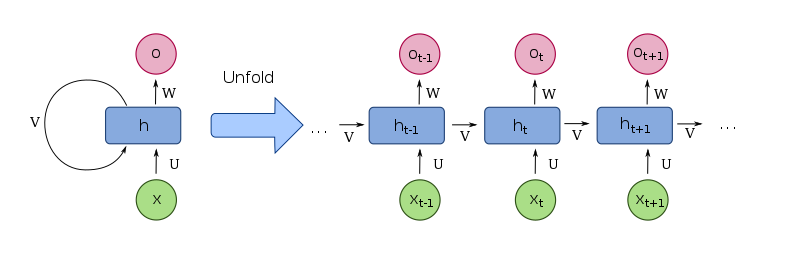
Recurrent Neural Networks
Las redes neuronales recurrentes (RNNs) son una arquitectura de red neuronal diseñada para procesar datos secuenciales.
El output (estado oculto) de una capa recurrente para el elemento t de una secuencia, es input de la misma capa para el elemento t+1. Esto les permite "recordar" valores anteriores
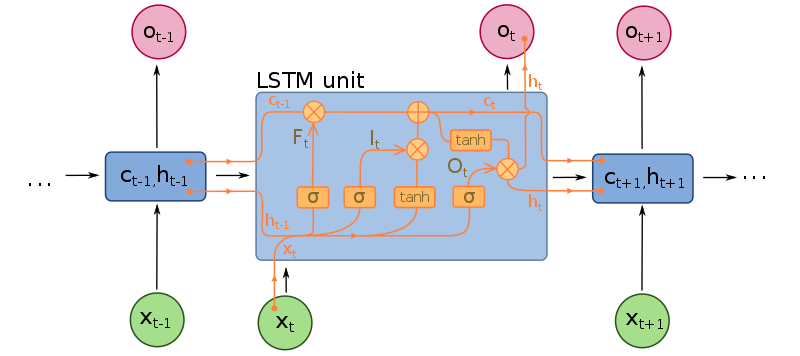
Long Short-Term Memory Cells
Una celda o unidad LSTM es una extensión de una capa recurrente. Estas unidades incluyen "compuertas" que permiten a la capa "olvidar" o "recordar" información a través de un estado, que se produce junto con el estado oculto de la capa.
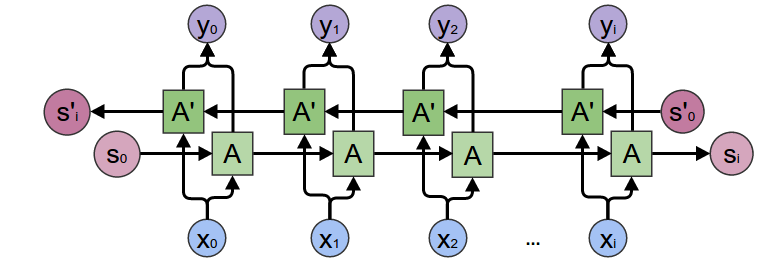
RNNs Bidireccionales (BRNNs)
Otra extensión de una capa RNN, se agrega una capa que recorre la secuencia en el sentido opuesto. Esto le permite a la siguiente capa obtener información no sólo de elementos pasados, sino también futuros.
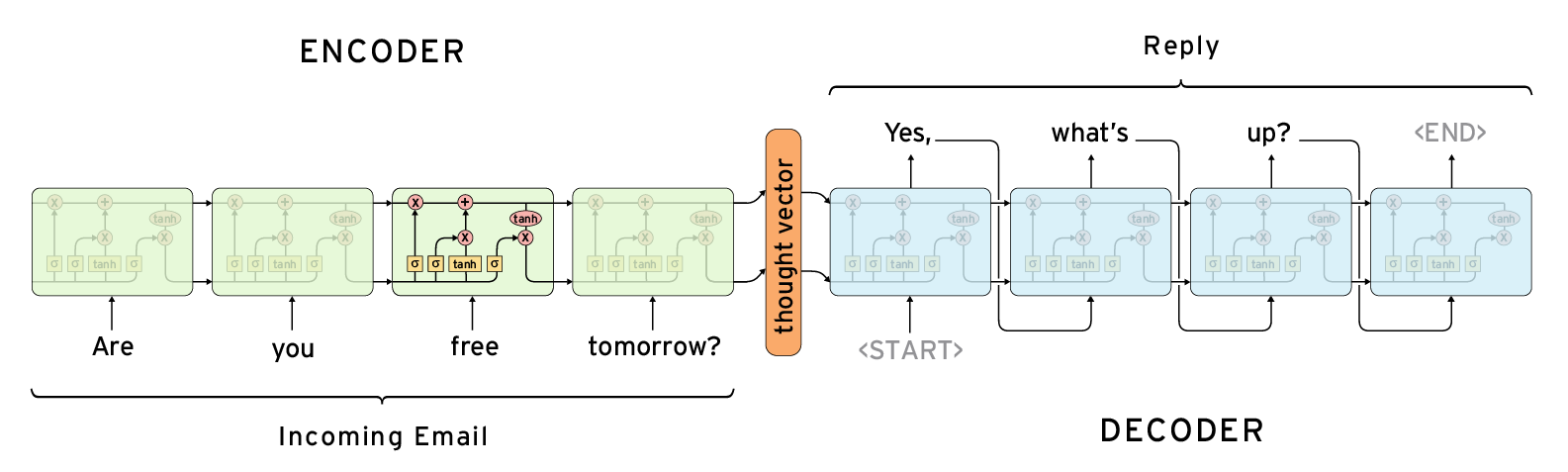
Encoder-Decoder Architecture
Una arquitectura para generar secuencias a partir de secuencias dadas. Una o varias capas recurrentes producen un estado oculto a partir de la secuencia de entrada, que se alimenta a otra serie de capas recurrentes para producir la secuencia de salida
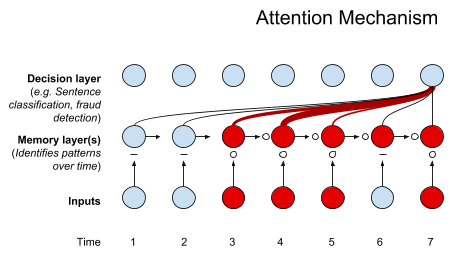
Mecanismo de atención
En RNNs, el mecanismo de atención le permite a capas posteriores a una capa recurrente tener acceso a la información en estados ocultos distintos del estado final a través de pesos. Esto le permite a esta capa "poner atención" en partes específicas de la secuencia.
Solución: Baseline
Características
- Una arquitectura encoder-decoder con BRNNs
- La secuencia de entrada es la pregunta en NL
- La secuencia de salida es el query de SQL
- Accuracy: 35.9%

Solución: Seq2SQL
Características
- Aprovecha la estructura de los queries de SQL
- Una BRNN para clasificar la agregación a usar
- Una BRNN para clasificar la columna a seleccionar
- Una BRNN encoder-decoder con una pérdida de RL
- Accuracy: 59.4%
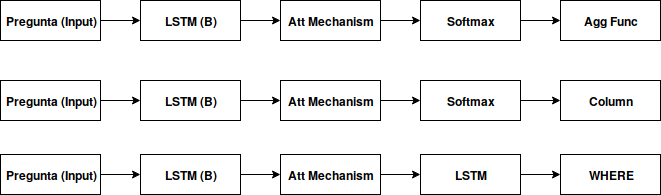
Cláusula WHERE
- Encoder-decoder para generar la cláusula
- No basta comparar la cláusula generada con la real
- El orden no importa!
- Se ejecuta el query para obtener la pérdida

- El "gradiente" se obtiene como un policy gradient
Solución: SQLNet
Características
- Se basa en un "sketch" de la query de SQL
- No usa una pérdida basada en ejecutar el query
- Se genera un conjunto de filtros, no una secuencia
- Esto permite usar una pérdida fácil de evaluar

- Una red para $AGG
- Una red para $COLUMN en la cláusula SELECT
- Accuracy: 68%
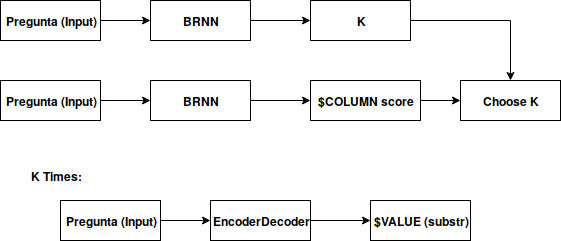
Cláusula WHERE
- Una RNN para predecir el número de filtros K
- Dado K, una RNN decide que columnas se incluyen
- Una RNN para llenar el valor de $OP (3 posibles)
- Encoder-decoder para llenar $VALUE
Más soluciones!
- TypeSQL agrega información de tipos (Acc: 73.5%)
- Coarse2Fine llena el sketch en dos fases (Acc: 78.5%)
- Inc2SQL llena el sketch iterativamente (Acc: 83.7%)
- SQLova utiliza una nueva representación de palabras (Acc: 86.2%)
- ...etc!
- Leaderboard: https://github.com/salesforce/wikisql
Trabajando en...
- Extender el dataset para incluir cláusulas GROUP BY
- Extender la arquitectura para cubrir este caso
- Más de una posible tabla fuente de datos
- ¿Cómo extraer y visualizar información relevante al query?
- ¿Cómo combinar información con varias tablas?
- ¿Cómo lidiar con agrupaciones multinivel?
- Un lenguaje distinto a SQL
¿Te interesa? adolfo@datank.ai
¡Gracias!
NL2Q
By Arinarmo

