Optimización de un sistema de transporte con aprendizaje por refuerzo
@pythondaymx

"I Know Kung Fu"
@pythondaymx
"I Know Kung Fu"
Optimización de un sistema de transporte con aprendizaje por refuerzo
@pythondaymx
Contexto
Sistema de Movilidad 1
- Red de autobuses de la "periferia"
- Diario: ~400 mil usuarios, ~110 mil km recorridos
- 94 rutas, ~650 autobuses

Balderas - Santa Fe
- Recorrido redondo: ~37 km, 76 paradas, ~2 hrs
- Balderas: Centro de la ciudad. Nodo importante de la red
- Santa Fe: Centro de actividad económica y comercial. Mordor Godínez

Planteando el problema
¿Cómo "optimizar" esta ruta?
- Dos (o más) filas
- Usuarios que buscan comodidad vs. usuarios que buscan rapidez
- El tiempo de espera regula este espectro
¿Cómo reducir el tiempo de espera?
- Tráfico: Imposible de controlar, se puede anticipar en cierta medida
- Ruta: Definida de antemano, cambia sólo excepcionalmente
- Horarios fijos por parada: Difícil (casi imposible) adopción en el corto plazo
- Estrategia de salidas: Controlable, actualmente se sigue una muy sencilla
¿Cómo afecta la estrategia de salidas el tiempo de espera de los usuarios?
estrategias de salida y tiempos de espera
¿Qué se hace actualmente?
- Estrategia sencilla basada en frecuencia
- Controladores humanos que siguen y adaptan dicha estrategia
- Mucha variabilidad en el "desempeño" de los controladores
¿Cómo mejorar esta situación?
Reinforcement Learning
- Paradigma de Machine Learning: Ni supervisado ni no-supervisado
- Problema: Determinar cómo tiene que actuar un agente en un ambiente para maximizar alguna recompensa en el largo plazo. Encontrar la estrategia óptima para el agente a partir del estado del ambiente
- Requisitos: Acciones periódicas, bien definidas y con resultados sensables, recompensa sensable eventualmente, ambiente sensable. Historia de acciones y recompensas y/o capacidad de aprendizaje online
- Ejemplos: Control de inventario, jugar Go, control de un robot
Problema de RL: Jugar Go
- Agente: Jugador de Go autónomo
- Ambiente: Juego de Go, reglas y dinámica
- Estado: El tablero en cada turno
- Acciones: Cada turno, colocar una piedra en un lugar válido
- Recompensa: Ganar (perder, o empatar) el juego
Problema de RL: Controlar salidas
- Agente: Controlador autónomo
- Ambiente: Ruta de autobús, dinámica de la misma
- Estado: Posición y velocidad de cada autobús
- Acciones: Cada cierto tiempo, elegir si sale o no un autobús
- Recompensa: Tiempo promedio de espera (recompensa negativa)
¿Tenemos datos para entrenar este agente?
Solucionando el problema
Datos disponibles
- Mediciones GPS de cada autobús, cada 30 segundos
- Número de usuarios diarios en toda la ruta
¡No podemos calcular los tiempos de espera!
Tres opciones
- Medir tiempos de espera
- Estimar tiempos de espera
- Utilizar proxy
Distribución de camiones vs tiempos de espera
Problema de RL: Controlar salidas
- Agente: Controlador autónomo
- Ambiente: Ruta de autobús, dinámica de la misma
- Estado: Posición y velocidad de cada autobús
- Acciones: Cada cierto tiempo, elegir si sale o no un autobús
-
Recompensa:
Tiempo promedio de esperaDistancia máxima entre autobuses
¿Cómo entrenar al agente?
- Existe historia, pero no nos permite explorar estrategias nuevas
- Es problemático implementar aprendizaje online
- Sin embargo, podemos simular la ruta a partir de la historia
Simulación de ruta
- Simular la velocidad de cada camión
- A partir de su velocidad, actualizar posición cada cierto tiempo
- La variabilidad nos da una gran cantidad de escenarios para entrenar
Preprocesamiento
Puntos GPS
Balderas - Santa Fe
Santa Fe - Balderas



Preprocesamiento

Posiciones de un viaje

Tiempo vs posición
Preprocesamiento
Tiempo vs posición

Interpolación
Preprocesamiento
Interpolación
Velocidad del viaje

Preprocesamiento
Velocidad del viaje

Datos de velocidad
Selección de variables


Modelo de velocidad de autobús
v_{t+1} \sim Gamma(\mu_{t+1}, \sigma)
\mu_{t+1} = \beta_0 v_t + \beta_1 \bar v_p
\beta_0, \beta_1 \sim HalfCauchy(2.5)
\sigma \sim HalfCauchy(2.5)
distribución posterior y ajuste visual


simulación de ruta
estrategia base (actual)


Q Learning
- Técnica popularizada gracias a DL
- Estimar el valor (recompensa acumulada) de una acción en un estado
- Idea básica: iterar la ecuación de Bellman
Q(s, a) = r(s, a) + \gamma \max_{a{'} \in A} \displaystyle \sum_{s{'} \in S} p(s{'} | s, a)Q(s{'}, a{'})
- Una red neuronal es capaz de aprender la función Q
- La estrategia óptima consiste en elegir la acción con el mejor valor Q en cada estado
- Implementamos una red siguiendo dos papers de DeepMind
Diseño de estado
- Cantidad de autobuses en ruta
- Cantidad de autobuses en terminal
- Velocidad promedio de autobuses
- Agregados de distancia: promedio, mínimo y máximo
- Autobús más cercano y más lejano: posición y velocidad
- Hora y minuto
aprendizaje de agente RL: primeros pasos
aprendizaje de agente RL: resultado final
desempeño de agente rl vs estrategia base


¿qué paquetes se usaron?
Cómputo matricial y numérico
Manejo de datos (Data Frames)
Graficación y visualización
Cómputo científico y estadístico
Programación probabilística (modelos Bayesianos)
Redes neuronales y cómputo con tensores
modelos jerárquicos bayesianos con pymc3
v_{t+1} \sim Gamma(\mu_{t+1}, \sigma)
\mu_{t+1} = \beta_0 v_t + \beta_1 \bar v_p
\beta_0, \beta_1 \sim HalfCauchy(2.5)
\sigma^{-1} \sim HalfCauchy(2.5)
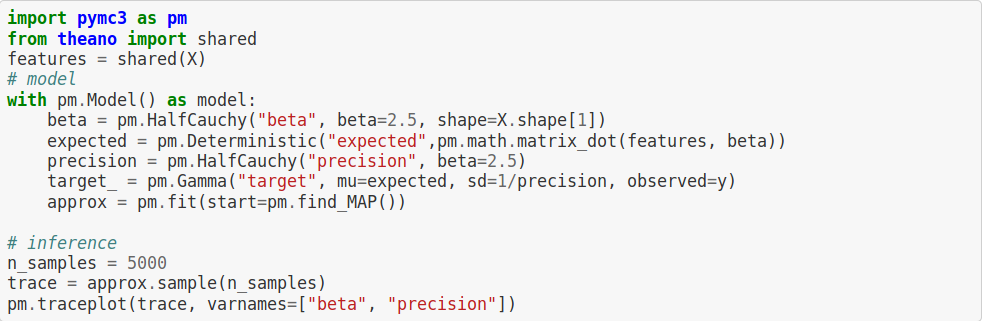
De esto:
A esto:
redes neuronales con tensorflow
De esto:
A esto:


en conclusión
- RL es una herramienta poderosa para resolver problemas de control
- Combinado con modelos generativos, podemos entrenar agentes sin afectar la realidad
- Esta solución fue probada durante unas semanas (link) con resultados positivos
- ...¿Y el kung-fu?
en conclusión
- RL es una herramienta poderosa para resolver problemas de control
- Combinado con modelos generativos, podemos entrenar agentes sin afectar la realidad
- Esta solución fue probada durante unas semanas (link) con resultados positivos
- ...¿Y el kung-fu?

¡gracias!
Mi twitter: @arinarmo
Estos slides: https://slides.com/arinarmo/kung-fu-1

"I know kung-fu" pyday
By Arinarmo

