GAN Tutorial
Arvin Liu @ 新竹AIA
Here is
slides.com/arvlinliu/gan
Codes:
goo.gl/yRvUk1
This slide is suitable for:
1. Have some experience in Deep Learning
2. Having basic GAN concept.
3. Thinking?
GAN Review
Generative
Adversarial
Network
GOAL
Generate a new data
Generative Adversarial Network
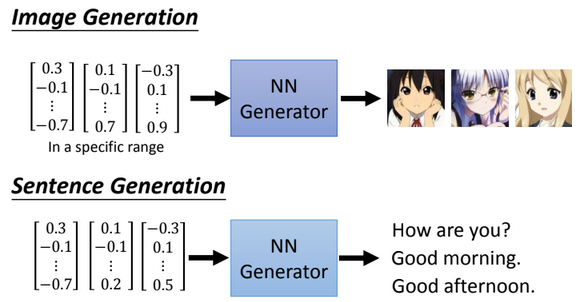
image resource: 李宏毅老師的投影片
Given skill points to generate something.
Skill points
Generative Adversarial Network
image resource: 李宏毅老師的投影片
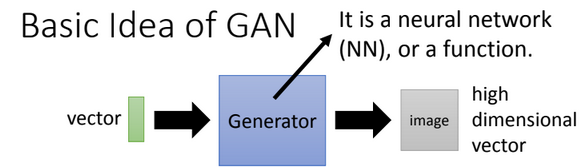
能力值 -G-> 角色
image resource: 李宏毅老師的投影片, anime image powered by http://mattya.github.io/chainer-DCGAN/
Low dim to high dim?
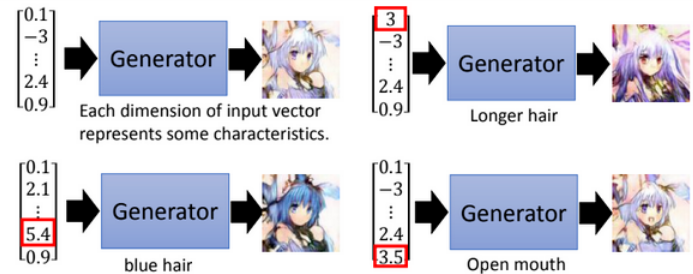
Generative Adversarial Network
image resource: 李宏毅老師的投影片
Generative Adversarial Network
image resource: 李宏毅老師的投影片
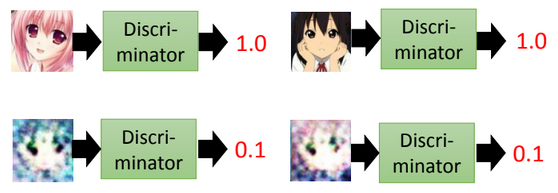
Generally...
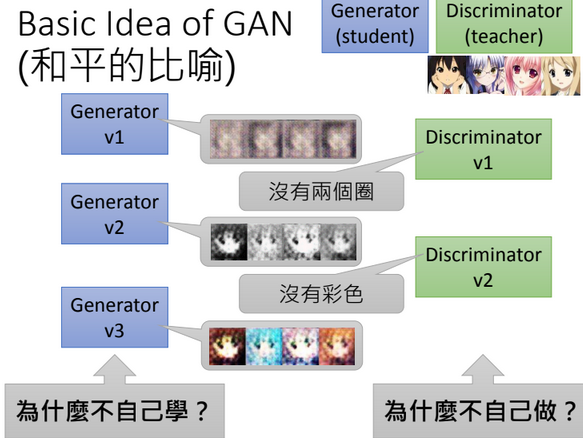
Generator
被囚禁在孤島的畫家
Discriminator
常常來探望並評論的藝術家
Generator
- 可以想像成一位智商堪憂的學生,慢慢學習。
- 為了獎勵 (minimize G_loss),你會想要好好討好老師。
- 智商低落,自己來學可能無法好好歸納特徵。
Discriminator
- 可以想像成一位"見過很多世面的老師",而且它很討厭學生。
- "見過世面",就是他看過 real data。
- "討厭學生",因為不這樣他沒錢拿 (minimize D_loss)。
- 就是嘴砲。
- 這麼會你來啊?為什麼不自己來?
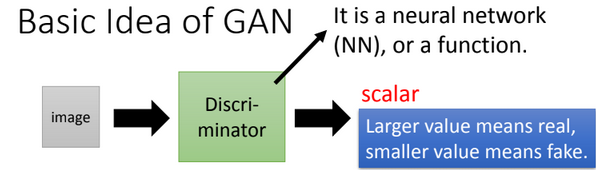
Generative Adversarial Network
image resource: 李宏毅老師的投影片
Only Generator
Like VAE, but blur due to loss function
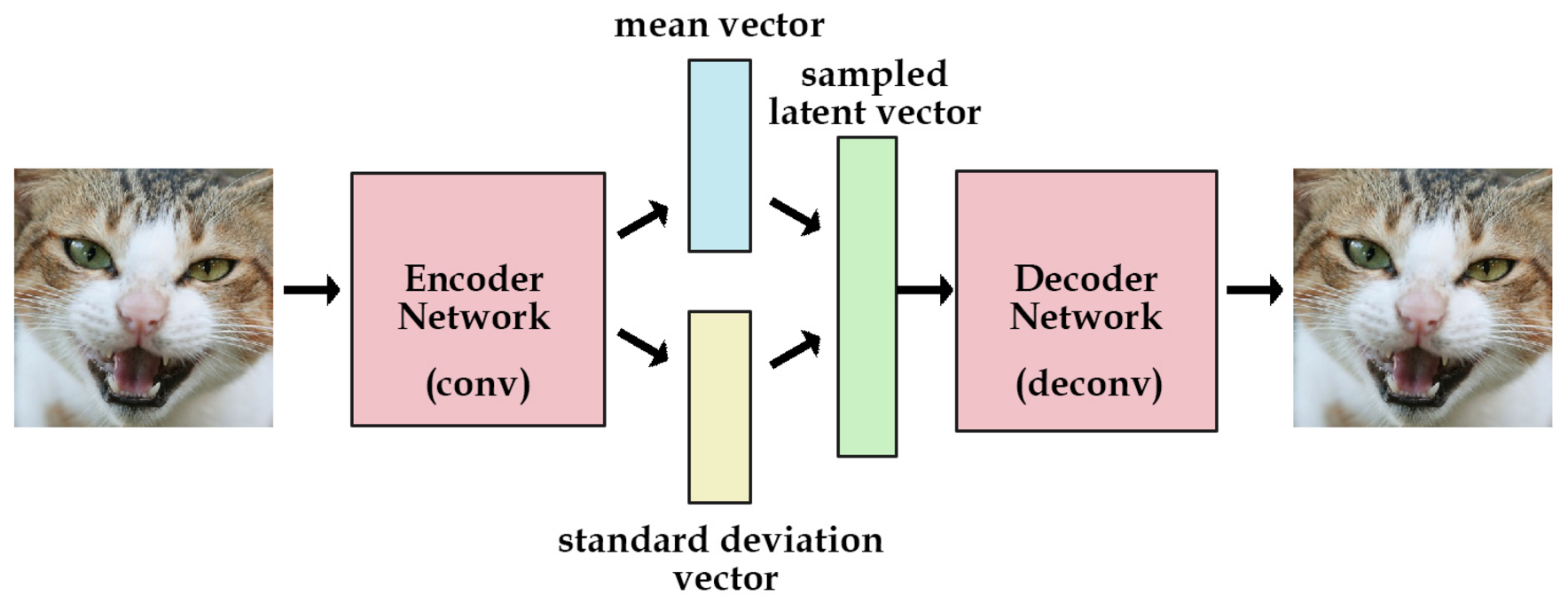
(Recall) What is
Variational AutoEnconder (VAE)?
用AE,中間latent增加隨機,
並希望latent可以~N(0,1)
image resource: https://www.cnblogs.com/huangshiyu13/p/6209016.html
image resource: 李宏毅老師的投影片

Due to superficial loss, we miss somthing.
Loss = NN?
You get the point!
Only Discriminator
Where is GOOD negative
(D(x)=0) sample?
Basically, it's a binary (predict 0,1) problem.
Little comment
(It is said that...)
seq2seq (like VAE) > GAN
in music generation nowadays.
Comment by 凱哥
Intro popular GAN ->
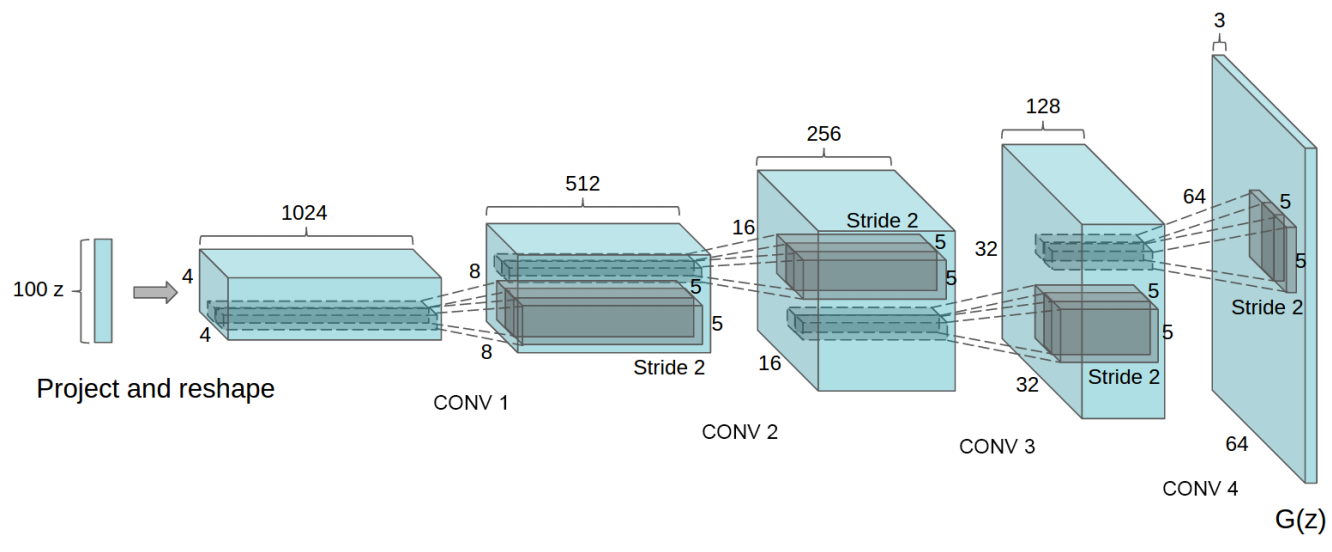
DCGAN Structure
DCGAN(ICLR'16) : https://arxiv.org/abs/1511.06434
Deep Convolutional GAN
Generator Structure
BN-> ReLU
tanh
DCGAN deconv: kernel size (5,5) , stride (2,2)
Discriminator Structure
BN + lReLU
lReLU
score
Before Viewing Code...

* resolution is not high due to image size(64x64).
DCGAN WITHOUT ANY TIPS
After Tips & High Resolution
* resolution = 128x128.

After Tips & High Resolution

Implement by code ->
GAN Code Definition
Sorry... but

I use tensorflow to train my GAN.
picture resource: https://www.tensorflow.org/
Utils
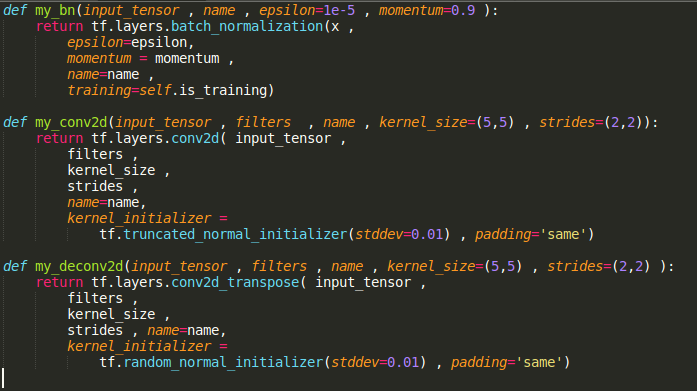
picture resource: my code displayed on sublime text3
Discriminator
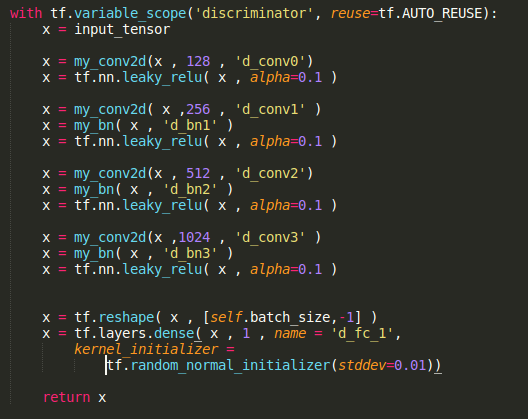
Convolution 128
f : (5,5) , s : (2,2)
Convolution 256
f : (5,5) , s : (2,2)
Convolution 512
f : (5,5) , s : (2,2)
Convolution 1024
f : (5,5) , s : (2,2)
Dense 1
Score

64x64x3 image
picture resource: my code displayed on sublime text3
Generator
Conv^T 512
f : (5,5) , s : (2,2)
Conv^T 256
f : (5,5) , s : (2,2)
Conv^T 128
f : (5,5) , s : (2,2)
Conv^T 3
f : (5,5) , s : (2,2)

Dense 2^14
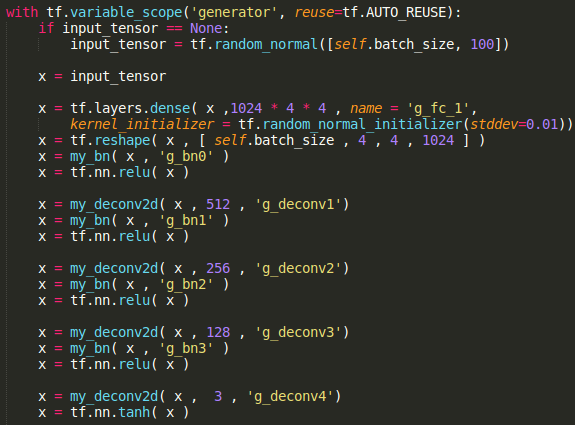
64x64x3 image
latent 100~N(0,1)
picture resource: my code displayed on sublime text3,
note that the latent in original paper is sampled from uniform distribution.
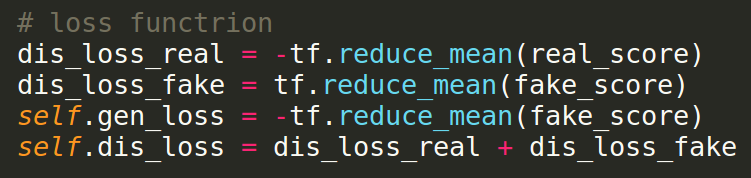
Loss definition
picture resource: my code displayed on sublime text3
Loss = \\\\
labels \times -\log( \sigma(logits) ) + \\
(1 - labels) \times -\log(1 - \sigma( logits))
binary cross entropy
tf.nn.sigmoid_cross_entropy_with_logits
Loss definition
picture resource: my code displayed on sublime text3
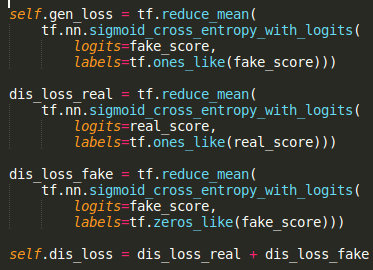
fake_score = discriminator(fake_data)
real_score = discriminator(real_data)
Be careful...
-
Read loss function carefully...
- You may put sigmoid twice.
- Give all the parametric layer a name.
- To reuse it.
Like... sigmoid_cross_entropy_with_logits

https://www.tensorflow.org/api_docs/python/tf/nn/sigmoid_cross_entropy_with_logits
GAN Code Details
GAN in short terms...


picture resource: 宏毅老師投影片
Why "Fix" parameters?
picture resource: 宏毅老師投影片
Why "Fix" parameters?
picture resource: 宏毅老師投影片
step1 : NOT fix G, train D
step2 : NOT fix D, train G
學生被洗腦,老師痛罵學生。
老師被洗腦,學生騙過老師。
How "Fix" parameters?
picture resource: 宏毅老師投影片
Train on specific variables
- Define Scope : tf.variable_scope(name)
- Get Variables : tf.trainable_variables(name)
- Optimize it : optimizer.minimize(loss,var_list=vars)
Reminder:
variable_scope(reuse = tf.AUTO_REUSE)
Fix specific variables
Graph
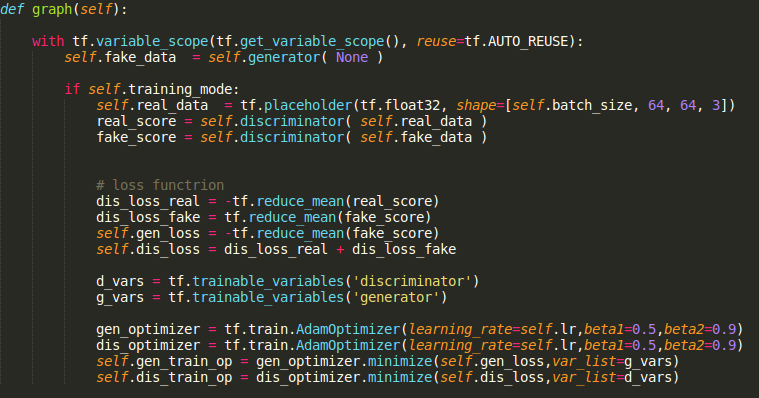
Training
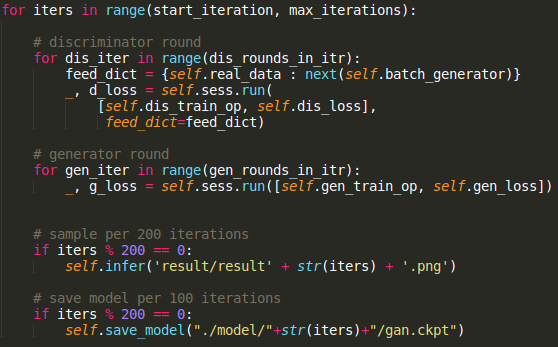
picture resource: my code displayed on sublime text3
Unlike PyTorch,
Tensorflow uses static computational graphs
That is, before training, define the computational graphs.
GAN in tasks
1step = 5 Discriminator iters + 1 Generator iter.
Step 0

picture resource: GAN result from Arvin Liu (myself).
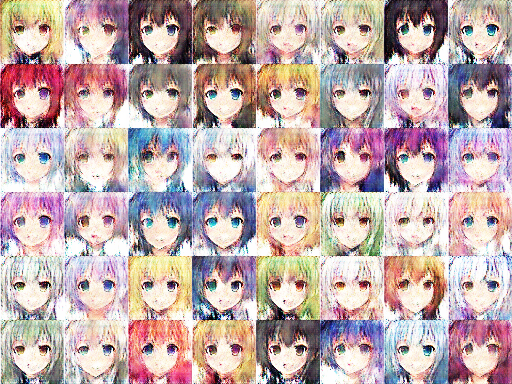
Step 800
picture resource: GAN result by Arvin Liu (myself).
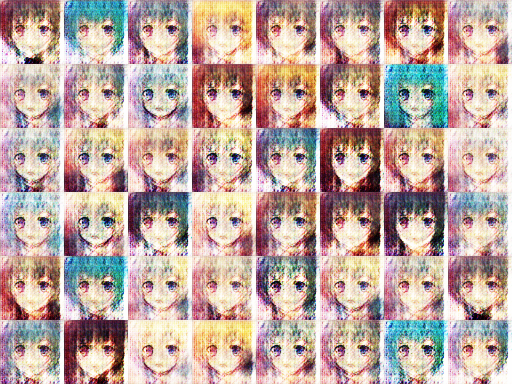
Step 2400
picture resource: GAN result by Arvin Liu (myself).
Step 6200
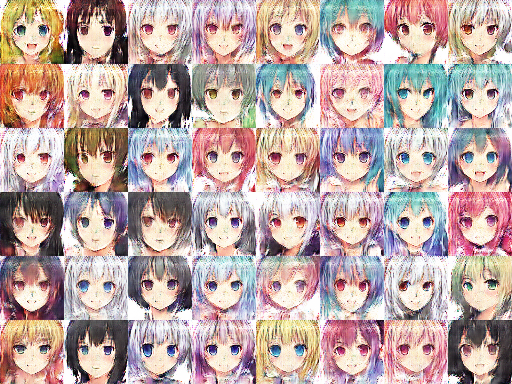
picture resource: GAN result by Arvin Liu (myself).
Step 21800
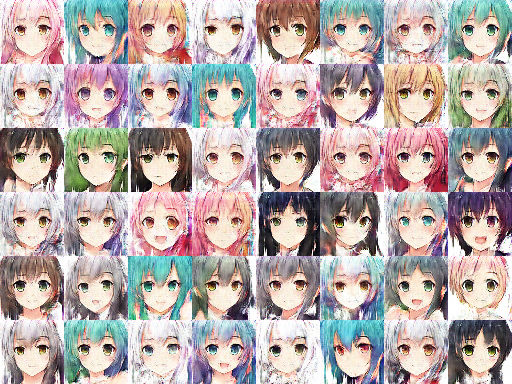
picture resource: GAN result by Arvin Liu (myself).
However... mode collapse
step 31600

However... mode collapse
step 31600
Wait... what is mode collapse?
GAN Problems
GAN Problems
- Mode Collapse
- Diminished Gradient
- Non-Convergence
What is Mode Collapse?


種類 - 崩潰/塌陷。
Why Mode Collapse?
Student
Teacher




What is Mode Collapse?
( latent : random normal distribution)

img created
by myself.
What is Mode Collapse?
( latent : random normal distribution)
img created
by myself.
image resource: 李宏毅老師的投影片
Why called Mode Collapse?
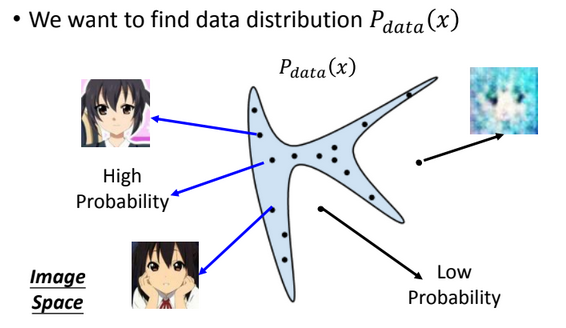
P_g(x)
Distribution(Mode) Collapse!
What is Diminished Grad?
Student
Teacher
Question : Generate a code for sorting




到底是誰的錯?



What is Diminished Grad?

Discriminator too strict!
image resource: 李宏毅老師的投影片
Discri-
minator
score
All possible data
What is Non-convergence?
When to stop
your training?
What is Non-convergence?
Before that,
thinking about GAN's target.
\text{let }V = E_{x \sim P_{data}}[\log D(x)] + E_{x \sim P_{G}}[\log (1-D(x))] \\
G^* = arg\,\,min_G\,(\,max_D\,(\,V(D,G)))
What is Non-convergence?
General Goal
GAN's Goal
image resource https://www.offconvex.org/2016/03/22/saddlepoints/
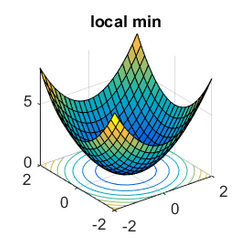
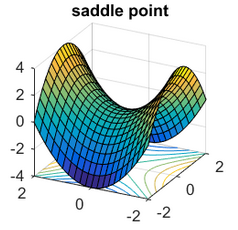
Early stopping +
validation

HUMAN!
Solve Non-convergence
Human monitoring
Save your model everytime,
save your whole life time.
Problem Timeline - Review
Diminished Gradient
Mode Collapse or
Gradient Explode
Non-convergence
Least Square GAN
Solve Diminished Gradient
https://arxiv.org/abs/1611.04076
Least Square GAN
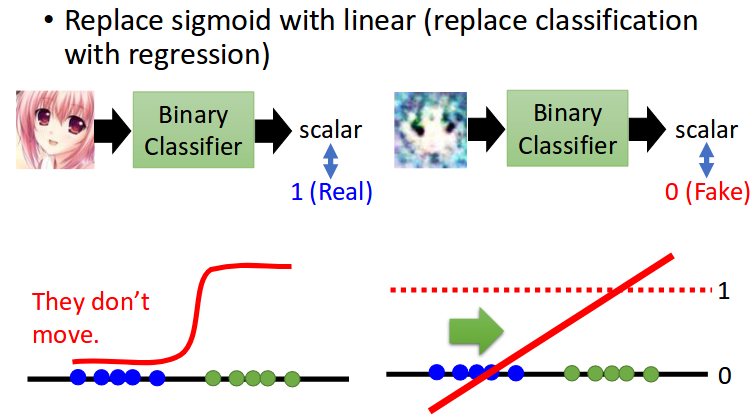
image resource: 李宏毅老師的投影片
(with sigmoid)
(without sigmoid)
Discriminator score
Least Square GAN
image resource: 李宏毅老師的投影片
Discriminator score
Sigmoid -> Linear , D_loss= D(fake)-D(Real)
D(fake) -> -∞ , D(real) -> ∞ ?
if D_0, D(fake)=-1 , D(real)=1 , Loss= -2
D_1, D(fake)=-2 , D(real)= 2 , Loss = -4, but?
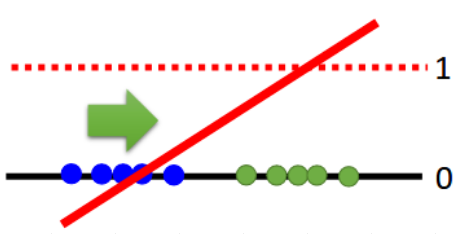
Least Square GAN
image resource: 李宏毅老師的投影片
Discriminator score
Sigmoid -> Linear
D(G) -> -∞ , D(real) -> ∞ ?
壓制在0~1:
D_Loss = (D(G) - 0)^2 + (D(real) - 1)^2
Loss Definition

picture resource: my code displayed on sublime text3
* both real_score & fake_score are NOT
pass through sigmoid function.
Early-Stopping
Solve Mode Collapse
How to Prevent Mode Collapse?
Stop training when it happens if you can. :)
Early Stopping
你潮棒der。
Mode Collapse
Mode Collapse
你潮棒der。
Case1:
Case2:
Nice Choice!


img resource:https://9gag.com/gag/aeexzeO/drake-meme
??????
沒人在天天過年的啦!
Early Stopping
WGAN-GP
Solve Diminished Gradient & Mode Collapse
Improved WGAN(NIPS '17): https://arxiv.org/abs/1704.00028
What is WGAN-GP?
WGAN - Gradient Penalty
What is WGAN?
Fast Review of WGAN
WGAN objective funciton:
V(P_{data} , P_{G}) = Wasserstein\,dis(P_{data} , P_{G})
How to measure?
V(P_{data} , P_{G}) = \max \{ D(real) - D(G) \}
if D is 1-lipschitz -> must be smooth
How to constrain D?
Weight Clipping once parameter update
Too complicated
Fast Review of WGAN
D_{loss} = D(fake) - D(real)
在D是 1-lipschitz function的條件下,(D 不過simgoid)
會不會這種情況?
D(fake) -> -∞ , D(real) -> ∞
Maybe! 但因為1-lip, 會很緩慢。
1-lipschitz : |f(x)-f(y)| <= |x-y|
Make it Smooth!!!
image resource: 李宏毅老師的投影片
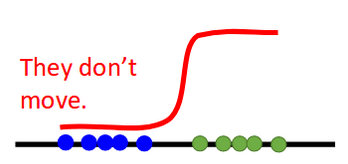
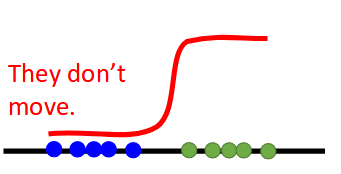
They don't move.
Why?
Gradient too steep!
(slope is too steep.)
Discriminator score
All possible data
Diminished Gradient
Explode Score
Gradient Problems?
Problem1: Fake data's score may diminished gradient. (too flat)
Problem2: Due to loss function, score may be scale drastically. (too steep)
Gradient Problems?
Problems: diminished + steep gradient
How to solve unbalanced gradient?
Penalty 中間的 Gradient to 1!
(because of 1-lipschitz function)
Make it Smooth!!!
image resource: 李宏毅老師的投影片
Q: How to smooth the gradient?
A: Regularization
(give it penalty)
That is Gradient Penalty(GP).
Regularization ?

Too Steep.
More Flat.
However...
How to find the middle of real & fake data?
How to find this value?
image resource: 李宏毅老師的投影片
Discriminator score
All possible data
Target is between the real data and fake data.
Between
the real and fake?
Interpolation!
Interpolation ?
B
-
α=0.1
α=0.9
Why not GP only on D(G)?
Score may explode in the middle!
Interpolation ?
B
-
α=0.1
α=0.9
How to suppress learning curve?
α = U[0,1],隨機壓一壓。
Improved WGAN / WGAN-GP
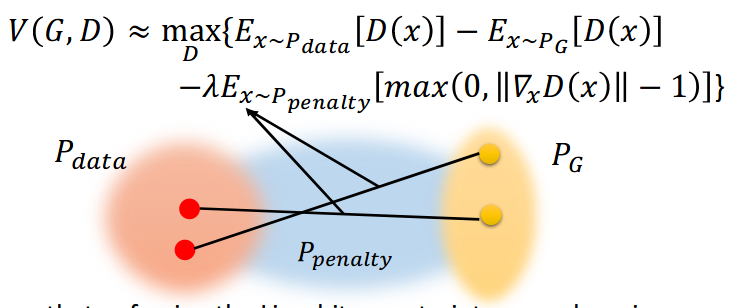
Note that 2-norm,
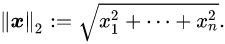
image resource: 李宏毅老師的投影片
Personal comment: gradient不能太高因為Loss,
gradient不能太低因為 diminished gradient,而1剛剛好。
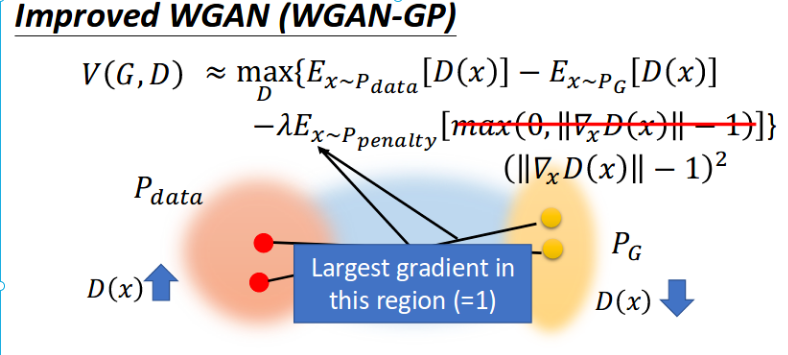
Gradient Penalty Step
- 1. Find interpolation
- 2. Calculate 2-norm of gradient
- 3. Calculate gradient penalty
WGAN loss function
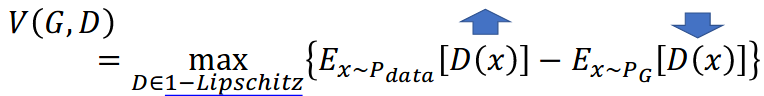
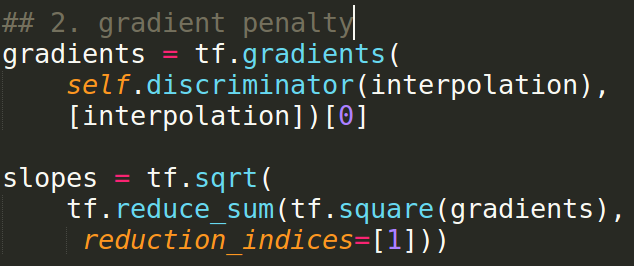
Gradient Penalty - Step1
Find interpolation

Gradient Penalty - Step2
||gradient of D(interpolate data)||
Gradient Penalty - Step3
Calculate Gradient Penalty

* lambda = 10 in paper
Reach 1-lipschitz
WGAN
Weight Clipping (WC)
WGAN-GP
Gradient Penalty (GP)
SN-GAN (spectral norm GAN)
divide spectral norm
(Not mentioned but very powerful)
WGAN-GP
Gradient Penalty (GP)
DCGAN+WGAN-GP result

* resolution is not high due to image size(64x64).
Another result
D:G = 4:1 , 5500 iterations
picture resource: GAN result by Arvin Liu (myself).
Why WGAN-GP solve the Mode Collapse?
[Personal viewpoint]
Actually, mode collapse...
If real data & G distribution....
A
B
C
What's your expect?
A
B
C
A
B
C
Dream on ! Get real!
A
B
C
A
B
C
Easy to minimize G_loss for G's data
Mode Collapse!
Discriminator do well on class B,C
Cyclic Changing
A
B
C
Easy to minimize G_loss for G's data
Mode Collapse!
A
B
C
Mode Collapse!
Original GAN
A
B
C
-
-
-
-
Easy to minimize G_loss for G's data
GP with Random Pair -
Amortize the Difficulty
A
B
C
-
-
-
-
Easy to minimize G_loss for G's data
GP with Random Pair -
Amortize the Difficulty
A
B
C
A
B
C
Easy to minimize G_loss for G's data
Cyclic Mode Collapse with Real Examples
DCGAN structure, image size 128x128
DCGAN - Step 44400

picture resource: GAN result by Arvin Liu (myself).
DCGAN - Step 44600

picture resource: GAN result by Arvin Liu (myself).
DCGAN - Step 44800

picture resource: GAN result by Arvin Liu (myself).
DCGAN - Step 45000
picture resource: GAN result by Arvin Liu (myself).

Minibatch-discrimination
Solve Mode Collapse
Ian Goodfellow : https://arxiv.org/pdf/1606.03498.pdf
Add Diversity Loss Intuitively
How to measure diversity?
It's cross-data loss!
MAMA MIA!
Thanks to minibatch!!
We can peep other data!
Main Idea of Minibatch Discrimination
- Let discriminator generalize the feature per data.
- N^2 calculate the difference of each pair.
- Append to the original Neural Network.
Flow Chart
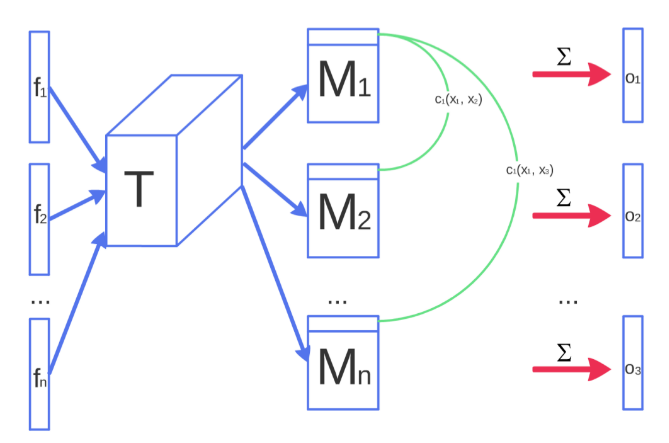
img resource: https://arxiv.org/pdf/1606.03498.pdf
F: raw
feature from each data
T: Projection
c: calculate difference
o: calculate diversity
What will Minibatch Discrimination works?
Generator 會順著 Discriminator "diversity"的gradient將接近的data拆開來。
因為Discriminator會知道"哪些data"很像。(有N^2比較。)
Due to Time Limit...
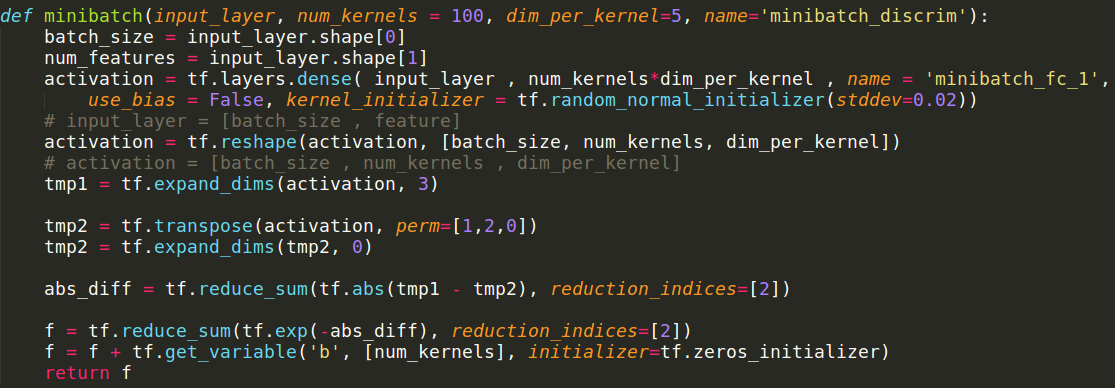
picture resource: my code displayed on sublime text3
這會放在zip檔,有興趣可以看看or跑跑看。
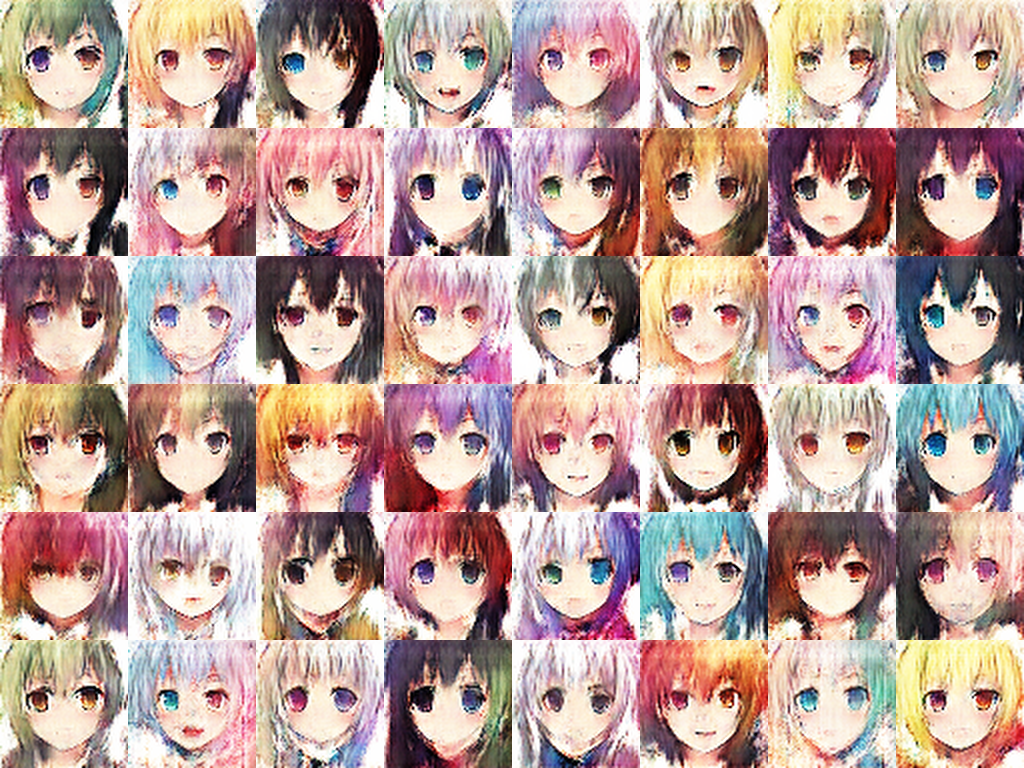
Minibatch Discrimination
picture resource: GAN result by Arvin Liu (myself).
WGAN-GP
- 很難mode collapse。
- Train起來相對久,中間有很大一段過程是在各個隱藏class的疊加態。
- 到非常後段(要收斂了)才會慢慢分離。
- WGAN-GP 就像是一個人生規劃導師,規劃各個data走向不同的路 (interpolation GP)。
Minibatch-Discrimination
- 一開始不會mode collapse,但其實train久了還是會。
- train的速度堪比一般的GAN,甚至更快(?)
- Minibatch-Discrimination就像是一個社會學家,勸戒各位不要都做同個工作。 (Discriminator diverge it)
多重Class的疊加態?
picture resource: GAN result by Arvin Liu (myself).
GAN 就只是炫砲技巧?
pix2pix
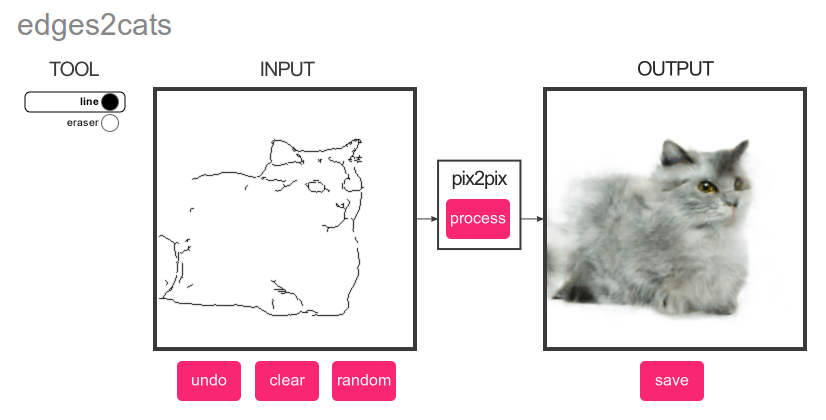
https://affinelayer.com/pixsrv/
Image Caption (im2txt)
Memes Generation: https://arxiv.org/pdf/1806.04510.pdf

Cloth Try on
https://arxiv.org/pdf/1711.08447.pdf

In General...
GAN can do most of "Generation Tasks"!
However...
These fashion application, maybe it's too far for you?
太炫砲了用不到!
Ultimate Data Augmentation
In classification problem...
Data Augmentation? Why not ...

image resource: https://chtseng.wordpress.com/2017/11/11/data-augmentation-%E8%B3%87%E6%96%99%E5%A2%9E%E5%BC%B7/
[Personal viewpoint]
In real tasks
class A
class B
class C
real data
GAN ganerator
simple augmentation
???
???
???
It's no guarantee that your augmented data follows original data distribution.
For example..
Rotation Degree?
Gaussian Noise?
Scale fx?
These data is based on "exist dataset."
In GAN, generator will generate new data.
In Real Tasks...
[Lab talk]
| Dataset A | Dataset B | is_pair? |
|---|---|---|
| exist | exist | Yes |
| not exist | exist | No |
| exist | not exist | No |
| not exist | not exist | ??? |
Data Shortage
cGAN Review
Conditional
Generative Adversarial Network
In a nut shell...
給GAN condition,要求生成資料要符合 condition.
How cGAN?
就直接丟進去Generator和Discriminator就好了!
Why it works???
Discriminator 會利用給定的condition痛罵Generator。
Simple cGAN Flow Chart
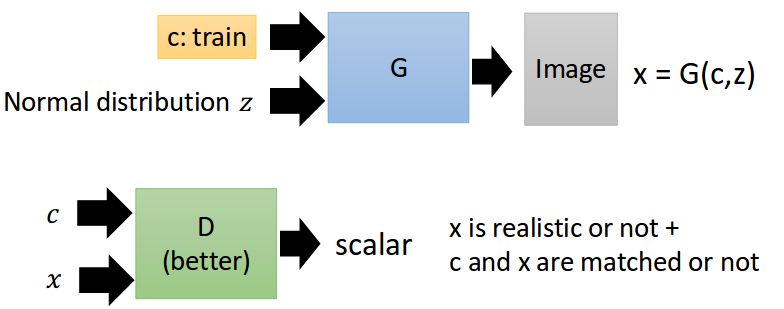
image resource: 李宏毅老師的投影片
Another Loss Measurement
你開心就好:)
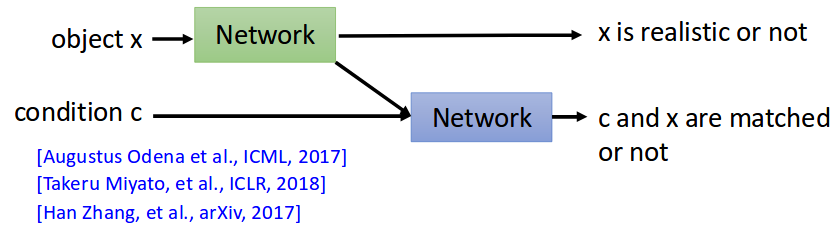
例如 classify 一個分數,real/fake 一個分數?
cGAN code
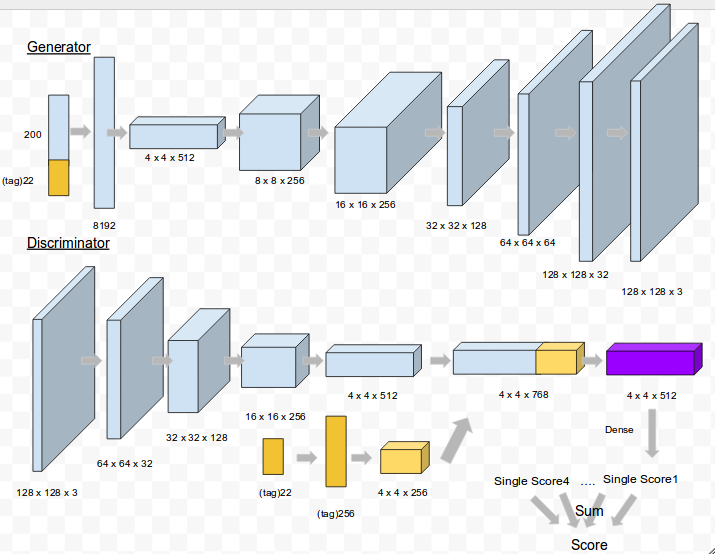
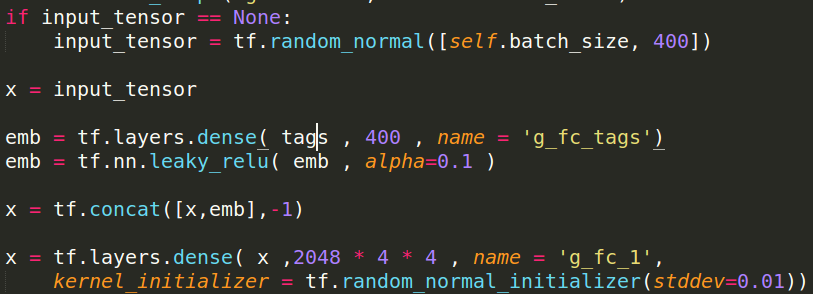
Generator Code

Discriminator Code

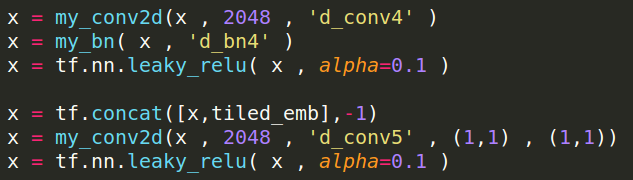
Loss Definition
同GAN/W-GAN/f-GAN...。
simple cGAN result (MC)

ACGAN + minibatch

Personal Experience
看看就好,拿來作弊用的
Personal Experience 1
Filter Bad Image
Use STRONGER D to filter G's data.
"Stronger" means train D lonely in the end.
Personal Experience 2
low lr at the end
When you think G is good enough, lower the learning rate, brighter image you get.
(Optional)
Tips : Dropout in G
https://arxiv.org/pdf/1611.07004v1.pdf
Tips : Use labels
Tips : Batch Normalization
Tips : Avoid Sparse Function
i.e.: Maxpooling, ReLU(but G can use it.)
Tips : Leaky ReLU for D, ReLU for G.
Maybe ReLU is suitible for "edge"?
Ques1 : slerp or lerp?
ICLR'2017 (rejected)
https://openreview.net/forum?id=SypU81Ole
LERP (Liner IntERPolation)
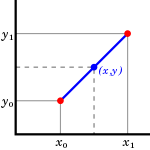
https://en.wikipedia.org/wiki/Linear_interpolation
SLERP (Spherical LERP)
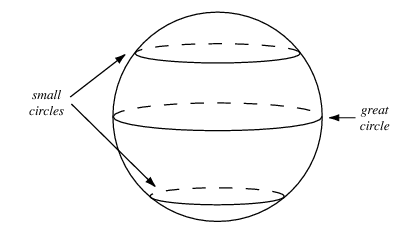
WGAN LERP 不用自作主張用SLERP :)
Ques2 : Batch Size?
Expert said...

In any tasks, size of mini-batch = 16~64 in my own practical experience :) .
Why? Maybe...
Q: Why not GD?
A: Easily sink into local minima.
Q: Why not SGD?
A: Hard to converge.
Q: Mini-batch?
Ques3 : Complex task is hard to GAN?
(WGAN-GP) only pink hair
D:G = 4:1 , 5500 iterations

picture resource: GAN result by Arvin Liu (myself).
(WGAN-GP) no-constraint
D:G = 4:1 , 5500 iterations
picture resource: GAN result by Arvin Liu (myself).
MISCs
MISC1 - ACGAN
Some Collection...
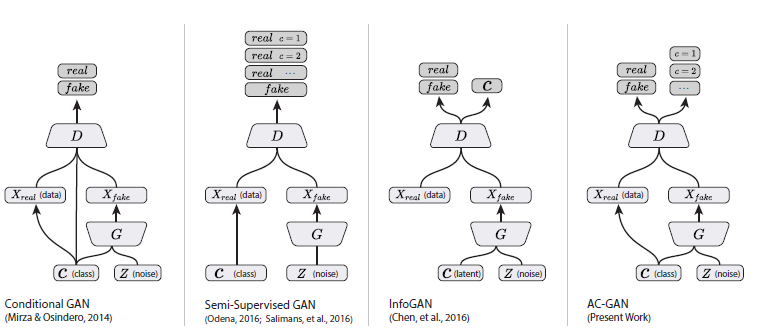
image resource: https://www.cnblogs.com/punkcure/p/7873566.html
Main Idea of ACGAN
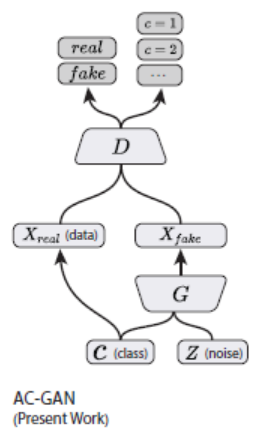
D output C/S
Thus, Having Classification & Synthesis(合成) eror.
ACGAN loss fucntion
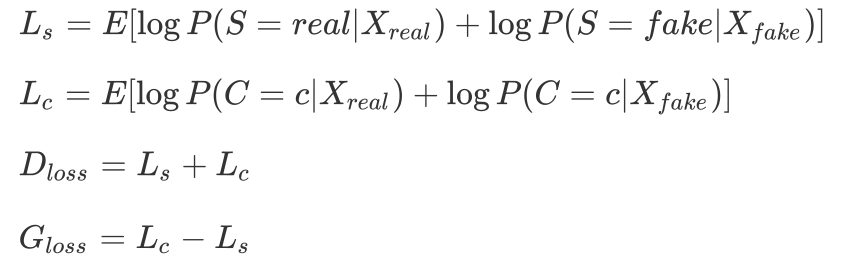
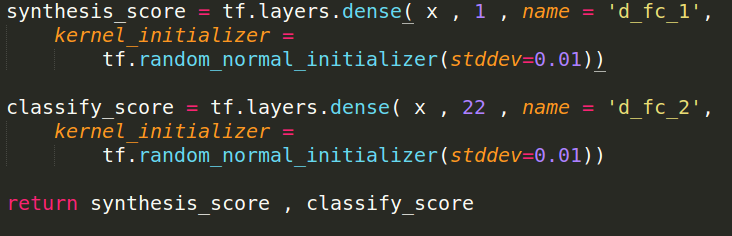
ACGAN code
Generator
same as cGAN.
Discriminator
Only need to change last layer.
Loss Function
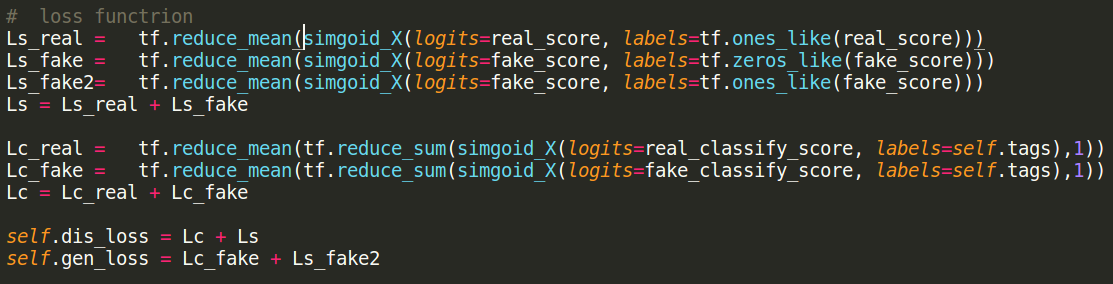
In this task, I change some loss function.
(For G, +log(z) -> -log(1-z))
Ls : loss in original GAN.
Lc : binary cross entropy
(tag loss, not softmax.)
ACGAN + minibatch
MISC2 - patch GAN
Patch GAN
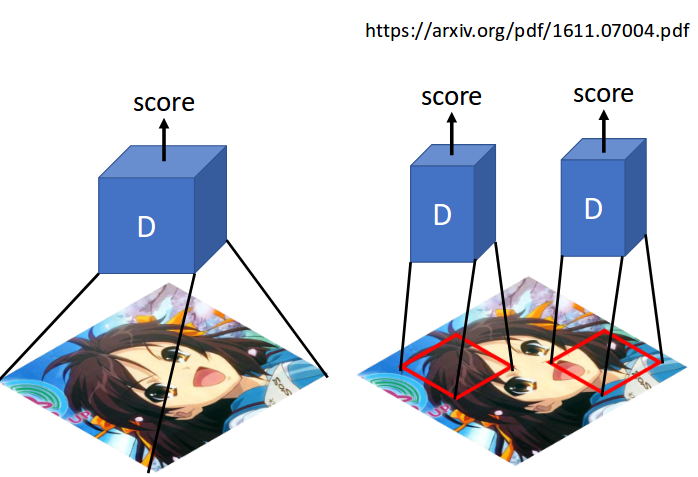
image resource: 李宏毅老師的投影片
Patch GAN risks












picture resource: GAN result by Arvin Liu (myself).
Review
GAN model
- DCGAN (Deep Convolutional GAN)
- LSGAN (Least Square GAN)
- WGAN-GP (Improved Wesserstein GAN)
- Patch GAN (Pix2Pix's Discriminator)
-
conditional GAN
-
ACGAN (Auxiliary Classifier GAN)
GAN main problems
- Mode collapse
- Diminished Gradient
- Non-convergence
Q & A
Thanks for your listening!

GAN
By Arvin Liu



