ML2019 FALL Hw4
手把手教學
~ Image Clustering~
Task Description
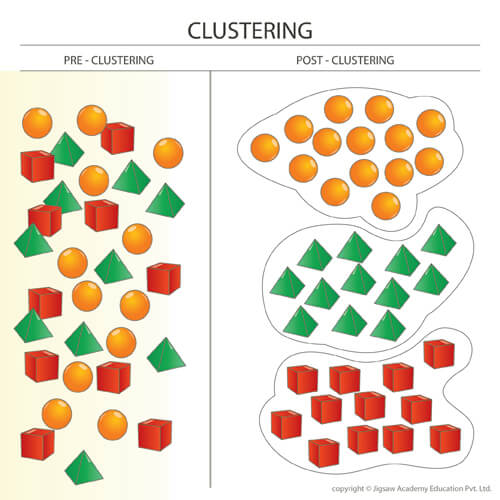
將混在一起的Data進行分類。
Work Flow
-
利用Autoencoder
進行降維打擊 -
利用非Deep Learning的方法進行二次降維打擊
-
利用Clustering方法來分類。
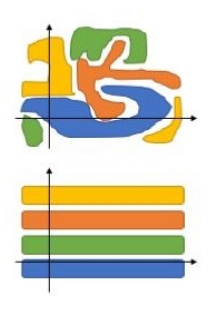
Why 兩次降維打擊?
單純利用Autoencoder暴力打擊(打到很低維)可能的風險
- 做不出好的Reconstruction (Loss 壓不下去)-> Latent並沒有很好的表現出圖片本來的資訊。
- 為了要讓Loss壓下去,導致Encoder或Decoder太過強大 -> 導致Latent太過歪七扭八,無法用一般的clustering方法找出好的群體。
- 其實也有可能做的很好,不過你可以就Try try see。
Step 0. 事前準備
事前準備
# detect is gpu available.
use_gpu = torch.cuda.is_available()
autoencoder = Autoencoder()
# load data and normalize to [-1, 1]
trainX = np.load('release/trainX.npy')
trainX = np.transpose(trainX, (0, 3, 1, 2)) / 255. * 2 - 1
trainX = torch.Tensor(trainX)
# if use_gpu, send model / data to GPU.
if use_gpu:
autoencoder.cuda()
trainX = trainX.cuda()
train_dataloader = DataLoader(trainX, batch_size=32, shuffle=True)
test_dataloader = DataLoader(trainX, batch_size=32, shuffle=False)
需要注意的是, 這裡我們要將圖片壓成 [-1~ 1]。
壓成[-1,1]時通常最後過tanh, 如果是[0, 1]的話則是sigmoid。
Optimizer & Loss function
# We set criterion : L1 loss (or Mean Absolute Error, MAE)
criterion = nn.L1Loss()
optimizer = optim.Adam(autoencoder.parameters(), lr=0.001)
這裡我們選用L1 - loss ,
Optimizer則是Adam,ae的模型之後詳述。
Step 1. Autoencoder
Autoencoder
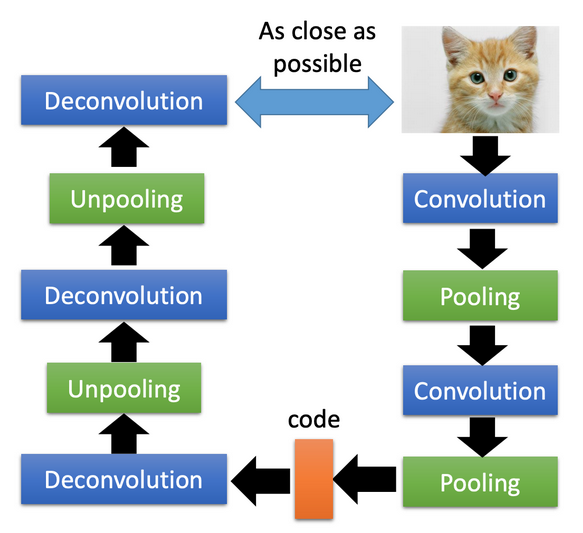
Encoder / Decoder
| Layer | Parameter | Output Shape |
|---|---|---|
| Encoder Input | - | (3, 32, 32) |
| Conv2d | (3, 8, 3, 2, 1) | (8, 16, 16) |
| Conv2d | (8, 16, 3, 2, 1) | (16, 8, 8) |
| Encoder Output | - | (16, 8, 8) |
| Decoder Input | - | (16, 8, 8) |
| ConvTranspose2d | (16, 8, 2, 2) | (8, 16, 16) |
| ConvTranspose2d | (8, 3, 2, 2) | (3, 32, 32) |
| Decoder Output | (3, 32, 32) |
Deconv / Conv 參數:
(input channel, output channel, kernel size, strides, padding )
Torch - Autoencoder Model
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# define: encoder
self.encoder = nn.Sequential(
nn.Conv2d(3, 8, 3, 2, 1),
nn.Conv2d(8, 16, 3, 2, 1),
)
# define: decoder
self.decoder = nn.Sequential(
nn.ConvTranspose2d(16, 8, 2, 2),
nn.ConvTranspose2d(8, 3, 2, 2),
nn.Tanh(),
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
# Total AE: return latent & reconstruct
return encoded, decoded
Train your AE
for epoch in range(20):
for x in train_dataloader:
latent, reconstruct = autoencoder(x)
loss = criterion(reconstruct, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
抓出 latent 層並標準化
latents = []
for x in test_dataloader:
latent, reconstruct = autoencoder(x)
latents.append(latent.cpu().detach().numpy())
latents = np.concatenate(latents, axis=0)
latents = latents.reshape([9000, -1])
latents_mean = np.mean(latents, axis=0)
latents_std = np.std(latents, axis=0)
latents = (latents - latents_mean) / latents_std
Step 2. 二次降維
PCA / SVD / t-SNE ...
用個最簡單的: PCA
from sklearn.decomposition import PCA
latents = PCA(n_components=32).fit_transform(latents)
Step 3. Clustering
k-means / knn ...
用個最常用的K-means
from sklearn.cluster import KMeans
result = KMeans(n_clusters = 2).fit(latents).labels_
Example code
Example code
import numpy as np
import torch
import torch.nn as nn
import pandas as pd
from torch import optim
from torch.utils.data import DataLoader, Dataset
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# define: encoder
self.encoder = nn.Sequential(
nn.Conv2d(3, 8, 3, 2, 1),
nn.Conv2d(8, 16, 3, 2, 1),
)
# define: decoder
self.decoder = nn.Sequential(
nn.ConvTranspose2d(16, 8, 2, 2),
nn.ConvTranspose2d(8, 3, 2, 2),
nn.Tanh(),
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
# Total AE: return latent & reconstruct
return encoded, decoded
if __name__ == '__main__':
# detect is gpu available.
use_gpu = torch.cuda.is_available()
autoencoder = Autoencoder()
# load data and normalize to [-1, 1]
trainX = np.load('release/trainX.npy')
trainX = np.transpose(trainX, (0, 3, 1, 2)) / 255. * 2 - 1
trainX = torch.Tensor(trainX)
# if use_gpu, send model / data to GPU.
if use_gpu:
autoencoder.cuda()
trainX = trainX.cuda()
# Dataloader: train shuffle = True
train_dataloader = DataLoader(trainX, batch_size=32, shuffle=True)
test_dataloader = DataLoader(trainX, batch_size=32, shuffle=False)
# We set criterion : L1 loss (or Mean Absolute Error, MAE)
criterion = nn.L1Loss()
optimizer = optim.Adam(autoencoder.parameters(), lr=0.001)
# Now, we train 20 epochs.
for epoch in range(20):
cumulate_loss = 0
for x in train_dataloader:
latent, reconstruct = autoencoder(x)
loss = criterion(reconstruct, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
cumulate_loss = loss.item() * x.shape[0]
print(f'Epoch { "%03d" % epoch }: Loss : { "%.5f" % (cumulate_loss / trainX.shape[0])}')
# Collect the latents and stdardize it.
latents = []
reconstructs = []
for x in test_dataloader:
latent, reconstruct = autoencoder(x)
latents.append(latent.cpu().detach().numpy())
reconstructs.append(reconstruct.cpu().detach().numpy())
latents = np.concatenate(latents, axis=0).reshape([9000, -1])
latents = (latents - np.mean(latents, axis=0)) / np.std(latents, axis=0)
# Use PCA to lower dim of latents and use K-means to clustering.
latents = PCA(n_components=32).fit_transform(latents)
result = KMeans(n_clusters = 2).fit(latents).labels_
# We know first 5 labels are zeros, it's a mechanism to check are your answers
# need to be flipped or not.
if np.sum(result[:5]) >= 3:
result = 1 - result
# Generate your submission
df = pd.DataFrame({'id': np.arange(0,len(result)), 'label': result})
df.to_csv('haha_submission.csv',index=False)
What Else?
改良AE
- 調Epoch (loss較低在這個任務不代表能做的比較好。)
- 改Model,控制中間的latent數量。
- loss = MAE或MSE。
- 換optimizer / 調learning rate
改良二次降維
改良Clustering
Dirty Tricks
- Ensemble 通常都是最後的大招。
ML2019 FALL
By Arvin Liu




