SDML Hw1
Team: SDML_SpioradBaseline
b05901082 楊晟甫
b05902127 劉俊緯
b06902080 吳士綸
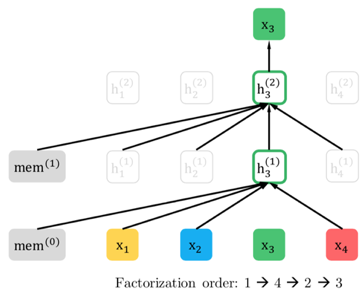
XLNet
Random mask
Result
0.697 - train from scratch (12-layers) + BCE
F1 loss & BCE loss
BCE loss
F1 loss
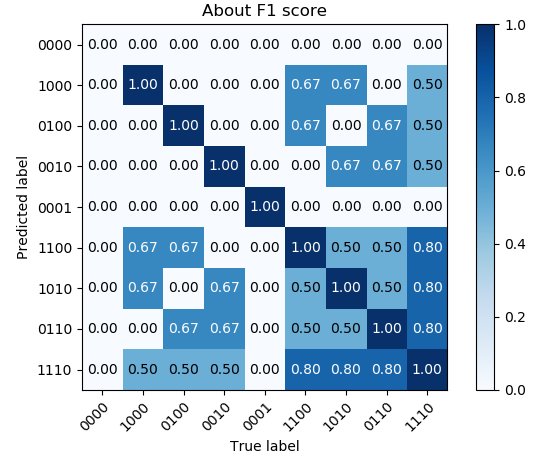
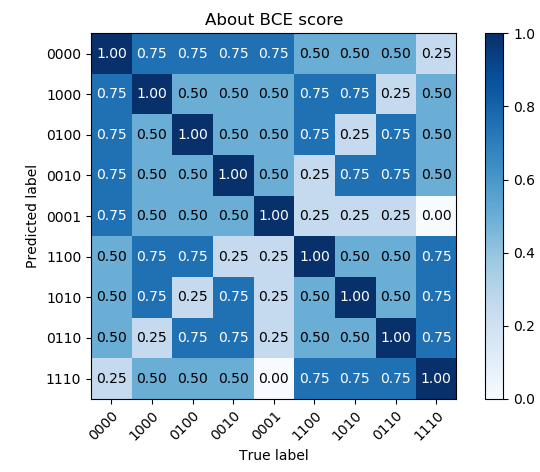
Actually : always output (1,1,1,0) -> score 0.560
differentiable F1 loss leads XLnet to local minima
Differentiable F1 loss
\frac{2 \times \text{precision} \times\text{recall} }{\text{precision} + \text{recall}} = \frac{2TP}{2TP+FP+FN}
TP = torch.sum(labels * logits, 1)
FP = torch.sum((1-labels) * logits, 1)
FN = torch.sum(labels * (1-logits), 1)
f1_loss = 1 - 2 * TP / (2*TP+FP+FN)
Avoid eps.
Mixed Loss - BCE + F1
\alpha \times \text{BCE}_{loss} + (1-\alpha ) \times \text{F1}_{loss}
\alpha \in [0,1]
-> More stable & Fit the target score
Bert
Result
0.70 - pre-train(only train & test) & fine tune
0.68 - only fine tune
Warm-up & Fine-tune
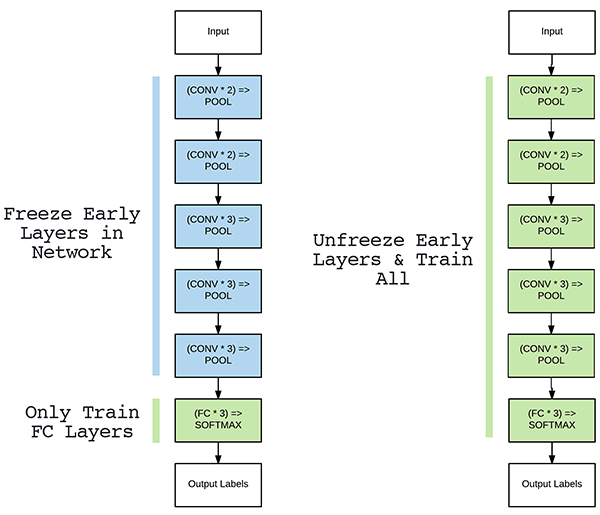
We freeze to self_attn 7.
Little Graph
Bert
Title
Abstract
Title loss
Abstract loss
Together train -> but only use abstract to predict
Distribution Shift
Little statistics
Theoretical : 45.9%
ENGINEERING : 48.4%
EMPIRICAL : 30.5%
OTHERS : 3.7%
In train:
use argsort to find 1 threshold
Result
0.694422 (XLnet w/o pretrain + BCE loss)-> 0.6976744
However...
it doesn't work in mixed-loss.
Zero Fixing
F1 Loss ???
Predict 0000 always no points
Zero Fixing
if not 0000
-> predict as usual
else:
-> use threshold
if still 0000:
-> logits*1.5 and use threshold
Importance
Little Graph
Bert
Title
Abstract
Title logits
Abstract logits
Imp
logits = imp * title + (1-imp) * abs
Timeline
Timeline
- XLnet - BCE / F1 / MSE / Softmax or Sigmoid
- XLnet - F1 + BCE + Threshold
- Bert - F1 + BCE
- Bert - F1 + BCE & Pretraining
- Bert - F1 + BCE & Pretraining & Fine-tune
- Add Importance
- Cat survey ~ 0.61-0.62
- Importance + cat survey(importance threshold)
- Add cat -> no improvement
Q&A
SDML Hw1
By Arvin Liu



