






















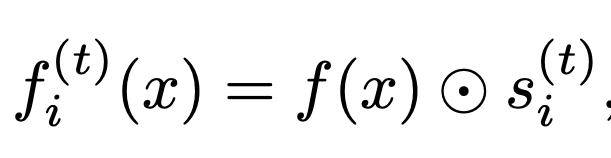
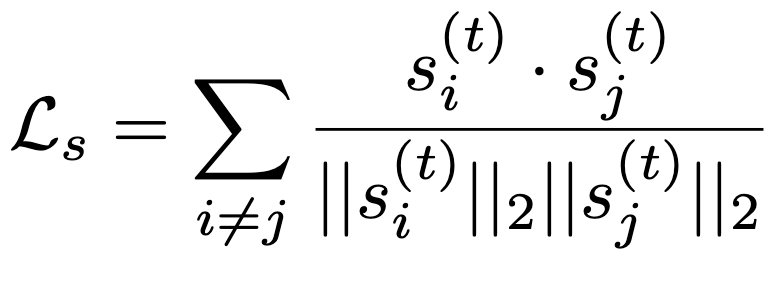

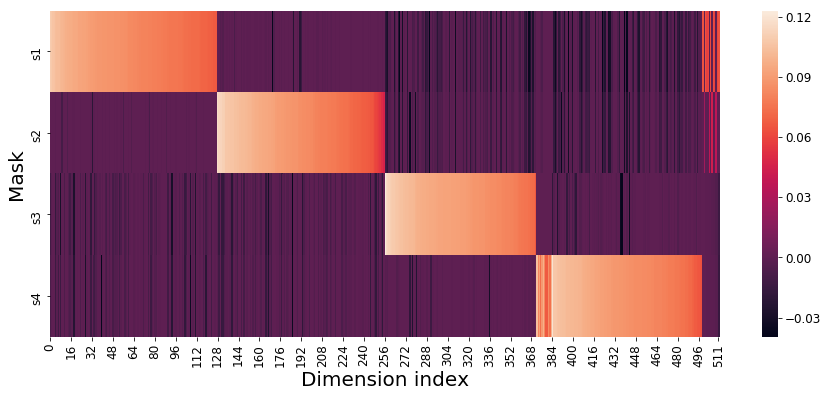






Artsiom S
PhD student in Computer Vision
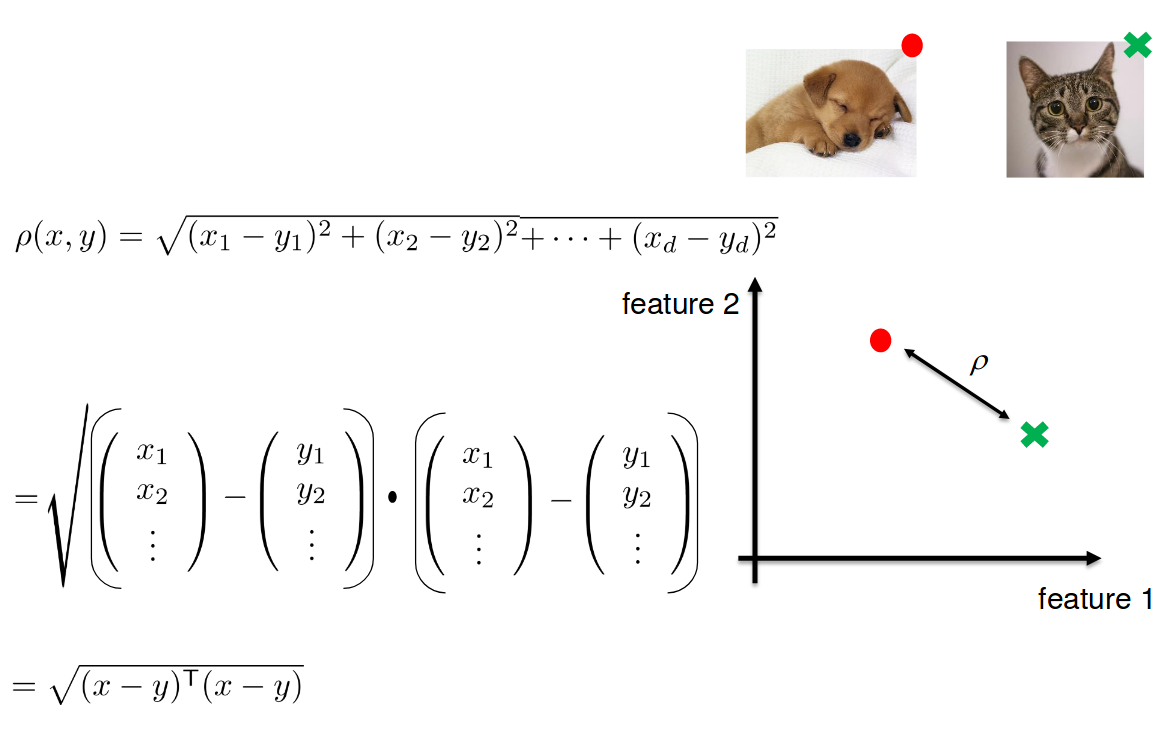
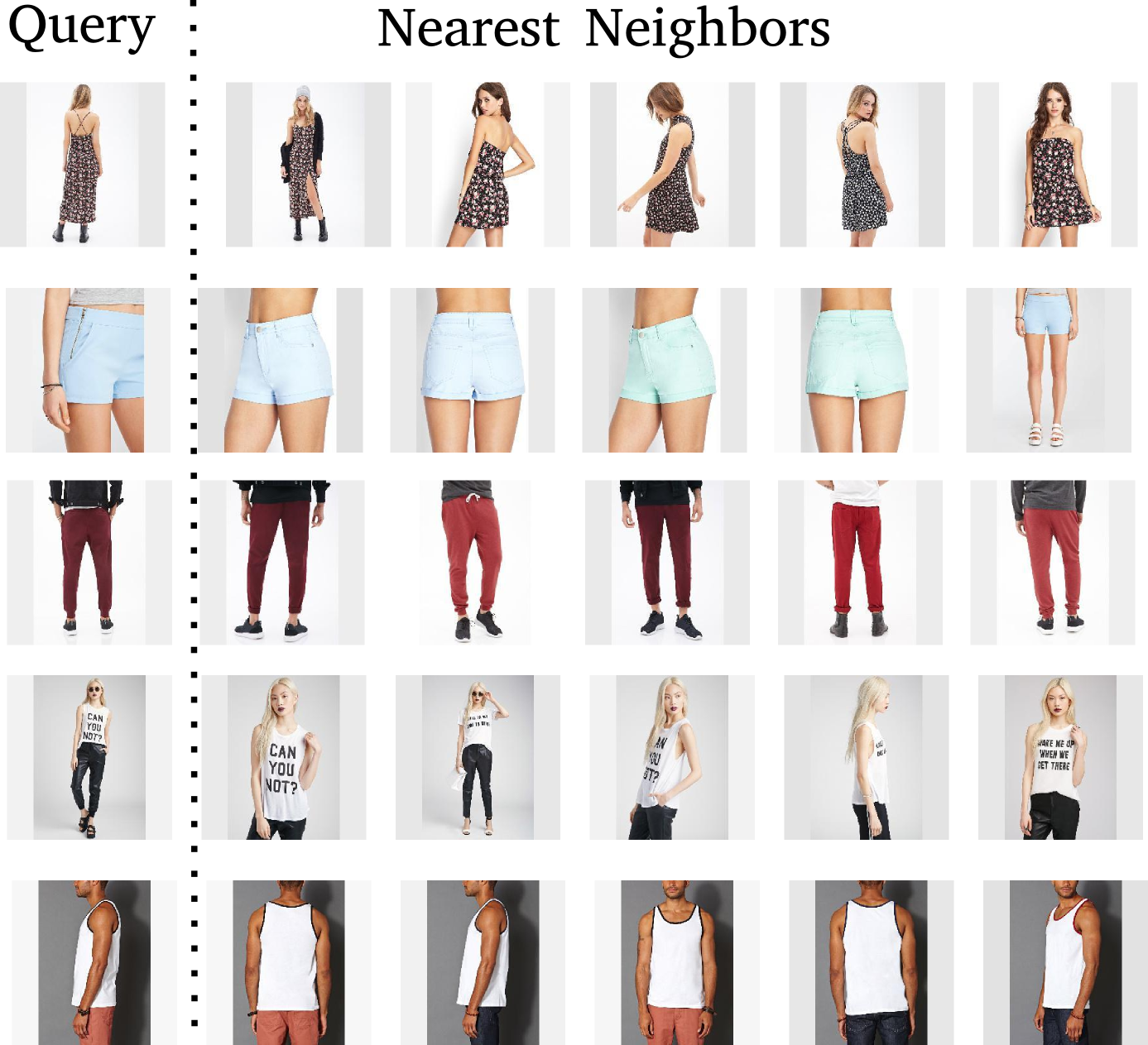
Project images in d-dimensional Euclidean space where distances directly correspond to a measure of similarity
Project Image in d-dimensional space where Euclidean distance would make sense
Basic idea: learn a metric that assigns small (resp. large) distance to pairs of examples that are semantically similar (resp. dissimilar).
Metric Learning
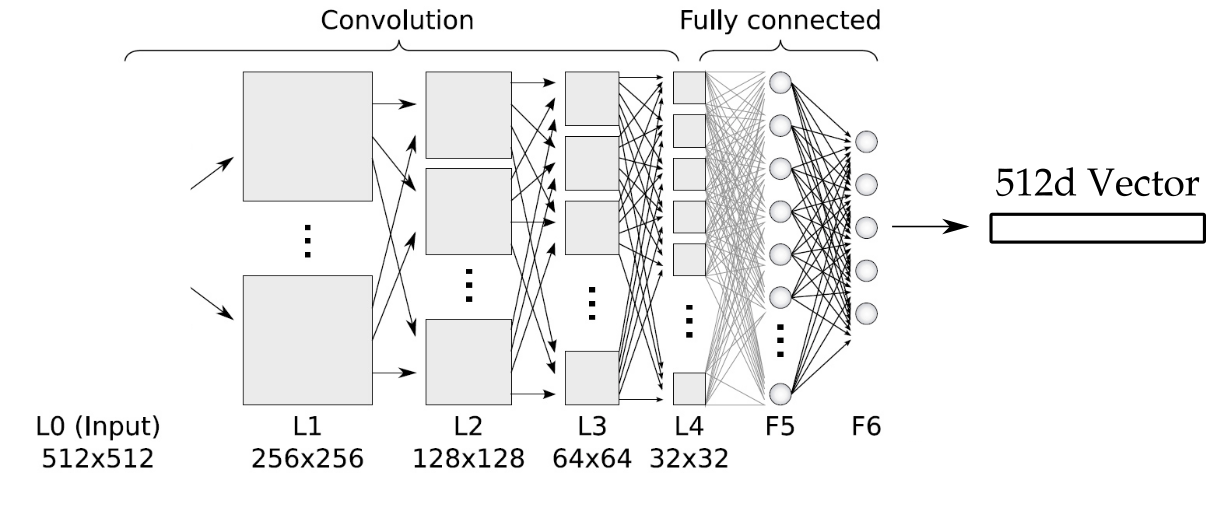
d-dimensional Embedding Space
Basic idea: learn a metric that assigns small (resp. large) distance to pairs of examples that are semantically similar (resp. dissimilar).
Metric Learning
d-dimensional Embedding Space
Small distance
Basic idea: learn a metric that assigns small (resp. large) distance to pairs of examples that are semantically similar (resp. dissimilar).
Metric Learning
d-dimensional Embedding Space
Large distance
Person identification
Image Search
Few-shot learning
Courtesy: cs-230 course, Stanford University
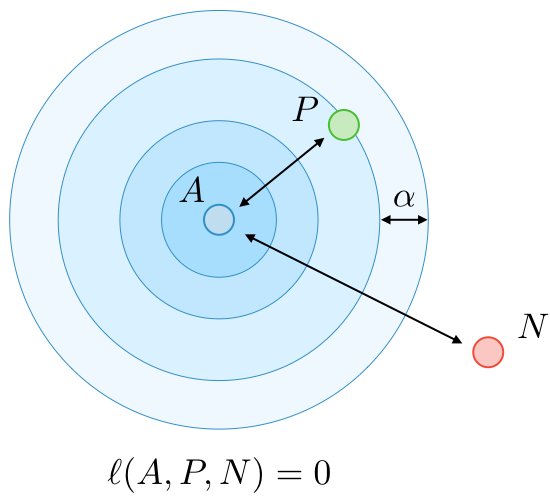
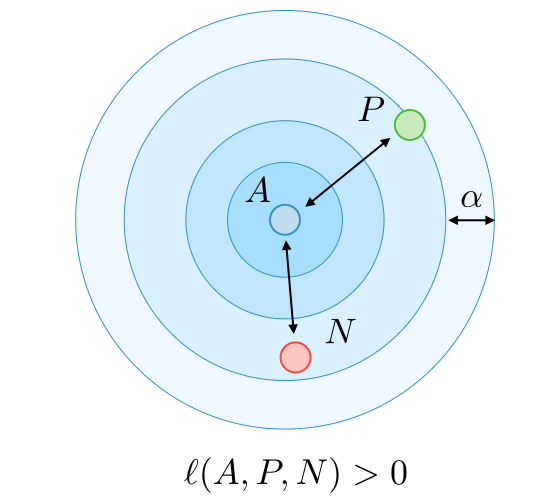
A = Anchor
P = Positive
N = Negative
Leopard
Lion
Easy!
Leopard
Jaguar
Hard!
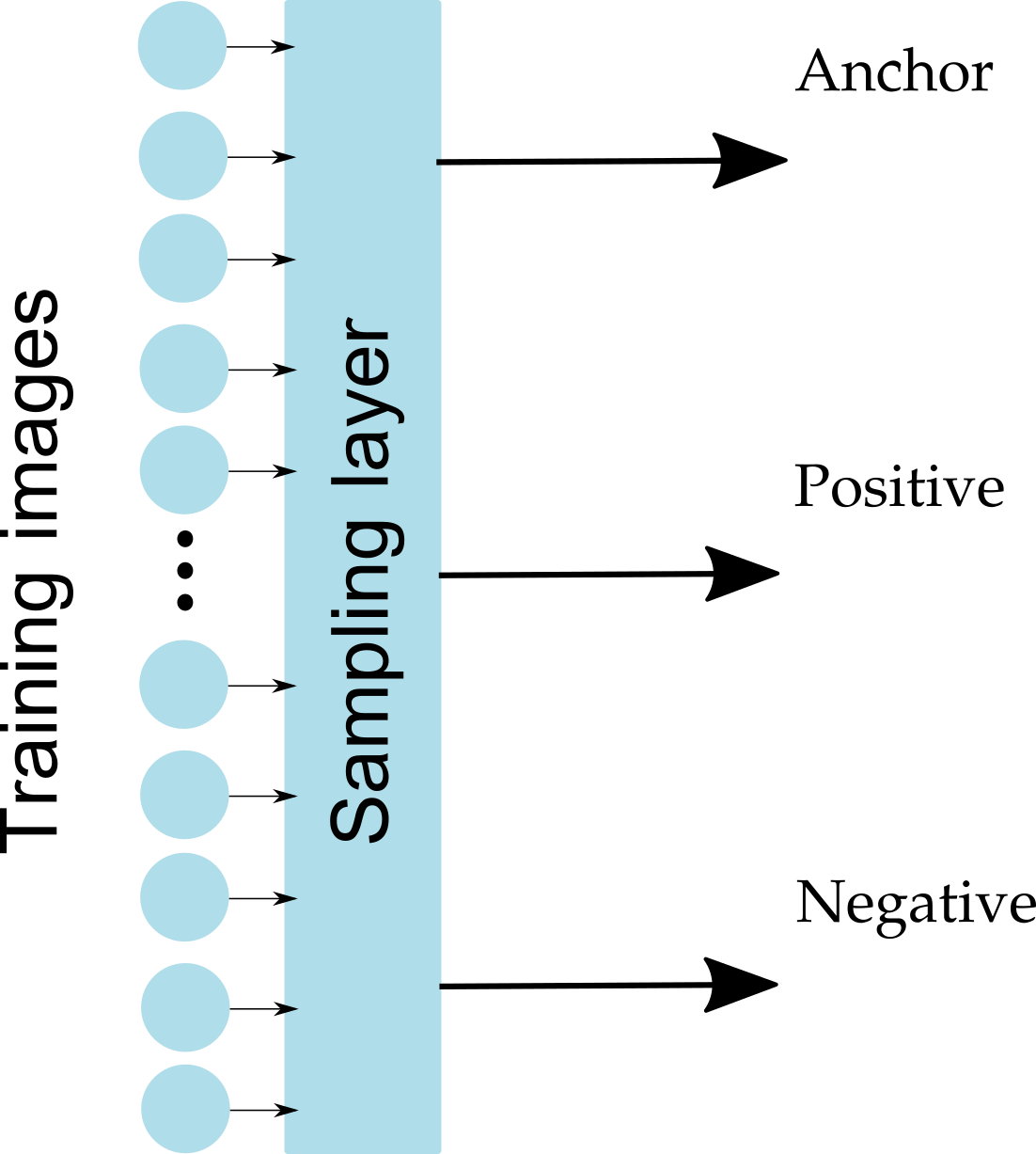
Sample "hard" (informative) triplets, where loss > 0
Sampling must select different triplets as training progresses
[1] FaceNet: A Unified Embedding for Face Recognition and Clustering, Schroff et al., 2015
Naive Approach: Learn a single distance metric for all training data
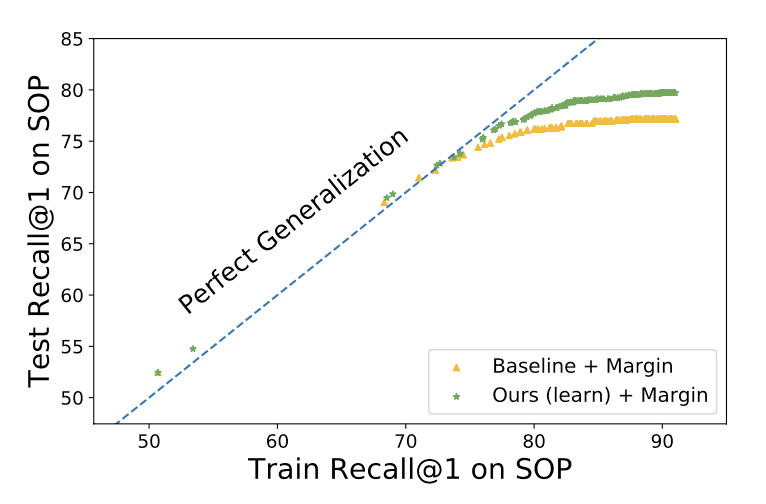
→ Overfit and fail to generalize well.
Naive Approach: Learn a single distance metric for all training data
→ Overfit and fail to generalize well.
Naive Approach: Learn a single distance metric for all training data
→ Fails to capture attributes which are not covered by provided GT labels during train.
Attributes which are the most discriminative on train are not necessary useful on novel test images
Training classes
Test classes
Attributes which are the most discriminative on train are not necessary useful on novel test images and other way around
Attributes which are the most discriminative on train are not necessary useful on novel test images and other way around
Chromatic abberation
Clean image
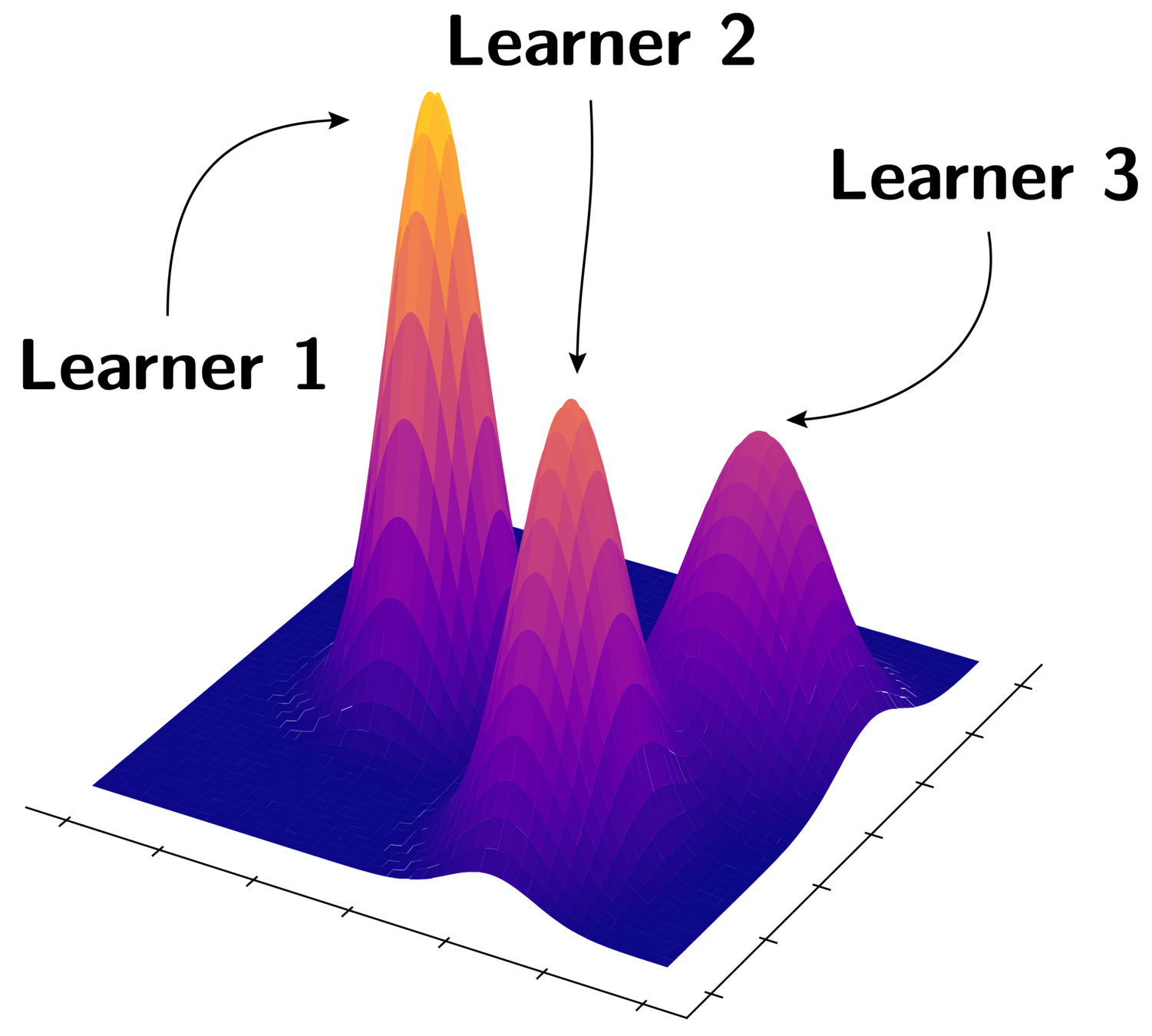
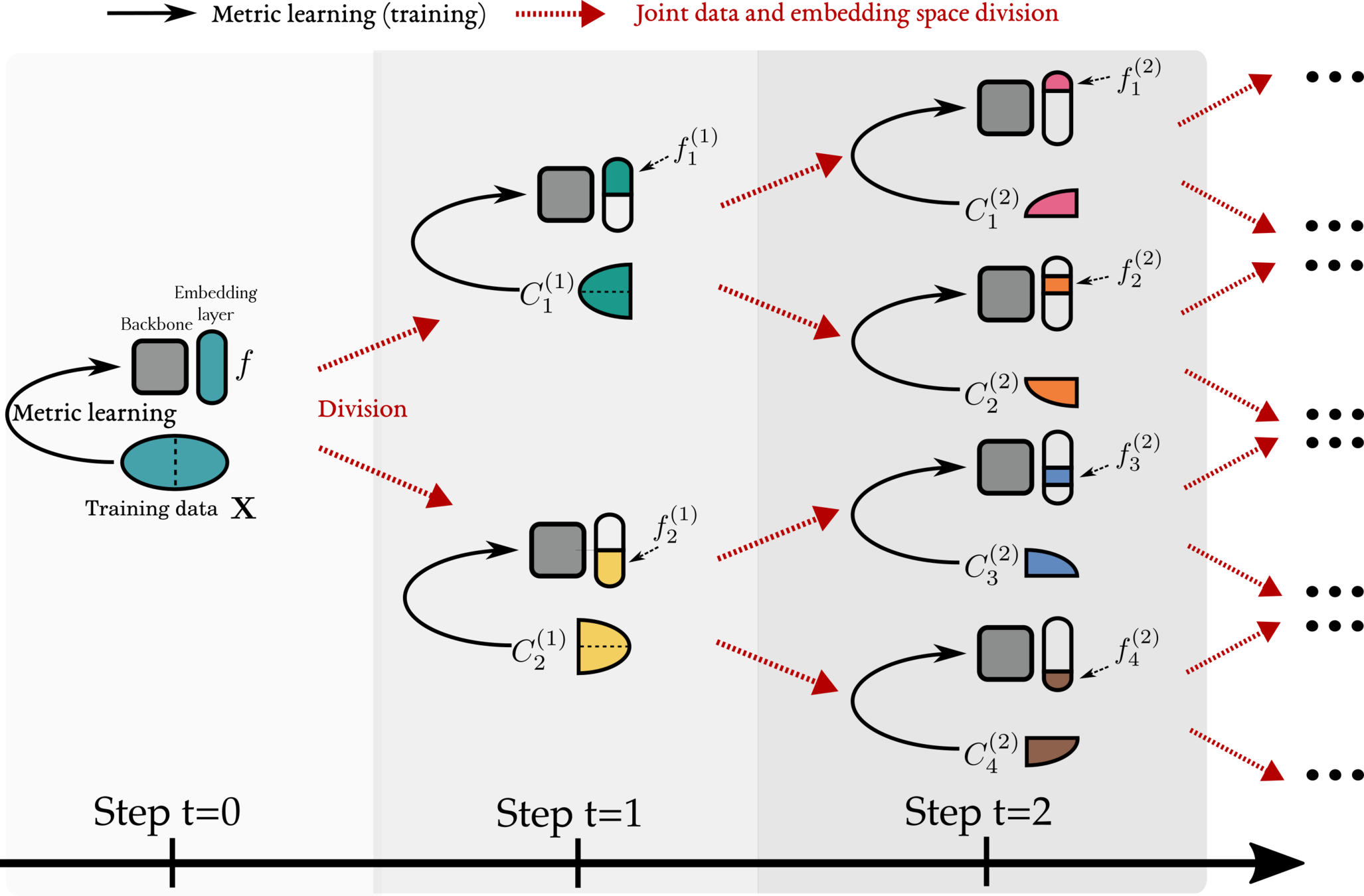
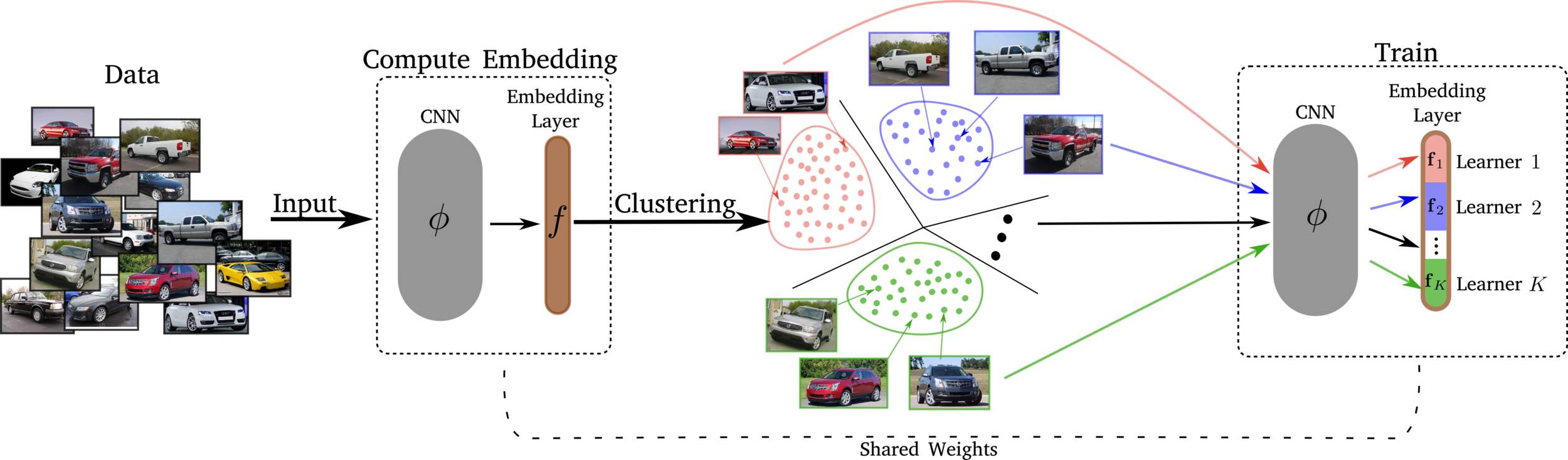
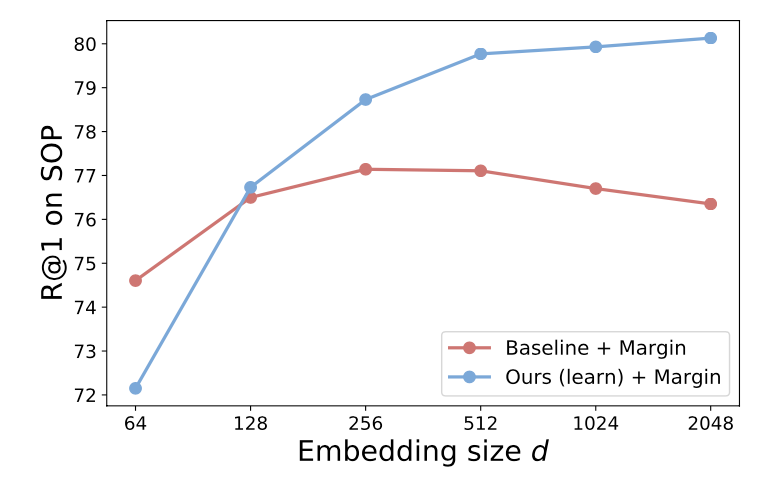
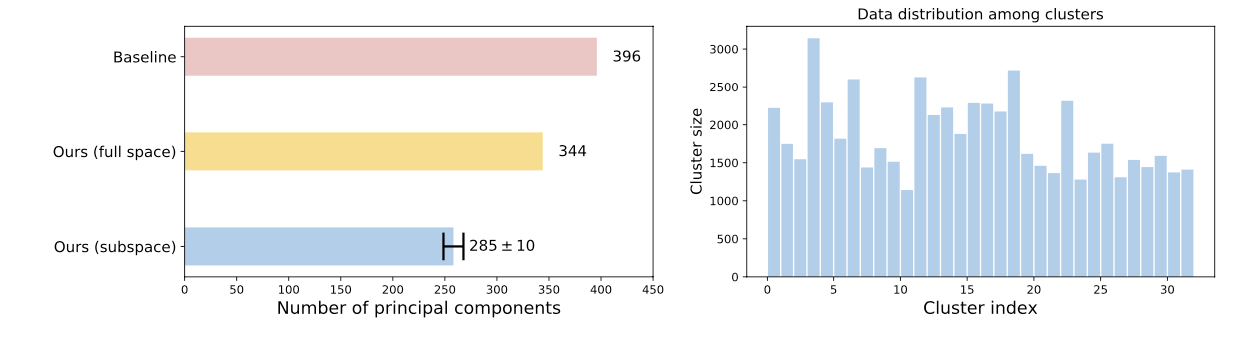
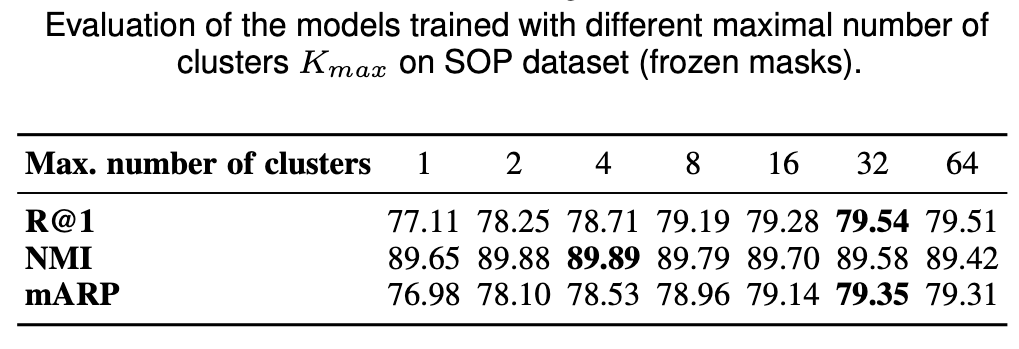
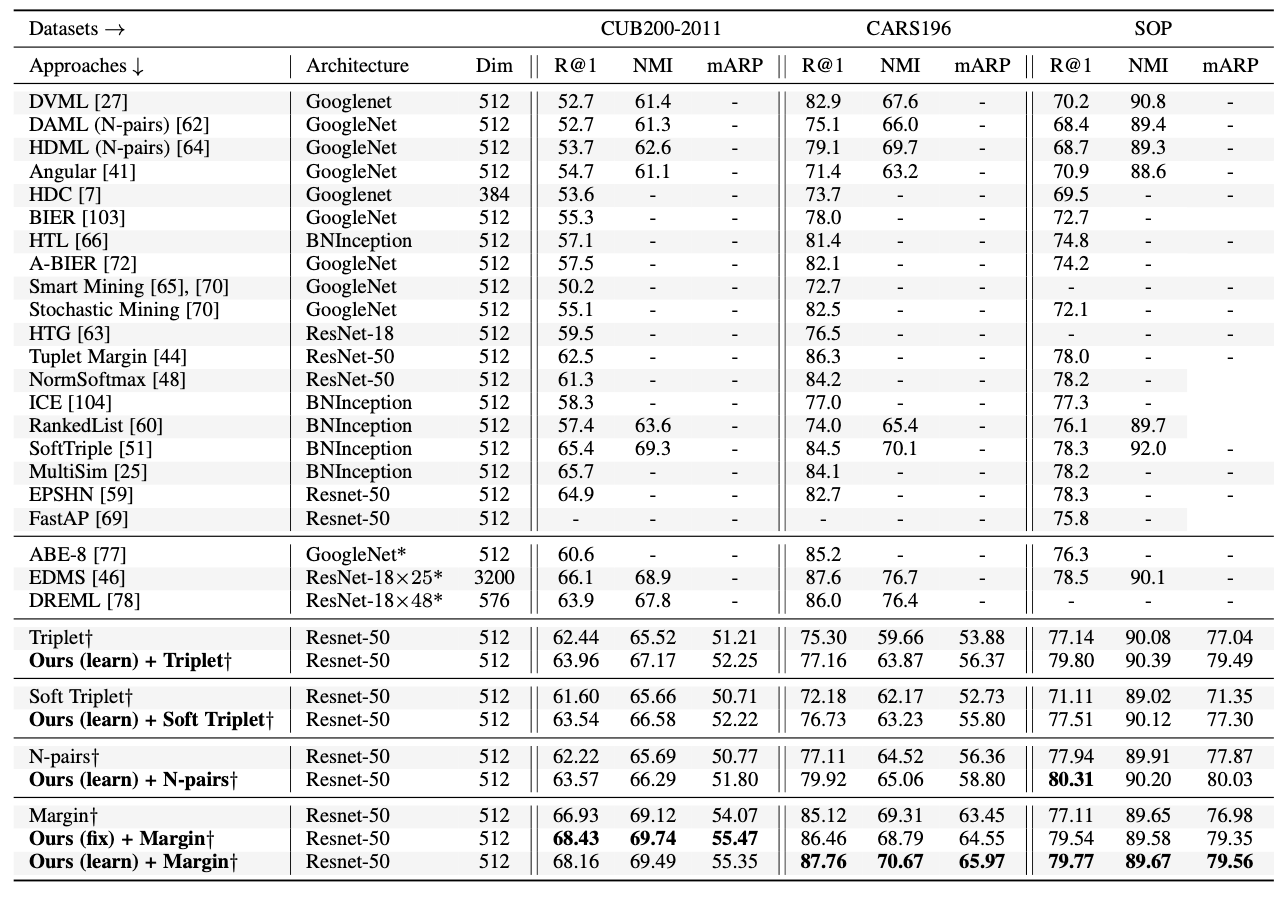
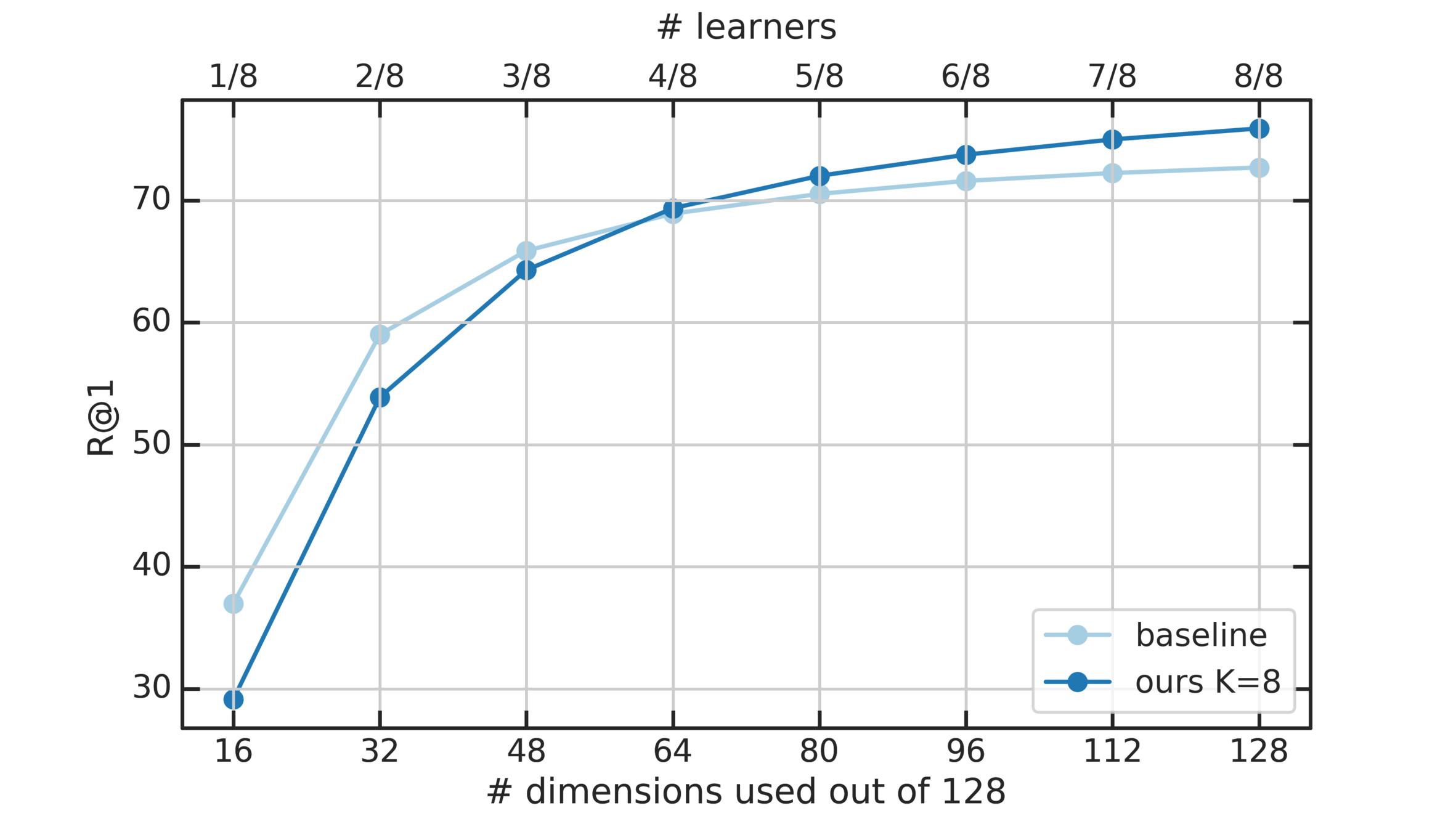
To alleviate the aforementioned issues: Learn several different distance metrics on non-overlaping subsets of the data.
Learnable mask which induces subspace i
Embedding subspace i
Subspace orthogonality loss
Split the embedding space in K subspaces
Training
Assign a separate learner (loss) to each subspace.
Train K different distance metrics using K learners.
Increase number of subproblems x 2
...
Conquer the embedding space by combining subspaces together
By Artsiom S
I will discuss our novel `divide and conquer` approach (CVPR 2019) for deep metric learning, which significantly improves the state-of-the-art performance of metric learning on computer vision tasks
